基于注意力机制的白细胞细粒度分类方法
1.本发明属于医学影像识别和深度学习技术领域,具体涉及一种基于global-local注意力的白细胞细粒度分类方法。
背景技术:
2.急性白血病等重大危险疾病近年来在全球发病率越来越高,年轻化的趋势越来越明显。对这些重大疾病的诊断,依赖于血液化验,或者血液涂片显微影像的识别和分类,在此基础上进行计数,从而统计出各类白细胞的类别比例(white blood cell count,全血细胞计数),从而对各种重大危险疾病做出诊断。现在在医院临床上,主要依赖于有经验的医师,人工地识别和计数。这样的话,耗时耗力且容易出错,因此会产生错误分类,会导致医生“误诊”或“漏诊”,从而威胁到病人的生命安全。
3.因此针对这种现象,学者们引入计算机视觉和机器学习技术,对血液图片的显微影像进行自动识别。传统的机器学习技术,例如边缘检测,阈值分割,支持向量机,灰度对比度,k-means分类等技术,但是受传统计算机视觉技术和机器学习技术的限制,其识别的准确率并不是很出色。
4.随着计算机算力的提升,深度学习迎来了极大的发展,在多个视觉领域都获得了成功应用。它们主要是利用卷积神经网络等深度神经网络来提取图像的局部特征,并且通过卷积,池化方法来逐步构建抽象特征图谱,从而通过全连接层进行物体识别的输出。其相比于传统的机器学习方法,极大的提升了分类的准确率。
5.但是,面向重大疾病如白血病辅助诊断的白细胞识别,面临如下问题:1)受不同医院,不同机器设备,不同成像环境的影响,生成的白细胞图像有着不同的色差,给机器自动识别造成困难。2)由于重大危险疾病医学领域的特点,很多医学数据集都存在长尾现象,罕见疾病类别的样本分布极少,常见疾病类别的样本分布特别多。因此类别分布极其不均衡。3)由于白细胞图像只存在白细胞图像,因此其特征十分单一,会对模型的图像识别造成困难。4)由于是白血病辅助诊断,因此需要进行骨髓涂片细胞学检测,即进行骨髓上的细胞抽取,白细胞可能某些细胞群,类别之间的差异没有特别明显,差异过小,例如红细胞中早幼红细胞,中幼红细胞与晚幼红细胞之间的差异过小。5)诊断白细胞,需要对高达40种类的白细胞,进行细粒度的精准识别。
6.基于现在的cnn卷积神经网络方法,并不能很好的解决上述问题。
技术实现要素:
7.本发明针对现有的技术的不足,提出了一种基于global-local注意力机制的白细胞分类方法。
8.本发明提出的基于global-local注意力机制的白细胞分类方法,其是端到端的可训练的transformer与卷积结合的模型,融合了transformer的擅长捕捉长距离依赖关系,提取全局特征的优点和cnn在low-level提取图像局部特征的优点,能够更好的构建白细胞
图像的特征图谱,丰富白细胞的特征信息,提高细胞图像的识别准确率。并且该模型具有一定的泛化性和稳定性,其使用sgd和adamw俩个优化器均能得到最优解。
9.本发明方法具体包括以下三个步骤:数据集的收集,wbclformer模型的搭建和训练,wbclformer模型效果检验。
10.步骤1:获取白细胞图像作为基础数据集,并且分为训练集和测试集;
11.步骤2:wbclformer模型的搭建和训练
12.wbclformer模型的训练分为三个步骤:神经网络模型的搭建,预训练,在白细胞数据集训练。
13.步骤2.1:神经网络模型搭建
14.该神经网络由三个部分组成,分别为特征提取器,编码器,辨别区域筛选。
15.步骤2.1.1:特征提取器
16.由于白细胞图像的特征不丰富,这会导致模型难以提取到精确的白细胞图像信息。不同于先前的vit及其改进模型中,将图像直接切割,不进行处理,这会导致切割后的token难以提取局部信息。因此该步骤先将图像数据转化为局部特征数据,采用卷积核为3*3的卷积操作获取图像的特征数据。
17.步骤2.1.2:编码器
18.在wbclformer中有两种编码器,一种为transformer中的编码器,另一种是通过改进的局部编码器。
19.步骤2.1.2.1:transformer编码器
20.该编码器分成两个模块,一个为multi-head self attention layers,即msa,另一个为feed forward network,即ffn;
21.msa:通过输入向量之间的彼此交互学习,通过计算不同对象的不同权重,从而找出更关注的区域信息。
22.ffn:获得加权的向量之后,需要将向量输入到ffn中进行进一步处理。
23.步骤2.1.2.2:局部编码器
24.局部编码器通过将自注意力机制中的全局注意力和cnn相结合,从而达到局部信息和全局信息之间的融合,能够提取到有效的白细胞特征信息。由于自注意力机制是通过学习不同patch之间的相关性,其更关注的是全局的特征信息,而对于白细胞图像来说,其局部性十分重要,因此并在编码器中加入卷积操作来实现局部信息的提取。
25.步骤2.1.3:辨别区域筛选
26.由于相似的图像之间存在的差别特别微小,因此为了能够使得网络能够聚焦于不同图像的差别之处,加入了辨别区域筛选模块,该模块作用是筛选具有相关性的token。
27.步骤2.2:白细胞数据集训练
28.由于wbclformer在小数据集上会产生过拟合的现象,因此该步骤分为俩个过程,在imagenet-2012数据集的预训练和在白细胞数据集的训练;
29.步骤2.2.1:预训练
30.模型训练采用adamw优化算法来调整参数,学习率为5e-4,权重衰减为1e-3,一阶指数衰减率为0.9,二阶指数衰减率为0.999,总共训练150-250轮。
31.步骤2.2.2:白细胞数据集训练
32.将模型的最后一层进行替换,并且使用预训练的模型参数作为训练的初始值,随后进行模型的训练。
33.模型训练采用的是adamw优化算法来调整参数,其训练参数与预训练相同。其学习率调整策略采用了warm-up和余弦退火,目的是为了保证模型的训练稳定性。
34.步骤3:wbclformer模型效果检验
35.为了能够定量的分析模型的泛化能力,需要将训练好的模型在测试集中进行测验,将预测的结果与实际值进行比较,并采用评价指标来进行分析。
36.作为优选,所述的获取白细胞图像作为基础数据集,并且分为训练集和测试集,其具体操作如下:进行白细胞图像数据集得采样,该数据集按照类别以8:2的比例划分训练集和测试集。
37.作为优选,所述的评价指标采用的准确率,精确率,召回率和f1分数;在介绍评价指标之前,先介绍混淆矩阵:
38.·
tp:被模型预测为正类的正样本
39.·
tn:被模型预测为负类的负样本
40.·
fp:被模型预测为正类的负样本
41.·
fn:被模型预测为负类的正样本
42.准确率accuracy:预测正确的结果占总样本的占比,公式如下
[0043][0044]
精确率precision:其含义是在被所有预测为正的样本中实际为正样本的概率。公式如下:
[0045][0046][0047]
召回率recall:其含义为实际为正的样本中被预测为正样本的概率。公式如下:
[0048][0049][0050]
f1分数:为了平衡精确率和召回率,引入了f1分数。公式如下:
[0051][0052]
由于是多分类问题,因此精确率和召回率的计算方式进行改变,首先计算各个类别的精确率和召回率,随后按照权重进行相加,计算平均的精确率和召回率。
[0053]
模型得出四个指标之后,与当前的主流模型进行对比,证明其性能更加优秀。
[0054]
采用本发明方法在不增加模型的参数量情况下,可以实现局部特征和全局特征的结合,丰富白细胞的图像特征。基于已经训练好的wbclformer可以达到最优性能。本发明具
有一下特点:
[0055]
1)该技术提出了局部特征与全局特征相结合的特征提取方式,丰富了白细胞的图像特征,提高了模型的识别准确率。特征提取器和局部编码器通过cnn来进行图像的局部特征提取,编码器中通过自注意力机制来对图像的全局特征提取,通过级联的方式,来将局部特征和全局特征相结合。
[0056]
2)该技术提出了辨别区域筛选模块,通过筛选图像的可辨别区域,提高白细胞的分类准确率。由于骨髓白细胞不同类存在形态相似,因此通过自注意力机制来筛选有区分度的部分,提高分类的准确率。
附图说明
[0057]
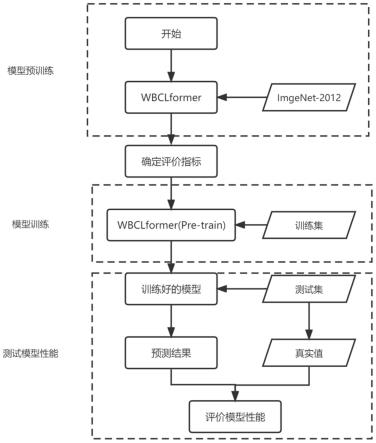
图1是本发明整体流程图;
[0058]
图2是本发明的网络结构图;
[0059]
图3是本发明网络结构中的特征提取器;
[0060]
图4是在本数据集中的结果对比图;
[0061]
图5在公开数据集中的结果对比图。
具体实施方式
[0062]
本发明方法具体包括以下三个步骤:数据集的收集,wbclformer模型的搭建和训练,wbclformer模型效果检验。
[0063]
步骤1:获取白细胞图像作为基础数据集,并且分为训练集和测试集,其具体操作如下:
[0064]
从当地得几家医院进行白细胞图像数据集得采样,总计92335张白细胞图片,一共40个白细胞类别,我们将该数据集按照类别以8:2得比例进行划分,训练集包含73877样本,测试集包含18458个样本。
[0065]
步骤2:wbclformer模型的搭建和训练(图2)
[0066]
wbclformer模型的训练分为三个步骤:神经网络模型的搭建,预训练,在白细胞数据集训练。
[0067]
步骤2.1:神经网络模型搭建
[0068]
该神经网络由三个部分组成,分别为特征提取器,编码器,辨别区域筛选。
[0069]
步骤2.1.1:特征提取器(图3)
[0070]
将输入得图像数据转化为特征数据,具体操作如下:
[0071]
将输入得图像数据通过卷积通道为64,128,256,512的卷积来进行图像的特征提取,其计算公式如下所示:
[0072]
z=conv(bn(relu(x)))
[0073]
其中x为输入的图像,其中c表示的输出的通道数,s是输入图像的步长,relu为其激活函数,bn(batch normalization)为批次归一化,conv为卷积核3*3的卷积操作。
[0074]
步骤2.1.2:编码器
[0075]
在wbclformer中有俩种编码器,一种为transformer中的编码器,另一种是通过改
进的局部编码器。
[0076]
步骤2.1.2.1:transformer编码器(图2.b的左边)
[0077]
该编码器主要分成俩个模块,一个为multi-head self attention layers(msa),另一个为feed forward network(ffn)。
[0078]
msa:通过输入向量之间的彼此交互学习,通过计算计算不同对象的不同权重,从而找出更关注的区域信息,其计算公式如下所示:
[0079][0080]
attention(q,k,v)=cos(q,k)
×v[0081]
q,k,v都是由输入向量的序列x∈rn×d通过线性映射所得到的,q=xwq,k=xwk,v=xwv,其中q表示的查询向量,k表示的是用来匹配q的向量,v表示的内容向量。首先使用softmax函数计算q与k之间的余弦相似度,计算得到每个对象的权重信息,随后将该余弦相似度与v相乘获得最终加权的向量,通过该操作可以对向量进行筛选。
[0082]
ffn:获得加权的向量之后,需要将向量输入到ffn中进行进一步处理,其公式如下:
[0083]
ffn(attn
x
)=mlp(ln(atten
x
))+atten
x
[0084]
atten
x
表示的通过msa获得的加权向量,ln(layer normalization)表示的是层归一化,其作用是防止梯度消失,并且加快收敛速度,该处使用ln是因为层归一化是针对每条数据来进行,这样不会改变数据的分布。mlp是多层感知机,其由俩个线性层组成,第一个线性层将数据的维度从d扩展到3d,第二个线性层将维度减小回d,并且层之间使用gelu激活函数来为网络增加非线性学习的能力。最终通过加上输入的加权向量来实现残差操作,防止模型过深造成梯度消失或梯度爆炸现象。
[0085]
步骤2.1.2.2:局部编码器(图2.b的右边)
[0086]
局部编码器通过将自注意力机制中的全局注意力和cnn相结合,从而达到局部信息和全局信息之间的融合,能够提取到有效的白细胞特征信息。由于自注意力机制是通过学习不同patch之间的相关性,其更关注的是全局的特征信息,而对于白细胞图像来说,其局部性十分重要,因此在编码器中加入卷积操作来实现局部信息的提取,其计算公式如下所示:
[0087]zseq+1
=i2s(dw(s2i(z
seq
)))
[0088]
其中s2i是将序列数据重构为二维图像数据,dw是depth-wise卷积操作,i2s是将二维图像数据转化为序列数据,因此局部编码器通过将序列数据重构为二维数据,并通过卷积操作获得其局部特征。
[0089]
步骤2.1.3:辨别区域筛选
[0090]
由于相似的图像之间存在的差别特别微小,因此为了能够使得网络能够聚焦于不同图像的差别之处,加入了辨别区域筛选模块,该模块作用是筛选具有相关性的token,其计算公式如下所示:
[0091]
atten
final
=πatteni[0092]
atteni表示的是第i层的注意力权重,将各个层的注意力权重相乘,筛选出模型最关注的token,从而进行最后的分类。
[0093]
步骤2.2:白细胞数据集训练
[0094]
由于wbclformer在小数据集上会产生过拟合的现象,因此该步骤分为俩个过程,在imagenet-2012数据集的预训练和在白细胞数据集的训练。
[0095]
步骤2.2.1:预训练(图1中的模型预训练)
[0096]
模型训练采用adamw优化算法来调整参数,学习率为5e-4,权重衰减为1e-3,一阶指数衰减率为0.9,二阶指数衰减率为0.999,总共训练200轮。
[0097]
步骤2.2.2:白细胞数据集训练(图1中的模型训练)
[0098]
将模型的最后一层进行替换,并且使用预训练的模型参数作为训练的初始值,随后进行模型的训练。
[0099]
模型训练采用的是adamw优化算法来调整参数,其训练参数与预训练相同。但是其学习率调整策略采用了warm-up和余弦退火,目的是为了保证模型的训练稳定性。
[0100]
步骤3:wbclformer模型效果检验(图1中的测试模型性能)
[0101]
用训练好的模型在测试集合中预测,将测试结果与真实值按照评价指标的计算方式计算结果。模型性能的评价指标采用accuracy,precision,recall,f1-score四个指标,模型得出四个评价指标后,与当前的主流模型进行对比。如图4所示,本发明提出的模型都处于领先地位,并且为了验证模型的泛化性,还使用了公开的数据集pbc和all-idb来进行验证,如图5所示,其准确率均处于领先低位,实验结果验证了本发明的有效性和泛化性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1