基于目标检测和特征点速度约束的动态视觉SLAM方法
基于目标检测和特征点速度约束的动态视觉slam方法
技术领域
1.本发明涉及一种基于目标检测和特征点速度约束的动态视觉slam方法,属于计算机视觉和深度学习技术领域。
背景技术:
2.同时定位与建图(slam)技术在计算机视觉领域发挥着重要作用,以相机作为主要传感器的slam方案被称为视觉slam。通过视觉slam技术,机器人可以在移动时确定自身位置并构建环境地图,无需事先了解环境信息,在自动驾驶、虚拟现实、室内机器人导航等领域有着巨大的潜在应用。在过去的几十年里,大量学者在这一领域进行了研究,提出了许多先进的slam算法,如orb-slam2、vins-mono等。
3.传统的视觉slam算法大都是基于静态环境的假设,在真实动态场景下系统将难以辨别载体的运动和环境中目标的运动,从而导致定位信息不准确、环境地图构建偏移严重。因此,如何提升视觉slam系统在动态场景下的定位精度和鲁棒性成为当下的研究热点。
4.现有的动态视觉slam方案可以归纳为两类:基于相机运动模型的动态视觉slam方法和不依赖相机自身运动的动态视觉slam方法。基于相机运动模型的方法在计算相机位姿的过程中,需要用到环境中的静态路标点,而剔除环境中动态路标点的过程中需要用到相机的位姿,形成“鸡生蛋、蛋生鸡”的矛盾问题;而不依赖相机自身运动的方法往往采用基于深度学习的动态目标剔除算法,更加侧重于具有先验信息的潜在动态目标判断,存在对目标的真实动态性产生误判的可能。
技术实现要素:
5.本发明的目的是针对当前基于相机运动模型的动态slam方案中存在“蛋生鸡、鸡生蛋”以及基于深度学习的方案中缺乏对潜在目标真实动态性判断的问题,提供一种基于目标检测和特征点速度约束的动态视觉slam方法,利用yolo_v5s模型对室内场景中的潜在动态目标进行检测,提供先验信息,同时通过orb-lk光流金字塔算法判断先验动态目标的真实运动状态,更加合理地剔除动态特征点,提高视觉slam系统在动态环境下的定位精度和鲁棒性。
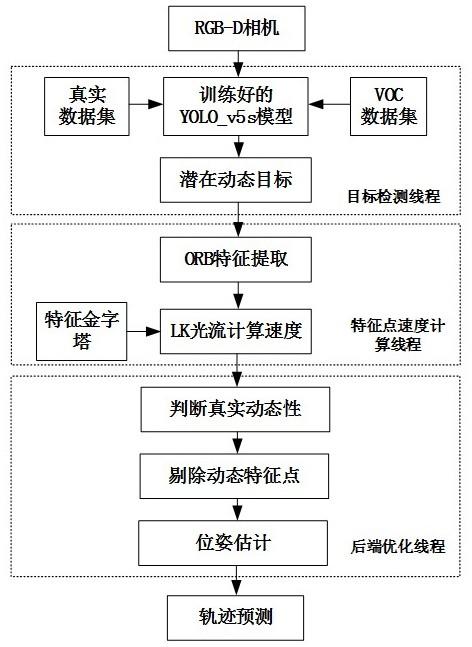
6.上述目的通过以下技术方案实现:一种基于目标检测和特征点速度约束的动态视觉slam方法,该方法包括如下步骤:(1)利用pascal voc 2012数据集和所拍摄的真实场景数据集对yolo_v5s模型进行训练,得到训练好的yolo_v5s模型;(2)通过rgb-d相机采集彩色和深度图像序列,采样频率为30hz,将当前时刻包含彩色和深度图像的当前帧输入到步骤(1)得到的训练好的yolo_v5s模型中,获得潜在动态目标的先验识别框;(3)从步骤(2)当前帧获得的潜在动态目标的先验识别框中提取orb特征点,当采
集到包含彩色和深度图像的下一帧之后,通过lk光流算法追踪两帧之间的特征点;(4)引入特征金字塔,从图像多尺度改进lk光流算法,并计算两帧之间特征点的相对运动速度;(5)通过步骤(4)中的特征点相对运动速度判断潜在动态目标的真实动态性,根据潜在动态目标在场景中的真实动态性剔除图像中的动态特征点;(6)剔除步骤(5)中的动态特征点后,利用剩余的静态特征点进行特征匹配与相机位姿估计,最终得到相机的最优运动轨迹。
7.所述的基于目标检测和特征点速度约束的动态视觉slam方法,步骤(1)的具体方法是:首先选择pascal voc 2012数据集中对yolo_v5系列中网络深度最小的yolo_v5s模型进行第一次训练,该数据集由现实世界中的对象类组成;然后采用所拍摄的真实场景数据集对第一次训练后的模型进行第二次训练,目标类别设定为数据集中潜在的动态对象。
8.所述的基于目标检测和特征点速度约束的动态视觉slam方法,步骤(2)的具体方法是:首先通过rgb-d相机以30hz的频率来采集彩色和深度图像序列,将包含彩色和深度图像的当前帧输入到步骤(1)里训练好的yolo_v5s模型中;然后yolo_v5s模型通过focus结构对图片进行切片操作,并经过cbl模块进行卷积操作;在backbone中,使用带残差结构的csp1_x,在neck中使用csp2_x;接着将neck中输出的特征图输入到预测层部分,采用ciou_loss bounding box损失函数最小化预测框和目标框之间的归一化距离;然后采用加权非极大值抑制的方式对多目标框进行筛选;最终得到潜在动态目标的先验识别框的位置以及顶点坐标。
9.所述的基于目标检测和特征点速度约束的动态视觉slam方法,步骤(3)的具体方法是:先通过orb算法提取经过畸变矫正、去噪处理的图像中的特征点。然后利用帧间像素的相似性,通过lk光流求解位移向量以实现特征点附近一个矩形窗口的匹配与跟踪。最后通过最小化窗口内的像素灰度差平方和来求解像素点光流d=[d
x
, dy]
t
,如下式所示:其中,x, y为特征邻域内的像素点,d
x
, dy分别表示x和y方向上的光流,[
·
]
t
表示转置, 表示最小化d
x
,dy的函数,u
x
, uy分别表示像素点的横纵坐标,m
x
, my为以像素点中心的矩形窗口长宽,ii(x,y)表示第i帧像素点的灰度值,i
i+1
(x+d
x
,y+dy)表示第i+1帧像素点的灰度值。
[0010]
步骤(3)中所述orb算法特征提取的具体方法是,提取潜在动态目标检测框内的fast特征点,定义图像矩为:其中,a,b为矩的阶次,m
ab
为a+b阶矩,利用图像矩计算质心坐标c,并定义方向因子
为图像块中心到质心的方向角度θ:其中m
10
为a=1,b=0时的图像矩,m
01
为a=0,b=1时的图像矩,m
00
为a=0,b=0时的图像矩,arctan表示计算反正切;然后引入旋转因子提取brief描述子,其核心思想是在特征点周围选取n个点对, 并把这n个点对的比较结果组合起来作为描述子,最终得到有旋转不变性的orb特征点。
[0011]
所述的基于目标检测和特征点速度约束的动态视觉slam方法,步骤(4)的具体方法是:引入特征金字塔模型,从图像多尺度改进lk光流算法,最终求解光流d,确保两帧间的特征点在不同分辨率下均构成匹配点对;将前一时刻的彩色图像和当前时刻的彩色图像进行金字塔分层,第s层图像的光流分为猜测光流gs=[g
x
, gy]
t
与剩余光流rs=[r
x
, ry]
t
(s=1,
…
,l-1,l),其中,g
x
, gy分别表示x和y方向上的猜测光流,r
x
, ry分别表示x和y方向上的剩余光流,s表示第s层金字塔,l表示最上层金字塔;定义猜测光流为上一层传递至下一层的光流,剩余光流为除猜测光流的剩余光流,根据猜测光流定义,最上层,即第l层猜测光流g
l
为:计算最上层剩余光流r
l
,根据图像金字塔相邻两层间缩放倍数为2的关系,将第l层剩余光流与猜测光流之和作为第(l-1)层猜测光流g
l-1
,即:计算第(l-1)层剩余光流r
l-1
,逐层递推至第0层,计算第0层的猜测光流g0和剩余光流r0,获得最终光流值d为:从图像多尺度求解光流,最终解算得到特征点的相对运动速度。
[0012]
所述的基于目标检测和特征点速度约束的动态视觉slam方法,步骤(5)的具体方法是:在真实场景中,由于存在处于准静态的目标在一段时间内是运动的;同时,处于动态的目标在一段时间内却是静止的这两种情况,对于真实场景中的目标需判断其真实动态性,通过步骤(3)中计算的特征点相对运动速度判断目标的真实动态性,如下式所示:其中,表示第i帧图像特征点k的运动速度,表示第i帧图像整体场景的运动速度,status表示当前特征点k的运动状态,true表示真实运动,false表示相对静止。设定为阈值,当特征点的运动速度大于阈值时,将该特征点视为真实动态特征点并剔除。
[0013]
所述的基于目标检测和特征点速度约束的动态视觉slam方法,步骤(6)的具体方法是:
从图像中剔除步骤(5)中的真实动态特征点,并利用剩余的静态特征点在两帧图像中进行特征匹配;然后利用ba的方法对相机的6自由度位姿和3d路标点同时进行优化,利用最小化重投影误差的方式计算当前帧的相机位姿和路标点的坐标,目标函数如下式所示:其中,z
i,j
表示路标点pj在第i帧图像中特征点的像素坐标,f(*)为映射函数,t
i,i-1
表示第i-1帧到第i帧的变换矩阵。进一步利用高斯—牛顿方法对目标函数进行求解。
[0014]
同时引入滑动窗口的策略与回环检测算法来校正漂移的位姿优化得到相机的位姿估计,最终得到相机的最优运动轨迹。
[0015]
有益效果:(1)本发明提出的通过yolo_v5s模型对场景中的潜在动态目标进行识别,可以为视觉slam前端的特征匹配环节提供先验信息,而且相比于基于语义分割的ds-slam等方法具有较快的运行速度,提高了动态slam系统的实时性;(2)本发明提出的orb-lk光流金字塔算法,能够从图像多尺度求解光流,提高特征点匹配精度与鲁棒性;(3)本发明提出的将深度学习和特征点速度约束相结合的方法,一方面通过yolo_v5s模型来判断具有先验信息的潜在动态目标,另一方面针对场景的真实运动状态,利用orb-lk光流金字塔算法来判断潜在动态目标的真实动态性,更加合理地对特征点进行剔除或保留,大大提升了视觉slam系统在动态环境下的定位精度。
附图说明
[0016]
图1 本发明原理示意图;图2 基于yolo_v5s模型的潜在动态目标检测线程;图3 基于orb-lk光流金字塔的特征点速度计算线程;图4 真实场景中判断目标真实动态性可视化结果,其中,(a)表示拿起的水杯,(b)表示移动的垃圾桶,(c)表示推动的椅子,(d)表示浏览页面的显示器;图5tum数据集下剔除目标真实动态特征点过程,其中,(a)表示通过yolo_v5s模型检测出的潜在动态目标,(b)表示通过orb-lk光流金字塔判断潜在动态目标的真实动态性,(c)表示剔除动态特征点;图6 orb-slam2和本发明算法的绝对轨迹误差对比,其中,(a)表示orb-slam2在序列fr3_walking_xyz下的绝对轨迹误差,(b)表示orb-slam2在序列fr3_walking_rpy下的绝对轨迹误差,(c)表示orb-slam2在序列fr3_walking_halfsphere下的绝对轨迹误差,(d)本发明方法在序列fr3_walking_xyz下的绝对轨迹误差,(e)表示本发明方法在序列fr3_walking_rpy下的绝对轨迹误差,(f)表示本发明方法在序列fr3_walking_halfsphere下的绝对轨迹误差。
具体实施方式
[0017]
以下将结合附图,对本发明的技术方案进行详细说明。
[0018]
如图1所示,本发明提供了一种基于目标检测和特征点速度约束的动态视觉slam方法。
[0019]
具体步骤如下:(1)利用pascal voc 2012数据集和500张真实场景数据集对yolo_v5s模型进行训练,得到训练好的yolo_v5s模型;(2)通过rgb-d相机采集彩色和深度图像序列,采样频率为30hz,将当前时刻包含彩色和深度图像的当前帧输入到步骤(1)得到的训练好的yolo_v5s模型中,获得潜在动态目标的先验识别框;(3)从步骤(2)当前帧获得的潜在动态目标的先验识别框中提取orb特征点,当采集到包含彩色和深度图像的下一帧之后,通过lk光流算法追踪两帧之间的特征点;(4)引入特征金字塔模型,从图像多尺度改进lk光流算法,确保步骤(3)中两帧间的特征点在不同分辨率下均构成匹配点对,并计算两帧之间特征点的相对运动速度;(5)通过步骤(4)中的特征点相对运动速度判断潜在动态目标的真实运动状态,根据潜在动态目标在场景中的真实动态性更加合理地剔除图像中的动态特征点;(6)剔除步骤(5)中的动态特征点后,利用剩余的静态特征点进行特征匹配与相机位姿估计,最终得到最优运动轨迹。
[0020]
进一步地,步骤(1)中,为了提高算法的实时性,选择yolo_v5系列中深度最小、特征图宽度最小的yolo_v5s模型,首先通过pascal voc 2012数据集对其进行第一次训练。该数据集由现实世界中的20个对象类组成,对于大多数环境,可能出现的动态目标都包含在该数据集中。为了提高算法在真实场景下的识别能力,通过rgb-d相机采集500张真实场景照片,对其进行分类和标注,并划分训练集和测试集,其中400张作为训练集,100张作为测试集。为了减轻网络权重,目标类别设定为数据集中潜在的动态对象,共7类:人、椅子、杯子、垃圾桶、显示器、键盘、鼠标。训练过程如图2中的上半部分。
[0021]
进一步地,步骤(2)中,如图2下半部分所示,通过rgb-d相机以30hz的频率来采集彩色和深度图像序列,当获取到包含彩色和深度图像的当前帧后,使用步骤(1)中训练好的yolo_v5s模型对当前帧进行目标检测。yolo_v5s模型中通过focus结构对图片进行切片操作,输入一个608
×
608
×
3的图片,经过切片操作后,变成304
×
304
×
12的特征图,然后经过cbl模块进行卷积操作,变成304
×
304
×
24的特征图。yolov5s模型在backbone和neck中使用了两种不同的csp,在backbone中,使用带有残差结构的csp1_x,因为backbone网络较深,残差结构的加入使得层和层之间进行反向传播时,梯度值得到增强,有效防止网络加深时所引起的梯度消失,得到的特征粒度更细;在neck中使用csp2_x,相对于单纯的cbl将主干网络的输出分成了两个分支,后将其concatenate,使网络对特征的融合能力得到加强,保留了更丰富的特征信息。最终输出潜在动态目标的先验识别框的位置以及顶点坐标。
[0022]
进一步地,步骤(3)中,首先提取潜在动态目标检测框内的fast特征点,定义图像矩为:
其中,a,b为矩的阶次,m
ab
为a+b阶矩,x, y为特征邻域内的像素点,利用图像矩计算质心坐标c,并定义方向因子为图像块中心到质心的方向角度θ:其中m
10
为a=1,b=0时的图像矩,m
01
为a=0,b=1时的图像矩,m
00
为a=0,b=0时的图像矩,arctan表示计算反正切;然后引入旋转因子提取brief描述子,其核心思想是在特征点周围选取n个点对, 并把这n个点对的比较结果组合起来作为描述子,最终得到有旋转不变性的orb特征点。
[0023]
通过orb算法提取经过畸变矫正、去噪处理的图像中的特征点后,利用帧间像素的相似性,通过lk光流求解位移向量以实现特征点附近一个矩形窗口的匹配与跟踪。最后通过最小化窗口内的像素灰度差平方和来求解像素点光流d=[d
x
, dy]
t
,如下式所示:其中,d
x
, dy分别表示x和y方向上的光流,[
·
]
t
表示转置,表示最小化d
x
,dy的函数,u
x
, uy分别表示像素点的横纵坐标,m
x
, my为以像素点中心的矩形窗口长宽,ii(x,y)表示第i帧像素点的灰度值,i
i+1
(x+d
x
,y+dy)表示第i+1帧像素点的灰度值。
[0024]
进一步地,步骤(4)中,为解决窗口选取大小对特征点匹配精度和鲁棒性的矛盾,引入特征金字塔模型,从图像多尺度改进lk光流算法,最终求解光流d,确保两帧间的特征点在不同分辨率下均构成匹配点对。将前一时刻的彩色图像和当前时刻的彩色图像进行金字塔分层,第s层图像的光流分为猜测光流gs=[g
x
, gy]
t
与剩余光流rs=[r
x
, ry]
t
(s=1,
…
,l-1,l),其中,g
x
, gy分别表示x和y方向上的猜测光流,r
x
, ry分别表示x和y方向上的剩余光流,s表示第s层金字塔,l表示最上层金字塔。定义猜测光流为上一层传递至下一层的光流,剩余光流为除猜测光流的剩余光流,根据猜测光流定义,最上层,即第l层猜测光流g
l
为:计算最上层剩余光流r
l
,根据图像金字塔相邻两层间缩放倍数为2的关系,将第l层剩余光流与猜测光流之和作为第(l-1)层猜测光流g
l-1
,即:计算第(l-1)层剩余光r
l-1
,逐层递推至第0层,计算第0层的猜测光流g0和剩余光流r0,获得最终光流值d为:特征点速度计算线程如图3所示,通过引入orb-lk金字塔算法,从图像多尺度求解光流,确保两帧间的特征点在不同分辨率下均构成匹配点对,最终解算得到特征点的相对运动速度。
[0025]
进一步地,步骤(5)中,在大部分场景下,经过深度学习目标检测的物体(如图4中的水杯、垃圾桶、椅子、显示器等)处于准静态情况,大部分动态slam方法没有判断其真实动态性,直接将其作为静态特征保留。然而在真实场景中,由于存在人拿起杯子喝水(图4
(a))、移动垃圾桶(图4(b))和椅子(图4(c))、浏览显示器上的网页(图4(d))等情况,在一段时间内是运动的,需要判断其真实动态性。通过步骤(4)中计算的特征点相对运动速度判断目标的真实动态性,如下式所示:其中,表示第i帧图像特征点k的运动速度,表示第i帧图像整体场景的运动速度,status表示当前特征点k的运动状态,true表示真实运动,false表示相对静止。设定为阈值,当特征点的运动速度大于阈值时,将其视为真实动态特征点并剔除。
[0026]
从图像中剔除步骤(5)中的真实动态特征点,并利用剩余的静态特征点在两帧图像中进行特征匹配,然后通过ba的方法对相机的6自由度位姿和3d路标点同时进行优化,利用最小化重投影误差的方式计算当前帧的相机位姿和路标点的坐标,目标函数如下式所示:其中,z
i,j
表示路标点pj在第i帧图像中特征点的像素坐标,f(*)为映射函数,t
i,i-1
表示第i-1帧到第i帧的变换矩阵。进一步利用高斯—牛顿方法对目标函数进行求解,同时引入滑动窗口的策略与回环检测算法来校正漂移的位姿优化得到相机的位姿估计,最终得到相机的最优运动轨迹。
[0027]
仿真实验:基于目标检测和特征点速度约束的动态视觉slam方法实验的仿真环境为:gpu nvidia rtx3060,cpu r7-5800h,ubuntu 20.04 lts,cuda 11.0,pytorch 1.8.1。
[0028]
选择公开数据集tum dynamic objects rgb-d(30hz)进行仿真,对于tum dynamic objects数据集,选择行走(freiburg3_walking)序列进行评估,该序列对应着三种相机运动方式:(1)xyz:相机沿x,y,z轴运动;(2)halfsphere:相机沿直径1m的半球面运动;(3)rpy:相机沿滚动、俯仰、偏航轴转动。在序列中,两个人在房间里随机运动并从摄像机前面经过,最终坐在椅子上,整个过程是动态的。
[0029]
为了验证本发明算法在动态环境下的性能,选择tum数据集中的动态子序列分别对orb-slam2和本发明方法进行比较。图5显示了所提算法在tum数据集下剔除目标真实动态特征点过程,其中,(a)表示通过yolo_v5s模型检测潜在动态目标,(b)表示通过orb-lk光流金字塔判断潜在动态目标的真实动态性,(c)表示剔除动态特征点,保留静态特征点;图6显示了orb-slam2和本发明方法的绝对轨迹误差,其中,(a)(b)(c)分别表示orb-slam2在序列fr3_walking_xyz、fr3_walking_rpy和fr3_walking_halfsphere的绝对轨迹误差,(d)(e)(f)分别表示本发明方法在对应序列下的绝对轨迹误差。表1显示了orb-slam2和本发明方法的绝对轨迹误差(ate)的均方根误差(rmse),通过量化的对比结果表明本发明明显提升了视觉slam系统在动态环境下的定位精度。
[0030]
表1 orb-slam2和本发明方法的绝对轨迹误差的rmse(m)
由此可以看出,本发明引入基于深度学习的潜在动态目标检测线程与基于orb-lk光流金字塔的特征点速度计算线程,通过yolo_v5s模型对场景中潜在的动态目标进行识别判断提供先验信息;同时通过orb-lk光流金字塔计算图像中特征点的相对速度,并根据特征点速度约束判断目标的真实动态性,更加合理地剔除动态特征点,大大提高视觉slam系统在动态环境下的定位精度和鲁棒性。
[0031]
如上所述,尽管参照特定的优选实施例已经表示和表述了本发明,但其不得解释为对本发明自身的限制。在不脱离所附权利要求定义的本发明的精神和范围前提下,可对其在形式上和细节上作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1