一种用于脉动阵列的数据调度方法与流程
1.本发明涉及神经网络技术领域,尤其涉及一种用于脉动阵列的数据调度方法。
背景技术:
2.深度神经网络模型规模以及数据集的不断增大,对硬件访存带宽的需求急剧增大,访存瓶颈日益加剧,采用脉动阵列加速矩阵乘/卷积运算是学术界、工业界的常见方法之一。脉动阵列的特点是数据在阵列内计算单元之间流动,能有效提升数据复用次数,减少访存量,进而降低带宽需求。
3.基于申威-ai加速芯片结构,提出用于脉动阵列的多样式调度策略。申威-ai芯片的具备两级阵列结构:m个处理核心,每个核心具备一个n
×
n维度的脉动阵列计算。两级阵列结构为卷积与矩阵乘算法的映射计算提供了多样式的映射空间。然而,目前缺少一种进一步增加片上数据的重用率,减少与片外的重复数据交互的数据调度方法,以进一步降低带宽需求,提升硬件加速器的性能。
技术实现要素:
4.本发明的目的是为了解决上述现有技术存在的问题,提供一种用于脉动阵列的数据调度方法,其能够有效提升片上数据的复用次数,降低带宽需求,可以有效提升硬件加速器性能。
5.本发明的目的是通过以下技术方案实现的:一种用于脉动阵列的数据调度方法,定义卷积计算/矩阵乘计算的公式为a*b=c,a、b、c均为多维向量,所述数据调度方法包括:步骤1,令待卷积/待矩阵乘的数据a分布在m个核心上;步骤2,将数据b广播给m个核心,m个核心每轮得到相同的b进行计算;步骤3,当每个核心上的分布式数据a与所有的b计算完成,将结果写回主存;步骤4,重复步骤1-3进行数据a下一部分的计算。
6.上述方法对分布式的数据a复用率最高,即不会出现片外的重复访存;广播数据b出现了重复的片外访存,但考虑到其访存模式为广播,对访存带宽的需求较低。当然,该方法也可以是a数据广播,而b数据分布。
7.作为本发明优选,若数据a合并方向包括n行/列数据,则所述数据调度方法包括:步骤1,将m个核心分为g组,以n组核心为一个单元,每组核心数量对应每行/列上数据a的数量;步骤2,令待卷积/待矩阵乘的数据a分布在m个核心上;步骤3,将每列/行数据b分别广播给g/n个单元,令数据b在同一单元中的n组核心之间广播;步骤4,每一组核心完成一轮计算后,在组内的核心之间交换数据a,直至得到完整计算结果;
步骤5,每个核心将完整计算结果写回主存。
8.上述方法针对仅当数据a在合并方向尺寸较大的情况,考虑切分数据a的合并方向(如卷积计算中,特征图切分通道方向进行分组),每个核心从主存获取的分布式数据a无法得到完整计算结果,需要核间交换分布式数据a继续进行合并方向的计算,得到完整结果后写回主存。和片外访存带宽相比,片上网络的访存带宽较大,核间数据交换可以在不影响计算效率的基础上大幅度提升数据的复用率,降低片外带宽需求。广播数据b根据分布式数据a的分布方式进行部分的行广播或列广播,进一步减少了片外访存。同样的,该方法也适用于仅当数据b在合并方向尺寸较大的情况。
9.作为本发明优选,若数据a和b合并方向均包括多行/列数据,则所述数据调度方法包括:步骤1,令待卷积/待矩阵乘的数据a和b均分布在m个核心上;步骤2,每个核心分别对不同的a和b进行计算;步骤3,将m个核心的计算结果通过核间通信,合并得到完整结果后写回主存。
10.上述方法针对当数据a和数据b的合并方向尺寸都较大,需要切分两者的合并方向,即两种数据都需要分布式的放在m个从核上,即每个核拿到的数为a0b0,a1b1…ꢀam-1bm-1
计算得到中间结果后通过核间通信,合并得到完整结果后写回主存。
11.本发明的优点是:利用广播机制和片上访存机制,减少片外数据的重复访存和中间值的访存,提升片上数据的复用次数,降低带宽需求,有效提升硬件加速器性能。
附图说明
12.图1为本发明一种用于脉动阵列的数据调度方法的第一种策略的示意图;图2为本发明一种用于脉动阵列的数据调度方法的第二种策略的示意图;图3为本发明一种用于脉动阵列的数据调度方法的第三种策略的示意图。
具体实施方式
13.下面将结合附图和具体实施方式对本发明做进一步的详细说明。
14.本发明提供一种用于脉动阵列的数据调度方法,结合卷积/矩阵乘在脉动阵列上的计算特征,针对待卷积数据/待矩阵乘数据a和b,主要有三种调度策略:1、a数据分布+b数据广播(或a数据广播+b数据分布);2、a数据分组分布+b数据分组广播(或a数据分组广播+b数据分组分布);3、a数据分布+b数据分布。
15.定义卷积计算/矩阵乘计算的公式为a*b=c,a、b、c均为多维向量,以下分别对三种调度策略进行介绍。
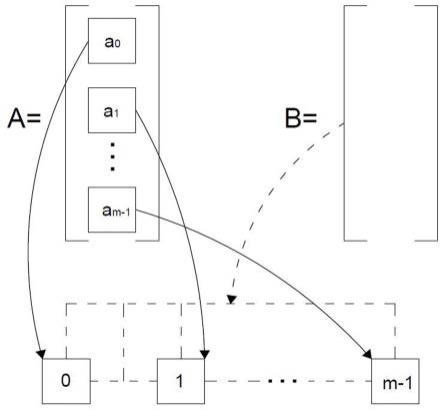
16.以图1为例进行说明,第一种调度策略包括如下步骤:步骤1,令待卷积/待矩阵乘的数据a分布在m个核心上,即每个核心拿到的数据分别为a0,a1ꢀ…ꢀam-1
;步骤2,将数据b广播给m个核心,m个核心每轮得到相同的b进行计算,即每个核心的计算过程为a0*b=c0,a1*b=c1ꢀ…ꢀam-1
*b=c
m-1
。
17.步骤3,当每个核心上的分布式数据a与所有的b计算完成,将结果写回主存;步骤4,重复步骤1-3进行数据a下一部分的计算,例如继续进行a0'*b=c0',a1'*b=
c1'
…ꢀam-1
'*b=c
m-1
'。
18.上述方法对分布式的数据a复用率最高,即不会出现片外的重复访存,所以数据a一般为矩阵相对较大的数据;广播数据b出现了重复的片外访存,所以数据b一般为矩阵相对较小的数据,同时考虑到其访存模式为广播,对访存带宽的需求较低。
19.第二种调度策略针对数据a合并方向的尺寸较大的情况,考虑切分数据a的合并方向(如卷积计算中,特征图切分通道方向进行分组),每个核心从主存获取的分布式数据a无法得到完整计算结果,需要核间交换分布式数据a继续进行合并方向的计算,得到完整结果后写回主存。以图2为例进行说明,完整的数据a包括两行数据,沿其合并方向切分为两组,即a
0-a3为一组,a
4-a7为一组,两组核心分别计算1/2的数据a,该方法包括如下步骤:步骤1,将m个核心分为g组,以n组核心为一个单元,每组核心数量对应每行/列上数据a的数量;图2中以两组核心进行说明,核0、1、2、3为一组,以核4、5、6、7为一组,两组构成一个单元。
20.步骤2,令待卷积/待矩阵乘的数据a分布在m个核心上,即核0-7分别分到数据a
0-a7。
21.步骤3,将每列/行数据b分别广播给g/n个单元,令数据b在同一单元中的n组核心之间广播;即核0-3得到数据b
1-b3,同时两组之间通过广播,令核4-7也得到数据b
1-b3。
22.步骤4,每一组核心完成一轮计算后,在组内的核心之间交换数据a,直至得到完整计算结果;以下依次为核0-3进行的四轮计算:第一轮计算,a0*b0,a1*b1',a2*b2",a3*b3''';之后核间交换数据a,例如数据a整体右移;第二轮计算,a3*b3,a0*b0',a1*b1",a2*b2''';数据a继续整体右移;第三轮计算,a2*b2,a3*b3',a0*b0",a1*b1''';数据a继续整体右移;第四轮计算,a1*b1,a2*b2',a3*b3",a0*b0''''。
23.步骤5,每个核心将完整计算结果写回主存;经过上述四轮计算后,四个核心均得到了完整的计算结果,可将完整计算结果写回主存,最终数据a的计算结果由以上两组核心的计算结果合并得到。
24.上述方法中的数据a一般为图片矩阵,其矩阵较大,对访存带宽要求较高,我们利用核间交换对数据a进行复用,因为和片外访存带宽相比,片上网络的访存带宽较大,核间数据交换可以在不影响计算效率的基础上大幅度提升数据的复用率,降低片外带宽需求。而数据b一般为卷积核矩阵,其矩阵较小,对访存带宽要求较低,所以我们利用片外广播来复用数据b,同时根据分布式数据a的分布方式进行部分的行广播或列广播,以进一步减少了片外访存。
25.第三种调度策略针对数据a和b的合并方向尺寸均较大的情况,以图3为例,第三种调度策略包括如下步骤:步骤1,令待卷积/待矩阵乘的数据a和b均分布在m个核心上,即每个核心拿到的数据a分别为a0,a1ꢀ…ꢀam-1
,拿到的数据b分别为b0,b1ꢀ…ꢀbm-1
;步骤2,每个核心分别对不同的a和b进行计算,即每个核心上进行的计算分别为a0b0,a
1 b1…ꢀam-1 b
m-1
,也即每个核心上仅能计算部分值,均无法得到完整结果;步骤3,将m个核心的计算结果通过核间通信,合并得到完整结果后写回主存。
26.上述方法主要利用了核间通信,将计算得到的中间结果进行合并,以得到完整结果。
27.以上所述,仅为本发明较佳的具体实施方式,该具体实施方式是基于本发明整体构思下的一种实现方式,而且本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1