基于深度学习去除视觉SLAM前端动态特征点的方法
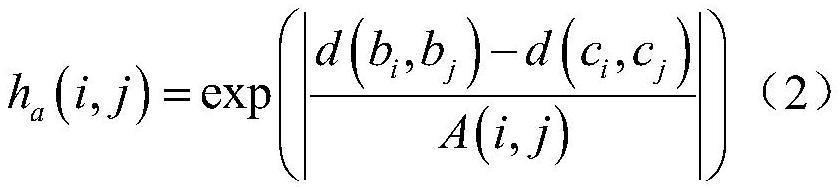
本发明属于视觉slam,涉及基于深度学习去除视觉slam前端动态特征点的方法。
背景技术:
1、对于同时定位与地图构建任务,视觉slam是最好的选择之一。近30年来,许多优秀的学者对视觉slam领域作出了卓越的贡献,使得现阶段视觉slam已经取得很好的表现,并已部分投入使用。例如orb-slam2,rgb-d slam-v2。由于其具有传感器采集速度快、成本低,能满足实时运行和具有较高的准确率等优点而被广泛应用。然而,orb-slam2和现有大多优秀算法一样,在现实场景的应用上依然存在一些问题。现有的算法大多为了方便计算,常对外部环境作静态假设,忽略了真实环境中动态物体对slam算法精度的影响,所使用的静态模型无法适应复杂多变的环境。因此,研究动态环境下的slam算法显得尤为重要。
技术实现思路
1、为全面解决上述问题,尤其是针对现有技术所存在的不足,本发明提供了基于深度学习去除视觉slam前端动态特征点的方法能够全面解决上述问题。
2、为实现上述目的,本发明采用以下技术手段:
3、基于深度学习去除视觉slam前端动态特征点的方法,包括下述步骤:
4、step1:使用深度相机获取彩色和深度图像,对采集到的rgb图像均匀化提取orb特征点,并使用yolov3目标检测算法获取边界框检测结果;
5、step2:将边界框检测结果分类,分为动态物体和静态物体并对其建立集合,筛选出仅存在于动态物体检测框内的特征点并剔除;
6、step3:根据提取的orb特征点,在此基础上利用基于多视角几何约束的动态物体检测算法筛选出剩余动态特征点并剔除;
7、step4:对剩下的静态特征点进行特征匹配,得到最佳匹配特征点并进行相机位姿估计,得到准确的相机运动结果,从而实现准确的面向动态场景下的视觉slam。
8、本发明进一步的优选方案:step1中,均匀化提取orb特征点的方法如下:
9、首先构建图像金字塔模型将原始图像作为最底层图像g0,利用高斯核对其进行卷积,然后对卷积后的图像进行下采样得到上一层图像g1,以此图像作为输入,重复卷积和下采样操作得到更上一层图像,反复迭代多次,形成一个金字塔形的图像数据结构;
10、再将原始的rgb图像分成若干个层,在各个层上进行fast角点的提取,然后计算图像金字塔每层需要提取的特征点数量xk,公式如下:
11、
12、式(1)中,x代表各层设置的各层的总特征点数量,k代表当前层数,α代表图像金字塔各层的图像的缩放因子,l代表图像金字塔总层数;
13、其次对构建的图像金字塔每一层都均匀地划分出30×30像素的格子,单独对每个格子提取fast角点,对于一些无法提取fast角点的格子,采用降低fast阈值的方法,从而保证一些纹理较弱的区域也可以提取到fast角点;
14、最后对于提取到的大量fast角点,使用基于四叉树的方法,均匀地选取xk个fast角点。
15、本发明进一步的优选方案:step1中,yolov3目标检测算法包括以下内容:
16、当获取到深度相机采集到的rgb图像后,使用yolov3网络模型对输入的rgb图像进行目标检测,输入图像经过全卷积神经网络得到3种尺度的输出特征图,在输出特征图上划分cell,对于ground truth box中心所在的cell,用于预测ground truth box框中的目标;
17、该cell先计算事先指定的3种anchor及相应的ground truth box的iou,选出iou最高的anchor,然后用选出的anchor生成需要的检测框,最后根据该检测框对不同类别的置信度来检测物体的类别;
18、yolov3使用了darknet-53的前52层,是一个全卷积网络,并且大量使用残差的跳层连接来降低池化带来的梯度负面效果。
19、本发明进一步的优选方案:step2中,剔除动态特征点的方法如下:
20、将边界框检测结果按照动态物体和静态物体分类,假设输入yolov3网络模型的第n帧rgb图像的动态物体像素点集合为:其中为第n帧图像中的动态物体检测框内的第i个像素点,而静态物体像素点集合为第n帧图像中的静态物体检测框内的第j个像素点;第n帧图像中提取到的特征点集合为其中为第n帧图像中的第m个特征点;若且则判断该特征点为动态特征点并从集合中删除之。
21、本发明进一步的优选方案:step3中,基于多视角几何约束的动态物体检测算法筛选出剩余动态特征点,具体方法如下:
22、分别选取相邻帧a1和a2的上三个特征点,并将其构成三角形δb1b2b3和三角形δc1c2c3,顶点b1、b2、b3为a1中的三个特征点,其分别与a2中的三个特征点c1、c2、c3相匹配,d为特征点之间的欧氏距离,定义几何约束得分函数:
23、
24、式(2)中,d(p,q)表示特征点p,q之间的欧式距离;a(i,j)代表三角形对应边之间的平均距离,可以表示为:
25、
26、由于相邻帧间的采样时间很短,由相机位姿变换引起的相机投影移动就变得非常小;
27、倘若场景中出现动态目标,那么由(2)式计算得到的几何约束得分函数值将会异常的大;
28、然而,几何约束得分涉及到两对特征点,真正的动态特征点难以确定,鉴于此,提出一种特征点双向打分方法来识别场景中真正的特征点,具体为:
29、定义一个特征点异常得分值,当三角形的一条边出现异常时,则将这条边上两个特征点的异常得分值都各加1分,这样,真正的动态特征点和静态特征点的异常得分值将会出现明显差异,可知,一个特征点的异常分值代表有多少个特征点判断该点为异常的动态点,特征点的异常分值的几何表达为:
30、
31、式(4)中,qbc(i)为第i个特征点的异常分值;s(i,j)表示异常分值增量:
32、
33、式(5)中,β为几何约束平均得分比例因子,其控制几何约束严格程度;as表示图像上各点对之间几何得分平均分值:
34、
35、式(6)中,n表示图像特征点匹配点对个数;qx(i,j)表示i,j两匹配特征点的几何得分值;表示几何误差权重因子,用以降低较大几何约束得分值对得分均值计算的影响:
36、
37、式(7)中,θth为设定的几何得分阈值,其代表当一个特征点的精度和几何约束得分的总值大于该阈值时,将不会参与as的计算;
38、设置自适应动态分割阈值为λt,其中t为提取的特征点总数;
39、qbc(i)>λt (8)
40、式(8)中,λ设置为60%,当60%的特征点认为一个特征点为异常时,则认为该特征点为动态特征点。
41、本发明进一步的优选方案:step4中,特征匹配与位姿估计的方法如下:
42、基于上述提取到的静态特征点,对相邻关键帧间特征点做特征匹配;
43、帧间图像的位姿变换关系可以由基本矩阵表示,通常使用ransac算法来估算,对错误数据进行过滤;
44、ransac算法中评估的模型就是帧间的位姿估计,在进行位姿估计求解时,通过不断地将错误匹配设置为局外点,配合位姿求解算法,得到最优的位姿估计。
45、本发明进一步的优选方案:动态物体包括人、猫、狗、车等。
46、本发明具有以下有益效果:
47、(1)、本发明将深度学习中的yolov3目标检测算法融入到视觉slam前端,检测场景中动态目标并剔除动态特征点,相对于现有主流的一些视觉slam方法,如rgb-dslam-v2,orb-slam2等,速度方面得到了大幅提升;
48、(2)、在提取动态特征点方面,将目标检测得到的动静态特征点取差集,然后再利用多视角几何约束的动态物体检测算法进一步剔除剩余动态特征点,此方法不仅能够精确地提取到场景中的动态特征点,还能够更好的保留住较多的高质量静态特征点用于位姿估计;
49、(3)、相对于传统视觉slam,本发明中所述的方法更适用于实际的场景,在动态场景下定位精度得到大幅提升。
- 还没有人留言评论。精彩留言会获得点赞!