一种基于多通道矩阵随机自编码器的自动特征提取方法
1.本发明属于机器学习和数据挖掘领域,涉及一种基于多通道矩阵随机自编码器的自动特征提取方法。
背景技术:
2.自编码器作为一种有效的自动特征提取方法,在机器学习和数据挖掘领域有着广泛的应用。特别地,基于单隐层前馈神经网络的随机自编码器(rnn-ae)具有快速的学习速度,更少的人工干预以及更好的特征学习能力,因此受到了广泛的研究与应用。然而目前的rnn-ae在进行自动特征提取时,需要将输入数据进行向量化,如大小为h
×
w的灰度图,在进行自动特征提取时,需要转化为(h*w)
×
1的向量。这种方式严重破坏了数据之间的结构信息,尤其对于多通道信号数据,如多通道脑电信号、视频序列等,该问题会严重影响最终rnn-ae自动提取的特征的表征性。目前缺少有效处理复杂高维多通道数据的随机自编码器,通道信息的遗漏无疑限制了自编码器在特征提取上的性能,导致其应用受限。
技术实现要素:
3.为了克服上述rnn-ae存在的问题,本发明提出了一种基于多通道矩阵随机自编码器(dmmrae)的自动特征提取方法,该方法针对多通道矩阵数据(设大小为d1×
d2×
k,k是通道数,d1是行数即长度,d2是列数即宽度),以矩阵形式分别获取各通道的隐藏层输出,并求和作为最终网络的隐藏层输出。然后根据隐藏层输出,分别重建各个通道的输入,在重建过程中学习到包含各个通道结构信息的特征表示,保留原始数据结构信息的同时也综合提取了所有通道的有效特征,实现了原始输入的极小化误差重建,使得能够高效的处理多种复杂高维多通道特征。
4.本发明的技术方案主要包括如下步骤:
5.步骤1、给定经过归一化处理后的多通道训练样本集x=[x1,x2,
…
,xn],i=1,2,
…
,n,其中表示第i个尺寸为d1×
d2×
k的样本,k表示通道数量,n表示样本数量。
[0006]
步骤2、以多通道训练样本集x作为输入,根据样本xi的通道数量随机生成k个权重矩阵以及k个隐藏层偏置矩阵l表示隐藏层节点的数量,其中k表示通道的编号,k=1,2,
…
,k。分别计算每个通道的隐藏层输出为:
[0007][0008]
其中g(
·
)激活函数,表示第i个尺寸为d1×
d2×
k的样本中第k个通道的数据;由此可以得到隐藏层输出:
[0009]
[0010]
步骤3、构建基于多通道的矩阵随机自编码器的损失函数,表述如下:
[0011][0012]
其中,是需要进行训练获得的输出权重,c为正则项参数,表示取f范数。上述损失函数明显属于凸优化问题,对输出权重β
(k)
求导后其导数表述为:
[0013][0014]
令上式(4)等于零可得到输出权重的解析解:
[0015][0016]
步骤4、上述步骤训练得到的仅仅是单侧的输出权重,为了同时利用双侧的结构信息,需要重复步骤2和步骤3训练另一侧的输出权重。在训练另一侧的输出权重之前,需要对数据集进行转置处理,即将归一化后的数据集转化成而后重复步骤2和步骤3。
[0017]
为了方便区分,将两侧的权重重新分别命名为和值得注意的是,对于d1=d2情况的数据集而言,转置后尽管在size数值外观上无明显变化,但是数据集内部的结构发生了改变,训练得到的两个权重并不相同,因此该步骤不可省略。
[0018]
步骤5、基于训练好的多通道矩阵随机自编码器的输出权重,即可获得综合所有通道的编码输出,也即自动提取的特征为:
[0019][0020]
本发明有益效果如下:
[0021]
本发明针对现有的随机自编码器rnn-ae无法有效处理复杂高维多通道矩阵数据的问题,提出了多通道矩阵随机自编码器,相比较于rnn-ae,提出的dmmrae可以直接以多通道矩阵数据作为输入,保护了数据内部的空间结构信息,从而获得更加优越的自动特征学习能力。同时,提出的dmmrae继承了rnn-ae的训练速度快和人工干预少的优点,具有广泛的应用前景。
附图说明
[0022]
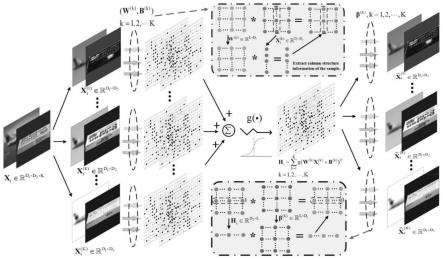
图1是多通道矩阵随机自编码器的结构图。
[0023]
图2是采用本发明提出的方法,对cifar10和coil100的3通道彩色图进行自动特征提取,随后进行异常检测的结果对比,可以看到本发明提出的方法(即dmmrae)具有最优的性能。
具体实施方式
[0024]
下面结合附图,将本发明的方法与异常检测任务相结合,对本发明作详细说明。同时,以下描述仅作为示范和解释,并不对本发明作任何形式上的限制。
[0025]
如图1,以三通道彩色图片数据集cifar-10为例,使用本发明提出的方法进行异常检测,具体实现如下:
[0026]
步骤1、本实例堆叠2个多通道矩阵随机自编码器。
[0027]
1-1.对于给定的训练集(正常类),进行特征归一化后得到新的训练样本x=[x1,x2,
…
,xn],i=1,2,
…
,n,其中xi∈r
32
×
32
×3表示第i个样本。
[0028]
1-2.对于第一个多通道矩阵随机自编码器,以归一化后的样本作为输入。我们设置隐藏层的维数为100
×
100,就三通道数据而言,需要分别随机生成三个通道的权重矩阵以及隐藏层偏置矩阵其中各元素值独立同分布,服从[-1,1]间的均匀分布。分别计算三个通道的隐藏层输出为:
[0029][0030]
其中g(.)取非线性的sigmoid函数作为激活函数。
[0031]
1-3.构造多通道矩阵随机自编码器的损失函数,表述如下:
[0032][0033]
其中是需要训练获得的左侧输出权重,c为正则项参数。
[0034]
上述损失函数明显属于凸优化问题,其对输出权重求导后表示如下:
[0035][0036]
令上式等于零可得其解析解:
[0037][0038]
1-4.计算右侧输出权重,需要对输入数据进行转置处理,而后重复上述步骤1-2和步骤1-3,训练得到的右侧输出权重命名为
[0039]
1-5.获得第一个多通道矩阵随机自编码器的编码输出为:
[0040][0041]
对于第2个多通道矩阵随机自编码器,我们以第一个多通道矩阵随机自编码器的编码输出作为各个通道的输入,其中并设置隐藏层的维数为100
×
100,以均匀分布随机生成的输入权重矩阵以及隐藏层偏置矩阵以及隐藏层偏置矩阵计算隐藏层输出为:
[0042]
[0043]
最后求解如下的损失函数:
[0044][0045]
得到第2个多通道矩阵随机自编码器的单侧输出权重。对第一个多通道矩阵随机自编码器的编码输出做转置处理后重复上述步骤1-2和步骤1-3可训练得到第2个多通道矩阵另一侧的输出权重。
[0046]
综上可得第2个多通道矩阵随机自编码器的各个通道的编码输出之和:
[0047][0048]
步骤2、构建矩阵均方误差损失函数,进行异常检测。
[0049]
将经过两个多通道矩阵随机自编码器后的编码输出展开成向量。对于具有n个样本的三通道数据集而言,最终可得到一个大小为(100
×
100)
×
n的编码输出矩阵y,构造如下损失函数:
[0050][0051]
其中c
′
表示权重衰减参数,t=[t1,t2,
…
,tn]
t
表示属于正常类训练样本的期望输出,β表示检测层需要进行训练的输出权重。对上述凸优化问题进行求导,得到如下所示导数:
[0052][0053]
令上式等于零可得到输出权重的解析解:
[0054][0055]
步骤3、输入测试数据进行测试。对包含异常值的测试数据经过归一化处理后输入到多通道多层矩阵随机神经网络中获得编码输出:
[0056][0057]
对编码输出做适当处理后传输给分类层进行异常检测:
[0058]
o=y
t
β
[0059]
计算实际输出与期望输出之间的误差距离,而后将该误差距离与阈值η比较:
[0060][0061]
如图2所示,每个类最好的结果在表格中用粗体标出,从表中可以看出,在15个测试类中,dmmrae有9个类获得了最高的检测准确率,具有较好的性能。添加表格具体比较数据说明。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1