基于迁移学习的跨域模型训练与日志异常检测方法及设备
1.本技术涉及日志异常检测技术领域,尤其涉及基于迁移学习的跨域模型训练与日志异常检测方法、设备及存储介质。
背景技术:
2.系统日志记录了详细的操作信息。一般情况下,故障原因也会被记录在系统中日志。通过对日志的分析和检测,可以为故障定位提供多种维度信息。日志异常检测,可以帮助系统调试和分析根本原因,为系统提供可靠的服务。在生产服务中,一个全新部署的系统,由于系统运行时间短,其收集的日志总数少,无法训练检测模型,出现日志异常检测冷启动问题。迁移学习是一种解决日志异常检测冷启动问题的有效方法。迁移学习是将一个领域(源领域)的知识,迁移到另外一个领域(目标领域),可以在样本不充足的条件下,大大提升日志异常检测效果。
3.然而,不同厂商和型号设备、系统日志的格式、语法和语义存在差异,没有统一标准,日志规范不统一。当软件系统工作服务性质不同时,它们的组件调用、io输出、故障种类也存在差异。因此,根据源系统与目标系统服务领域的相似度,可以分为同领域跨系统和跨领域两种迁移。同领域跨系统指源系统和目标系统的系统服务对象相似,仅在日志语法、格式不同。跨领域迁移指源系统和目标系统的系统服务对象、运行逻辑不同。例如bgl(blue gene/l超级计算机)、hpc(高性能集群)、thunderbird都属于超级计算机系统;hdfs、hadoop(wordcount、pagerank)与spark都为分布式系统;windows、linux、mac都是操作系统。跨系统迁移是相同领域系统间迁移,如windows-》linux、bgl-》thunderbird。跨领域迁移是跨领域系统进行迁移,如windows-》hadoop、bgl-》hadoop。
4.现有迁移学习方法都是跨系统迁移,但是在现实环境中,由于数据集缺少,对于跨领域迁移学习的需求更大,然而在源系统、目标系统领域不同时,模型对目标系统异常检测性能较差。
5.因此,如何在目标系统小样本条件下,提升日志异常检测的检测效果,成为需要解决的问题。
6.在背景技术中公开的上述信息仅用于加强对本技术的背景的理解,因此其可能包含没有形成为本领域普通技术人员所知晓的现有技术的信息。
技术实现要素:
7.本技术提供一种模型训练及日志异常检测方法、设备及存储介质,用以解决现有技术存在的问题。
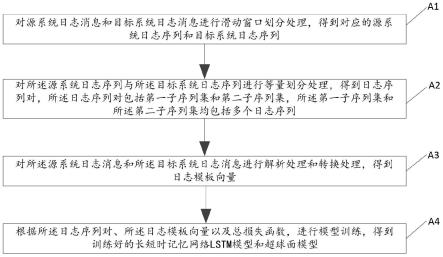
8.第一方面,本技术提供一种模型训练方法,包括以下步骤:a1、对源系统日志消息和目标系统日志消息进行滑动窗口划分处理,得到对应的源系统日志序列和目标系统日志序列;a2、对所述源系统日志序列与所述目标系统日志序列进行等量划分处理,得到日志序列对,所述日志序列对包括第一子序列集和第二子序列集,所述第一子序列集和所述第二
子序列集均包括多个日志序列;a3、对所述源系统日志消息和所述目标系统日志消息进行解析处理和转换处理,得到日志模板向量;a4、根据所述日志序列对、所述日志模板向量以及总损失函数,进行模型训练,得到训练好的lstm(long short-term memory,长短时记忆网络)模型和超球面模型;其中,所述总损失函数包括:超球面损失函数、对齐损失函数和均匀损失函数,所述对齐损失函数用于对齐或拉近同一对日志序列特征的距离,所述均匀损失函数用于使所述日志序列特征均匀分布在超球面上。
9.在一些实施例中,所述超球面损失函数lossh为:
[0010][0011]
其中,v1表示所述第一子序列集经过所述lstm模型提取后形成的第一日志序列特征集,v2表示所述第二子序列集经过所述lstm模型提取后形成的第二日志序列特征集,vi表示单个日志序列特征,c表示超球面球心特征;
[0012]
所述总损失函数loss
sum
为:
[0013]
loss
sum
=α1*lossh+α2*loss
align
+loss
uniform
[0014]
其中,α1、α2是平衡三个损失函数的超参数,loss
align
表示对齐损失函数,loss
uniform
表示均匀损失函数,lossh表示超球面损失函数。
[0015]
在一些实施例中,所述对齐损失函数loss
align
为:
[0016][0017]
其中,表示所述第一日志序列特征集中第i个所述日志序列特征,表示所述第二日志序列特征集中第i个所述日志序列特征,n
sub
表示单个日志序列特征集中的日志序列特征总数。
[0018]
在一些实施例中,所述均匀损失函数loss
uniform
为:
[0019][0020]
其中,e表示自然对数的底数,表示所述第一日志序列特征集中第i个所述日志序列特征,表示所述第二日志序列特征集中第i个所述日志序列特征,n
sub
表示单个日志序列特征集日志序列特征总数。
[0021]
在一些实施例中,所述a2,包括:a21、将所述源系统日志序列和所述目标系统日志序列混合并随机打乱,得到混合日志序列;a22、将所述混合日志序列划分为两个等量的子日志序列集,得到所述日志序列对。
[0022]
在一些实施例中,所述模型训练方法还包括:基于所述lstm模型提取所述日志序列特征,调整并确定决策边界,所述决策边界用于区分正常日志序列特征和异常日志序列特征,得到决策边界距离,所述决策边界距离为所述决策边界至所述超球面模型球心的距离。
[0023]
第二方面,本技术提供一种日志异常检测方法,所述日志异常检测方法通过lstm模型和超球面模型实现,所述lstm模型和所述超球面模型根据所述模型训练方法训练得到,所述日志异常检测方法包括以下步骤:b1、对待检测的目标系统日志消息进行滑动窗口切分处理,得到目标系统日志序列;b2、将所述目标系统日志序列解析为日志模板,根据所述日志模板,得到日志模板向量;b3、将所述日志模板向量输入训练好的所述lstm模型,得到日志序列特征集,所述日志序列特征集包括多个日志序列特征;b4、将所述日志序列特征输入训练好的所述超球面模型,得到异常检测结果。
[0024]
在一些实施例中,所述b4,包括:b41、计算所述日志序列特征至所述超球面模型球心的第一距离;b42、比较所述第一距离与决策边界距离的大小,得到比较结果;b43、根据所述比较结果,得到异常检测结果。
[0025]
第三方面,本技术提供一种终端设备,包括:
[0026]
存储器,用于存储计算机程序;
[0027]
处理器,用于读取所述存储器中的计算机程序并执行所述基于迁移学习的跨域模型训练方法或者所述基于迁移学习的跨域日志异常检测方法。
[0028]
第四方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现所述基于迁移学习的跨域模型训练方法或者所述基于迁移学习的跨域日志异常检测方法。
[0029]
本技术提供的模型训练方法,包括以下步骤:a1、对源系统日志消息和目标系统日志消息进行滑动窗口划分处理,得到对应的源系统日志序列和目标系统日志序列;a2、对所述源系统日志序列与所述目标系统日志序列进行等量划分处理,得到日志序列对,所述日志序列对包括第一子序列集和第二子序列集,所述第一子序列集和所述第二子序列集均包括多个日志序列;a3、对所述源系统日志消息和所述目标系统日志消息进行解析处理和转换处理,得到日志模板向量;a4、根据所述日志序列对、所述日志模板向量以及总损失函数,进行模型训练,得到训练好的lstm模型和超球面模型;其中,所述总损失函数包括:超球面损失函数、对齐损失函数和均匀损失函数,所述对齐损失函数用于对齐或拉近同一对日志序列特征的距离,所述均匀损失函数用于使所述日志序列特征均匀分布在超球面上。本技术的模型训练方法,利用源系统正常数据与少量目标系统正常数据进行训练,使目标系统数据更符合源系统数据分布,从而不需要目标系统异常数据进行训练就能实现异常检测,大大的降低了训练成本;通过对比学习的方法,采用对齐损失函数和均匀损失函数,成对比较两个特征之间的相似度;通过不断训练特征提取器,缩小特征之间的差异;直接衡量相似度,有利于量化特征之间的差异,从而将源系统与目标系统特征进一步拉近。
附图说明
[0030]
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本技术的实施例,并与说明书一起用于解释本技术的原理。
[0031]
图1为本技术提供的基于迁移学习的跨域模型训练及日志异常检测的示意图;
[0032]
图2为本技术提供的滑动窗口划分日志序列的示意图;
[0033]
图3为本技术提供的数据切分的示意图;
[0034]
图4为本技术提供的日志解析示例图;
[0035]
图5为本技术提供的孪生神经网络框架的示意图;
[0036]
图6为本技术提供的决策边界计算框架示意图;
[0037]
图7为本技术提供的基于迁移学习的跨域模型训练方法的步骤流程图;
[0038]
图8为本技术提供的基于迁移学习的跨域日志异常检测方法的步骤流程图;
[0039]
图9为本技术提供的终端设备的示意图。
[0040]
附图标记说明:
[0041]
100、处理器;200、存储器。
[0042]
通过上述附图,已示出本技术明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本技术构思的范围,而是通过参考特定实施例为本领域技术人员说明本技术的概念。
具体实施方式
[0043]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0044]
在本技术实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本技术实施例中所使用的单数形式的“一种”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。
[0045]
需要说明的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本技术的描述中,“多个”、“若干个”的含义是两个或两个以上,除非另有明确具体的限定。
[0046]
须知,本说明书附图所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本技术可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本技术所能产生的功效及所能达成的目的下,均应仍落在本技术所揭示的技术内容得能涵盖的范围内。
[0047]
应当理解,本文中使用的术语“和/或”仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”一般表示前后关联对象是一种“或”的关系。
[0048]
取决于语境,如在此所使用的词语“如果”、“若”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”或“响应于检测”。类似地,取决于语境,短语“如果确定”或“如果检测(陈述的条件或事件)”可以被解释成为“当确定时”或“响应于确定”或“当检测(陈述的条件或事件)时”或“响应于检测(陈述的条件或事件)”。
[0049]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的商品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种商品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的商品或者系统中还
存在另外的相同要素。
[0050]
专业术语的解释:
[0051]
logbert:基于bert结构的多任务无监督日志异常检测方法。该方法采用bert对解析后的日志模板id和日志模板词汇进行随机初始向量化得到日志向量,然后通过结合预测日志序列掩码id与最小化超球面两个自我监督的训练任务,学习正常日志序列的模式,违反正常模式的日志序列将判定为异常,该方法为无监督方法。
[0052]
word2vec:是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
[0053]
deepsvdd:是利用神经网络训练来最小化样本特征空间,以划分超球面,根据距离来判定样本点是否异常。
[0054]
下面以具体地实施例对本技术的技术方案以及本技术的技术方案如何解决上述技术问题进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例中不再赘述。下面将结合附图,对本技术的实施例进行描述。
[0055]
图1为本技术提供的基于迁移学习的跨域模型训练及日志异常检测的示意图,图7为本技术提供的基于迁移学习的跨域模型训练方法的步骤流程图,图8为本技术提供的基于迁移学习的跨域日志异常检测方法的步骤流程图,如图1、图7及图8所示,本技术提供的一种基于迁移学习的跨域模型训练及日志异常检测方法,离线模型训练过程中主要包括窗口划分、数据划分、特征嵌入、模型训练及计算决策边界五个部分,在线异常检测阶段主要包括窗口划分、特征嵌入和异常检测三个部分。以下是针对日志异常检测及模型训练各个过程的详细说明:
[0056]
a1、对源系统日志消息和目标系统日志消息进行滑动窗口划分处理,得到对应的源系统日志序列和目标系统日志序列;
[0057]
在一些实施例中,源系统是一个已经长期部署的软件系统,包含有大量正常日志数据s。本技术将源系统日志数据集定义为其中代表一条日志消息,ns代表ds中日志消息的总数。目标系统是一个全新部署的系统,只收集了少量日志数据。本技术将第r个目标系统日志数据集定义为:
[0058][0059]
其中,是第r个目标系统日志消息的总数。
[0060]
需要说明的是,在本技术实施例中,日志异常检测任务是对异常日志序列进行检测。在一些实施例中,窗口划分是指可以通过窗口的方式将日志消息列表划分为不同的块,这些块是日志序列。异常事件发生时,收到的日志消息是异常的。如果日志序列中有异常日志消息,则说明日志序列异常;如果日志序列中没有异常日志消息,则说明日志序列正常。日志异常检测任务就是检测日志序列。
[0061]
在一些实施例中,所述滑动窗口划分处理,即窗口划分,具体处理过程为:采用滑动窗口大小w和步长sp,将日志消息按序列进行切分;滑动窗口是一种基于双指针的一种思
想,两个指针指向的元素之间形成一个窗口,就像一个滑动的窗口套在一个序列中,左右的滑动,窗口内就是一个内容集;图2为本技术提供的滑动窗口划分日志序列的示意图,如图2所示,以滑动窗口大小w=4,步长sp=1为例,第一次划分得到的日志序列为l1={x1,x2,x3,x4},紧接着窗口按步长大小向后滑动得到第二个日志序列l2={x2,x3,x4,x5}。依此类推,直到窗口滑动到最后一个日志消息后停止。
[0062]
因此,第i个日志序列为:
[0063]
li={xj,
…
,x
j+w
}
j=i*sp
[0064]
其中,xj表示第j条日志消息,则划分后的日志序列总数为:
[0065]
m=(n-w)/sp+1
[0066]
其中,m表示日志序列总数,n表示日志消息总数,w表示滑动窗口大小,sp表示滑动窗口步长。
[0067]
因此,源系统日志序列表示为:第r个目标系统日志序列表示为
[0068]
a2、对所述源系统日志序列与所述目标系统日志序列进行等量划分处理,得到日志序列对,所述日志序列对包括第一子序列集和第二子序列集,所述第一子序列集和所述第二子序列集均包括多个日志序列;
[0069]
需要说明的是,在本技术实施例中,源系统日志与目标系统日志之间的差异远高于源系统日志之间差异。因此,对比源系统与目标系统日志序列特征的相似度,需要将数据划分成对,通过对数据成对比较,得到整体相似度差异。通过减少对比损失,调整特征提取器输出结果,使源系统与目标系统差异降低,目标系统特征相似度更高。因此,本技术将源系统与目标系统的数据进行混合,并划分为两个子日志序列集合,即第一子序列集和第二子序列集,这两个子序列集将为后续下游任务各提供成对日志序列。
[0070]
为了能衡量系统数据间的相似度,减小特征差异,需要将系统日志数据划分成对。在一些实施例中,所述等量划分处理,即数据划分,具体处理过程为:将源系统与目标系统日志进行滑动窗口切分后,得到源系统日志序列ls与多个目标系统日志序列图3为本技术提供的数据切分的示意图,如图3所示,将源系统日志序列ls与多个目标系统日志序列混合随机打乱后,划分成两个等量的子数据集l1与l2,作为后续模型的输入;源系统和目标系统的日志序列不进行区分,随机混合切分。
[0071]
具体的,在本技术实施例中,将日志向量序列进行混合,并将其平均切分成长度大小为的两个子序列集。
[0072]
两个子序列集合为孪生lstm模型提供日志序列对
[0073]
a3、对所述源系统日志消息和所述目标系统日志消息进行解析处理和转换处理,得到日志模板向量;
[0074]
需要说明的是,日志是非结构化文本,需要将半结构化日志消息解析为结构化日志模板。检测模型无法直接处理文本数据,需要通过word2vec提取日志模板中单词,将单词
映射成对应的向量表示,从而构造日志模板向量,作为检测模型输入。
[0075]
日志消息由半结构化的常量字符串和变量组成。在日志异常检测前,日志消息需要正确地被解析为日志模板,日志模板是日志的常量部分或摘要。
[0076]
在一些实施例中,所述解析处理,即日志解析,具体处理过程为:通过删除参数将日志消息解析为日志模板。通过日志解析,可以将每个日志消息解析为唯一的日志事件。日志解析可以用p(xi)表示,p(xi)是日志消息xi的映射。
[0077]
图4为本技术提供的日志解析示例图,如图4所示,一条bgl日志消息。消息内容为87 l3 edram error(s)(dcr 0x0157)detected and corrected over 27362seconds。日志模板为《*》《*》《*》error(s)(dcr《*》)detected and corrected over《*》seconds。通过日志解析,可以获得日志消息的结构化表示,每个日志消息都可以映射到唯一的日志事件。
[0078]
为了表示日志序列,我们首先需要表示单词和日志事件。通过nlp语言模型可以得到日志中的单词向量或嵌入,单词嵌入可以进一步构造日志事件嵌入。
[0079]
在一些实施例中,所述转换处理,即特征表示,具体处理过程为:使用word2vec语言模型来捕获单词之间的关系,将单个单词w转换为d维嵌入word2vec(w)∈rd,并将词向量求和平均得到日志模板向量ej∈rd,日志模板向量ej为:
[0080]ej
=f(p(xj))=mean(word2vec(w)),w∈p(xj)
[0081]
其中,mean表示求和平均,w表示单个单词,word2vec(w)表示语言模型的输出,p(xj)表示日志模板。
[0082]
a4、根据所述日志序列对、所述日志模板向量以及总损失函数,进行模型训练,得到训练好的lstm模型和超球面模型;
[0083]
其中,所述总损失函数包括:超球面损失函数、对齐损失函数和均匀损失函数,所述对齐损失函数用于对齐或拉近同一对日志序列特征的距离,所述均匀损失函数用于使所述日志序列特征均匀分布在超球面上。
[0084]
孪生神经网络被广泛应用于两个事物之间的相似性或可比性任务,如签名验证、人脸验证、图像相似性和句子相似性。图5为本技术提供的孪生神经网络框架的示意图,如图5所示,孪生体系结构由两个具有相同结构和共享权重的神经网络组成,利用两个相同的模型来处理相似的输入,这两个模型并行地提取特征表示向量,使它们更容易比较成对的样本。此外,模型之间的共享权重需要更少的训练参数、更少的训练数据和更少的过度拟合趋势,是一种少镜头的学习,通常,该模型以两个样本对作为输入。孪生神经网络可以是各种神经网络,如mlp(multilayer perceptron,多层感知机)、cnn(convolutional neural network,卷积神经网络)和rnn(recurrent neural network,循环神经网络),这取决于任务。
[0085]
需要说明的是,孪生神经网络能最大限度地提取相似样本的共同特征,采用孪生lstm模型共享参数并提取出日志序列对的特征,并利用三个损失函数来约束日志序列对之间的特征,衡量成对特征的相似度。为了能使正常特征与异常特征能有效的进行分离,本技术采用超球面损失函数,使所有正常特征都接近球体的中心,异常特征被抛离。由于使用大量源系统数据训练模型,需要将目标系统特征与源系统特征进行对齐,解决两者数据不匹配问题,本技术使用对齐损失函数衡量两者相似度,从而使目标系统数据更加符合源系统数据分布,达到模型迁移目的。而在模型迁移的过程中,不可避免会丢失数据部分特征信
息。为了尽可能保留更多的原始特征信息,我们引入均匀损失函数使得成对特征均匀分布在超球面上,以保持原始特征信息。
[0086]
lstm是一种特殊的rnn,通过选通状态控制传输状态,在时间序列数据中得到了广泛的应用。在日志异常检测中,日志序列由一系列日志向量组成,这些日志向量根据生成时间点进行排序。因此,本技术使用lstm模型作为孪生神经网络的基本模型来构建检测模型。
[0087]hj
=lstm(ej,h
j-1
)
[0088]
vi=hw[0089]
其中,ej是第j个日志模板的日志模板向量,h
j-1
是第j-1个lstm隐藏层向量,最后一个隐藏向量hw提取整个日志向量序列的特征,作为日志序列表示vi=hw。
[0090]
对于两个子序列集而言,将来自第一个子序列集l1的第j个日志序列的特征表示为所有日志序列特征表示构建一个日志序列特征集v1;第二个子序列集l2的第j个日志序列特征表示为所有日志特征序列表示构建了一个日志序列特征集v2。
[0091]
采用最小化超球面对异常日志序列进行检测,已经广泛的运用于无监督日志异常检测中。由deepsvdd方法通过训练神经网络最小化特征空间划分异常数据。输出特征空间中的样本点,并映射到超球面中,正常数据通过训练将尽可能映射到球心c附近,而异常数据将会远离球心c,通过判断样本点与球心的距离,将异常数据筛选出来。
[0092]
为了使正常数据尽可能接近超球体的中心,在一些实施例中,通过使用样本与中心之间距离的均方误差作为损失函数:
[0093][0094]
其中,v1表示所述第一子序列集经过所述lstm模型提取后形成的日志序列特征集,v2表示所述第二子序列集经过所述lstm模型提取后形成的日志序列特征集,vi表示单个日志序列特征,c表示超球面球心特征。
[0095]
总损失函数loss
sum
为:
[0096]
loss
sum
=α1*lossh+α2*loss
align
+loss
uniform
[0097]
其中,α1、α2是平衡三个损失函数的超参数,loss
align
表示对齐损失函数,loss
uniform
表示均匀损失函数,lossh表示超球面损失函数。
[0098]
受对比学习的启发,为了将相似的特征分配给相似的样本,并保留特征最多信息的特征分布,本技术引入了对齐损失和均匀损失。对齐损失对齐或拉近同一对特征的距离,均匀损失使特征均匀分布在超球面上。
[0099]
由于,对比学习的训练效果取决于对齐与均匀两种指标,对齐的意思是正对的两个样本应该映射到附近的特征,均匀的意识是特征向量大致均匀分布在超球上,尽可能保留数据的信息;同时优化这两种指标进行训练,在下游任务中能具有更好的表现。因此,本技术通过设计对齐损失函数与均匀损失函数,能够不断优化两种指标构建良好的超球面表征。
[0100]
在一些实施例中,对齐损失函数loss
align
为:
[0101][0102]
其中,表示所述第一日志序列特征集中第i个所述日志序列特征,表示所述第二日志序列特征集中第i个所述日志序列特征,n
sub
表示单个日志序列特征集中的日志序列特征总数。
[0103]
在一些实施例子中,通过使用高斯势核函数,即均匀损失函数,并定义为其成对样本的高斯势核函数的对数,使得均匀性度量能将分布收敛到均匀,能在有限样本下具有通用的合理性,均匀损失函数loss
uniform
为:
[0104][0105]
其中,e表示自然对数的底数表示所述第一日志序列特征集中第i个所述日志序列特征,表示所述第二日志序列特征集中第i个所述日志序列特征,n
sub
表示单个日志序列特征集中的日志序列特征总数。
[0106]
需要说明的是,在本技术实施例中,e为无限不循环小数,e≈2.71828。
[0107]
a5、基于所述lstm模型提取所述日志序列特征,调整并确定决策边界,所述决策边界用于区分正常日志序列特征和异常日志序列特征,得到决策边界距离,所述决策边界距离为所述决策边界至所述超球面模型球心的距离;
[0108]
需要说明的是,通过训练超球面,正常特征与异常特征已经有效地分离。需要确定两者间的划分边界,从而实现异常检测。通过收集第r个目标系统一天的全部日志消息,并进行标记作为验证集其中包含已经标记好的正常与异常日志。计算验证集中正常与异常日志序列特征与超球面球心之间距离,得到该第r个目标系统的决策边界将围绕在超球面周围的目标系统日志序列特征成功划分为正常与异常两个集团。
[0109]
具体的,在本技术实施例中,通过对模型的训练,超球面已经能有效地将正常的日志序列特征集聚在超球面球心周围,异常序列特征被超球面抛离。本技术收集第r个目标系统一天运行的日志消息作为验证集有正常与异常的日志消息,并对验证集进行标记。图6为本技术提供的决策边界计算框架示意图,如图6所示,通过对验证集进行窗口划分得到第r个目标系统的日志序列集合日志序列经过已经上述步骤训练后的lstm模型提取出日志序列特征由于验证集中包含有异常日志消息,因此异常日志序列提取出的异常日志序列特征在图中表示为叉,正常日志序列特征图中表示为圆圈。正常的日志序列特征集聚在超球面球心周围,异常序列特征被超球面抛离。首先以全部正常日志序列特征与超球面球心间距离的平均值作为初始的边界距离,随后不断扩大边界距离,将小于边界距离的日志序列特征作为正常,大于边界距离的为异常。计算整个验证集日志序列的auc(area under curve,面积曲线),日志序列包含正常与异常,将得到最佳auc指标的边界距
离作为该第r个目标系统的决策边界
[0110]
更为具体的阐述,计算日志序列特征与超球面球心之间距离distance的公式为:
[0111][0112]
其中,v代表单个日志序列特征,c代表超球面球心。
[0113]
a6、将所述日志模板向量输入训练好的所述lstm模型,得到日志序列特征集,所述日志序列特征集包括多个日志序列特征;将所述日志序列特征输入训练好的所述超球面模型,得到异常检测结果。
[0114]
需要说明的是,在检测阶段,对目标系统产生的全新日志消息进行收集、窗口划分并提取日志序列特征。新日志序列特征向量到超球中心的距离与决策边界b进行比对来判断异常日志序列。在下一步骤中,将详细描述每个步骤的过程。
[0115]
在检测阶段,对第r个目标系统产生的全新日志消息进行收集、窗口划分并提取日志序列特征。与计算决策边界类似,计算日志序列特征与超球面中心间的距离distance,与决策边界距离进行比对。若距离distance小于决策边界距离则认为该日志序列特征为正常,即该日志序列正常,序列中所有日志消息为正常;当距离distance大于决策边界距离时,则认为该日志序列特征为异常,即该日志序列异常,序列中存在异常日志消息。
[0116]
具体实施例如下:
[0117]
在三个日志数据集上对本技术的方法进行评估,如下所述:
[0118]
bgl:从加利福尼亚州利弗莫尔的劳伦斯利弗莫尔国家实验室(llnl)的bluegene/l超级计算机系统收集214天运行情况的日志开放数据集。
[0119]
thunderbird:从阿尔伯克基桑迪亚国家实验室(snl)的thunderbird超级计算机系统收集244天运行情况的日志开放数据集,其包含有211,212,192条原始日志消息。我们选取前5,000,000条日志消息作为我们的数据集,其中异常日志消息的数量为226,753条。
[0120]
wordcount:是hadoop大数据处理框架下,所执行的应用程序中所收集3天运行情况的日志数据集。其是hadoop发布的应用程序,作为mapreduce编程的一个例子。wordcount应用程序分析输入文件并计算输入文件中每个单词的出现次数。其为模拟真实环境下的服务故障,注入了计算机关闭、网络断开连接、磁盘已满的部署故障。
[0121]
表1数据集的概述
[0122]
datasets#oflogs#ofanomaliesbgl1,200,00099,677thunderbird-mini5,000,000226,753wordcount81,9484,564
[0123]
为了验证本技术中提出方法的合理性以及先进性,将该异常检测方法分别与机器学习方法im,三种基于迁移学习的方法logtad、logtransfer、deepsvdd以及三种无监督方法deeplog、logcluster、logbert进行了比较。
[0124]
im:im从日志序列挖掘工作流的不变量,揭示程序工作流固有的线性特征。通过这些不变量能有效地检测日志序列中的异常。
[0125]
deeplog:deeplog采用无监督lstm来捕获正常日志序列的顺序模式,并基于以下日志键的预测进一步识别异常日志序列。
[0126]
logcluster:是一种基于聚类的方法,通过与现有聚类进行比较来检测异常日志序列。
[0127]
logbert:logbert是一种基于变压器双向编码器表示(bert)的日志异常检测自监督框架。它通过两个任务捕获正常日志序列的模式:屏蔽日志密钥预测和超球体体积最小化。
[0128]
logtad:logtad利用对抗性域适配技术使来自不同系统的日志数据具有相似的分布,以便检测模型能够检测来自多个系统的异常。
[0129]
logtransfer:logtransfer可以实现跨系统异常检测,但需要来自源系统和目标系统的标记数据来训练分类器,该分类器共享相同的完全连接网络,而不是源系统和目标系统之间的相同lstm网络。它是一种半监督的迁移学习方法。
[0130]
deepsvdd:deepsvdd是利用神经网络训练来最小化样本特征空间,以划分超球面,根据距离来判定样本点是否异常。为了更加贴合日志异常检测实际环境,本实施例中采用deepsvdd的思想构建了一个lstm+超球面的基础模型,作为提出的模型的比较基线。deepsvdd相较于本技术提出的方法,缺少对比loss的构建,在接下来的实验中会进一步进行讨论。
[0131]
将日志序列的窗口大小设置为20,步长为3。word2vec训练词向量维数为300,lstm隐藏层大小为128,学习率a1设置为10e4、a2设置为10e5。选取源系统正常日志size为100,000,目标系统正常日志size为1,000进行训练。对于lstm层数选取与损失函数的影响,我们在实验中研究了它们的影响。
[0132]
对于logtransfer,采用全部源系统数据训练预训练模型,当bgl或thunderbird作为目标系统时,取数据集前2%的异常数据作为logtransfer的迁移数据,当wordcount作为目标系统时取数据集前5%的异常数据作为迁移数据。deepsvdd与logtad均选取源系统正常日志size为100,000,目标系统正常日志size为1,000。单系统无监督方法将训练集与测试集比例划分为4:6。
[0133]
所有实验均在12th gen英特尔酷睿i5-12600kf以及nvidia geforcertx 3070ti上运行。
[0134]
为了评估本技术的模型性能,对跨系统迁移效果、跨领域迁移和多目标系统迁移进行了实验。
[0135]
如表2所示,我们比较了bgl与thunderbird互为源系统与目标系统的情况。
[0136]
表2跨系统迁移总体性能
[0137][0138]
通过以上实验结果,作为一种少训练样本的基于迁移学习的无监督学习方法,本技术的方法logmtc在召回率和f1分数上优于大部分单系统无监督学习异常检测方法,在与迁移学习方法logtransfer比较时,即使logtransfer使用了目标系统带标签数据进行训练,本技术的方法也优于logtransfer。通过以上实验结果,可以看出基于对比学习域自适应的跨域日志异常检测方法只需要训练较少的数据集就能获得理想的异常检测模型,明显减少了模型的训练成本。
[0139]
在跨领域迁移的情况下,如表3所示,我们比较了bgl与thunderbird为源系统,wordcount为目标系统的情况。
[0140]
表3跨领域迁移总体性能
[0141][0142][0143]
通过以上实验结果可以明显看到,单系统无监督学习方法需要使用大量数据进行
训练,模型需要“从头开始”寻找数据分布的内在规律。在训练样本不足的情况下,模型性能将严重下降。在bgl为源系统,wordcount为目标系统的情况下,本技术的方法logmtc精度、召回率与f1达到68.61%、80.60%、74.13%。可以看到logtad与基线deepsvdd相比,其性能不升反降,出现了负迁移的情况,精度、召回率、f1分数均大幅下降,这是由于在跨域的情况下,对抗的方法并不能有效的混淆源系统与目标系统特征分布,导致超球面分类效果变差。而我们的方法logmtc,直接采用计算源系统与目标系统相似度的方式,将两者特征分布拉近,从而避免了负迁移的情况。
[0144]
多目标系统迁移是传统的单源系统-单目标系统迁移进一步衍生,期望训练一个模型,该模型能充分利用单个源域与多个目标域的数据,并在不同的目标域上检测效果良好。在实验中并未区分设置跨系统或跨领域数据作为目标系统,因为在多目标系统情况下,希望模型能够在更加复杂多变的情况下,也能保持良好的性能。如表4所示,我们比较了以bgl为源系统,thunderbird为目标系统a,wordcount为目标系统b的情况。如表5所示,我们比较了以thunderbirdbgl为源系统,bgl为目标系统a,wordcount为目标系统b的情况。
[0145]
表4以bgl为源系统,多目标系统迁移总体性能
[0146][0147][0148]
表5以thunderbird为源系统,多目标系统迁移总体性能
[0149][0150]
通过以上实验结果可以明显看到,当有两个目标系统时,deepsvdd只保证一个目标系统的检测精度,这无法保证两个目标系统的迁移效果。本技术的方法取得了更好的效果,在多目标系统情况下,单目标系统的检测效果,仅略微下降。这是因为在多目标系统迁移时,本技术的方法logmtc通过直接拉近源系统与目标系统特征的方式,避免了多个目标系统之间的相互干扰。
[0151]
第二方面,本技术提供一种终端设备,图9为本技术提供的终端设备的示意图,如图9所示,包括:
[0152]
存储器200,用于存储计算机程序;
[0153]
处理器100,用于读取所述存储器200中的计算机程序并执行所述模型训练方法或者所述日志异常检测方法。
[0154]
第三方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器100执行时用于实现所述模型训练方法或者所述日志异常检测方法。
[0155]
需要进一步说明的是,本技术提供的日志异常检测方法可应用于多目标系统日志
的异常检测,将多个目标系统数据共同进行训练,得到一个综合泛化的检测模型。
[0156]
除此之外,本技术涉及的方法还可以进行跨领域跨多系统的日志异常检测,可以结合任意的迁移学习或对比学习进行使用。
[0157]
应该理解的是,虽然上述实施例中的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,其可以以其他的顺序执行。而且,图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,其执行顺序也不必然是依次进行,而是可以与其他步骤或者其他步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
[0158]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
[0159]
本领域技术人员在考虑说明书及实践这里公开的申请后,将容易想到本技术的其它实施方案。本技术旨在涵盖本技术的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本技术的一般性原理并包括本技术未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本技术的真正范围和精神由下面的权利要求书指出。
[0160]
应当理解的是,本技术并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本技术的范围仅由所附的权利要求书来限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1