客服话务量预测方法与流程
1.本发明涉及电子商务服务技术领域,尤其涉及一种根据现有客服输入话务量预测未来几天的输入话务量的预测方法。
背景技术:
2.随着呼叫中心规模的日益扩大和服务中心,运营管理的要求不断提高,如何在现有人力条件下达到客户服务水平目标,合理安排人力,优化现场管理成为排班师面临的巨大挑战。时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征。这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的。时间序列可以分为平稳序列,即存在某种周期,季节性及趋势的方差和均值不随时间变化的序列,及非平稳序列。
3.传统的预测方法分为两种,一种是移动平均法,指数平均法等;一种是用的还算较多的,既ar,ma,arma等,这三种模型试用的场景不同,基于此类方法的建模步骤是,首先需要对观测值序列进行平稳性检测,不过不稳定,则对其进行差分运算直到差分后的数据平稳;在数据平稳后则对其进行白噪声检验,白噪声是指零均值常方差的随机平稳序列;如果是平稳非白噪声序列就计算acf(自相关系数),pacf(偏自相关系数),进行arma等模型识别,对已识别好的模型,确定模型参数,最后应用预测并进行误差分析。
4.现代时间序列预测方法偏向于机器学习以及深度学习方法。对于机器学习方法,xgboost,随机森林以及支持向量机可以用的。用数据挖掘方法关键在于特征工程,跟其他的挖掘任务不同的是,时间序列的特征工程会使用滑动窗口,即计算滑动窗口内的数据指标,如最大值,最小值,均值,方差等作为新特征。对于深度学习方法,lstm神经网络用的最多也适合解决这类方法。
5.上述方法,时间序列数据随机性很大,又受确实性,周期性,季节性等等因素影响,传统方法预测难度大,甚至会出现滞后性等重大问题。
技术实现要素:
6.本发明目的在于克服现有技术中存在的问题,提供一种客服话务量预测方法。
7.为了达到上述目的,本发明的技术方案如下:
8.客服话务量预测方法,其特征在于,包括如下步骤
9.1)数据预处理
10.对缺失值进行填充,异常值不删除;
11.2)数据模型建立
12.分别建立lstm,holt-winter,xgboost,prophet四个基本模型,每个模型的数据处理一致,但是模型的输入数据格式各有不同,数据预处理涉及缺失值填充,特征构造;
13.3)建立一个线性规划
14.目标是根据历史的数据预测未来45天的数据,并提取预测的下一个月的数据,对于模型的要求是预测值必须在实际值的98.4%,以及108.4%这个区间内,根据以上的基础模型的预测结果建立如下的线性规划问题:
15.已知x是输入的历史数据,fi是每个基本模型,y是实际的话务量数据,αi表示每个基本模型的权重,
16.min b=|∑α
ifi
(x)-y|
17.0.984y≤b≤1.804y
18.建立如上的线性规划,得出αi的值,然后用∑α
ifi
(x)作为最终的模型预测未来的数据。
19.其中步骤2)中,所述lstm模型和所述xgboost模型采用的是滚动预测,在gpu上进行训练。
20.其中步骤2)中,所述prophet模型添加节假日作为因子参数。
21.本发明的有益效果:
22.在使用xgboost和lstm模型的时候采用了滚动预测的方式,比如说预测未来半天的话务量,再将新预测的话务量重新加入到以前的训练集,然后训练,预测未来半天,这样会比直接预测未来一周的话务量效果要好。另外时间序列预测经常会出现滞后项的问题,产生滞后项的原因是序列存在自相关性,在处理的过程中需要进行差分运算,也就是将当前时刻与前一时刻的差值作为回归目标。
23.最后采用了横向和纵向的预测方式,横向就是按正常每一刻钟采样的话务量进行模型训练,纵向就是每隔一天采样,比如第一天12:30,第二天12:30
…
,预测未来某一天的同一时刻,然后再将横向和纵向的预测结果求平均即可,这样的预测结果比单向的要好一些。
24.本方案采用了一个线性规划,让每个模型赋予了权重,从而让每个模型对最终预测的影响不同,起到一个优劣互补的作用。
25.本发明克服单个模型准确不高,鲁棒性不强的特点,采用类似于集成算法和提升算法的方法,同时兼顾节假日等因数,让预测结果的准确率提升一个档次。
附图说明
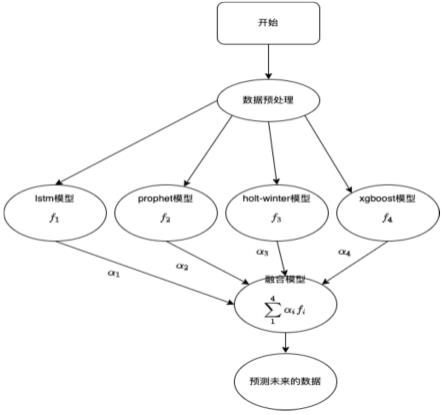
26.图1为本发明所述的预测流程图。
27.图2为某年一月份话务量数据实例图。
28.图3为时间序列稳定性分析图。
29.图4为holt-winter模型时间序列预测。
30.图5为lstm模型时间序列预测。
31.图6为xgboost模型时间序列预测。
32.图7为prophet模型时间序列预测
33.图8为4个模型融合一起的最终的预测
具体实施方式
34.下面结合具体实施例,进一步阐述本发明。
35.本方案依据过去的客服输入话务量预测未来几天的输入话务量,属于时间序列建模的范畴
36.步骤1.通过df-test检验话务量数据不是稳定的,基本上所有年份的数据都是稳定的,所以该数据集是非常适合做时间序列建模进行预测分析。
37.步骤2.数据预处理,模型数据会有很多的缺失值,影响预测结果,所以要对缺失值进行填充,另外异常值很重要,不能删除。
38.步骤3.数据模型建立,这里我们分别建立lstm,holt-winter,xgboost,prophet四个基本模型,每个模型的数据处理一致,但是模型的输入数据各有不同,得分别整合成相应的的输入,得到每个模型的预测结果,记录为
39.步骤4,建立一个线性规划问题,目标是根据历史的的数据预测未来45天的数据,并提取预测的下一个月的数据,对于模型的要求是预测值必须在实际值的98.4%,以及108.4%这个区间内,所以我们可以根据以上的基础模型的预测结果建立如下的线性规划问题:
40.已知x是输入的历史数据,fi是每个基本模型,y是实际的话务量数据,αi表示每个基本模型的权重,
41.min b=|∑α
ifi
(x)-y|
42.0.984y≤b≤1.804y
43.建立如上的线性规划问题,得出αi的值,然后用∑α
ifi
(x)作为最终的模型预测未来的数据,混合模型的结果比单个模型至少提升10%的准确率。
44.图1为本发明所述的预测流程图。如图1所示,4个基本模型lstm,prophet,holt-winter,xgboost,一个融合的模型,其中αi表示每个模型的权重,需要自己计算出来。
45.时间序列的预测用到四个模型,lstm,xgboost,holt-winter,prophet,这四个模型都能做时间序列,有些会考虑趋势性,节假日,周期性等,有些会根据以往的特征用机器学习方法直接预测未来的值。单个模型由于单一性,实际的效果并不好,考虑到组合算法的优势,我们需要把每个基本模型融合在一起,这样保证综合模型的效果更具有鲁棒性,效果更好。
46.单个模型比如长短期记忆算法(lstm)需要对时许数据进行分解,拼接成lstm所需要的输入格式,喂给模型,xgboost就是得把时间进行分解,提取相应特征,prophet适合做单维度时间序列建模,会考虑节假日等因素,也是唯一一个把节假日显示的表现出来,最后一个holt-winter,它是三次指数平滑算法,会考虑趋势性,周期性等时间序列特征。
47.首先我们会分别建立四个基本模型,并尽量让每个模型的准确率做到最高,然后用一种加权求和的形式,为每个模型加权重,之后用组合的模型去预测未来的数据。
48.本方案看起来比较复杂,看起来没有理论支撑,但是融合的模型确实比单个模型的准确率高,类似于随机深林或者boosting算法,几个弱学习器组合成一个强学习器。
49.基于往年客服首次按键总话务量的数据预测未来一段时间的话务量,摘取一个月话务量可视化如下:
50.图2为某年一月份话务量数据。以上是一月份的客服的输入话务量的示例,每15分钟一采样,做预测时我们用了两年的历史话务量的数据预测未来一个月的客服话务量,预测话务量的目的是为了坐席排班,合理安排每位客服人员的工作时间。
51.稳定性分析:
52.参见图3稳定性分析。其中蓝线表示18年1月至2019年1的原始话务量时序图,红线表示滑动平均线,黑线表示滑动平均标准差。
53.通过df-test检验发现2018年的话务量数据是非常稳定的,基本上所有年份的数据都是稳定的,所以该数据集是非常适合做时间序列建模进行预测分析。
54.目标是根据本月15号之前的的数据预测未来45天的数据,并提取预测的下一个月的数据,对于模型的要求是预测值必须在实际值的98.4%,以及108.4%这个区间内。
55.预测结果如下:
56.图4holt-winter时间序列预测,图5为lstm模型时间序列预测,图6为xgboost模型时间序列预测,图7为prophet模型时间序列预测,以上是4个模型的结果。
57.下图是最终融合模型的结果:图8为4个模型融合一起的最终的预测。圆心点就是预测正确的点,预测结果比人工要好很多。
58.以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明专利要求保护的范围由所附的权利要求书及其等同物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1