用户类目识别方法、装置、电子设备及存储介质与流程
本技术涉及计算机,具体而言,涉及一种用户类目识别方法、装置、电子设备及存储介质。
背景技术:
1、用户类目的识别研究有利于针对不同类别的用户提供不同的业务,现有的用户类目识别方案多依赖于人工对与用户关联的文本设定标签,然后使用文本分类方案预测单条文本的类目,最后将与用户关联的所有文本类目预测结果汇总,并基于汇总的数据对该用户进行真实类目的判断。
2、显然,上述方案只能针对单条文本进行预测,没有有效利用用户对应的多条文本,无法精确对用户类别进行预测。
技术实现思路
1、为解决上述技术问题,本技术的实施例提供了一种用户类目识别方法及装置、电子设备、计算机可读存储介质、计算机程序产品。
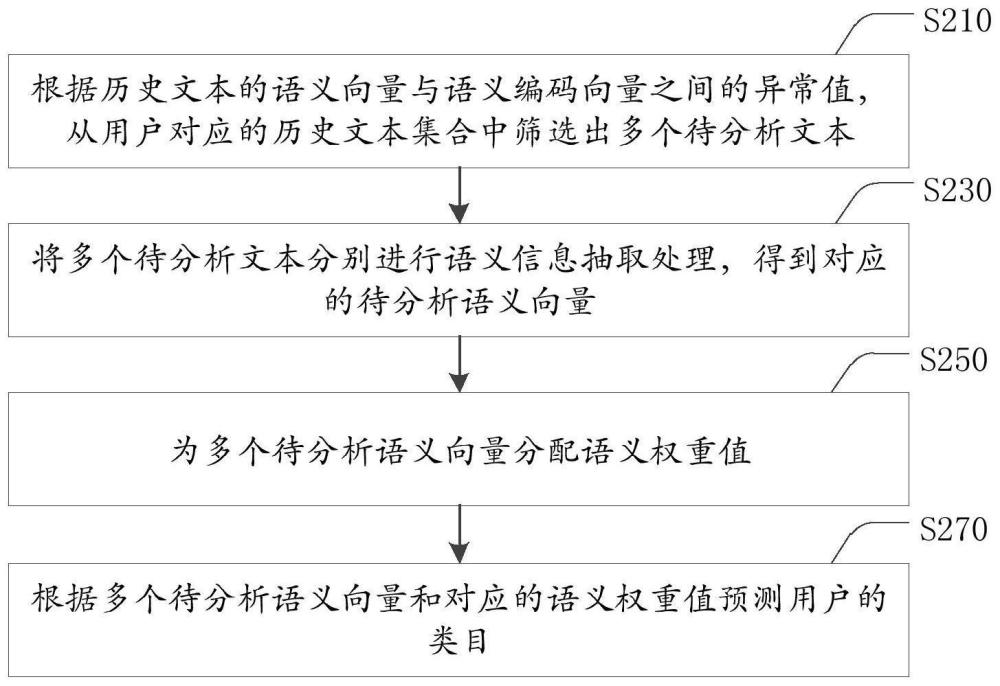
2、根据本技术实施例的一个方面,提供了一种用户类目识别方法,包括:根据历史文本的语义向量与语义编码向量之间的异常值,从用户对应的历史文本集合中筛选出多个待分析文本;其中,所述语义编码向量为对所述语义向量进行自编码处理所得到的;将所述多个待分析文本分别进行语义信息抽取处理,得到对应的待分析语义向量;为多个待分析语义向量分配语义权重值;根据所述多个待分析语义向量和对应的语义权重值预测所述用户的类目。
3、根据本技术实施例的一个方面,提供了一种用户类目识别装置,包括:预处理模块,配置为根据历史文本的语义向量与语义编码向量之间的异常值,从用户对应的历史文本集合中筛选出多个待分析文本;其中,所述语义编码向量为对所述语义向量进行自编码处理所得到的;待分析语义向量获取模块,配置为将所述多个待分析文本分别进行语义信息抽取处理,得到对应的待分析语义向量;权重值分配模块,配置为针对多个待分析语义向量分配语义权重值;分类模块,配置为根据所述多个待分析语义向量和对应的语义权重值预测所述用户的类目。
4、在一实施例中,预处理模块包括:
5、历史语义向量获取单元,配置为对历史文本集合中的各历史文本分别进行语义信息抽取处理,得到各历史文本对应的历史语义向量;
6、历史语义编码向量获取单元,配置为将各历史语义向量分别进行自编码处理,得到对应的历史语义编码向量;
7、第一异常值获取单元,配置为计算各历史语义向量与对应历史语义编码向量之间的异常值;
8、第一待分析文本获取单元,配置为将异常值小于预设异常阈值的历史文本作为待分析文本。
9、在一实施例中,预处理模块还包括:
10、拼接文本获取单元,配置为将用户关联的多条文字信息分别与对应的文字名称进行拼接,得到多条拼接文本;其中,文字名称用于表征对应文字信息的主题;
11、替换单元,配置为将各条拼接文本中与指定类型字符相关的文字信息替换为预设字符,得到历史文本集合中的各历史文本。
12、在一实施例中,待分析文本获取单元包括:
13、第一文本获取板块,配置为若异常值小于预设异常阈值的历史文本子集中的文本数量大于预设数量阈值,则从历史文本子集中选择获取时间在预设时间段内的历史文本作为第一文本;
14、第二文本获取板块,配置为从历史文本子集中随机抽取除第一文本外的其他历史文本作为第二文本;其中,第一文本与第二文本的数量和不大于预设数量阈值;
15、待分析文本获取,板块,配置为将第一文本和第二文本作为待分析文本。
16、在一实施例中,预处理模块包括:
17、语义向量获取单元,配置为将历史文本集合中的历史文本分别输入至语言模型,获得语言模型的第一网络层段输出的第一语义向量,以及语言模型的第二网络层段输出的第二语义向量;其中,第一网络层段的输出信号作为第二网络层段的输入信号;
18、第二语义编码向量获取单元,配置为将第二语义向量进行自编码处理,得到第二语义编码向量;
19、第二异常值获取单元,配置为计算各历史文本对应的第一语义向量与第二语义编码向量之间的异常值;
20、第二待分析文本获取单元,配置为将异常值小于预设异常阈值的历史文本作为待分析文本。
21、在一实施例中,该用户类目识别装置还包括:
22、第一训练文本输入模块,配置为将训练文本输入至待训练的语言模型;
23、第一训练模块,配置为基于预设的判别器对待训练的语言模型的第一网络层段输出的语义向量进行预测,并根据所得到的预测值对待训练的语言模型的第一网络层段进行训练,得到训练后的语言模型;
24、第二训练文本输入模块,配置为将训练文本输入至训练后的语言模型;
25、第二训练模块,配置为基于训练后的语言模型的第一网络层段输出的语义向量和训练后的语言模型的第二网络层段输出的语义向量,对训练后的语言模型的第二网络层段进行训练,得到用于接收所述历史文本集合中的历史文本输入的语言模型。
26、在一实施例中,在对待训练的语言模型的第一网络层段进行训练处理时,还对判别器进行训练处理;第二训练模块包括:
27、训练编码向量获取单元,配置为对训练后的语言模型的第二网络层段输出的语义向量进行自编码处理,得到训练编码向量;
28、第二训练单元,配置为基于训练编码向量和训练后的语言模型的第一网络层段对应输出的语义向量,对训练后的语言模型的第二网络层段进行训练处理,直至经过训练处理后的判别器针对第一网络层段输出的语义向量所得到的第一预测值,以及针对训练编码向量所得到的第二预测值之间的误差在预设误差阈值内。
29、在一实施例中,分类模块包括:
30、多维向量获取单元,配置为将多个待分析语义向量和对应的语义权重值进行加权聚合处理,得到用户对应的多维向量;
31、分类单元,配置为对多维向量经映射处理所得到的标量进行预测,以得到用户所属的类目。
32、根据本技术实施例的一个方面,提供了一种电子设备,包括一个或多个处理器;存储装置,用于存储一个或多个计算机程序,当所述一个或多个计算机程序被所述一个或多个处理器执行时,使得所述电子设备实现如上所述的用户类目识别方法。
33、根据本技术实施例的一个方面,提供了一种计算机可读存储介质,其上存储有计算机可读指令,当所述计算机可读指令被计算机的处理器执行时,使计算机执行如上所述的用户类目识别方法。
34、根据本技术实施例的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述各种可选实施例中提供的用户类目识别方法。
35、根据本技术实施例的一个方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如上所述的用户类目识别方法中的步骤。
36、在本技术的实施例所提供的技术方案中,是利用用户的多个待分析文本共同进行用户类目的预测,并且在预测过程中通过语义向量与语义编码向量之间的异常值过滤掉无效、低质的文本,能够提高多个待分析文本的质量,还通过为多个待分析文本分配语义权重值,以对多个待分析文本中的有效语义进行筛选,从而能够实现对真实用户类目的精准预测。
37、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!