基于三分图视觉Transformer语义信息解码器的抠图方法与装置
基于三分图视觉transformer语义信息解码器的抠图方法与装置
技术领域
1.本发明属于深度学习和计算机视觉技术领域,更具体地,涉及一种基于三分图视觉transformer语义信息解码器的抠图方法与装置。
背景技术:
2.图像抠图是计算机视觉中的一项重要任务。它可以被广泛应用在诸如图像编辑,图像合成,特效制作等任务之中。在过去的几十年里,涌现出了大量抠图的方法:如基于采样的方法或基于传播的方法。然而,由于这些方法通常使用的是人工构造的特征,这些特征往往受制于像素点的颜色、距离等,这使得它们很难处理复杂、需要更多语义信息的情况。
3.抠图任务用公式可表示为:i=αf+(1-α)b,其中i表示原图,f表示前景图片,b表示背景图片,α表示前景的透明度。求解抠图问题,即求解上式中的α值。然而,由于前景图片f和背景图片b均未知,这使得这一问题在传统思路里为欠约束问题。为此,人们提出了三分图的概念。如下图1所示,三分图是一种人工绘制的提示性图片,它将图片分为了确定前景,确定背景和不确定区域。在确定区域α=1/0,不确定区域即为待求解区域。通过使用三分图,上式变得可解。三分图的使用,也沿用到了后来的基于深度学习的抠图方法中。
4.近年来,随着深度学习的发展,计算机视觉领域取得了突破性的进步。在计算机视觉下游的图像抠图领域中,已经出现了大量基于卷积神经网络的抠图方法,这些方法推动了图像抠图领域的发展。然而,随着视觉transformer的快速发展,视觉transformer已经逐渐取代卷积神经网络,成为了计算机视觉领域的主流趋势。一方面,视觉transformer的注意力机制可以使得网络的感受野大幅度提高,提取语义信息的能力增强,从而提升了算法的精度。另一方面,视觉transformer可以被大量数据进行预训练,经过预训练的视觉transformer可以在下游任务中表现出更优秀的性能。
技术实现要素:
5.针对现有技术的以上缺陷或改进需求,本发明提供了一种基于三分图视觉transformer语义信息解码器的图像抠图方法,通过本发明设计的三分图视觉transformer语义信息解码器和抠图解码器,提升抠图性能。
6.为实现上述目的,按照本发明的一个方面,提供了一种基于三分图视觉transformer语义信息解码器的抠图方法,包括如下步骤:
7.(1)用连续的卷积层构建起一个轻量化的细节特征提取层,使用该特征提取层处理图片i,得到细节特征图组{d1,d2,d3,d4};
8.(2)使用三分图视觉transformer语义信息解码器处理细节特征图d4和三分图trimap,得到语义特征图s4;
9.(3)通过连续使用抠图解码器,处理上层语义特征图和对应细节特征图,得到融合语义特征图以及层级抠图输出;
10.(4)在训练数据集上训练由步骤(1)-(3)构建的基于三分图视觉transformer解码器的抠图网络至收敛;
11.(5)使用步骤(4)训练好的抠图网络处理待抠图图片,最后一层抠图解码器输出的层级抠图输出结果,即为最终的抠图结果。
12.本发明的一个实施例中,所述三分图视觉transformer语义信息解码器通过以下步骤实现:
13.(2.1)记输入原始图片i的维度为(h,w,3),则输入的原始三分图trimap的维度为(h,w,1),细节特征图d4的维度为使用最近邻插值下采样trimap,并在在第三维度上升维至与细节特征图d4维度相同,得到triamp
′
,其维度为
14.(2.2)将处理后的三分图triamp
′
与细节特征图d4相加,并通过一个线性层;将线性层的输出结果与细节特征图d4相加,构建基于三分图的残差结构,最终得到语义特征图s
tri
;
15.(2.3)级联朴素视觉transformer层,构建朴素视觉transformer;
16.(2.4)根据已有的掩码自编码器方法在图像分类数据集上预训练朴素视觉transformer,得到模型的预训练权重。
17.本发明的一个实施例中,所述抠图解码器通过以下步骤实现:
18.(3.1)在抠图解码器mdi中,先将来自于上层抠图解码器或三分图视觉transformer语义信息解码器的上层语义特征图s
i+1
进行双线性插值上采样,并通过卷积层,得到语义特征图s
i+1
′
;
19.(3.2)将语义特征图s
i+1
′
和细节特征图di拼接,得到中间特征图msi,将msi通过卷积层,生成新的融合语义特征图si;并且将msi进行反卷积,然后进行三个轻量化卷积同时使用归一化指数函数,得到层级抠图输出αi;
20.(3.3)在训练时,使用损失函数对所有的层级抠图输出进行监督,对已经训练好的网络,使用最后一层抠图输出α1为最终抠图结果。
21.本发明的一个实施例中,所述步骤(2.2)的计算公式为s
tri
=d4+linear(d4+triamp
′
),其中linear表示线性层。
22.本发明的一个实施例中,所述线性层采用全零初始化。
23.本发明的一个实施例中,在所述步骤(2.3)中,每层朴素视觉transformer层block_n,将中间语义特征图ms
n-1
映射为矩阵查询矩阵qn,键矩阵kn和值矩阵vn,通过自注意力机制和线性层,得到新的中间语义特征图msn。
24.本发明的一个实施例中,在所述步骤(2.4)中进行训练时,使用mae预训练后的朴素视觉transformer权重对所述朴素视觉transformer模块进行初始化。
25.本发明的一个实施例中,所述步骤(3.2)的计算公式为:
[0026][0027]
si=conv(msi)
[0028]
αi=softmax(convs(transconv(msi)))
[0029]
其中,upsample表示双线性插值上采样,表示拼接操作,transconv表示反卷积,
conv表示卷积,convs表示连续卷积,softmax表示归一化指数函数。
[0030]
本发明的一个实施例中,在所述步骤(3)中,对层级抠图输出采用深度监督的训练策略。
[0031]
按照本发明的另一方面,还提供了一种基于三分图视觉transformer语义信息解码器的抠图装置,包括至少一个处理器和存储器,所述至少一个处理器和存储器之间通过数据总线连接,所述存储器存储能被所述至少一个处理器执行的指令,所述指令在被所述处理器执行后,用于完成上述的基于三分图视觉transformer语义信息解码器的抠图方法。
[0032]
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有如下有益效果:
[0033]
本发明提供了一种基于三分图视觉transformer语义信息解码器的图像抠图方法。通过本发明设计的三分图视觉transformer语义信息解码器,大幅度提升了抠图网络的语义信息提取能力和三分图信息提取能力。并且本发明还设计了一个抠图解码器,能够更加高效地融合语义信息和细节信息,并对网络提供深度监督,进一步提升了抠图的性能。
附图说明
[0034]
图1是本发明实施例中一种三分图示例图;
[0035]
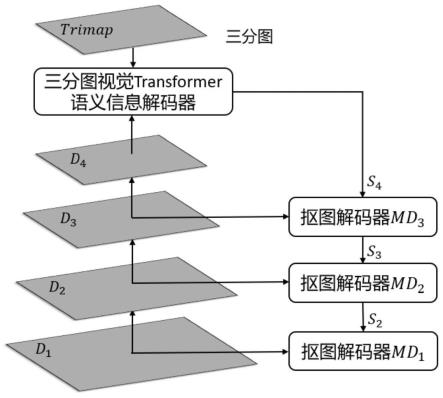
图2是本发明实施例中一种基于三分图视觉transformer语义信息解码器的抠图网络的原理示意图;
[0036]
图3是本发明实施例中一种三分图视觉transformer语义信息解码器的原理示意图;
[0037]
图4是本发明实施例中一种抠图解码器的原理示意图。
具体实施方式
[0038]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0039]
图2是本发明实施例中一种基于三分图视觉transformer语义信息解码器的抠图网络的原理示意图。如图2所示,本发明提供了一种基于三分图视觉transformer语义信息解码器的抠图方法,包括:
[0040]
(1)用连续的卷积层构建起一个轻量化的细节特征提取层,使用该特征提取层处理图片i,得到细节特征图组{d1,d2,d3,d4};
[0041]
(2)使用三分图视觉transformer语义信息解码器处理细节特征图d4和三分图trimap,得到语义特征图s4;
[0042]
(3)通过连续使用抠图解码器,处理上层语义特征图和对应细节特征图,得到融合语义特征图以及层级抠图输出;
[0043]
(4)在训练数据集上训练由步骤(1)-(3)构建的基于三分图视觉transformer语义信息解码器的抠图网络至收敛;
[0044]
(5)使用步骤(4)训练好的抠图网络处理待抠图图片,最后一层抠图解码器输出的
层级抠图输出结果,即为最终的抠图结果。
[0045]
进一步地,如图3所示,所述步骤(2)中的三分图视觉transformer语义信息解码器通过以下步骤实现:
[0046]
(2.1)记输入原图i的维度为(h,w,3),则输入的原始三分图trimap的维度为(h,w,1),细节特征图d4的维度为使用最近邻插值下采样trimap,并在在第三维度上升维至与细节特征图d4维度相同,得到triamp
′
。其维度为
[0047]
(2.2)将处理后的三分图triamp
′
与细节特征图d4相加,并通过一个线性层;将线性层的输出结果与细节特征图d4相加,构建基于三分图的残差结构。最终得到语义特征图s
tri
,如下公式所示,其中linear表示线性层:
[0048]stri
=d4+linear(d4+triamp
′
)
[0049]
步骤(2.1)和本步骤共同构建了如图2所示的基于三分图的语义信息提取模块。在训练时,该模块的线性层采用全零初始化。
[0050]
(2.3)根据已有方法,级联朴素视觉transformer层,构建朴素视觉transformer。其中,每层朴素视觉transformer层block_n,将中间语义特征图ms
n-1
映射为矩阵查询矩阵qn,键矩阵kn和值矩阵vn,通过自注意力机制和线性层,得到新的中间语义特征图msn。
[0051]
(2.4)根据已有的掩码自编码器mae(masked autoencoders)方法在图像分类数据集上预训练朴素视觉transformer,得到模型的预训练权重;训练时,使用mae预训练后的朴素视觉transformer权重对本发明中对应的朴素视觉transformer模块进行初始化。至此,我们完成了三分图视觉transformer语义信息解码器功能的构建。
[0052]
进一步地,如图4所示,所述步骤(2)中的抠图解码器通过以下步骤实现:
[0053]
(3.1)在抠图解码器mdi中,先将来自于上层抠图解码器或三分图视觉transformer语义信息解码器的上层语义特征图s
i+1
进行双线性插值上采样,并通过卷积层,得到语义特征图s
i+1
′
;
[0054]
(3.2)将语义特征图s
i+1
′
和细节特征图di拼接,得到中间特征图msi。将msi通过卷积层,生成新的融合语义特征图si;同时,将msi进行反卷积,然后进行三个轻量化卷积同时使用归一化指数函数,得到层级抠图输出αi。如下公式所示,其中,upsample表示双线性插值上采样,表示拼接操作,transconv表示反卷积,conv表示卷积,convs表示连续卷积,softmax表示归一化指数函数:
[0055][0056]
si=conv(msi)
[0057]
αi=softmax(convs(transconv(msi)))
[0058]
(3.3)在训练时,使用损失函数对所有的层级抠图输出进行监督。对已经训练好的网络,使用最后一层抠图输出α1为最终抠图结果。至此,完成了抠图解码器的功能。
[0059]
进一步地,本发明还提供了一种基于三分图视觉transformer语义信息解码器的抠图装置,包括至少一个处理器和存储器,所述至少一个处理器和存储器之间通过数据总线连接,所述存储器存储能被所述至少一个处理器执行的指令,所述指令在被所述处理器执行后,用于完成上述的基于三分图视觉transformer语义信息解码器的抠图方法。
[0060]
本发明通过使用基于三分图视觉transformer语义信息解码器的网络架构,在基于三分图数据集的compositional-1k进行测试,超过了目前最先进的抠图方法,达到了目前最佳的抠图性能。
[0061][0062]
表1在compositional-1k的测试结果
[0063]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1