基于注意力机制的空间目标小样本识别方法
1.本发明涉及计算机视觉技术领域,具体涉及空间目标小样本识别技术领域,更具体地涉及一种基于注意力机制的空间目标小样本识别方法。
背景技术:
2.近年来,人类航天探索活动日益频繁,各国在轨道空间目标数量陡增,对空间目标进行碰撞预警对保障我国空间站与各种高价值空间目标的在轨安全具有十分重要的意义。空间态势感知技术通过长时间监测非合作空间目标的位置和运动状态信息用于确定其状态、属性以及意图,是目前空间安全问题的主要应对和防范手段。空间目标识别技术是空间态势感知的一项基础性关键技术,其主要任务是利用空间目标图像对目标身份进行识别,便于后续对目标信息(属性、功能与意图)进一步判读。
3.由于天基光学观测成本等原因,空间目标图像数量非常稀少,常规基于深度学习的图像识别方法训练非常依赖大量数据样本,因此常规深度学习方法难以解决这类小样本识别任务。另外,当前适用于小样本任务的主流基于度量学习的小样本图像识别方法的应用对象主要是人物、动物、生活物品等生活场景,针对空间目标的专用小样本识别方法在行业内依然是空白。因此,研究在训练样本量受限条件下,空间图像专用小样本目标识别方法是一件亟待解决又极具挑战性的技术问题。
4.目前,将常规小样本图像识别方法直接用于空间目标识别任务存在以下三点困难:(1)训练样本数量较少,特征提取网络较浅导致特征提取能力有限,样本特征具有局限性;(2)空间图像宽幅大场景、光照不均及过曝严重等特点,进一步增加特征提取难度,使得前述问题(1)更加凸显;(3)小样本识别方法模型学习的是不同特征之间距离,无论支持样本还是查询样本都难以获取类别信息;尤其对于具有光照不均与过曝严重特点的空间图像,卷积网络未能捕捉到目标实例特征,而往往更关注光照不均“噪声”部分,造成在度量空间中目标特征的“误对齐”,严重影响小样本目标识别精度。
技术实现要素:
5.有鉴于此,本发明提供了一种基于注意力机制的空间目标小样本识别方法,以解决对于具有光照不均与过曝严重特点的空间图像,现有的空间目标小样本识别的精度不高的技术问题。
6.本发明提供的基于注意力机制的空间目标小样本识别方法,包括:获取支持样本集和查询样本集,其中,支持样本集包括多个已标记的空间图像样本,查询样本集为多个未标记的空间图像样本;使用支持样本集和查询样本集作为训练数据,来训练空间目标识别网络模型,空间目标识别网络模型依次包括特征提取网络、特征对齐网络和度量网络,其中,特征提取网络对输入的支持样本集和查询样本集进行浅层特征提取,获得查询样本集的原始特征图xq和支持样本集的原始特征图;特征对齐网络对原始特征图xq和进行空间目标实例的特征对齐,生成查询样本集的重构特征图和支持样本集的重构特征图
;度量网络将支持样本集的类别标签通过距离度量方式或相似性度量方式传播至查询样本集的核心网络;将待识别图像输入训练好的空间目标识别网络模型,输出待识别图像的预测类别。
7.与现有技术相比,本发明提供的基于注意力机制的空间目标小样本识别方法,至少具有以下有益效果:(1)可对宽幅大场景空间图像中的目标实例实现语义特征对齐,抑制目标特征“误对齐”现象,增强同类别样本特征相关性以及不同类别样本特征可分离性,大幅提高空间目标小样本识别的精度;(2)提出了一种基于多尺度注意力机制的语义特征对齐结构,用于查询样本特征图和支持样本特征图的相关性目标特征建模,以实现目标语义特征对齐,提高同类别的支持样本、查询样本特征图的特征相关性以及特征可分离性;(3)在msafa特征对齐结构基础上,提出了基于注意力机制的空间目标识别模型,通过将msafa结构嵌入现有的小样本识别网络中,提高了空间目标小样本识别方法的性能;(4)提出在空间目标识别网络模型的训练过程中使用查询分类损失函数的策略,降低网络训练难度,加速网络收敛。
附图说明
8.通过以下参照附图对本发明实施例的描述,本发明的上述以及其他目的、特征和优点将更为清楚,在附图中:图1示意性示出了根据本发明实施例的基于注意力机制的空间目标小样本识别方法的流程图;图2示意性示出了根据本发明实施例的特征对齐网络的实现流程图;图3示意性示出了根据本发明实施例的特征对齐网络的结构图;图4示意性示出了根据本发明实施例的空间目标识别网络模型的结构图。
具体实施方式
9.为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
10.在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本发明。在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
11.在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
12.在人类学习行为模式启发下,本发明提供了一种基于注意力机制的空间目标小样本识别方法,可对宽幅大场景空间图像中的目标实例实现语义特征对齐,抑制目标特征“误对齐”现象,增强同类别样本特征相关性以及不同类别样本特征可分离性,大幅提高空间目
标小样本识别的精度。
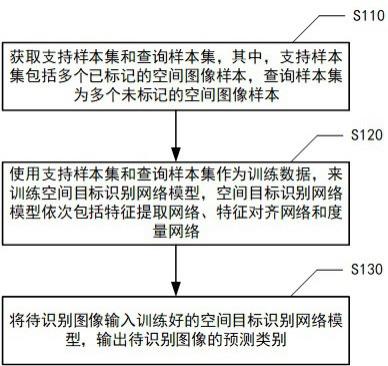
13.图1示意性示出了根据本发明实施例的基于注意力机制的空间目标小样本识别方法的流程图。
14.如图1所示,根据该实施例的基于注意力机制的空间目标小样本识别方法,可以包括操作s110~操作s130。
15.在操作s110,获取支持样本集和查询样本集,其中,支持样本集包括多个已标记的空间图像样本,查询样本集为多个未标记的空间图像样本。
16.在操作s120,使用支持样本集和查询样本集作为训练数据,来训练空间目标识别网络模型,空间目标识别网络模型依次包括特征提取网络、特征对齐网络和度量网络。
17.其中,特征提取网络对输入的支持样本集和查询样本集进行浅层特征提取,获得查询样本集的原始特征图xq和支持样本集的原始特征图;特征对齐网络对原始特征图xq和进行空间目标实例的特征对齐,生成查询样本集的重构特征图和支持样本集的重构特征图;度量网络将支持样本集的类别标签通过距离度量方式或相似性度量方式传播至查询样本集的核心网络。
18.在操作s130,将待识别图像输入训练好的空间目标识别网络模型,输出待识别图像的预测类别。
19.通过本发明的实施例,根据支持样本集和查询样本集,采用嵌入特征对齐网络的空间目标识别网络模型来训练,得到最终训练好的空间目标识别网络模型,以对待识别图像进行类别预测,从而得到更准确的预测结果。本发明实施例可对宽幅大场景空间图像中的目标实例实现语义特征对齐,抑制目标特征“误对齐”现象,增强同类别样本特征相关性以及不同类别样本特征可分离性,大幅提高空间目标小样本识别的精度。
20.本实施例中,特征对齐网络是一种基于多尺度注意力机制的语义特征对齐结构(multi-scale attention features align block, 简称msafa block或者msafa结构)。msafa结构引入的想法是受人类在小样本情况下学习行为启发,一般来说,为了在给定极少量标记图像样本(支持样本集)的情况下识别未知类别图像样本(查询样本集),人类倾向于首先在标记图像和未知类别图像中查找并定位两者中最相关的区域,再综合对比两张图相似性。
21.类似地,在现有小样本识别网络中,对于给定支持样本特征图和查询样本特征图,msafa结构分别为每个特征图生成一个注意力特征图以凸显和加强图像中的目标实例对象,从而实现特征图中的目标实例特征对齐,增强同类别的支持、查询样本的特征相关性,提高不同类别支持、查询样本的特征可分离性,最终降低关系网络的学习难度并提升小样本分类网络的精度。另外,本发明实施例提出的msafa结构也可以帮助卷积层提取更具辨识力的特征。
22.msafa结构的核心任务是对查询样本的原始特征图xq和支持样本的原始特征图xs中不同地物实例进行特征建模,因此msafa结构的输入数据为原始特征图xq和xs,输出为实现特征对齐后的重构特征图和。
23.将msafa结构输入的查询样本的原始特征图xq和支持样本的原始特征图xs表示为:
式中,n=h
×
w,h是输入特征图高度,w是输入特征图高度宽度;c是输入特征图的通道数量;是原始特征图xq中的第j个特征点;是原始特征图xs中的第i个特征点。
24.以下以实现特征对齐后的重构特征图为例,进一步说明msafa结构的处理过程。
25.图2示意性示出了根据本发明实施例的特征对齐网络的实现流程图。图3示意性示出了根据本发明实施例的特征对齐网络的结构图。
26.结合图2和图3所示,本实施例中,在上述操作s120中,特征对齐网络对原始特征图xq和xs进行目标实例的特征对齐,生成查询样本集的重构特征图和支持样本集的重构特征图,可以进一步包括操作s1201~操作s1205。
27.在操作s1201,分别将查询样本集的原始特征图xq和支持样本集的原始特征图xs线性映射到嵌入特征空间中,获得编码特征。
28.在操作s1202,根据编码特征,生成对应的新特征图。
29.具体地,根据以下公式将原始特征图xq和xs线性映射到嵌入特征空间(embedding space)中,可以得到全新的编码特征::::式中,是线性映射矩阵,它们都是1
×
1卷积层中可学习的网络参数;是映射到嵌入特征空间中新特征图的特征通道维数;i、j、l、u是特征图中特征点的序列号。
30.由此,新特征图表示如下:表示如下:
其中,i、j、l、u取值均从1到n。
31.在操作s1203,对新特征图和分别采用不同参数设置的均值池化层进行下采样,生成多尺度的金字塔特征图。
32.生成的多尺度金字塔特征图(multi-scale pyramid feature maps,简称mpf)如以下公式所示:以下公式所示:以下公式所示:以下公式所示:式中,apm(
·
)表示采用多种参数设置的均值池化层操作,具体经过均值池化后输出特征图尺寸如下表1所示:其中,pool-1、pool-2、pool-3、pool-4、pool-5依次表示五个池化层操作。
33.然后,在操作s1204,将金字塔特征图和在空间维展开,利用高斯核函数计算分布在嵌入特征空间内的金字塔特征图的任一特征点和一编码特征点之间的相似度,以及金字塔特征图的另一特征点和另一编码特征点之间的相似度,获得注意力权重矩阵s
qs
和s
sq
。
34.其中,将金字塔特征图和在空间维展开,可得到:展开,可得到:展开,可得到:展开,可得到:式中,t为在空间维展开过程的中间系数;v、w、k、m是特征图中特征点的序列号。
35.利用高斯核函数计算分布在嵌入特征空间内的金字塔特征图的任一特征点和一编码特征点之间的相似度,以及金字塔特征图的另一特征点和另一编码特征点之间的相似度,获得注意力权重矩阵s
qs
和s
sq
,具体公式计算如下:式计算如下:其中,为查询样本的第j个编码特征点;为支持样本的第i个编码特征点;为支持样本的一金字塔特征图在空间维展开后的第k个特征点; 为查询样本的金字塔特征图在空间维展开后的第v个特征点。
36.需要说明的是,以上注意力权重矩阵的计算公式的具体编程可以利用softmax函数来实现。由此,获得的注意力权重矩阵s
qs
和s
sq
具体如下式来表示:具体如下式来表示:在操作s1205,使用所述注意力权重矩阵s
qs
和s
sq
作为权重系数,分别用嵌入特征空间中的所述金字塔特征图和作为重构基底,生成所述查询样本集的重构特征图和支持样本集的重构特征图。
37.具体如下式所示:具体如下式所示:经过上述处理,可以实现对查询样本的原始特征图xq和支持样本的原始特征图xs中的多个地物目标实例特征进行相关性建模,在大量数据训练以及学习过程中,实现对两张特征图中目标实例的特征对齐。
38.针对空间目标识别任务中训练样本量严重受限问题,结合本发明实施例提出的msafa结构的特征对齐优势,本发明实施例提出了基于注意力机制的空间目标识别网络模型。
39.图4示意性示出了根据本发明实施例的空间目标识别网络模型的结构图。
40.如图4所示,本发明实施例中的空间目标识别网络模型依次包括特征提取网络、特征对齐网络和度量网络三个部分。
41.由于训练样本量严重不足,特征提取网络是一个由9个卷积层构成的浅层网络,负责对输入的查询样本集和支持样本集图像进行特征提取。特征对齐网络的核心是msafa结构。度量网络将支持样本集的类别标签通过距离度量方式或相似性度量方式传播至查询样本集的核心网络。
42.具体地,度量网络可分成两部分组成:1)特征再提取模块;2)关联层(correlation layer)和查询分类器(query classifier)。
43.特征再提取模块对经过msafa结构进行特征对齐的查询样本的重构特征图和支持样本集的重构特征图进行二次特征提取,获得查询样本和支持样本集的目标类别实例特征,以进一步挖掘目标类别实例特征。
44.查询分类器只在空间目标识别网络模型的训练过程中使用,通过引入查询样本的类别信息,以优化特征提取网络的参数,从而尽可能地改善特征提取网络性能,同时加强网络挖掘类别实例特征能力。另外,在预测推理过程中不考虑查询分类器预测结果。
45.针对小样本任务特点以及加强类别实例特征抓取能力要求,本实施例中,采用近邻分类损失函数(nearest neighbor classifier loss,nnc loss)和查询分类损失函数(query classifier loss,qc loss)的联合训练策略,来训练空间目标识别网络模型。
46.1、近邻分类损失函数本实施例中,近邻分类损失函数根据以下方式来构建:以支持样本集的重构特征图为参考,度量查询样本的原始特征图xq与支持样本的重构特征图中的每个特征点的距离,利用最近距离对查询样本的类别标签进行分类。
47.具体地,通过关联层(correlation layer)实现对两个特征之间的相似性度量,对于第i个查询样本,通过近邻分类器在支持样本集c个的类别标签上通过相似性度量可以生成类似于softmax的标签分布。
48.第i个查询样本的原始特征图预测为第k类的概率为:其中,c是当前任务batch中支持样本集的类别总数;是第i个查询样本的原始特征图经过全局均值池化(global average pooling,gap)操作后形成的特征向量;是所述支持样本集的重构特征图中的第j种类别特征向量;d(
·
)表示余弦距离。
49.值得注意的是,在度量查询样本的原始特征图xq与每个支持样本的重构特征图的距离之前,还需要对经过全局均值池化操作后的第i个查询样本的特征向量和第j种
类别特征向量进行l2范数特征标准化处理。
50.然后,近邻分类损失函数l1可以描述为:其中,nq是一个批处理batch中查询样本的数量。
51.2、查询分类损失函数为了加强网络提取类别实例特征进一步改善特征度量学习性能,本发明实施例提出在网络训练过程中使用查询分类损失函数的策略。使用全连接层(fully connection layer,fc layer)构成查询分类器(query classifier),然后使用softmax函数对所有可用的训练类别中的每个查询样本进行分类。
52.需要强调的是,查询分类器只在网络训练过程中起作用,通过引入更多的类别信息帮助特征提取网络更好地强化特征提取能力,尽可能捕捉类别实例特征;当网络进行预测推理时,查询分类器预测结果被屏蔽。
53.假设支持样本集中的所有可见类别总数为c,则每一个查询样本的原始特征图,对应的分类置信概率为,则查询分类损失函数根据以下方式来构建:其中,nq是一个批处理batch中查询样本的数量;y
ik
是第i个查询样本中的第k个指示变量,取值为0或1,当该类别与第i个查询样本的类别相同即取1,否则取0;是第i个查询样本属于类别k的预测概率。
54.本实施例中,空间目标识别网络模型的总损失函数为近邻分类损失函数和查询分类损失函数的加权和。
55.总损失函数l定义如下:式中,λ为超参数,是为了平衡两种不同损失函数影响力的指标。在实验编程中,超参数λ可以取0.5。
56.通过优化总损失函数l,可以实现对整个空间目标识别网络模型进行端到端训练。
57.综上所述,本发明实施例提供一种基于注意力机制的空间目标小样本识别方法,实现目标实例特征对齐以提高特征可分离性,可适用于在空间目标小样本识别任务,提升当前网络分类性能。并且,方法结构采用模块化设计;即插即用,适应性强,可针对所有基于度量学习网络结构,具有一定算法普适性。
58.附图中示出了一些方框图和/或流程图。应理解,方框图和/或流程图中的一些方框或其组合可以由计算机程序指令来实现。这些计算机程序指令可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器,从而这些指令在由该处理器执行时可以创建用于实现这些方框图和/或流程图中所说明的功能/操作的装置。
59.此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性
或者隐含指明所指示的技术特征的数量。因此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个、三个等,除非另有明确具体的限定。此外,位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。
60.以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1