一种用于fpga芯片的装箱方法
技术领域
1.本发明涉及一种用于fpga芯片的装箱方法,属于电子设计自动化技术领域。
背景技术:2.fpga芯片上逻辑资源可以被划分为若干tile,例如通用逻辑块(clb),块存储单元(ram)以及乘法器(dsp)。每个tile类型都包含了若干site,例如clb下的slice。每个site下还包含多个基本逻辑单元(ble)。基本逻辑单元中包含逻辑上不可拆分的原语,比如查找表(lut)、触发器(ff)。此外,tile之间通过可配置的开关矩阵和互连线进行连接。
3.在使用芯片设计电路时,用户首先用硬件描述语言(hdl)将待实现的电路进行文本化描述。然后,使用电子设计自动化软件(eda)对电路进行编译,最终将电路转为比特流。最后,比特流对芯片内部的结构进行配置,从而在芯片上实现目标电路功能。fpga的eda流程通常包括综合、装箱、布局和布线。综合是将用户电路转换为lut、ff等原语级网表。装箱将lut、ff等原语打包成tile模块,比如clb。布局则是将tile级模块放置到合适的位置。布线作为最后一步,将tile模块通过布线资源连接。装箱作为综合后的第一步,其结果影响着布局布线的质量。
4.早期fpga的结构较简单,ble由lut与ff组成。针对此结构,betz v在1997年提出了vpack算法,首先将lut与ff打包成基本逻辑单元(ble),再将ble打包成clb。rose j在1999年提出了t-vpack算法,在vpack的基础上加入了时序优化,与vpack相比,关键路径延时降低了7%,使用的通道数减少了12%。dppack在t-vpack的代价函数中加入了曼哈顿距离,布局布线后比t-vpack减少了16%的总线长以及8%的关键路径延时。
5.随着工艺的进步,fpga的结构变得复杂,ble中已经包含了可拆分lut和可配置的ff,ble之间加入了多路选择器以及加法器。针对复杂结构,luu j在2014年提出了aapack算法,在装箱之前先进行预装箱,即先将原语打包成分子,再对分子进行装箱。rsvpack算法是travis haroldsen在2016年提出的,针对xilinx v6架构,拉近了学术界与工业界的距离,但不具有通用性。betz v团队在2020年的vtr8.0中对aapack算法进行了改进,在种子选取、吸引力函数等方面进行了优化。
6.现代fpga中不仅包含clb和io,还引入了dsp与ram。随着dsp、ram等模块的引入,用户设计的电路有了新的特性。这类原语的面积较大,是clb的几倍或者几十倍甚至更高。原语的端口较多且端口之间关联性较差。
技术实现要素:7.本发明要解决的技术问题是:针对dsp和ram的特性对装箱算法进行改进,一种用于fpga芯片的装箱方法的方法。
8.为了解决上述技术问题,本发明提出的技术方案是:一种用于fpga芯片的装箱方法,执行如下步骤:
9.1)归类特殊原语,将fpga中的用户网表中符合特殊原语判定条件的dsp和ram归类
为特殊原语;
10.所述特殊原语判定条件,
[0011][0012]
其中num
dsp
为用户网表中dsp的数量,num
ram
为用户网表中ram的数量,num
adder
为用户网表中加法器的数量,num
total
为用户网表中原语的总数量,thre为阈值;
[0013]
2)预处理,将部分原语打包;采用现有技术论文“architecture-aware packing and cad infrastructure for field-programmable gate array”中第61页的4.3.3节pre-packing部分。
[0014]
3)判断是否有未装箱分子,若无则结束,若有则下一步;
[0015]
4)通过种子收益模型选择收益值最大的原语作为种子;
[0016]
所述种子收益模型为,
[0017]
seed_gain=w1*num
in
+w2*num
used_in
+w3*num
block
+w4*crit+w5*i
special
,
[0018]
其中,num
in
为作为种子的原语的输入引脚数与所有原语中最大输入引脚数的比值,num
used_in
为作为种子的原语使用的输入引脚数与原语的输入引脚数的比值,num
block
为作为种子的原语所在分子内的原语数与最大分子内原语数量的比值,crit为原语引脚的延时,i
special
用于判断当前原语是否为特殊原语,w1、w2、w3、w4、w5为权值;
[0019]
5)根据待装箱tile与原语之间的连接关系使用不同的装箱收益模型;
[0020]
所述装箱收益模型分别为,与所述待装箱tile直接连接的原语装箱收益模型、与所述待装箱tile通过特殊原语间接连接的原语装箱收益模型、与所述待装箱tile通过普通原语间接连接的原语装箱收益模型、所述待装箱tile通过高扇出连接的原语装箱收益模型;
[0021]
6)引脚利用率判断,若符合要求返回步骤3)。
[0022]
上述技术方案的改进是:步骤4)中的所述w1、w2、w3、w4、w5分别为0.5、0.2、0.2、0.1和0.1。
[0023]
上述技术方案的改进是:所述fpga芯片中dsp、ram以及加法器的总占比小于20%。
[0024]
本发明带来的有益效果是:给出了特殊原语判定条件,并确定了特殊原语的适用条件,既不会因电路中ram和dsp的比重高,导致周围原语选择性少;也不会因为电路中加法器比重高,导致使用原语对电路划分会影响其吸收原语,造成资源消耗增加。并增加了特殊原语的权重,使特殊原语优先装箱。改进通过特殊原语与当前tile间接连接的原语的吸引力函数。
附图说明
[0025]
下面结合附图对本发明作进一步说明。
[0026]
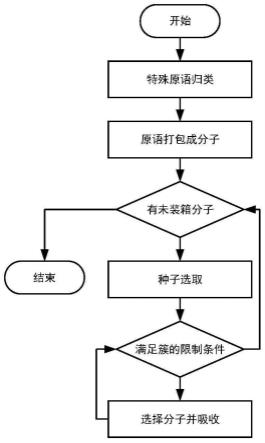
图1是本发明实施例的一种用于fpga芯片的装箱方法的流程示意图。
[0027]
图2是本发明实施例的一种用于fpga芯片的装箱方法中提到的原语与tile的三种连接关系示意图。
[0028]
图3是本发明实施例的一种用于fpga芯片的装箱方法中间接连接的三种方式的示意图。
[0029]
图4是本发明的一种用于fpga芯片的装箱方法的电路中dsp、ram和加法器的比重对关键路径延时的影响的示意图。
[0030]
图5是本实施例的n
dir
变化对关键路径延时的影响示意图。
[0031]
图6是本实施例的w
port
变化对关键路径延时的影响示意图
具体实施方式
[0032]
实施例
[0033]
本实施例的运行环境为linux服务器,cpu为16核32线程3ghz的amd epyc 7302p,运行内存为64g。本发明采用的fpga架构为vtr提供的类agilex架构,但布线结构采用的是类stratix iv。本发明采用的测试案例来自koios测试集。koios测试集包含20个深度学习相关电路,均为中型或大型电路,适用于架构研究与eda算法研究。本发明在运行koios的中型电路时通道宽度为200,大型电路的通道宽度为300。
[0034]
如图1所示,本实施例的一种用于fpga芯片的装箱方法,执行如下步骤:
[0035]
1)归类特殊原语,将fpga中的用户网表中符合特殊原语判定条件的dsp和ram归类为特殊原语;
[0036]
所述特殊原语判定条件,
[0037][0038]
其中num
dsp
为用户网表中dsp的数量,num
ram
为用户网表中ram的数量,num
adder
为用户网表中加法器的数量,num
total
为用户网表中原语的总数量,thre为阈值;
[0039]
其他为满足上述条件的dsp和ram归为普通原语。
[0040]
2)预处理,将部分原语打包;对用户网表中的原语进行预处理,将部分原语打包在一起,用于减少装箱时的复杂度并减少装箱失败的情况。
[0041]
3)判断是否有未装箱分子,若无则结束,若有则下一步;
[0042]
4)通过种子收益模型择收益值最大的原语作为种子;
[0043]
所述种子收益模型为,
[0044]
seed_gain=w1*num
in
+w2*num
used_in
+w3*num
block
+w4*crit+w5*i
special
,
[0045]
其中,num
in
为作为种子的原语的输入引脚数与所有原语中最大输入引脚数的比值,num
used_in
为作为种子的原语使用的输入引脚数与原语的输入引脚数的比值,num
block
为作为种子的原语所在分子内的原语数与最大分子内原语数量的比值,crit为原语引脚的延时,i
special
用于判断当前原语是否为特殊原语,w1、w2、w3、w4、w5为权值;,其中w1、w2、w3、w4、w5分别为0.5、0.2、0.2、0.1和0.1。
[0046]
根据所述种子收益模型,选择收益值最大的原语作为种子。
[0047]
5)根据待装箱tile与原语之间的连接关系使用不同的装箱收益模型;
[0048]
所述装箱收益模型分别为,与所述待装箱tile直接连接的原语装箱收益模型、与所述待装箱tile通过特殊原语间接连接的原语装箱收益模型、与所述待装箱tile通过普通原语间接连接的原语装箱收益模型、所述待装箱tile通过高扇出连接的原语装箱收益模型;
[0049]
构建装箱收益模型,用于表示待装箱的tile周围的原语吸收进tile之后对电路的
影响。原语与tile的连接关系有三种:直接连接、间接连接以及高扇出连接。直接连接是指原语与tile直接相连并且相连的网络扇出小。原语与tile没有直接相连,但是都与同一个tile相连,此类连接关系为间接连接。高扇出连接是指原语与tile直接相连但相连的网络扇出大。
[0050]
参照图2,假设lut1为种子,组成了待装箱tile。ff1与tile直接连接,ff3与tile是高扇出连接,ff6与ff5与tile是间接连接。若ram为特殊原语,则ff6是通过特殊tile与待装箱tile间接连接,ff5是通过普通tile与待装箱tile间接连接。
[0051]
所述装箱收益模型根据tile与原语的连接关系分为4类。第一类为与当前tile直接连接的原语,模型为
[0052][0053]
其中nets(p,b)是分子p与当前tile结构b的共享节点数量,而connections(p,b)和p的引脚与b的连接关系紧密关联,公式如下
[0054][0055]
其中ext(p,b)是p与tileb相连的引脚连接的原语中未装箱的数量,packed(p)为p与tileb相连的引脚连接的原语中已装入其它tile的数量。
[0056]
第二类为与当前tile通过特殊原语间接连接的原语。当前tile与原语通过特殊tile间接连接的方式有三种。一是通过同一个port间接连接,如图3中ff1。二是通过不同port的引脚,但引脚方向相同的原语,如图3中ff2。三是通过不同port的引脚且引脚方向不同的原语,如图3中lut1。
[0057]
通过特殊tile间接连接的原语模型为
[0058]
aff=w
port
*num
port
+w
dir
*num
dir
+w
rev
*num
rev
[0059]
其中,w
port
为通过同一个port间接连接原语的权重,w
dir
为间接连接的引脚方向相同但不属于同一个port的原语权重,w
rev
为间接连接的引脚方向不同的原语的权重,num
port
,num
dir
和num
rev
分别为三种间接连接原语的连接次数。w
dir
公式如下
[0060][0061]
其中,n
dir
为正整数。
[0062]
第三类为与当前tile通过普通原语间接连接的原语,模型为
[0063]
aff=w
indir
*num
indir
[0064]
其中w
indir
为原语与待装箱tile通过普通tile间接连接的权重,num
indir
为原语与待装箱tile通过普通tile间接连接的个数。式中,w
indir
取值0.003。
[0065]
第四类为高扇出连接的原语。当直接连接和间接连接的原语均被装箱且当前tile的限制条件还未满足时,装箱引擎会将高扇出的原语放入当前tile中。
[0066]
根据所述装箱收益模型,不断选择收益值最大的原语吸收进当前tile,直到tile的限制条件不再满足或者周围的原语均被装箱时结束。
[0067]
6)引脚利用率判断,以确定当前tile的引脚利用率,若符合要求返回步骤3)。
[0068]
在实际使用中,dsp和ram不同端口往往连接着不同功能的电路,同一端口间接连接的电路关联性较强。根据dsp和ram在应用电路中的特性,装箱引擎可以将通过dsp和ram间接连接的电路进行优先级划分。装箱主要针对clb中的原语进行打包。电路中ram和dsp的比重高,会使其周围原语装箱时选择变少,尤其对于含有加法器的clb,进而导致资源消耗和关键路径延时增加。因此本实施例要求电路中dsp、ram以及加法器总占比不超过20%。
[0069]
如图4所示,左侧坐标为电路中dsp、ram和加法器的比重,右侧坐标为关键路径延时的优化率。在图4中dsp、ram以及加法器的占比小于20%的12个电路中,有11个电路的关键路径延时都有优化;占比超过20%的8个电路中,有4个电路关键路径延时有增加。以上比较均较于vtr8.0的算法,关键路径延时降低了。
[0070]
从图5和图6可以看出,在测试集中,符合特殊原语条件的电路在w
port
为0.03,w
dir
为0.005,w
rev
为0.001时关键路径延时取得较优结果。表1为本发明装箱方法与vtr8.0在布局布线后的结果对比,其中的电路均为符合特殊原语适用条件的电路,相较于vtr8.0,本发明在资源消耗和运行时间少量增长的代价下,关键路径延时平均降低了8.45%。对不符合特殊原语条件的电路,本发明不改进dsp和ram周围的原语的装箱优先级,所以资源消耗以及关键路径延时与vtr8.0相同。
[0071]
表1本发明装箱方法与vtr8.0在布局布线后的结果对比
[0072]