一种基于图聚合和推理的文本关系抽取方法
1.本发明属于自然语言处理领域,具体涉及一种基于图聚合和推理的文本关系抽取方法。
背景技术:
2.关系抽取是识别文本中一对命名实体之间的语义关系。关系抽取在通过给定文本的未知关系事实构建知识图谱方面发挥着重要作用。以前的工作侧重于句子级的关系抽取,它提取单个句子中实体之间的关系。在现实世界中应用程序,大量关系,例如来自维基百科文章和生物医学的关系事实文学,跨越文章中的多个句子。根据对维基百科语料库的分析,至少40.7%的关系依赖于要提取的文档中多个句子的信息。因此,有必要在文档级别提取关系。
3.以前的研究利用关系抽取来缩短文本跨度。比如说新提出的docred数据集,其中包含许多带有大规模人工注释的文档,推动了句子级关系抽取向文档级关系抽取发展。为了充分利用文档的复杂语义信息,最近的工作设计文档级图并致力于提出了基于图神经网络的模型。比如有人拆分文档级图分成两个有向无环图(dag),并为每个dag使用图lstm来获得每个单词的上下文表示。也有人提出了一种面向边缘的模型,它构造了一个具有不同类型节点和边的文档级图,以获得全局关系分类的表示。同时也有将文档图定义为潜在变量并基于结构化注意力进行诱导以提高文档级关系的性能,通过优化文档图的结构来提取模型。然而,这些发明只是平均提及的嵌入以获得实体嵌入并将它们输入分类器以获得关系标签。此外,每个实体在不同的实体对中具有相同的表示,这可能会引入来自无关上下文的噪音。
技术实现要素:
4.针对现有技术中的上述不足,本发明提供的一种基于图聚合和推理的文本关系抽取方法解决了现有的文档关系抽取过程中不能充分利用文档的语义信息和跨句子实体对之间关系的问题。
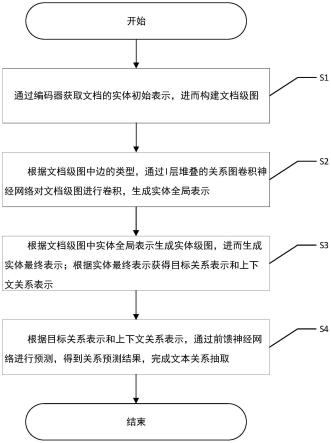
5.为了达到上述发明目的,本发明采用的技术方案为:一种基于图聚合和推理的文本关系抽取方法,包括以下步骤:
6.s1、通过编码器获取文档的实体初始表示,进而构建文档级图;
7.s2、根据文档级图中边的类型,通过l层堆叠的关系图卷积神经网络对文档级图进行卷积,生成实体全局表示;
8.s3、根据文档级图中实体全局表示生成实体级图,进而生成实体最终表示;根据实体最终表示获得目标关系表示和上下文关系表示;
9.s4、根据目标关系表示和上下文关系表示,通过前馈神经网络进行预测,得到关系预测结果,完成文本关系抽取。
10.进一步地:所述步骤s1包括以下分步骤:
11.s11、将bert作为编码器获取文档的嵌入,并通过logsumexp池化层获得文档的实体初始表示;
12.其中,得到所述文档的嵌入h的表达式具体为:
13.h=[h1,h2,
…
,h
k2
]=bert([w1,w2,
…
,w
k1
])
[0014]
式中,w
k1
为文档d的第k1个单词,h
k2
为第k2层bert输出获得的隐藏状态序列;
[0015]
获得文档的实体初始表示的表达式具体为:
[0016][0017]
式中,为包含提及的隐藏状态序列,为提及的总数;
[0018]
s12、根据文档的实体初始表示构建文档级图;
[0019]
其中,所述文档级图包括句子节点和提及节点;
[0020]
所述句子节点的表达式为提及节点的表达式为
[0021]
进一步地:所述步骤s2包括以下分步骤:
[0022]
s21、基于文档级图中句子节点与提及节点,定义文档级图中边的类型,并生成文档级图的边;
[0023]
s22、通过l层堆叠的关系图卷积神经网络对文档级图进行卷积,获取文档级图中边的关系,生成异构图;
[0024]
s23、将异构图输入logsumexp池化层,得到实体全局表示。
[0025]
进一步地:所述步骤s21中,文档级图中边的类型包括提及-提及边缘、提及句子边缘和句子-句子边缘;
[0026]
所述步骤s21具体为:
[0027]
当两个不同的实体初始表示在同一个句子中时,则连接两个不同实体初始表示的提及节点,生成提及-提及边缘;当提及节点在句子中时,则连接提及节点和当前句子中的句子节点,生成提及句子边缘;连接所有句子节点,生成句子-句子边缘。
[0028]
进一步地:所述步骤s22中,l层堆叠的关系图卷积神经网络对节点前向传递更新的表达式具体为:
[0029][0030]
式中,为l层堆叠的关系图卷积神经网络输出的文档级图中节点,和均为l-1层堆叠的关系图卷积神经网络输出的文档级图中节点,σ(
·
)为激活函数,为与边x连接的节点i的邻居集合,为边类型的集合,为可训练的参数矩阵,dn为节点表示的维度。
[0031]
进一步地:所述步骤s23中,计算实体全局表示的表达式具体为:
[0032][0033]
式中,和均为可训练的参数矩阵,为logsumexp池化层输出的实体表示相关函数,为实体初始表示相关函数,ν为标准化特征向量。
[0034]
进一步地:所述步骤s3包括以下分步骤:
[0035]
s31、根据文档级图中实体全局表示生成实体级图,通过l层堆叠的关系图卷积神经网络对实体级图进行卷积,生成实体推理表示,根据实体推理表示和实体全局表示得到实体最终表示;
[0036]
s32、根据实体最终表示和相对距离表示,得到实体对的特定实体表示,连接实体对的特定实体表示得到目标关系表示,根据目标关系表示获得上下文关系表示。
[0037]
进一步地:所述步骤s31中,得到实体最终表示的表达式具体为:
[0038][0039]
式中,和均为可训练的参数矩阵,为实体推理表示,为实体初始表示;
[0040]
所述步骤s32中,实体对的特定实体表示包括第一特定实体表示和第二特定实体表示其表达式具体为:
[0041][0042][0043]
式中,δ
ij
为文档d中实体节点ei的第一次提及到实体节点ej的第一次提及相对距离;δ
ji
为文档d中实体节点ej的第一次提及到实体节点ei的第一次提及相对距离;
[0044]
得到上下文关系表示oc的表达式具体为:
[0045][0046]
式中,w为一个可训练的参数矩阵,目标关系表示oi为第i个实体对的关系表示,o
′r为or的转置,θi为oi的注意力权重,p为实体对的数量。
[0047]
进一步地:所述步骤s4包括以下分步骤:
[0048]
s41、将目标关系表示or和上下文关系表示oc输入前馈神经网络进行预测,得到属于类别r的预测概率;
[0049]
s42、基于属于类别r的预测概率,定义损失函数并通过分类器得到关系预测结果,
完成文本关系抽取。
[0050]
进一步地:所述步骤s41中,得到属于类别r的预测概率yr的表达式具体为:
[0051]
yr=sigmoid(ffnn([or;oc]))
[0052]
式中,ffnn(
·
)为前馈神经网络的预测结果,sigmoid(
·
)为机器学习函数;
[0053]
所述步骤s42中,损失函数的表达式具体为:
[0054][0055]
式中,为r的真实标签,为目标关系表示和上下文关系表示的集合。
[0056]
本发明的有益效果为:本发明提出了一个基于复杂语义信息的文档级图,这是一个异构的过程包含提及节点和句子节点的图形,用于集成文档的丰富语义信息获取实体表示。
[0057]
本发明提出了一种实体级图获取方法,以发现长距离跨句子实体对的一些关系。然后,我们使用注意机制融合实体全局表示、实体推理表示和实体初始表示信息,以提取实体对之间的关系。
附图说明
[0058]
图1为本发明的流程图。
[0059]
图2为本发明的消融研究结果图。
具体实施方式
[0060]
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
[0061]
实施例1:
[0062]
如图1所示,在本发明的一个实施例中,一种基于图聚合和推理的文本关系抽取方法,包括以下步骤:
[0063]
s1、通过编码器获取文档的实体初始表示,进而构建文档级图;
[0064]
s2、根据文档级图中边的类型,通过l层堆叠的关系图卷积神经网络对文档级图进行卷积,生成实体全局表示;
[0065]
s3、根据文档级图中实体全局表示生成实体级图,进而生成实体最终表示;根据实体最终表示获得目标关系表示和上下文关系表示;
[0066]
s4、根据目标关系表示和上下文关系表示,通过前馈神经网络进行预测,得到关系预测结果,完成文本关系抽取。
[0067]
在本实施例中,文档采用docred和化学疾病关系(cdr)数据集。docred数据集是一个大规模的人工注释数据集,由wikipedia和wikidata构建,用于文档级re,共有96种关系类型、132275个实体和56354个关系事实。docred涵盖了与科学、艺术、时间、个人生活等相关的各种关系。化学疾病关系(cdr)数据集是一个人类注释数据集,其专为biocreative v挑战而设计。它由三个子数据集组成,即训练、开发和测试每本书包含500篇关于化学和疾
病的文献。
[0068]
对数据集进行预处理,确定每个数据集的一些参数设定,在模型实现中,选择uncased bert base作为记录并将嵌入维度和隐藏维度设置为768。对于cdr数据集,选择上biobert-base v1.1,重新训练了关于生物医学的bert-based-cased模型。dlg有两层,elg有一层r-gcns。此外,节点的大小图的嵌入是768。所有超参数均根据开发集进行调整。另外网络中的参数都是通过随机正交初始化和在训练期间更新。
[0069]
所述步骤s1包括以下分步骤:
[0070]
s11、将bert作为编码器获取文档的嵌入,并通过logsumexp池化层获得文档的实体初始表示;
[0071]
其中,得到所述文档的嵌入h的表达式具体为:
[0072]
h=[h1,h2,
…
,h
k2
]=bert([w1,w2,
…
,w
k1
])
[0073]
式中,w
k1
为文档d的第k1个单词,h
k2
为第k2层bert输出获得的隐藏状态序列;
[0074]
获得文档的实体初始表示的表达式具体为:
[0075][0076]
式中,为包含提及的隐藏状态序列,为提及的总数;
[0077]
s12、根据文档的实体初始表示构建文档级图;
[0078]
其中,所述文档级图包括句子节点和提及节点;
[0079]
句子节点的表示是通过对包含的单词的表示进行平均来定义,提及节点的表示是通过对包含的单词的表示进行平均来定义。
[0080]
所述句子节点的表达式为提及节点的表达式为
[0081]
在本实施例中,选择bert作为编码器可以更好地捕获文章的语义信息,实体初始表示包含多个提及,通过logsumexp池化层可以获得实体初始表示。
[0082]
所述步骤s2包括以下分步骤:
[0083]
s21、基于文档级图中句子节点与提及节点,定义文档级图中边的类型,并生成文档级图的边;
[0084]
s22、通过l层堆叠的关系图卷积神经网络对文档级图进行卷积,获取文档级图中边的关系,生成异构图;
[0085]
s23、将异构图输入logsumexp池化层,得到实体全局表示。
[0086]
所述步骤s21中,文档级图中边的类型包括提及-提及边缘、提及句子边缘和句子-句子边缘;
[0087]
所述步骤s21具体为:
[0088]
当两个不同的实体初始表示在同一个句子中时,则连接两个不同实体初始表示的提及节点,生成提及-提及边缘;当提及节点在句子中时,则连接提及节点和当前句子中的句子节点,生成提及句子边缘;连接所有句子节点,生成句子-句子边缘。
[0089]
所述步骤s22中,l层堆叠的关系图卷积神经网络对节点前向传递更新的表达式具
体为:
[0090][0091]
式中,为l层堆叠的关系图卷积神经网络输出的文档级图中节点,和均为l-1层堆叠的关系图卷积神经网络输出的文档级图中节点,σ(
·
)为激活函数,为与边x连接的节点i的邻居集合,为边类型的集合,为可训练的参数矩阵,dn为节点表示的维度。
[0092]
在本实施例中,l层堆叠的关系图卷积神经网络(r-gcn)对文档级图进行卷积操作,考虑了各种类型的边,可以更好地建模具有多关系的异构图。
[0093]
所述步骤s23中,计算实体全局表示的表达式具体为:
[0094][0095]
式中,和均为可训练的参数矩阵,为logsumexp池化层输出的实体表示相关函数,为实体初始表示相关函数,v为标准化特征向量。
[0096]
在本实施例中,通过logsumexp池化方式利用图卷积后提及节点的表示计算实体的表示。将文档级图获得的实体表示为它涉及整个文档中的语义信息。但整个文档的信息不可避免地掺杂了噪声,因此本发明采用注意力机制融合实体初始表示和实体的语义信息以减少噪声。
[0097]
所述步骤s3包括以下分步骤:
[0098]
s31、根据文档级图中实体全局表示生成实体级图,通过l层堆叠的关系图卷积神经网络对实体级图进行卷积,生成实体推理表示,根据实体推理表示和实体全局表示得到实体最终表示;
[0099]
s32、根据实体最终表示和相对距离表示,得到实体对的特定实体表示,连接实体对的特定实体表示得到目标关系表示,根据目标关系表示获得上下文关系表示。
[0100]
在本实施例中,为了发现长距离跨句实体对的一些关系,本发明构建实体级图(elg),实体级图包括实体节点,其表示文档d中的实体。
[0101]
实体节点的表示由文档级图获得的实体,实体级图中包括两种边:句子内边缘和逻辑推理边缘。
[0102]
当两个实体节点的提及在同一个句子中时,则两个不同的实体通过句子内边缘连接。例如,如果对于一个实体对《ei,ej》存在表示为的路径pi
i,j
,则elg使用句子内边连接实体节点ei和ej,因为它们出现在输入文档的同一个句子s1中。和分别是与两个实体相关的提及。
”‑
》”表示从实体节点ei到实体节点ej的推理路径上的一个推理步骤。
[0103]
当两句子中存在连接实体对的桥实体时,则用逻辑推理边缘连接两实体节点。例如,在句子s1和s2中分布的一对实体对《ei,ej》之间的关系是由桥实体ek间接建立的。因为桥实体ek的提及和s2中的实体与ei和ej相关。例如,存在一个逻辑推理路径pi
i,
表示为用逻辑推理边连接实体节点ei和ej。
[0104]
所述步骤s31中,得到实体最终表示的表达式具体为:
[0105][0106]
式中,和均为可训练的参数矩阵,为实体推理表示,为实体初始表示;
[0107]
通过l层堆叠的r-gcn对实体级图进行卷积,以获得实体推理表示,为了更好地整合实体的信息,本发明采用注意力机制将实体全局表示、实体推理表示和实体初始表示融合在一起,形成实体的最终表示。
[0108]
所述步骤s32中,实体对的特定实体表示包括第一特定实体表示和第二特定实体表示其表达式具体为:
[0109][0110][0111]
式中,δ
ij
为文档d中实体节点ei的第一次提及到实体节点ej的第一次提及相对距离;δ
ji
为文档d中实体节点ej的第一次提及到实体节点eo的第一次提及相对距离;
[0112]
相对距离首先被分成几个集合{1,2,...,2j}。然后,每个集合都与一个可训练的距离嵌入相关联。δ将每个δ关联到一个集合。
[0113]
得到上下文关系表示oc的表达式具体为:
[0114][0115]
式中,w为一个可训练的参数矩阵,目标关系表示oi为第i个实体对的关系表示,o
′r为or的转置,θo为oi的注意力权重,p为实体对的数量。
[0116]
本发明使用自注意力来捕获上下文关系表示,这可以帮助我们利用文档的主题信息。
[0117]
所述步骤s4包括以下分步骤:
[0118]
s41、将目标关系表示or和上下文关系表示oc输入前馈神经网络进行预测,得到属于类别r的预测概率;
[0119]
s42、基于属于类别r的预测概率,定义损失函数并通过分类器得到关系预测结果,
完成文本关系抽取。
[0120]
所述步骤s41中,得到属于类别r的预测概率yr的表达式具体为:
[0121]
yr=sigmoid(ffnn([or;oc]))
[0122]
式中,ffnn(
·
)为前馈神经网络的预测结果,sigmoid(
·
)为机器学习函数;
[0123]
所述步骤s42中,损失函数的表达式具体为:
[0124][0125]
式中,为r的真实标签,为目标关系表示和上下文关系表示的集合。
[0126]
在本实施例中,通过adam优化器来优化损失函数。在docred数据集进行实验过程中,分别设置具有两种模型,不具有两种模型,以及各自不具有其中一种模型来进行对比,并设置gara-bert作为基准模型。
[0127]
选取两个指标来对图滤波的作用来进行检验。
[0128]
在之前的工作之后,将f1和ign f1作为docred的评估指标。f1成绩可以通过在线界面计算得出,因为docred测试集的金标准未知。此外,ign f1表示f1分数忽略了训练集和开发/测试集共享的相关事实,得到的结果如图2所示,在docred的开发集上对gara的消融研究,其中“w/o”表示没有。
[0129]
由图2可知,到当删除根据实体推理表示获取实体的最终表示时,我们的f1和ign f1在文档开发集上的模型分数分别下降0.43%和41%。同样地删除根据实体全局表示生成实体的最终表示时,导致0.16%和0.24%的错误f1和ign f1下降,ign f1下降0.14%。
[0130]
删除根据实体推理表示和实体全局表示获取实体的最终表示时,会出现更大的下降。f1的得分从59.73%下降到59.16%,ign f1得分从57.85%降至57.33%。这项研究表明,所有根据实体全局表示、实体推理表示和实体初始表示生成实体的最终表示可以更有效地处理关系提取任务。
[0131]
本发明的有益效果为:本发明提出了一个基于复杂语义信息的文档级图,这是一个异构的过程包含提及节点和句子节点的图形,用于集成文档的丰富语义信息获取实体表示。
[0132]
本发明提出了一种实体级图获取方法,以发现长距离跨句子实体对的一些关系。然后,我们使用注意机制融合实体全局表示、实体推理表示和实体初始表示信息,以提取实体对之间的关系。
[0133]
在本发明的描述中,需要理解的是,术语“中心”、“厚度”、“上”、“下”、“水平”、“顶”、“底”、“内”、“外”、“径向”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的设备或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性或隐含指明的技术特征的数量。因此,限定由“第一”、“第二”、“第三”的特征可以明示或隐含地包括一个或者更多个该特征。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1