一种基于Cell-FreemMIMO网络的联邦学习设备端能耗优化方法
本发明涉及无线通信,尤其涉及一种基于cell-free mmimo网络的联邦学习设备端能耗优化方法。
背景技术:
1、随着终端设备智能化的发展,越来越多的隐私数据被要求发送到云端服务器作为机器学习的源数据集。用户文本数据、图像数据、视频数据等隐私数据上传到云服务器的过程中存在泄露风险,会给用户带来不必要的困扰和损失。为了保护用户的数据隐私,联邦学习支持用户在本地训练模型,用户仅需上传本地模型的参数即可参与全局训练。
2、然而,为了使全局模型收敛,参与联邦学习的海量用户设备需要在训练过程中通过无线通信链路频繁更新模型参数。用户设备通常采用锂电池供电,设备端进行本地训练模型以及上传模型参数所消耗的能量不容忽视。在本地模型训练阶段,用户设备的cpu工作频率和本地模型的训练精度是影响用户设备端功耗的关键优化变量。在本地模型参数上传阶段,海量用户设备进行联邦学习的数据上传导致了无线信道的复杂性,总有一部分用户受到严重的通信干扰并使得其通信质量降低。另一方面,参与训练的所有用户上传本地模型之后才可以完成一轮全局训练,因此一轮全局训练的时延由通信质量最低的用户设备决定,这就是落后者效应。通信质量较差的设备需要更长的上传时间,这增加了该设备的上行通信功耗,并导致其他设备在等待过程中消耗更多能量维持待机状态,因此抑制落后者效应是优化设备端上行功耗的关键。
3、为了减少设备端功耗,现有的方法可以分为两类。一类方法为优化云端模型的聚合方式,降低联邦学习设备端功耗。具体方法为,以用户本地模型对全局模型的贡献作为进行用户设备调度的依据,提高模型收敛速度。另一类方法旨在降低每轮联邦学习全局聚合过程的通信消耗,降低联邦学习设备端功耗。具体方法为通过资源分配方案和模型参数的压缩方法,降低模型训练时间和每轮通信的数据量。然而,方法一调度的用户可能是掉线的用户设备,因此仅采取用户调度方案并不总是有效的设备端功耗;方法二在大规模网络中的效率不高,特别是当用户设备数量较大时,会导致联邦学习的设备端功耗显著增加。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺点,而提出的一种基于cell-freemmimo网络的联邦学习设备端能耗优化方法,可以显著降低联邦学习过程中设备端的能耗,不依赖于特定的联邦聚合方法和联邦学习类型,在大部分联邦学习场景中均可以提供良好的能耗优化性能。
2、为了实现上述目的,本发明采用了如下技术方案:
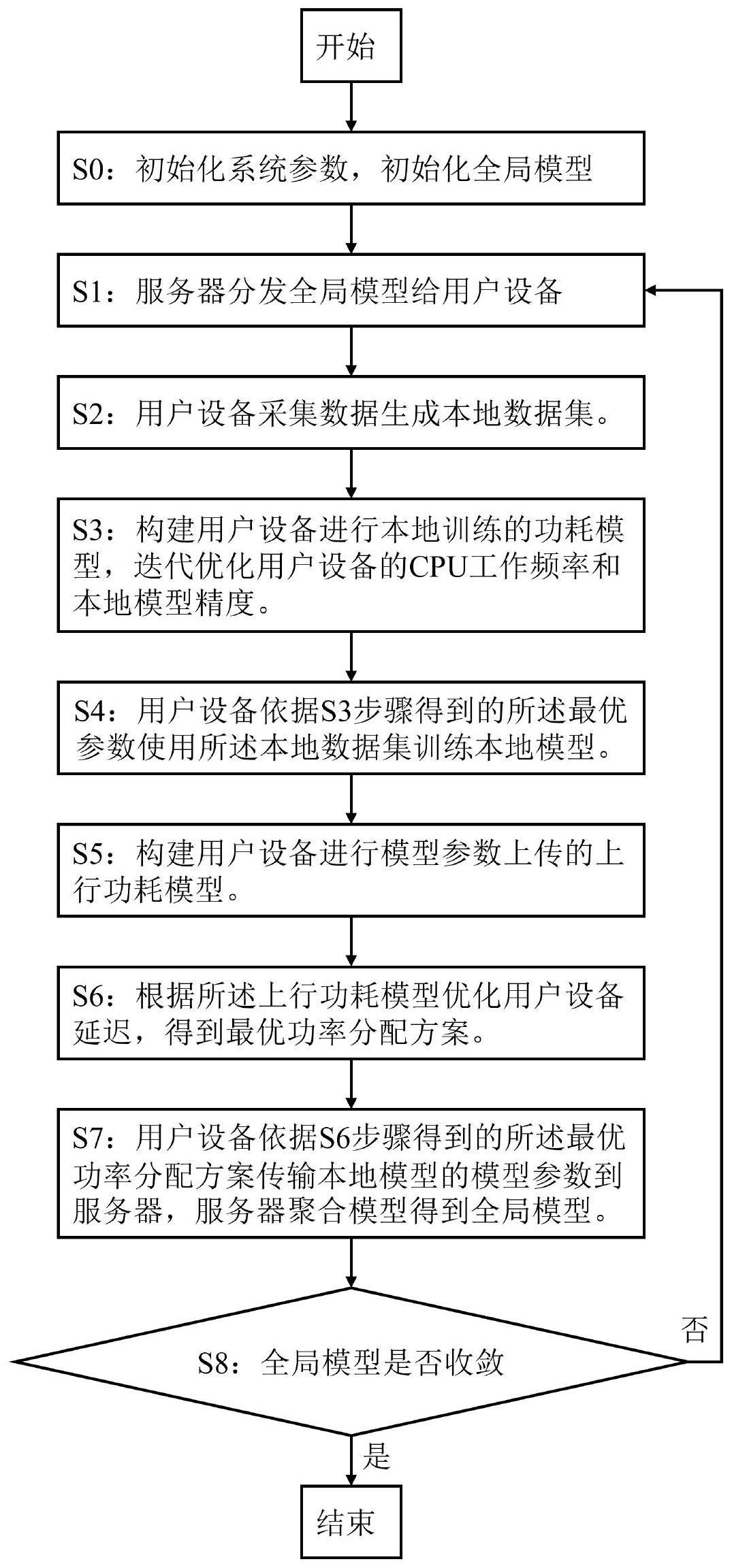
3、一种基于cell-free mmimo网络的联邦学习设备端能耗优化方法,具体步骤如下:
4、s0:初始化系统参数,初始化全局模型;
5、s1:服务器分发全局模型给用户设备;
6、s2:用户设备采集数据生成本地数据集;
7、s3:构建用户设备进行本地训练的功耗模型,迭代优化用户设备的cpu工作频率和本地模型精度;
8、s4:用户设备依据s3步骤得到的最优参数使用本地数据集训练本地模型;
9、s5:构建用户设备进行模型参数上传的上行功耗模型;
10、s6:根据上行功耗模型优化用户设备延迟,得到最优功率分配方案;
11、s7:用户设备依据s6步骤得到的最优功率分配方案传输本地模型的模型参数到服务器,服务器聚合模型得到全局模型;
12、s8:重复上述s1-s7直至全局模型收敛为止。
13、优选地,所述步骤s0中:
14、初始化的系统参数包括k个用户设备的cpu所支持的工作频率范围,即用户设备k的cpu所支持的最小工作频率和最大工作频率
15、初始化的系统参数包括k个用户设备的本地模型支持的训练精度范围,即用户设备k的所支持的最小训练精度和最大训练精度
16、初始化的全局模型为w(0),在第i轮全局训练中,服务器下发的全局模型为w(i)。
17、优选地,所述步骤s1中:服务器向所有用户设备分发全局模型,或是向部分用户设备分发全局模型。
18、优选地,所述步骤s2中:用户设备k采集数据得到本地数据集{xk∈su,yk},其中su为本地数据集的大小,xk和yk分别表示本地数据集的输入参数与输出参数。
19、优选地,所述步骤s3中:
20、在联邦学习的第i轮全局训练过程中,用户设备k使用本地数据集训练全局模型w(i)得到本地模型
21、对于一个给定的本地模型精度θ,模型在本地训练得到最优模型需要的迭代次数为其中取决于数据集的大小和本地模型的规模;
22、用户设备k在本地训练的时间延迟可以表示为:
23、
24、其中ck表示用户设备k的cpu处理一个数据样本所需的周期数,ck是通过离线测量预先知晓的常数,dk和fk分别为本地数据集的大小和用户设备k的cpu工作频率;
25、用户设备k在本地训练模型所消耗的能量可以表示为:
26、
27、其中α表示用户设备k的cpu的电容系数,α是通过离线测量预先知晓的常数;
28、根据用户设备本地训练的功耗模型建立以下本地模型训练阶段的功耗优化问题:
29、
30、其中,
31、
32、表示用户k的本地训练功耗,表示用户设备进行模型上传的次数,即全局训练次数,其中和为全局模型参数,为已知常数;
33、解决用户设备k本地模型训练阶段的功耗优化问题的迭代优化算法如下:
34、算法1:本地模型训练阶段的功耗优化问题的迭代优化算法
35、输入:最小工作频率最大工作频率最小训练精度最大训练精度本地训练延迟算法精度算法迭代次数索引ω,算法最大迭代次数ωmax;
36、初始化:算法精度ω=1
37、
38、
39、输出:
40、优选地,所述步骤s4中:在联邦学习的第i轮全局训练过程中,用户设备k依据最优参数使用本地数据集{xk∈su,yk}训练本地模型在本地模型收敛后,用户设备k本地模型在全局第i次迭代的更新表示为需要的存储空间为su。
41、优选地,所述步骤s5中:
42、用户设备进行模型参数上传的上行功耗模型建模为:
43、eu,k(ηk,ru,k(η))=ρuηktu,k(ru,k(η)) (1.5)
44、用户的发射功率为ρuηk,其中ρu为上行最大发射功率,ηk为用户k的上行功率控制系数,为用户设备k发送本地模型所需的时间,其中:
45、
46、为用户设备k在去蜂窝大规模mimo网络中的上行通信速率,βmk表示无蜂窝网络中接入点m与用户设备k之间无线信道的大尺度衰落系数,σmk表示估计的信道的功率,φl表示第l个导频,表示零均值的复高斯随机噪声。
47、优选地,所述步骤s6中:
48、根据用户设备上传模型参数的功耗模型建立以下上传模型阶段的功耗优化问题:
49、
50、其中θ*通过本地模型训练阶段的功耗优化问题的迭代优化算法获得,g(θ*)为已知常数;c.1中tk=tc,k+tu,k为用户设备k的本地训练延迟和上行传输延迟,tg为联邦学习一次全局训练所允许的最大延迟;c.2中hu,k(η)为ru,k的凹的下界,便于使用凸优化工具在可行域上搜索ru,k的解;为了抑制落后者效应,本地模型训练阶段的功耗优化问题服从延迟约束t1=...=tk=...=tk;
51、用户设备上传模型阶段的功耗优化问题转化为以下可行性搜索问题:
52、
53、其中为一次算法迭代过程中最大设备延迟;
54、解决用户设备k上传模型阶段的功耗优化问题的优化算法如下:
55、算法2:上传模型阶段的功耗优化问题的优化算法
56、输入:本地训练延迟tc,k,用户上行最大功率ρu,用户设备的上行功率控制系数ηk,算法精度算法上界tupper,算法下界tlower;
57、初始化:算法精度算法上界算法下界tlower=0;
58、
59、
60、输出:
61、优选地,所述步骤s7中:服务器包括云服务器和边缘服务器。
62、与现有技术相比,本发明具有以下有益效果:
63、1、本发明在用户训练本地模型的阶段,通过迭代优化用户设备端cpu的工作频率和本地模型的训练精度降低用户设备的本地训练功耗;在用户设备上传模型参数阶段,以最小化用户设备的最大时延为目标进行功率分配,一方面减少通信质量佳的设备等待其它通信质量差的设备上传时所消耗的待机功耗,另一方面通过功率分配抑制干扰水平进而节约设备端上行功率。
64、2、本发明可以显著降低联邦学习过程中设备端的能耗,不依赖于特定的联邦聚合方法和联邦学习类型,在大部分联邦学习场景中均可以提供良好的能耗优化性能,并且本发明的实现复杂度低,易于部署。
- 还没有人留言评论。精彩留言会获得点赞!