一种适用于稀疏神经网络的软硬件协同的加速器设计方法
1.本发明属于神经网络加速器设计技术领域,具体涉及稀疏化神经网络加速器设计方法。
背景技术:
2.近年来,在算力、大数据等方面的推动下,卷积神经网络在人工智能领域取得巨大成功,例如图像识别,语音识别,图片分类等,其识别精准率大大超出传统算法,在某些特殊领域的准确率甚至超越了人类。卷积神经网络的深度以及网络参数数量不断增加,导致网络计算时间以及内存需求显著增加。为了推广基于神经网络的人工智能应用,高性能的神经网络计算加速器设计成为一个至关重要的技术方向。无论是基于fpga的方案还是基于asic的方案都成为目前的研究重点。
3.剪枝算法的目的是将大量的权重数据设成零,相应的神经网络连接就可以被剪枝,从而达到简化神经网络、减少计算量的目的。但如何得到高效的并行计算电路是一个需要解决的问题。比如,gpu计算稀疏矩阵乘法甚至比非稀疏矩阵乘法更慢。本发明提出的就是稀疏神经网络的硬件加速电路设计方案。
4.专有名词解释:
5.卷积神经网络:一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一;
6.稀疏神经网络:大量权重数据为零值的卷积神经网络,突触之间连接非常稀疏;
7.输入通道:卷积神经网络卷积层或全连接层的权重参数为一个四维向量,其中每一个滤波器的深度方向称为输入通道;
8.稀疏率:总权重数量对非零值权重数据数的比例。
技术实现要素:
9.本发明的目的是提供一种适用于稀疏神经网络的软硬件协同的硬速器设计方法,能够快速将神经网络快速部署到fpga加速器端,降低设计复杂度,简化硬件加速成本。
10.本发明提供的适用于稀疏神经网络的软硬件协同的加速器设计方法,包括一个输入通道分组均匀稀疏化剪枝算法及相应的硬件加速器设计方法。其中:
11.所述输入通道分组均匀稀疏化剪枝算法如下:设卷积神经网络的卷积层或全连接层的权重矩阵是一个4维矩阵(n,c,k
x
,ky),这4个维度分别称为输出通道、输入通道、x、y;稀疏化剪枝算法,就是将长度为c的每个输入通道分成长度为g的小组;对于给定稀疏率r,剪枝算法将每个小组里面较小的个权重数据设成零;为了保证稀疏后的识别精度,采用渐进稀疏与训练的算法,在网络训练迭代过程中初步将稀疏率从逐步提高到r;由于g的大小对于精度损失影响很大,当无法降低目标损失函数的误差时,我们会增加g的大小重新进行剪枝训练;我们的实验表明g为32,r为4对于目前的图像识别及视频检测网络均可以达
到较小的识别率损失;权重数据编码采用直接地址编码方式;
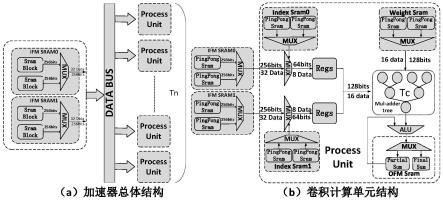
12.所述稀疏网络计算加速器设计方法,参见图1(a)所示,稀疏网络计算加速器包括:输入数据缓存模块(ifm cache),数据读取逻辑与总线,计算单元(processunit,pu)阵列;一个计算单元(pu)具有多个乘加计算逻辑(pe),这些乘加计算逻辑(pe)用于并行处理多个输入通道的数据进行乘加计算;在计算单元(pu)阵列中,每个计算单元(pu)以并行的方式处理一个或多个输出通道;输入数据缓存模块(ifm)每次读取r
×
pe个输入数据,并通过总线传给所有的计算单元(pu);
13.所述计算单元(pu),其结构如图1(b)所示;它包括:用于存放所述权重数据的权重缓存(weight cache)、索引缓存(index cache)、输出特征图数据缓存(ofm cache)、稀疏数据选择器逻辑(mux)以及点积计算乘加树(alu);输入特征图数据输入到计算单元(pu)以后,稀疏数据选择器根据索引缓存中的数据选出对应的数据送入到乘加树中,与权重数据一起进行点积计算,并进行后续的池化计算与激励计算,最终输出到输出缓存;池化计算与激励计算由点积计算乘加树(alu)模块完成。
14.为了提高计算效率,本发明的所有数据传输通道,包括稀疏数据选择通道、权重数据读取通道、权重索引读取通道、输出数据到ofm缓存通道均采用乒乓缓存结构以实现数据传输与计算的流水线化。乒乓缓存为双缓冲与双数据读写通道,一个通道往缓存里面写数据,另一个通道从缓存里面读数据。两个通道交替进行读/写操作。
15.本发明中,计算与数据调度的流程为:
16.(1)每个时钟节拍从输入数据缓存模块(ifm)读入r
×
pe个数据,通过稀疏数据选择器逻辑(mux)选出pu个对应非零权重的输入数据写入寄存器reg中;
17.(2)寄存器reg的输入数据与权重数据传给dsp进行点积计算;同时,从输入数据缓存模块(ifm)读入下一组r
×
pe个数据,实现数据读入、选择与点积计算的流水线计算。
18.本发明中,r、pe、pu均为可变参数。一般建议r为4。提高r的代价是稀疏后的识别精度会下降。稀疏的分组大小g将根据网络通过剪枝算法自动求解。对于目前的常用网络,本发明的方案是32。pe、pu根据dsp(乘法器)的资源数量设置,建议pe
×
pu不超过dsp资源数量的80%。这个dsp资源数量由计划使用的fpga芯片或asic芯片的面积大小来确定。这里的可变参数pu、pe、分别表示计算单元(pu)和乘加计算逻辑(pe)的数量。
19.对多种卷积神经网络基于imagenet训练与测试集,使用本发明的稀疏剪枝算法进行精度测试。分组大小为32,稀疏率为4,量化数据位宽为8位。经过训练后的网络识别精度列在表格1中。
20.表1,稀疏与量化精度
21.网络非稀疏网络精度稀疏后精度精度损失稀疏及量化后精度精度损失ssd0.770.7582%0.7532%yolo-v20.780.780%0.745%alexnet0.5650.5375%0.5188%vgg160.680.680%0.680%googlenet0.680.654%0.654%
。
22.本发明中,分组均匀稀疏方案保证了各个并行计算通道的数据处理速度均衡,从
而不需要常规稀疏网络加速器所需要的fifo逻辑以及保证各计算通道数率均衡的控制逻辑,极大的简化了设计、减少了lut与ff资源的需求。由于每个fpga芯片的各种逻辑资源、bram、dsp数量是有限的,减少逻辑资源的需求可以提高dsp资源的利用率及计算效率。对于稀疏率为4稀疏神经网络,对比了本发明的加速器设计pu的资源需求与传统的非均匀稀疏方案加速器设计的资源需求。测试结果见表格2。数据显示本发明的设计方案可以降低slice的需求3.5倍,bram数量1.4倍。
23.表2,分组均匀稀疏与非均匀稀疏硬件资源对比
[0024] dspslicebram非均匀稀疏卷积计算单元16220813.5均匀稀疏卷积计算单元166279.5。
[0025]
对于一个权重大小为(n,c,k
x
,ky)卷积层i,pe/pu阵列计算的效率为:
[0026][0027]
输入图片大小为(c,x,y),卷积步长为s
x
与sy,则计算量为:
[0028][0029]
加权计算效率为:wi×ei
。
[0030]
对于一个n层的网络,总体计算效率为:e=∑wi×ei
。从而,可以计算出最优的pe/pu组合达到最大的总体计算效率e。
[0031]
本发明与其它几个神经网络加速器实现yolo-v2网络的资源与性能对比,见表格3。fclnn
[1]
使用winograd算法减少卷积的乘法运算,zhao et al.
[2]
使用两个独立的运算单元用于计算全连接层和卷积层,与相同电路计算全连接层和卷积层相比,可以实现更高的计算效率。结果表明,fclnn通过增加50%的dsp和更先进一代的半导体工艺获得了50%的更高帧率,但是他们的dsp效率比本发明的低3倍。zhao et al.使用相同的28nm fpga,但只有1.4fps。sparse-yolo
[3]
也采用了更先进的半导体工艺及更多的逻辑资源实现了更高的计算速度。本发明的设计方案能够更充分的使用fpga芯片上的dsp资源,取得较好的性价比。
[0032]
表3,加速器设计方案对比
[0033] 本发明fclnn1zhao et al.2sparse-yolo3工艺28nm20nm28nm20nmfpga平台v7 690tgx1150zc706gx1150电路频率100mhz278mhz200mhz204mhzdsp使用数量10241488未知92slice使用数量55843143750未知129375bram使用数量2.8125mb7.227mb未知7.884mb计算速度fps13.918.61.461.9单位dsp效率3.991.32未知未知
。
[0034]
注:单位dsp效率=吞吐率/dsp消耗/时钟频率,吞吐率=fps*网络计算量,由于xilinx和altera fpga中的bram组织方式不同,将其统一为具体容量进行比较。
[0035]
本发明提出的计算架构同样适用于asic设计方案,分组均匀稀疏方案及加速器设计可以极大的简化稀疏数据处理。本发明设计中稀疏数据选择逻辑占总逻辑资源约为1.2%.相比于之下,cambricon-x
[4]
设计中用于稀疏数据选择的mux电路和控制逻辑(fifo缓存)占整个芯片三分之一的面积。由于cambricon-x是在asic上实现的,我们无法进行更详细的对比。
附图说明
[0036]
图1为本发明加速器结构示意图。
具体实施方式
[0037]
本发明设计了一个在fpga上实现的稀疏神经网络加速器。以xilinxxc7vx690t为例,稀疏度r=4,系统由64个pu组成,每个pu有16个pe(dsp),分组大小为32。通过前面说明的网络稀疏化训练算法将每一个卷积层的权重按照稀疏度4进行稀疏化。具体地,对于4维权重数组[n,c,k
x
,ky],其中n为输出通道数,c为输入通道数,k
x
、ky是卷积核在x方向和y方向的长度。本发明的网络稀疏软件可以将权重数组按c方向每32个数只保留32/4=8个非零值。加速器的时钟频率、资源使用情况及计算性能如表格3所示。
[0038]
以上具体实施方式及实施例是对本发明提出的一种稀疏神经网络加速器技术思想的具体支持,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在本技术方案基础上所做的任何等同变化或等效的改动,均仍属于本发明技术方案保护的范围。
[0039]
参考文献
[0040]
1、xu x,liu b.fclnn:a flexible framework for fast cnn prototyping on fpga with opencl and caffe.in:ieee.2018international conference on field-programmable technology(fpt);2018:238-241
[0041]
2、zhao r,niu x,wu y,luk w,liu q.optimizing cnn-based object detection algorithms on embedded fpga platforms.in:springer.international symposium on applied reconfigurable computing:255-267.
[0042]
3、wang z,xu k,wu s,liu l,liu l,wang d.sparse-yolo:hardware/software co-design of an fpga accelerator for yolov2.ieee access 2020;8:116569
–
116585.
[0043]
4、zhang s,du z,zhang l,et al.cambricon-x:an accelerator for sparse neural networks.in:ieee.2016 49th annualieee/acm international symposium on microarchitecture(micro);2016:1
–
12.
[0044]
5、庞伟等,一种针对硬件实现稀疏化卷积神经网络推断的加速方法,专利申请号cn201811486547。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1