一种甲骨文识别方法及系统
1.本发明涉及甲骨文信息处理技术领域,具体为一种甲骨文识别方法及系统。
背景技术:
2.甲骨文是中国迄今发现的最早的文字系统。甲骨文研究对于揭示中国古代社会制度、居民生活和重大历史事件具有重要意义。传统的甲骨文研究包括甲骨片缀合、字义考释、甲骨字组类划分等,但由于甲骨文距今年代久远,甲骨文的书写形式和基本语法规则与现代文字有很大的不同,加之缺乏足够的传世文献,传统研究在考释、缀合等研究方向面临巨大瓶颈。而计算机技术的发展使得甲骨文相关史料、文献得到数字化保存,同时也给利用计算机处理和研究甲骨文提供了条件。
3.在专业领域研究方面,甲骨学研究需要大量的古文字知识储备与积累,高效的查找和检索相关信息是保障相关研究的基础。在甲骨文文化推广方面,对于普通群众,认识甲骨字以及了解其相关意思、背景是核心需求。
4.甲骨文载体有多种形式,较为常见的有拓片、照片以及临摹体,其中临摹体为书写者比照镌刻的甲骨字,书写在纸上或者电子画板上的一种形式。目前大型甲骨文大数据平台均提供甲骨文字库功能,其文字形式大多以手写体形式存在,例如殷契文淵(http://jgw.aynu.edu.cn/)。手写甲骨文识别研究为甲骨文检索、相关资料查找以及知识关联等提供了便利的技术手段。通过任意形式的手写输入,即使一般用户的非专业字形临摹,可以快速定位到相应的甲骨文,并且通过相关文献、图片等资料信息映射等可以满足各种甲骨文研究以及文化推广的需求。
5.目前,现有技术中,之间针对手写甲骨文识别的研究成果较少,甲骨文识别研究主要针对甲骨字拓片进行开展。主要方法可分为两类:(1)基于传统机器学习的识别方法;(2)基于深度学习的识别方法。
6.若考虑面向甲骨文拓片文字识别的研究成果,相关技术缺点总结如下:
7.(1)其中基于传统机器学习的方法把甲骨文看作图像处理,通过分析其图形图像特点将其转化成相应的结构编码等形式,再利用相似度计算以及svm等分类算法实现甲骨文的识别。
8.但基于甲骨文拓扑、字形结构以及传统机器学习的方法,在处理复杂文字时仍然存在一些问题,特别是合体字,同时具有较多笔画时效果较差,并且识别效果受拓片中文字清晰度以及断裂、磨损等噪声影响较大。
9.(2)基于深度学习的识别方法通过对拓片上的甲骨字进行检测,然后利用cnn、yolo、inception v3等深度学习模型实现甲骨文的识别。
10.虽然基于深度学习的甲骨文识别研究,在处理能力以及识别效果上与传统机器学习方法相比有一定优势,仍然存在一定问题,主要包括:首先,研究者基于cnn、yolo、inception-v3等深度学习模型进行甲骨文识别,其准确率仍然相对较低,识别方法大多处于实验室级别,无法进一步大规模实际应用。其次,现有相关研究提出的算法在执行效率上
仍有所欠缺,响应时间等仍有进步空间。最后,针对拓片的识别处理使用的都是裁剪后的拓片文字,其形式不具有手写体的录入方式的多样性,现有方法难以直接应用于手写甲骨文识别。
技术实现要素:
11.本发明提出了一种甲骨文识别方法及系统,能够更为快速准确的识别出用户手写的甲骨字,提供技术工具支撑,可使用户方便的进行甲骨文以及相关文献资料的检索与查找。
12.本发明提供了一种甲骨文识别方法,包括以下步骤:
13.获取不同甲骨文字的原始书写图片,并对每个甲骨文字的原始书写图片的背景分别进行不同大小的扩充,得到扩充后的图片;
14.对不同甲骨文字的原始书写图片及扩充后的图片分别进行标注,标注后的原始书写图片及扩充后的图片构成训练集;
15.基于easydl平台中,及paddlepaddle深度学习框架,结合auto model search在easydl平台的图像分类模型选择与甲骨文字的训练集的训练样本数据处理匹配的算法,创建手写甲骨文识别模型;
16.利用训练集对所创建的手写甲骨文识别模型进行训练;
17.利用训练完毕的手写甲骨文识别模型对用户输入的待识别甲骨文字进行识别,得到识别结果。
18.进一步地,利用甲骨文字数据平台获取所述不同甲骨文字的原始书写图片。
19.进一步地,所述对不同甲骨文字的原始书写图片及扩充后的图片分别进行标注,包括:
20.将所述不同甲骨文字的原始书写图片及扩充后的图片分别进行归类;
21.利用nodejs对归类后的所述不同甲骨文字的原始书写图片及扩充后的图片统一进行批量标注。
22.进一步地,在对所述手写甲骨文识别模型进行训练之前,还包括:
23.对所述训练集中的数据进行划分,得到多个分训练集。
24.进一步地,所述对手写甲骨文识别模型进行训练,包括:
25.利用所述多个分训练集分别训练手写甲骨文识别模型,得到多个训练完毕的分手写甲骨文识别模型;
26.将所述多个分手写甲骨文识别模型进行集成,得到最终训练完毕的手写甲骨文识别模型。
27.进一步地,还包括:
28.在公有云部署已训练完毕的所述手写甲骨文识别模型
29.进一步地,所述用户输入甲骨文字的方式包括:
30.利用鼠标手绘输入甲骨文字;
31.利用写字板书写输入甲骨文字;
32.将书写有甲骨文字的图片上传,实现甲骨文字输入;
33.利用拍照的方式上传。
34.本发明还提供一种甲骨文识别系统,包括:
35.数据扩充模块,用于获取不同甲骨文字的原始书写图片,并对每个所述甲骨文字的原始书写图片的背景分别进行不同大小的扩充,得到扩充后的图片;
36.数据标注模块,用于对不同所述甲骨文字的原始书写图片及扩充后的图片分别进行标注,标注后的所述原始书写图片及所述扩充后的图片构成训练集;
37.模型构建模块,用于基于easydl平台中,及paddlepaddle深度学习框架,结合auto model search在easydl平台的图像分类模型选择与甲骨文字的训练集的训练样本数据处理匹配的算法,创建手写甲骨文识别模型,并利用训练集对所创建的手写甲骨文识别模型进行训练;
38.识别模块,用于利用训练完毕的手写甲骨文识别模型对用户输入的待识别甲骨文字进行识别,得到识别结果。
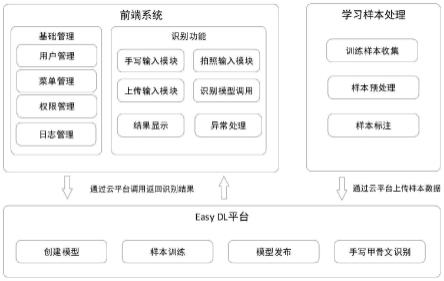
39.进一步地,还包括:前端系统,用于用户输入甲骨文字。
40.与现有技术相比,本发明的有益效果:
41.本发明中所提出的甲骨文识别方法,具体基于easydl平台创建高精度的手写甲骨文识别模型,并利用获取到的甲骨文字的图片作为训练集对所构建的手写甲骨文识别模型进行训练,并对训练好的手写甲骨文识别模型利用公有云的方式部署,方便用户实现甲骨文识别,提高了手写甲骨文识别效率,以及识别的准确性显著提升。
42.此外,本发明中甲骨文识别系统在保证正确率以及处理效率的同时还可以支持图片上传、在线输入、拍照上传等多种输入形式,方便快捷的为甲骨文检索等提供技术支撑。可以通过多种手写体录入方式进行识别,满足专业研究人员到甲骨文爱好者等不同的使用需求,并可以应用在各类甲骨文数据库检索系统中,提高甲骨文检索的准确率及效率。
附图说明
43.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
44.图1是本发明提出的一种甲骨文识别方法的流程示意框图;
45.图2是本发明提出的一种甲骨文识别方法的中的模型创建过程流程图;
46.图3是本发明提出的一种甲骨文识别方法及系统的实施例中的数据扩充过程示意图;
47.图4是本发明提出的一种甲骨文识别方法及系统的实施例中的easydl平台架构;
48.图5是本发明提出的一种甲骨文识别方法及系统的实施例中的采用高精度方式进行模型训练的具体过程;
49.图6是本发明提出的一种甲骨文识别方法及系统的实施例中的用户输入的甲骨文字迹正常的示意图(一);
50.图7是本发明提出的一种甲骨文识别方法及系统的实施例中的用户输入的甲骨文字迹正常的示意图(二);
51.图8是本发明提出的一种甲骨文识别方法及系统的实施例中的用户输入的甲骨文字迹潦草的示意图(一);
52.图9是本发明提出的一种甲骨文识别方法及系统的实施例中的用户输入的甲骨文
字迹潦草的示意图(二)。
具体实施方式
53.下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
54.殷契文淵是目前全球范围最大的甲骨文大数据平台,包括字库、著錄库、文献库等多个数据库,该平台面向全球用户开放,专家学者、甲骨文爱好者、普通用户都可以通过注册访问该平台系统。
55.殷契文淵数据库中各类甲骨文相关资料都有一定的联系,比如某一文字出现在哪些甲骨片,其考释的字义是什么,又有哪些文献中研究了相关文字,目前该平台的检索尚未实现直接通过图片的形式完成检索功能,一些文字与著錄、文献的联系都是通过预先知晓的关联关系通过连接设定进行的。
56.在使用字库、著錄库等数据库时需要具有一定的甲骨学知识,在进行文字查找以及相对应文献查找时效率较低。
57.本发明的应用实施可以高效、快速的检索手写甲骨字以及检索包含该字体的文献资料,可以节省研究过程由于翻找文献所需时间,并且可以减低使用、查找甲骨文的门槛,既能为专业人士提高研究效率所使用,也可为爱好者或者普通用户进行检索时使用。此外,后续通过结合拓片、照片等更多形式的甲骨文,可以做到多源文字通用检索,更进一步推动甲骨文研究的发展。
58.如图1-2所示,本发明提供一种甲骨文识别方法,包括以下步骤:
59.步骤s1:获取不同甲骨文字的原始书写图片,并对每个甲骨文字的原始书写图片的背景分别进行不同大小的扩充,得到扩充后的图片;
60.步骤s2:对不同甲骨文字的原始书写图片及扩充后的图片分别进行标注,标注后的原始书写图片及扩充后的图片构成训练集;
61.步骤s3:基于easydl平台中,及paddlepaddle深度学习框架,结合auto model search在easydl平台的图像分类模型选择与甲骨文字的训练集的训练样本数据处理匹配的算法,创建手写甲骨文识别模型;利用训练集对所创建的手写甲骨文识别模型进行训练;
62.步骤s4:利用训练完毕的手写甲骨文识别模型对用户输入的待识别甲骨文字进行识别,得到识别结果。
63.其中步骤s1中,利用甲骨文字数据平台获取不同甲骨文字的原始书写图片。
64.其中步骤s2中,对不同甲骨文字的原始书写图片及扩充后的图片分别进行标注,包括:
65.步骤s2.1:将不同甲骨文字的原始书写图片及扩充后的图片分别进行归类;
66.步骤s2.2:利用nodejs对归类后的不同甲骨文字的原始书写图片及扩充后的图片统一进行批量标注。
67.在对手写甲骨文识别模型进行训练之前,还包括:
68.对训练集中的数据进行划分,得到多个分训练集。
69.在步骤s3中,对手写甲骨文识别模型进行训练,包括:
70.利用多个分训练集分别训练手写甲骨文识别模型,得到多个训练完毕的分手写甲
骨文识别模型;
71.将多个分手写甲骨文识别模型进行集成,得到最终训练完毕的手写甲骨文识别模型。
72.当手写甲骨文识别模型训练完毕后在公有云部署已训练完毕的手写甲骨文识别模型。
73.在步骤s4中,用户输入甲骨文字的方式包括:
74.利用鼠标手绘输入甲骨文字;
75.利用写字板书写输入甲骨文字;
76.将书写有甲骨文字的图片上传,实现甲骨文字输入;
77.利用拍照的方式上传。
78.本发明还提供一种甲骨文识别系统,包括:
79.数据扩充模块,用于获取不同甲骨文字的原始书写图片,并对每个甲骨文字的原始书写图片的背景分别进行不同大小的扩充,得到扩充后的图片;
80.数据标注模块,用于对不同甲骨文字的原始书写图片及扩充后的图片分别进行标注,标注后的原始书写图片及扩充后的图片构成训练集;
81.模型构建模块,用于基于easydl平台中,及paddlepaddle深度学习框架,结合auto model search在easydl平台的图像分类模型选择与甲骨文字的训练集的训练样本数据处理匹配的算法,创建手写甲骨文识别模型,并利用训练集对所创建的手写甲骨文识别模型进行训练;
82.识别模块,用于利用训练完毕的手写甲骨文识别模型对用户输入的待识别甲骨文字进行识别,得到识别结果。
83.本发明所提供的一种甲骨文识别系统,还包括:
84.前端系统,用于用户输入甲骨文字。
85.下面结合具体的实施例对本发明中的技术方案作进一步详细说明。
86.1、获取训练样本数据,并进行扩充
87.训练数据来源为殷契文淵甲骨文大数据平台,该平台为权威的甲骨文数据中心。利用殷契文淵甲骨文大数据平台每个甲骨文字可获得19至24个训练样本,为了使easydl模型取得良好训练效果则需要的样本数量在50个以上。
88.为了将样本数量控制在easydl要求的50个以上的数量,因此需要进行数据扩充。考虑到手写甲骨文录入的方式,一般都是在白色画板或者白色纸张上进行书写,因此,本发明采用的扩充样本背景大小的方式实现样本数量的增广,如图1所示。采用node-image库对样本进行扩充,每个训练样本原本的背景大小为400px*400px,在此基础上,对每个训练图片的背景进行了扩充,本发明中的样本扩充方法仅扩充图片背景,字体大小不变,非图片整体放大。
89.如图3所示,殷契文淵提供的每个训练样本原本的背景大小为400px*400px,对每个训练样本进行背景扩充(字体大小不变),获得背景大小为420px*420px和450px*450px新的样本数据,每一个甲骨字的样本从19至24个扩充至57至72个。
90.2、对训练集中的各个训练样本分别进行标注。
91.由于殷契文淵提供的数据集中,每一个甲骨字都是单独的图片,因此可以省去检
测步骤,直接为同一文字样本进行标注。
92.本实施例中的数据集中总共有三千多个甲骨字,每一个甲骨字样本数量在57至72个之间,因此完全使用人工标注费时费力。
93.本发明采用半自动化的方法实现样本标注,主要过程如下:
94.首先,对原始样本以及扩充样本进行文件归类;
95.其次,利用nodejs对数据集批量生成标注;
96.最后,按照easydl要求对处理后的数据集进行上传。
97.3、数据集划分方法
98.easydl平台处理数据时,单个模型支持的标签类型上限为1000(经实测标签达到995测试效果不稳定),本实施例中的训练集中包括的文字有3000多个,因此,需采用四分法对训练集进行划分,每一份用来训练一个模型。实际调用时,后端对四个训练后的模型做集成,用来支持三千多个甲骨文。
99.具体划分方法为:每950个甲骨字划分为一组,划分规则采用随机方式,若不够950个字则按照实际甲骨字数量分组。
100.4、基于easydl平台创建手写甲骨文识别模型
101.easydl平台提供了功能强大且使用便捷的六类模型:
102.图像分类、物体检测、图像分割、文本分类、语音分类和视频分类。
103.本发明使用图像分类模型实现手写甲骨文识别,并根据相关要求进行模型创建,如图4中模型创建部分所示。
104.easydl图像分类功能预置了resnet(50,101)、se_resnext(50,101)、mobilenet nasnet、inception series等算法,构建训练模型是可根据需求选择其提供的高精度、高性能、autodl transfer等不同形式选择,为了取得更为准确的识别效果,本发明选择高精度方式,通过paddlepaddle深度学习框架结合auto model search选择与数据处理最为匹配的算法构建手写甲骨文训练模型,过程如图5所示。
105.5、用户进行甲骨文输入后进行识别
106.为了用户能直接使用进行手写甲骨文录入以及识别操作,本实施例中的前端系统,主要包括:i基础管理;ii识别功能管理,具体如下:
107.基础管理包括用户管理、菜单管理、角色管理等,其中最为重要的是用户管理,通过邮箱注册、手机注册等方式在保证用户身份合理验证的同时,尊重用户隐私同时加强访问安全。
108.识别功能管理主要包括几类识别模块的设计,目前手写输入主要通过鼠标手绘以及通过写字板进行书写,因为前段系统中有手写识别模块可以实现该功能;另外一些研究者有一些甲骨文手写字库图片,通过图片上传可以进行手写甲骨文识别;再有,拍照上传是在检索甲骨文时一种很常见的形式,因此设置了拍照上传功能。
109.本发明中的甲骨文识别系统硬件平台主要包括:pc机、手写输入数字板、摄像头、云服务器等。其中pc机是本地部署核心,系统登录、数据输入、云服务器访问以及结果显示等都通过pc实现。数据输入功能可以通过pc机鼠标书写完成,也可通过手写板、照相机等与pc机相连实现,这些录入硬件是可选的,云平台服务器则部署识别模块,通过云端调用实现。
110.在对用户输入的甲骨文进行识别时,系统针对正常书写字迹,包括在直接在画板输入、上传图片以及在白纸上书写上传的手写体识别准确率在95%以上。实验结果来自以字库中300个随机选择甲骨字为研究对象,通过三种方式进行输入识别,系统反馈结果的统计,正常输入示例如图6、图7所示。
111.若输入字迹十分潦草,由于甲骨字字形结构有简单线条独体字以及复杂线条合体字,总体来说,前者识别准确率仍能够保持在90%后者相对较低有40%准确率,潦草字迹如图8、图9所示。
112.最后说明的是:以上公开的仅为本发明的一个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1