基于量子花朵授粉算法优化AdaBi-LSTM模型的电力设备和主体持续信任评估方法与流程
本发明涉及去边界化安全防护领域,特别涉及一种基于量子花朵授粉算法优化自适应双向长短时记忆网络(adabi-lstm)模型的电力设备和主体持续信任评估方法。
背景技术:
1、目前,在电力系统中,现有的基于边界的保护系统和“一次认证、一次授权、长期有效”的方法难以应对来自内部和外部设备以及具有合法权限的用户的攻击威胁。然而典型的电力网络结构正变得日益复杂.单个电力的网络可能由多个内部网、远程设备、移动办公用户以及云服务构成。由于电力网络的边界变得日益模糊,传统的基于边界防护的电力网络安全策略变得不再适用。在这种背景下,业界提出了采用零信任架构.零信任体系结构的核心思想是默认情况下不信任网络内外的任何人、设备或系统,并基于身份验证和授权重构访问控制的信任基础。这意味着一个永不信任且始终进行身份验证的安全模型。在此模式下,能够很好的解决内部人员违规或恶意攻击问题,为实现电力物联网“任何时间、任何地点、任何人、任何事”的信息连接和安全交互提供保障。假设网络是恶意的,即使是企业的内部网也不例外,需要研究持续的身份认证和信任评估,通过实时评估设备和用户的信任,调整用户的权限级别,实现准确的管理和控制。
2、一般信任评估方法大致分为两类,一类是对信任度进行直接计算,缺乏动态性,不能实现“持续评估,永不信任”;另一类仅采用机器学习对设备和用户的信任度进行预测,未对参数进一步优化,模型预测精度不够高。
技术实现思路
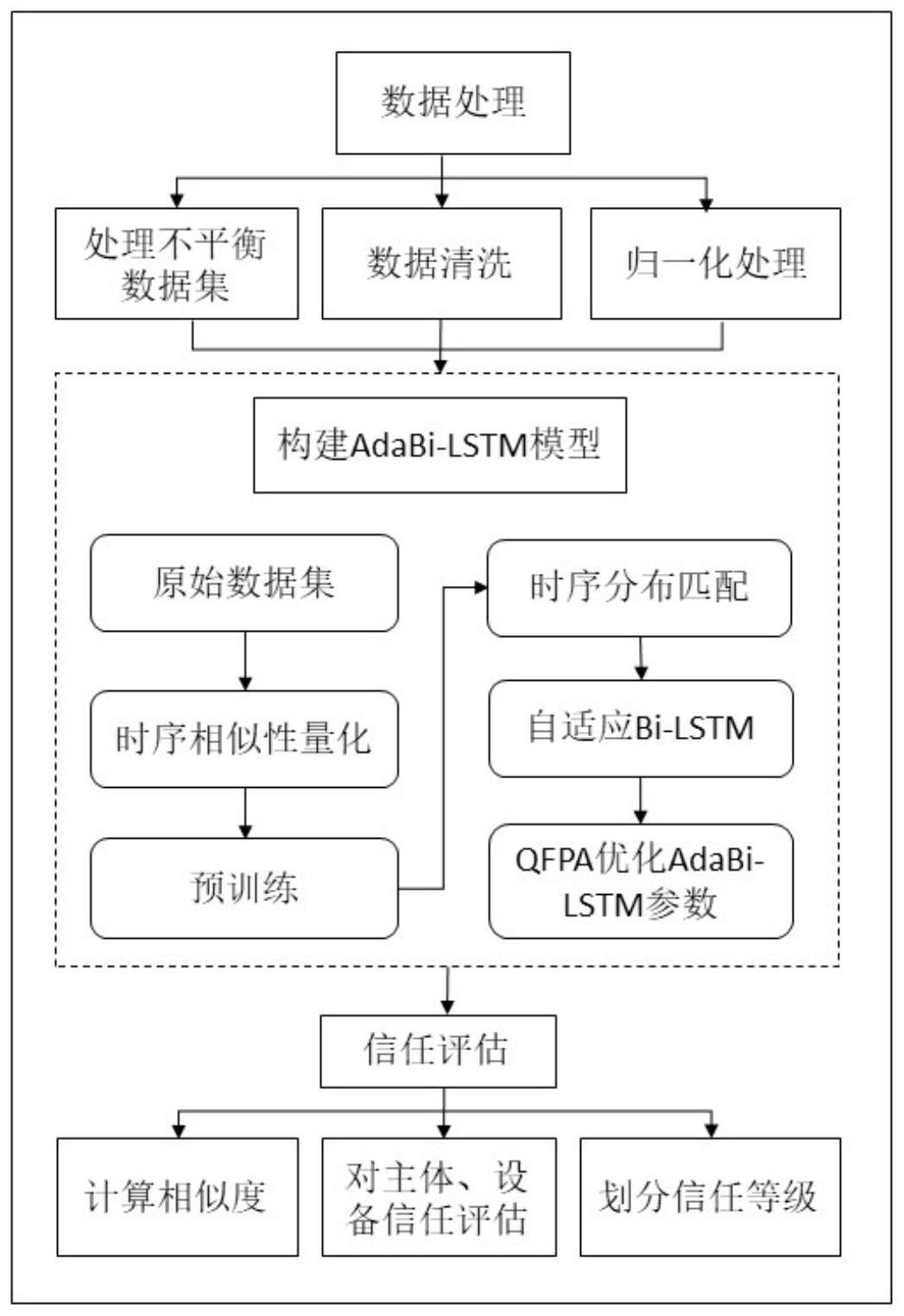
1、本发明提出一种基于量子花朵授粉算法优化adabi-lstm模型的电力设备和主体持续信任评估方法。该方法可帮助系统实现对设备和用户的持续信任评估,增强了信任评估的动态适应性、模型的预测精度和系统抵御恶意攻击的能力。
2、本发明采用数据集平衡方法-自适应综合过采样方法(adaptive syntheticsampling,adasyn)和adabi-lstm模型,通过训练模型,使用量子花朵授粉算法寻找adabi-lstm模型的最优或接近最优的结构和参数,实现对电力设备和主体行为的准确预测,克服了以往信任评估在适应性、精确度和算法效率等方面的缺陷。本发明具有良好的泛化能力。
3、为实现上述目的,本发明包括如下步骤:
4、步骤1,采集电力系统中多台设备和主体的静态信息、交互历史、动作属性、环境属性等信息;
5、步骤2,使用adasyn方法处理数据集的不平衡;
6、步骤3,对数据进行数据清洗,并进行归一化处理得到数据矩阵,并将数据划分为训练集与测试集;
7、步骤4,构建adabi-lstm信任评估模型,利用量子花朵授粉算法搜索adabi-lstm模型的最优或接近最优的结构和参数,以获得最佳的设备和主体信任度预测性能,包括batch_size、layers和每层单元数;
8、步骤5,将训练集作为adabi-lstm模型的输入,对模型进行训练,对模型的预测精度进行验证,以达到对设备和主体行为的精确预测;
9、步骤6,根据信任评估模型的预测结果,应用相似度算法计算相似度,对设备和主体进行信任评估;
10、步骤7,根据信任评估结果划分信任等级。
11、所述的使用adasyn方法处理数据集的不平衡步骤为:
12、步骤2.1:计算不平衡度:d=ms/ml,其中d∈(0,1],ms为少数类样本,ml为多数类样本。
13、步骤2.2:计算需要合成的样本数量:g=(ml-ms)×β,其中β∈[0,1]是一个用于指定合成数据生成后所需的平衡水平参数。当β=1时,g等于少数类和多数累的差值,此时合成数据后的多数类数据和少数类数据正好平衡。
14、步骤2.3:对每个属于少数类的样本用欧式距离计算k个最近邻居,计算比例ri为:ri=δi/k,i=1,...,ms,其中,δi为k个邻居中属于多数类的样本数目,ri∈[0,1]。
15、步骤2.4:在步骤2.3中得到每一个少数类样本的ri,用以下公式计算每个少数类样本的周围多数类的情况:
16、
17、其中:是密度分布,
18、步骤2.5:对每个少数类样本计算合成样本的数目其中g是合成样本总数;
19、步骤2.6:在每个待合成的少数类样本周围k个邻居中选择1个少数类样本,根据下列等式进行合成,重复合成直到满足需要步骤2.5合成的数目为止:
20、si=xi+(xzi-xi)×λ
21、其中:(xzi-xi)是n维空间中的差向量,λ∈[0,1]是一个随机数。
22、所述的adabi-lstm模型结构满足:
23、时序相似性量化(temporal distribution characterization,tdc):将时间序列中连续的数据分布情形进行量化,以将其分为k段分布最不相似的序列。其假设是如果模型能够将此k段最不相似的序列的分布差异减小,则模型将具有最强的泛化能力。因此对于未知的数据预测效果会更好。
24、为将时间序列切分为k段最不相似的序列(对应于正式中的求最大值操作、同时使得k最小),时序相似性量化方法将此问题表征为一优化问题:
25、
26、
27、其中:d是时间序列数据,n表示时间序列数据标记段的数量,d(·,·)表示相似度度量函数,δ1,δ2和k0是为了避免无意义的解而预先定义好的参数。此优化问题可以用动态规划算法进行高效求解。
28、时序分布匹配(temporal distribution matching,tdm)为上述k段时间序列构建迁移学习模型以学习一个具有时序不变性的模型。特别地,为了在迁移过程中不损失时序相关性,必须要动态度量bi-lstm单元中每个时间状态的重要。此时,迁移过程中每个时间状态对整个训练过程的重要性被可被动态地进行学习。
29、长短期记忆网络lstm其内在的存储单元和门机制可以克服传统rnn中梯度消失和爆炸的问题,在时间序列中保存延迟事件,并在后续训练中提取。核心计算公式如下:
30、ft=σ(wf·[ht-1,xt]+bf)
31、it=σ(wi·[ht-1,xt]+bi)
32、gt=tanh(wg·[ht-1,xt]+bg)
33、ct=ft*ct-1+it*gt
34、ot=σ(wo·[ht-1,xt]+bo)
35、ht=ot*tanh(ct)
36、其中:ft,it,gt,ot分别是遗忘门、输入门、更新门和输出门的输出值,四个门的输入包括lstm在t-1时刻的输出值ht-1和当前时刻的输入值xt,wf,wi,wg,wo均表示重矩阵,bf,bi,bg,bo均表示偏置向量,ct是记忆单元,σ是sigmoid激活函数。
37、单向lstm模型使用先前的信息来预测后续信息,而双向lstm(bi-lstm)可以同时全面学习前向和后向的时间相关信息,以提高预测精度。在电力设备和主体行为预测中,考虑到设备和主体行为时间序列数据中关于过去和未来的信息可以同时发挥重要作用,本发明使用bi-lstm进行预测,bi-lstm模型包括前向lstm层和后向lstm层。水平方向计算正向lstm隐藏向量同时每个时间步t计算后向lstm隐藏向量垂直方向表示从输入层到隐藏层然后到输出层的单向流。然后,连接两个隐藏状态来计算bi-lstm的最终预测。
38、本发明所述的量子花朵授粉算法满足:
39、在量子空间,用波函数描述量子花朵空间的花朵状态,在d维空间的第i个花朵的位置为xi(t)=(xi1,xi2,…,xim),建立可变的δ势肼场使花朵在局部点p(p1,p2,…,pd)具有聚集态,以一定的概率密度出现在空间任何点,使花朵可以在整个可行解空间进行搜索,但又不会发散到无穷处,具体步骤如下:
40、步骤4.1:初始化参数:花朵种群规模n,最大迭代次数nmax,转换概率p=0.8;
41、步骤4.2:计算当前种群的适应度值,记录全局最优值及其对应的最优解;
42、步骤4.3:分别利用以下公式计算花朵的平均最优位置avgbest及收缩扩张因子β,
43、
44、
45、步骤4.4:若转换概率p<rand,进入全局搜索,按以下公式对解进行更新,并对新解越界处理;
46、
47、其中:v=rand(0,1),q为局部吸引因子,由公式q=αx(t)+(1-α)xbest(α∈[0,1],xbest是种群中当前的最好位置)计算得到,l为δ势阱的特征长度是花朵进化算法中的重要变量,由公式l(t)=2β|avgbest-x(t)|计算得到;
48、步骤4.5:若转换概率p>rand,进入局部搜索,按以下公式对解进行更新,并对解进行越界处理;
49、
50、其中:q′=xbest,l′为δ势阱新修改的特征长度,由以下公式计算得到:
51、l(t)′=2β|avgbest-xbest|
52、步骤4.6:计算步骤4.4和步骤4.5的花朵个体的适应度值,并记录最优值和最优位置;
53、步骤4.7:判断结束条件,若满足,退出程序并输出最优值及最优解,否则转步骤4.3。
54、与现有技术相比,本发明方法具有以下优点:
55、1.本发明采用adasyn技术平衡数据集,不平衡是任何类型的数据集都可能出现的问题,导致预测模型效率降低的主要原因。因此,本发明采用这项技术可以避免预测模型的低效。
56、2.本发明采用的自适应双向长短时记忆网络,解决了机器学习界被称为分布移位问题,即因为时间序列的统计特性可以随时间而变化,进而导致分布随时间而变化。在本发明中,建立了时间序列预测的时间协变量移位(tcs)问题。提出了自适应双向长短时记忆网络来解决tcs问题。依次由两个模块组成。第一个模块称为时序相似性量化,旨在更好地表征时间序列中的分布信息。第二个模块是时间分布匹配,旨在减少时间序列中的分布失配,学习一种基于bi-lstm的自适应时间序列预测模型,以更好地泛化,对于电力设备和主体行为的预测更加准确,从而更准确的对电力设备和主体进行持续性信任评估。
57、3.本发明采用量子花朵授粉算法对adabi-lstm的结构和参数进行优化,以确定训练损耗最小的最佳预测模型进行目标电力设备和主体行为预测,提高模型的准确性。
- 还没有人留言评论。精彩留言会获得点赞!