基于错误传播建模和缺陷特征增强的软件错误定位方法
1.本发明属于软件测试技术领域,涉及到软件错误定位,具体涉及一种基于错误传播建模和缺陷特征增强的软件错误定位方法。
背景技术:
2.早期的软件错误定位大多采用设置断点等人工分析的方法,人工定位错误不仅难度大,而且极其耗时。自动化软件错误定位可以帮助开发人员节约错误定位成本,根据是否需要执行测试用例可以分为基于静态分析的错误定位和基于动态分析的错误定位。基于静态分析的方法不运行待测程序,仅静态的对被测程序的内在程序结构、界面或者文档进行分析,以确定错误语句在被测程序中的可能出现的位置。而基于动态分析的软件错误定位通过执行测试用例分析程序运行过程中产生的运行时状态,根据程序运行中的观测结果的变化确定缺陷位置,生成缺陷报告,为开发人员快速有效地定位软件错误提供参考。
3.在动态错误定位方法中,基于程序频谱的错误定位被证明是低成本且有效的方法之一。因为它独立于程序模型且易于实现。程序频谱表示程序运行时的覆盖信息,反应程序运行某一代码剖面的特征信息。程序频谱与程序行为之间存在着一定的关系,通过对比失败测试用例和成功测试用例之间代码覆盖的差异为软件错误定位提供帮助。对于任意一个程序实体si在测试用例下的覆盖特征可以用一个四元组表示即n(si)=(n
cf
,n
uf
,n
cp
,n
up
),其中这四个元素分别代表执行失败且覆盖si的测试用例个数、执行失败且未覆盖si的测试用例个数、执行成功且覆盖si的测试用例个数和执行成功且未覆盖si的测试用例个数。对于程序的单条语句,被失败测试用例执行的次数越多,通过测试用例执行的越少,语句含有错误的可能性就越大,利用这种特征对程序语句进行统计分析,找出含有错误的程序语句。本发明充分考虑每个测试用例的不同重要性,排除传统算法对每个测试用例都同样重要的假设,根据测试用例的重要性动态调整算法。该算法在不同测试集上得到的定位效果稳定,准确。
4.与开发软件一样,测试用例的设计也是人类一种脑力劳动,人们在设计测试用例可能会出现疏忽或者考虑不周等情况,不可避免的出现测试用例质量不佳的情况。测试用例的偶然正确性现象也是影响基于代码覆盖的错误定位技术有效性的主要因素之一,偶然正确性现象是指程序中包含错误的代码行被执行,但没有产生错误结果的现象。现有方法对偶然性正确测试用例的处理在提高真正错误语句可疑度的同时会提高正确语句的可疑度,从而导致提升错误定位的效果不太理想。
技术实现要素:
5.本发明针对上述基于频谱的错误定位技术的不足提出一种基于错误传播建模和缺陷特征增强的软件错误定位方法。应用复杂网络构建错误传播模型,计算测试用例权重。测试用例加权方法不局限于测试用例覆盖向量本身,通过分析程序频谱和程序语句之间的错误传播计算测试用例对错误定位的贡献大小。针对偶然性正确测试用例对错误定位的负
面影响,提出两种偶然性正确测试用例处理方法进行缺陷特征增强,得到优化的程序频谱,从而提高软件错误定位效率。
6.本发明方法具体包括以下步骤:
7.步骤1:对源程序进行插桩,执行测试用例,收集测试用例的程序频谱,包括执行结果和执行覆盖信息;
8.步骤2:降低偶然性正确测试用例对错误定位的负面影响;
9.步骤3:分别使用成功和失败测试用例的执行覆盖信息建立两个有向无权复杂网络模型g
p
和gf;
10.3-1.根据程序频谱建立测试用例和语句节点之间的连接,如果测试用例ti覆盖语句sj则节点ti与sj之间存在双向边;
11.3-2.根据测试用例执行上下文建立语句和语句节点之间的连接,单向逆序连接测试用例执行轨迹中的语句节点;
12.步骤4:通过trustrank排名算法分别计算复杂网络模型g
p
和gf中每个节点的重要性,并通过节点重要性给成功和失败测试用例分配权重,计算加权后的语句执行四元组信息;
13.4-1.构造转移矩阵表示网络模型中节点之间的随机游走跳转概率,对g
p
和gf构造转移矩阵方法相同;
14.对于gf,构造一个大小为ns×nt
的矩阵s2t,其中ns表示失败测试用例执行向量并集的语句数量,n
t
表示失败测试用例的数量;如果语句si覆盖tj,tj执行条语句,表示tj执行的语句数量,分配因为tj执行条语句时每条语句对tj的tr贡献值为构造一个大小为n
t
×ns
的矩阵t2s,如果tj执行si,si覆盖个失败测试用例,分配因为si执行个失败测试用例时,每个测试用例对si的tr贡献值为构造一个表示语句之间错误传播的ns×ns
的转移矩阵s2s,当语句si与sj之间有边时,s
ij
=1/ns,并将s2s按列归一化;
15.4-2.构造信任传播向量,选择测试用例节点作为种子节点,添加测试用例提供的额外信息来控制节点在网络模型中的游走行为;让复杂网络在随机游走过程中对该种子节点集合具有更高的偏向性;
16.信任传播向量的形式设置为vs表示语句的信任传播向量,v
t
表示测试用例的信任传播向量;因为只选择测试用例节点作为种子节点,所以在gf中,失败测试用例执行的语句数量越少,则权重应该越大,所以其中:ci表示ti执行的语句数量,由于成功测试用例不满足上述分析,在g
p
中给成功测试用例分配相同的权重值即其中n
p
是成功测试用例总数;
17.4-3.计算语句执行四元组信息,每一轮迭代过程中,语句节点吸收相连的测试用例节点和指向其的语句节点的重要性,测试用例节点根据连接的语句节点重要性修改自身的重要性,语句和测试用例节点重要性相互作用,直至整个网络节点重要性稳定;如第k次
迭代时,相应节点重要性的计算:
[0018][0019][0020]
其中ws和w
t
分别代表语句和测试用例的节点重要性向量,α是阻尼系数,作用是使得计算迭代中节点值传递能够稳定延续,不至于中断或者无限放大;运行两次上述算法,得到gf和g
p
中节点重要性向量,迭代完成后对向量标准化:
[0021][0022]
4-4.通过修改后的测试用例权重信息计算语句的四元组信息向量:
[0023][0024][0025]
其中和分别表示程序中每条语句执行失败和成功测试用例数量的向量,nf和n
p
分别表示失败和成功测试用例总数;
[0026]
步骤5:通过sbfl计算公式根据语句的四元组信息计算可疑度,将错误定位信息按可疑度降序排列,可疑度高的语句被认定为更有可能出错。
[0027]
作为优选,步骤1所述的获取程序频谱具体为:
[0028]
在ubuntu系统中使用gcc对源程序进行编译处理,动态执行测试用例并使用gcov工具收集测试用例的执行结果和执行覆盖信息,得到程序频谱。
[0029]
作为优选,步骤2所述的降低偶然性正确测试用例对错误定位的负面影响具体为:
[0030]
对所有失败测试用例的语句覆盖向量做交运算,得到的程序语句集合定义为故障基;定义偶然性正确测试用例为执行故障基中所有语句的成功测试用例;使用方法1或者方法2;其中方法1为:将故障基中语句覆盖偶然性正确测试用例的位置修改为未覆盖;方法2为:将故障基之外的覆盖偶然性正确测试用例的位置修改为未覆盖并重新标记偶然性正确测试用例为失败测试用例,得到新的程序覆盖信息。
[0031]
作为优选,步骤5所述的通过sbfl计算公式根据语句的四元组信息计算可疑度,具体如下:
[0032]
通过sbfl计算公式根据语句的四元组信息向量计算可疑度,如通过sbfl计算公式根据语句的四元组信息向量计算可疑度,如将错误定位信息按可疑度进行降序排列,可疑度高的语句被认定为更有可能出错。
[0033]
本发明较传统方法来说有以下有益效果:
[0034]
本发明考虑到偶然性正确测试用例的存在会降低真正错误语句的可疑度,因此通过减少偶然性正确测试用例对真正错误语句的覆盖率减小偶然性正确测试用例对错误定位产生的负面影响。
[0035]
本发明考虑到基于频谱的错误定位技术隐式地认为每个测试用例都同样重要。然而一些不频繁的覆盖关系(例如,覆盖少数程序实体的测试或覆盖少数测试的程序实体)对错误定位更有帮助,因此考虑测试用例权重可以更高效的区分测试用例对错误定位的贡
献,降低错误定位代价。
[0036]
本发明考虑到基于频谱的错误定位技术只关心程序覆盖测试用例信息,将每个程序实体孤立对待,忽视程序实体的内部信息及其之间的交互关系。然而与可疑度越大的语句存在交互的语句,可疑度也应更大,因此考虑错误传播可以减少多条语句的错误怀疑度值相同对错误定位效率的影响。
附图说明
[0037]
图1为示例程序代码及程序频谱。
[0038]
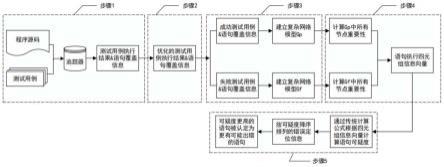
图2为本发明整体示意图。
[0039]
图3为处理偶然性正确测试用例流程图。
[0040]
图4为计算复杂网络模型节点重要性流程图。
[0041]
图5为本发明中的阻尼系数α对错误定位性能提升的实验结果图。
[0042]
图6为本发明在tarantula公式上错误定位性能提升的实验结果图。
具体实施方式
[0043]
为检验本发明所提方法的定位效率,使用siemens suit进行实验验证。该套件包含print_tokens、print_tokens2、schedule、schedule2、replace、tcas、tot_info7个项目,这些待测程序中的缺陷位置、缺陷数目和缺陷类型都是已知的。选取图1所示的siemens中print_tokens2程序的is_num_constant()作为示例程序对本发明进行详细说明。本发明整体示意图如附图图2所示,具体步骤如下:
[0044]
步骤1:输入is_num_constant()与测试用例集{t1,t2,t3,t4,t5,t6,t7};
●
代表运行测试用例时语句被执行,空白表示未覆盖,最后一行为测试用例的执行结果,p和f分别代表该测试用例为成功和失败测试用例。
[0045]
步骤2:减小偶然性正确测试用例的干扰,流程图如图3所示。对所有失败测试用例的语句覆盖频谱做交运算,得到的程序语句集合定义为故障基,定义偶然性正确测试用例为执行故障基中所有语句的成功测试用例。方法1将故障基中语句覆盖偶然性正确测试用例的位置修改为未覆盖,方法2将故障基之外的覆盖偶然性正确测试用例的位置修改为未覆盖并重新标记偶然性正确测试用例为失败测试用例。示例中,故障基fb={s1,s2,s3},t3,t5,t7执行故障基中的所有语句,为偶然性正确测试用例。对于方法1,将t3,t5,t7执行fb的位置修改为未覆盖,减少真实错误语句覆盖的成功测试用例数。对于方法2,将t3,t5,t7重新标记为失败测试用例并将其执行fb之外的位置修改为未覆盖,减少真实错误语句覆盖成功测试用例数的同时增加真实错误语句覆盖的失败测试用例数。
[0046]
步骤3:以步骤2中的方法1为例,分别使用成功和失败测试用例的执行覆盖信息构建两个有向无权复杂网络模型g
p
和gf。
[0047]
3-1.根据程序频谱建立测试用例和语句节点之间的连接,如果ti测试用例覆盖sj语句则节点ti与sj之间存在双向边。如测试用例t1与语句节点s1、s2、s3、s4、s5、s6、s8之间存在双向边。
[0048]
3-2.根据测试用例执行上下文建立语句和语句节点之间的连接。分析错误传播,考虑到程序语句行为异常和错误传播对全局错误怀疑度的影响,建立网络中语句节点之间
的拓扑关系。语句之间错误传播的原则是:在测试用例执行路径中语句之间存在不同程度的错误传播并且假定错误是从程序执行上下文的底端向顶端传播。如示例程序的gf,测试用例t1,执行路径为{s1,s2,s3,s4,s5,s6,s8},所以存在边《s8,s6》,《s6,s5》,《s5,s4》,《s4,s3》,《s3,s2》,《s2,s1》;测试用例t2的执行路径为{s1,s2,s3,s4,s5,s7},增加边《s7,s5》。测试用例t6的执行路径为{s1,s2,s3,s8},增加边《s8,s3》。
[0049]
步骤4:通过trustrank排名算法分别计算复杂网络模型g
p
和gf中每个节点的重要性,并通过节点重要性给成功和失败测试用例分配权重,计算加权后的语句执行四元组信息,具体流程如图4所示。具体的计算如下:
[0050]
4-1.首先构造转移矩阵表示网络模型中节点之间的随机游走跳转概率,对g
p
和gf构造转移矩阵方法相同。
[0051]
其中对于gf,构造一个大小为8
×
3的矩阵s2t,如语句s1覆盖t1,分配s2t
11
=1/7。因为t1执行7条语句,每条语句对t1的tr贡献值为1/7;构造一个大小为3
×
8的矩阵t2s,如t1执行s1,分配t2s
11
=1/3,因为s1执行3个失败测试用例,每个测试用例对s2的tr贡献值为1/3;构造一个表示语句之间错误传播的8
×
8的转移矩阵,当语句si与sj之间有边时,s
ij
=1/8,并将s2s按列归一化。
[0052][0053][0054][0055]
通常数据集中的测试用例数远远大于语句数,所以语句之间的错误传播矩阵s25一般为稀疏矩阵,t2s和s2t对网络中的节点重要性影响更大
[0056]
4-2.构造信任传播向量,选择测试用例节点作为种子节点,添加测试用例提供的额外信息来控制节点在网络模型中的游走行为。让复杂网络在随机游走过程中对该种子节点集合具有更高的偏向性。
[0057]
信任传播向量的形式设置为因为只选择测试用例节点作为种子节点,所以
[0058]
在gf中,失败测试用例执行的语句数量越少,则权重应该越大,所以中,失败测试用例执行的语句数量越少,则权重应该越大,所以其中:
[0059]
由于成功测试用例不满足上述分析,在g
p
中给成功测试用例分配相同的权重值即
其中n
p
是成功测试用例总数。
[0060]
示例程序的信任传播向量应设置为示例程序的信任传播向量应设置为
[0061]
4-3.节点重要性计算,因为trustrank算法是利用种子节点集合计算的pagerank值,所以为网络中的节点设置初始值的原则是:将种子节点的初始值设置为信任传播向量,其他节点初始值置0,阻尼系数α设置为0.5。trustrank算法在计算gf和g
p
中节点的重要性时,每一轮迭代过程中,语句节点吸收相连的测试用例节点和指向其的语句节点的重要性,测试用例节点根据连接的语句节点重要性修改自身的重要性,语句和测试用例节点重要性相互作用,直至整个网络重要性稳定。如第k次迭代时,相应节点重要性的计算:
[0062][0063][0064]
运行两次上述算法,得到gf和g
p
中节点重要性向量,迭代完成后对向量标准化:
[0065][0066]
示例程序的语句节点重要性向量为示例程序的语句节点重要性向量为
[0067]
4-4.通过修改后的测试用例权重信息计算每条语句的四元组信息。
[0068][0069][0070]
其中和分别表示程序中每条语句执行失败和成功测试用例数量的向量,nf和n
p
分别表示失败和成功测试用例总数。示例程序的ef=[1,1,0.99,0.57,0.57,0.29,0.26,0.62,0],e
p
=[1,1,0.66,0.4,0.4,0.4,0.18,0.42,0.3]。
[0071]
步骤5:通过sbfl计算公式根据每条语句的四元组信息计算可疑度,将错误定位信息按可疑度进行降序排列,以计算公式为例,本发明得到的语句可疑度次序为{s3,s8,s7,s4,s5,s2,s1,s6,s9},传统tarantula得到的语句可疑度次序为{s4,s7,s8,s5,s3,s1,s2,s6,s9}。从实施例中可以看出通过本发明真实错误语句s3的可疑度排名得到提升。
[0072]
图5展示了在[0,1.0]的范围内调节α对本发明wtfl方法在12个经典错误定位计算公式上性能提升结果。横轴表示α的不同取值,纵轴表示在不同错误定位器上mwe(最小平均检查语句数)指标提升的百分比。
[0073]
图6进一步比较了7个项目的错误定位绝对排名结果(log2对数尺度)的分布,使用原sbfl的错误定位公式tarantula和本发明wtccl、wtcc2方法绘制小提琴图。横轴表示不同的错误定位方法,纵轴表示错误语句排名等级即错误语句位于可疑度排名列表中的位置。小提琴图中的黑色图例反映错误语句的等级分布,中间线表示检测到的错误绝对排名位置的中位数,上下的线分别表示上下四分位数。由图可得,与原始sbfl结果相比,本发明的中
位数和四分位数向下移动,多数错误语句的分布也处于较低的位置,且小提琴图的位置整体偏下,说明错误语句整体排名提高,可见本发明可以有效提高错误定位方法的定位效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1