一种面向区块链低存储开销的审计数据有效性验证方法
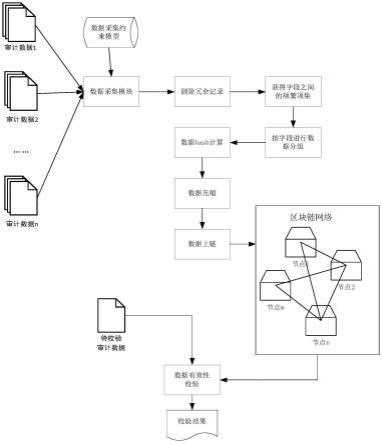
1.本发明属于区块链和审计领域,特别是涉及一种面向区块链低存储开销的审计数据有效性验证方法。
背景技术:
2.现代审计要求实行审计全覆盖,审计所需要的数据广度和深度将发生明显的变化,大量历史数据将可能被综合应用到审计全覆盖的流程中,如何保障大量审计数据存储的有效性以及校验的高效性,是现代审计面临的一个重要问题。区块链技术具有不可篡改、可追溯等特点,能大幅提升审计的可靠性,但审计数据多而复杂,不同审计需求用到的数据相差很大,如果将所有历史数据做一个总的校验值,将可能由于某些无关数据的失效而导致整批数据校验不通过,因此有必要对审计数据进行分类校验,细粒度管理。而区块链技术的数据有效性保证是建立在大量副本基础之上,如果数据管理的粒度过细,区块链需保存的校验数据量将十分庞大,且大部分情况下这些存储的数据频繁使用,因此不利于资源的有效利用。为同时满足审计数据细粒度管理需求和区块链低存储开销的要求,需有效结合审计的特点,对数据进行精准管理,既有效保障审计数据有效性校验的准确性,又尽可能降低校验数据在区块链上的存储要求。
技术实现要素:
3.为解决上述问题,本发明结合数据关联分析和数据压缩技术,提出一种面向区块链低存储开销的审计数据有效性验证的方法。
4.技术方案:
5.所述方法包括以下步骤:
6.(1)采集数据,并构建审计数据采集约束规则,主要用于对采集的数据进行约束;其形式化表示为m(d,r),其中,d表示所有采集的数据集合,数据采用二维表的形式进行保存,记为d(t1,t2,
…
,tn),ti(1≤i≤n)为其中的一个表,每个表ti包含多条记录,每条记录可分为多个字段,用于表示该记录的不同属性特征;r表示所有约束的集合,以实现该方法的具体编程语言的语法进行定义,以判断采集数据是否有效;
7.(2)对于同一个表中的数据,以记录为单位,进行数据条目之间的相似度分析,如果两条记录的相似度超过阈值τ,则删除分析的第二条记录;
8.(3)以字段为单位,以历史审计信息为基础,使用apriori算法进行频繁项分析,确定各数据字段同时使用的频度及最大频繁项集;
9.(4)根据数据字段的最大频繁项集,对数据字段进行分组,并构建字段到分组的映射m;
10.(5)以分组为单位,对数据进行hash编码,形成总的hash列表h,并建立各数据分组到其对应hash编码位置的映射i_hash;
11.(6)对m和i_hash进行序列化,然后采用成熟的压缩算法,对m、h和i_hash进行压缩
编码;
12.(7)将压缩后的数据作为交易数据保存在区块链上;
13.(8)当需要校验数据时,先在区块链中找到该字段所在分组对应年份的链上hash值h1,并获得该分组的所有字段xt。然后提取xt中包含的所有字段相应年份的数据进行hash值计算,得到其hash值h2。最后对比h1和h2,如果两者相等,则验证通过;否则,验证不通过。
14.优选的,步骤(2)中数据相似性分析将以记录为单位,分层进行计算。我们用ri表示第i条记录,表示第i条记录的第k个字段。在计算记录ri与rj之间的相似度时,将分为以下两个步骤:
[0015]-依次遍历记录的每个字段,对于第k个字段,如果该字段是字符型数据,则计算与的编辑距离然后通过公式来获得该字段的相似度,其中表示和中字符串的总长度;如果该字段是数值型数据,则先分别计算他们的欧式距离余弦相似度和皮尔森相关系数然后取其中最大额值作为该字段的相似度,即
[0016]-采用平均法综合各字段的相似度作为记录的相似度。即对于ri与rj的相似度s
i,j
,其相似度为其中,n表示该条记录字段的个数。
[0017]
优选的,步骤(4)中根据数据字段的同时使用频度进行分组时,如果字段已经被包含于某一个最大的频繁项集,则将该字段与该频繁项集中的其他字段划分为一组。对于不属于任意频繁项集的字段集合x,我们将以该字段所在记录为基准,如果xi,xj∈x,且xi,xj属于同一记录的不同字段,则将xi和xj划分到同一组中。并采用字典m保存每个字段所在分组,m中每一项表示为{k:(num,z)}。其中k表示字段名,num表示分组编号,z表示该分组中包含的所有字段。通过m[k]可以找到k字段所在分组num以及num分组包含的所有字段。
[0018]
优选的,步骤(5)中计算分组的hash值时,我们将根据数据采集的时间,以年度为单位,分别计算每个分组的hash值。具体的包括以下步骤:
[0019]-设置总的hash字段h,初始化为空;
[0020]-依次遍历每个分组,根据分组包含的字段,提取该分组采集的所有数据d1;
[0021]-以年度为单位,将相同年份对应字段的数据提取出来,然后采用md5方法依次计算每个年份的hash值。对于没有数据的年份,用其数据用一条全0的记录表示;
[0022]-将所有年份的hash值按年份递增的顺序依次拼接到h的后面;
[0023]-构建i_hash,采用字典结构,每一项表示为{num:(off,year)},其中num表示分组编号,off表示该分组对应hash相对于h起始位置的偏移值,year表示这批数据的起始年份。
[0024]
优选的,步骤(6)中压缩编码时,我们将m、h和i_hash分别进行压缩,然后再进行拼接,形成压缩后的数据。具体包括以下几个步骤:
[0025]-将m中每个元素用其本身的字符串表示作为其序列化值,元素之间用“#”进行连接,即“k1:(num1,z1)#k2:(num2,z2)#...#kn:(numn,zn)”,其序列化结果为seqm;
[0026]-使用m序列化相同的方法对i_hash进行序列化,得到seq
i_hash
;
[0027]-使用成熟压缩算法对seqm、seq
i_hash
和h分别进行压缩,得到压缩后的数据依次为compm,comp
i_hash
,comph。
[0028]-将数据按照如下结构进行拼接,形成压缩后的数据。其中len(compm)表示compm的长度,以字节计算,占4个字节,len(comp
i_hash
)表示compm的长度,以字节计算,占4个字节。
[0029][0030]
优选的,步骤(8)中查找字段y在所在分组q年份的链上hash值时,将先对compm、comp
i_hash
、comph字段分别进行解压缩,然后根据获得的映射表m和i_hash。具体包括以下步骤:
[0031]-定位到交易字段x,从其前8个字节分别提取len(compm)和len(comp
i_hash
)的值。
[0032]-根据len(compm)值,从x起始位置偏移8个字节的位置开始解压len(compm)字节的数据,并进行反序列化,得到m;
[0033]-根据len(compm)值,从x起始位置偏移(8+len(compm))个字节的位置开始解压len(comp
i_hash
)字节的数据,并进行反序列化,得到i_hash;
[0034]-从x起始位置偏移(8+len(compm)+len(comp
i_hash
))个字节的位置开始解压到x字段的最后,得到h;
[0035]-根据要查找的字段y,先通过m字典映射,查到y所对应的分组及其所包含的字段(numy,zy);
[0036]-根据numy,通过i_hash[numy]查找到该分组在h中的偏移和起始年份(offy,yeary);
[0037]-在h偏移(offy+(q-yeary)*16)字节的位置,取出16字节的数据,即为字段y在所在分组q年份的链上hash值hy;
[0038]-返回(hy,zy)。
[0039]
本发明的有益效果
[0040]
面向区块链低存储开销的审计数据有效性验证方法,一方面可以借助于区块链技术,有效的校验大量历史审计数据的有效性,避免因有意或无意的篡改数据对审计造成影响;另一方面,借助于冗余数据消除、关联分析和压缩算法,删除了不必要的数据,对关联紧密的数据进行联合校验,避免了单数据校验带来的数据量剧增的风险,有效提高了校验数据的存储效率和使用效率。面向区块链低存储开销的审计数据有效性验证方法,将有望取代传统的基于数据库的审计数据存储方法,成为审计数据存储有效性研究领域的一个重要突破点。
附图说明
[0041]
图1是本发明一种面向区块链低存储开销的审计数据有效性验证方法的示意图;
[0042]
图2冗余记录示意图;
[0043]
图3历史采集的审计数据示意图;
[0044]
图4m映射示意图;
[0045]
图5i_hash映射示意图;
[0046]
图6压缩后的上链数据示意图。
具体实施方式
[0047]
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
[0048]
结合图1,一种面向区块链低存储开销的审计数据有效性验证方法,包括以下步骤:
[0049]
(1)采集数据,并构建审计数据采集约束规则,主要用于对采集的数据进行约束。具体的,假如我们采集的数据为人员信息,里面包含有(姓名、年龄、身份证号、住址、手机号码)5个信息,分别依次用(name,age,identity,address,mobile)表示。那么对于年龄字段,一般要求年龄是正数且不超过100岁,假如实现该方法的编程语言是c语言,那么可以在规则模板中限定”age》0&&age《=100”,以确保输入的数据符合要求。
[0050]
(2)对于同一个表中的数据,以记录为单位,进行数据条目之间的相似度分析,如果两条记录的相似度超过阈值τ,则删除分析的第二条记录。具体的,对于如图2所示的两条人员信息记录,我们假设name、identity、address和mobile四个字段都是字符型数据,age是数值型数据,因此在计算name、identity、address和mobile四个字段时,我们将基于编辑距离进行计算。对于name字段,两条记录都是“张三”,完全相同,编辑距离为0,因此其相似度为1。同理,identity和mobile的相似度也为1。对于address字段,第二条记录比第一条记录少了3个字,我们假设一个汉字占2个字符,因此其编辑距离为6。而两者总的字符数为“江苏省南京市浦口区雨山西路八号”的字符数(即30)加上“南京市浦口区雨山西路八号”的字符数(即24),总共为54个字符,因此在address字段,其相似度为(54-6)/54=0.889。对于age字段,由于两个数值都为18,因此该字段的相似度为所以两条记录总的相似度为(1+1+1+0.889+1)/5=0.978。如果阈值设置为0.8,则认为这两条记录相同,可以删除第二条记录。
[0051]
(3)以字段为单位,以历史审计信息为基础,使用apriori算法进行频繁项分析,确定各数据字段同时使用的频度及最大频繁项集。比如,我们使用apriori算法,对历史审计数据的使用情况依次进行分析,如果“name”和“identity”字段大部分情况下都是一起被使用,则他们将被划分到一个最大频繁项集中。
[0052]
(4)根据步骤(3)获得的最大频繁项集,对数据字段进行分组,如果字段已经被包含于某一个最大的频繁项集,则将该字段与该频繁项集中的其他字段划分为一组。对于不属于任意频繁项集的字段集合x,我们将以该字段所在记录为基准,如果xi,xj∈x,且xi,xj属于同一记录的不同字段,则将xi和xj划分到同一组中。并采用字典m保存每个字段所在分组,m中每一项表示为{k:(num,z)}。其中k表示字段名,num表示分组编号,z表示该分组中包含的所有字段。通过m[k]可以找到k字段所在分组num以及num分组包含的所有字段。比如步骤(3)获得的第一个最大频繁项集包括“name”和“identity”这两个字段,那么我们将他们划分到一个组,标记其编号为1,并构建字典映射{“name”:(1,{“name”,“identity”})}和{“identity”:(1,{“name”,“identity”})},加入到m中。
[0053]
(5)以分组为单位,对数据进行hash编码,形成总的hash列表h,并建立各数据分组
到其对应hash编码位置的映射i_hash。具体的,计算分组的hash值时,我们将根据数据采集的时间,以年度为单位,分别计算每个分组的hash值。如图3所示,里面记录了2017年和2018年两年的相关数据,其中通过步骤(4)分析,“time”、“info”和“price”是一组,“id”是单独一组,其在m中的记录如图4所示。此时,在计算这批数据的hash时,我们首先将其分为如图3(b)所示的4组数据。接着将每组数据转为字符串进行拼接。如对于图3(b)的分数据1,我们将其拼接为“2017.3.29感冒灵颗粒152017.10.30穿心莲内酯软胶囊17.5”,然后求其md5值为:0x9fbb189f03956d0f8a1e27d34c6b1a4d。同理,将其他三组分数据进行md5值求解,分别获得其结果为:0x62766d090d6f67c33d7e074db67a9dec、0x58562d4d3209d2d0dff8b18549af8f14、0x5c8f32fbecb74e25c8a5ec655b61e5f5。接着将其进行拼接获得二进制hash串0x9fbb189f03956d0f8a1e27d34c6b1a4d62766d090d6f67c33d7e074db67a9dec58562d4d3209d2d0dff8b18549af8f145c8f32fbecb74e25c8a5ec655b61e5f5。同时,将分组相关信息加入i_hash,获得如图5所示的i_hash。
[0054]
(6)对m和i_hash进行序列化,然后采用成熟的压缩算法(如lzw,lzma、lz4等),对m、h和i_hash进行压缩编码。具体的,图4所示m将序列化为“time:(28,{time,info,price})#info:(28,{time,info,price})#price:(28,{time,info,price})#id:(29,{id})”,图5所示的i_hash序列化为“28:(0,2017)#29:(32,2017)”。然后使用成熟的压缩算法,如lzw等,对m、i_hash、h进行压缩,得到类似图6所示的压缩后额数据。
[0055]
(7)将压缩后的数据作为交易数据保存在区块链上;
[0056]
(8)当需要校验历史数据有效性时,先在区块链中找到该字段所在分组对应年份的链上hash值h1,并获得该分组的所有字段xt。然后提取xt中包含的所有字段相应年份的数据进行hash值计算,得到其hash值h2。最后对比h1和h2,如果两者相等,则验证通过;否则,验证不通过。具体的,假设要查找图3中price字段2017年份的数据是否有效,我们先从链上找到对应的区块,获得如图6所示的交易数据x。然后从其前8个字节的值,获得len(compm)=0x2c=44,len(comp
i_hash
)=0x10=16。接着,我们从x起始位置偏移8字节的位置开始,获得44字节的数据,并进行解压缩,得到m序列化后的结果数据。进而通过反序列化,获得如图4所示的m。同理,可以获得如图5所示的i_hash以及h值。由于现在要校验的是price字段2017年份的数据,因此在m中查找price,发现其组号为28,组内成员有{“time”,“info”,“price”}。根据组号28,我们在i_hash中找到其位置信息为(0,2017),因此2017年份的price所在组的校验数据即为i_hash开始16字节的数据,假设其值为0x9fbb189f03956d0f8a1e27d34c6b1a4d。接着,系统将返回二元组(0x9fbb189f03956d0f8a1e27d34c6b1a4d,{“time”,“info”,“price”})。校验者获得该信息后,提取出2017年份{“time”,“info”,“price”}这三个字段的值,计算其md5值。如果其重新计算的md5值等于0x9fbb189f03956d0f8a1e27d34c6b1a4d,则表明数据有效;否则,即为无效数据。
[0057]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1