一种基于自适应直方图均衡化的视觉定位方法
1.本发明属于视觉定位领域,是一种基于二分支网络:位姿估计网络和深度估计网络来估计单目相机运动轨迹的视觉定位算法。针对室内场景图像存在过度曝光或曝光不足的场景,该算法通过引入基于自适应直方图均衡理论(clahe)的对比度增强算法改善图像过度曝光问题,有效提高视觉定位精度。
背景技术:
2.随着机器人技术的不断发展,机器人位置的准确定位对机器人的运动规划和导航等下游任务具有至关重要的影响。智能机器人的服务场景目前主要可以分为室内场景和室外场景,在室外环境下,全球导航卫星系统(gnss)通过卫星信号可以提供精确的位置服务,在室内场景下,由于室内建筑物的干扰,无线卫星信号不稳定导致基于全球导航卫星系统的定位精度不尽如人意,视觉里程计(visual odometry)无需借助任何外界信号,仅通过估计相邻图像帧之间的运动来确定主体的相对位置,因其实时性高,部署简单,成本低等优点逐渐成为视觉定位领域的热点研究内容。
3.视觉里程计目前根据传感器类型可以分为单目视觉里程计和双目视觉里程计。单目视觉里程计实时性高,系统结构简单,但缺乏绝对尺度,存在尺度不确定性问题,双目视觉里程计通过固定基线在三角测量可以获取图像绝对尺度。近年来深度学习逐渐在计算机视觉领域成为主流,基于数据驱动的视觉里程计算法通过卷积神经网络代替传统方法中的视觉特征提取模块,并能得到更加高级的视觉特征,进而借助神经网络强大的学习能力得到最终的位姿估计。
4.尽管深度学习对于视觉里程计带来了巨大的性能提升,目前在视觉里程计领域仍然存在一些问题亟待优化。图像帧作为视觉里程计的输入,其中所包含的纹理和边缘特征主要受到光照的影响,在室外场景中,由于过度曝光导致图像会出现过亮的区域,而室内场景中由于光照不足会导致图像出现过暗的区域。图像的过亮或过暗都会导致图像纹理及边缘信息的缺失,进而影响后续神经网络对于图像视觉特征的学习,降低模型推理精度。
5.为解决上述问题,本发明基于直方图均衡化理论通过融合限制对比度自适应直方图均衡化算法(clahe)恢复并增强过度曝光或曝光不足的图像的纹理和边缘细节特征,提出了一种基于clahe的视觉定位算法。
技术实现要素:
6.针对场景光照条件和天气因素的影响,本发明采用基于直方图均衡化的图像增强算法对过度曝光或曝光不足的图像进行图像纹理细节信息恢复,然后采用基于深度残差神经网络的二分支预测网络计算输入视频帧的相机位姿结果。
7.为实现上述目的,本发明采取如下技术方案:
8.首先,在离线阶段,对于输入的时间序列图像帧序列,通过图像增强模块恢复并增强输入图像的纹理和边缘结构信息,然后将增强图像输入掩膜模块对图像中的动态目标和
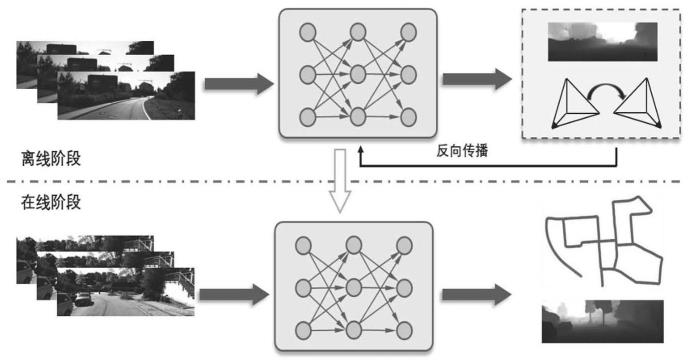
遮挡进行剔除,接下来将预处理的增强图像馈入resnet编码器提取图像运动和深度信息,最终通过解码器恢复图像尺寸并得到位姿预测结果,然后根据损失函数得到的梯度通过反向传播更新网络权重,最终得到鲁棒的位姿估计网络模型。在在线阶段,将输入图像帧序列馈入训练得到的网络模型得到相应的位姿估计结果。本发明定位方法的示意图参见图1。
9.一种基于自适应直方图均衡化的视觉定位方法,算法流程图如图2所示,主要分为离线模型构建和在线实时定位两个阶段:
10.离线模型训练阶段中主要包括以下模块:
11.(1)图像增强模块:对于输入的图像帧序列,首先进行图像的分块填充,然后基于直方图均衡化策略对每个分块计算映射关系,基于得到的映射关系进行对比度限制,最后通过双线性插值得到增强图像。利用限制对比度的直方图均衡化方法对图像的边缘和纹理信息进行增强,改善图像中过亮或过暗区域的目标物体显示。
12.(2)基于resnet的编码器:使用经典的特征提取网络resnet提取增强图像的时间和空间特征,步骤如下:
13.定位模型由一个二分支网络组成:深度预测网络和位姿估计网络。其中深度预测网络用于产生图像的深度信息,借助图像的深度信息缓解长序列位姿估计的尺度漂移问题。对于深度预测网络,解码器部分采用resnet50提取图像时空特征。对于位姿估计网络,采用resnet18作为解码器,为了使输入图像同时输入两张图像,修改resnet第一层输入通道为6通道输入。
14.确定各隐含层层数、各层神经元个数、学习率,设置各层预训练迭代次数、微调迭代次数等网络参数;设置输出层的激活函数为sigmoid函数,其他非线性激活层激活函数为elu。
15.两个网络通过同一个损失函数联合训练,损失函数由光度一致性损失、边缘平滑损失和深度一致性损失三部分得来。
16.(3)解码器:对于深度预测网络,如图3所示,采用dispresnet作为解码器,通过逐层上采样将图像时空特征恢复。对于位姿估计网络,如图4所示,采用poseresnet设计四层卷积层得到6自由度预测位姿。
17.(4)基于遮挡掩码的掩膜:场景中的动态目标和遮挡违反了静态场景假设。由于动态目标和遮挡的存在,预测图像深度信息与真实图像深度会在动态目标区域产生明显的深度不一致性,进而影响深度网络和位姿网络参数的正确学习。如图5所示,基于预测的单视图深度信息,通过视图合成原理将目标视图翻转到源视图中得到合成的目标深度图,然后将目标视图深度图和合成的目标深度图作差得到深度差异图,并将其进一步计算为二进制掩膜,二进制掩膜在动态目标区域差异值大而静态区域差异近乎零,借助二进制掩膜用于在计算损失前剔除动态目标和遮挡的干扰。
附图说明
18.图1是本视觉定位方法的流程图。
19.图2是离线阶段本发明clahe结合resnet定位算法流程图。
20.图3是深度估计网络基本结构图。
21.图4是位姿估计网络基本结构图。
22.图5是掩膜生成网络基本结构图。
具体实施方式
23.本发明方法流程图参见图1。离线训练阶段通过收集到的视频数据,通过图像增强模块、基于resnet的图像特征编码模块、posresnet解码器模块、dispresnet解码器模块以及掩膜生成模块得到最终的位姿估计。在训练过程中,通过光度一致性损失、边缘平滑损失和深度一致性损失监督网络对相机位姿的学习,获得具有尺度一致性的位姿。在在线阶段,导入训练好的网络模型,通过相机输入的图像帧实时地估计相机的位姿和相对于场景的位置。
24.具体实施步骤如下:
25.(1)图像增强模块:受到天气和场景的影响,光照条件的变化对相机得到的图像帧具有重要的影响,为了改善光照不足和过度曝光对图像纹理信息的负面影响,采用基于直方图均衡化的图像增强算法对原始输入图像进行边缘和纹理信息增强。
26.对于输入图像帧,基于人类视觉的局部性原理,首先将图像进行分块,以局部的图像块作为直方图均衡化的基本单位,避免直方图均衡化在过暗的区域放大噪声。
27.对于图像分块后的图像切片,由于图像中存在过暗的区域,这些区域在直方图上就会表征为在某一像素上的概率密度过大,经过变换映射函数后会产生更大的像素概率密度增幅导致图像出现噪声,针对噪声问题,根据对比度公式,选取合理的图像对比度阈值,对于高于阈值的像素分布均匀的分散至整个图像块像素分布中,由此来限制变换映射函数的。图像对比度根据如下公式计算:
[0028][0029]
其中,i
sc_max
表示图像像素最大值,i
sc_min
表示图像像素最小值。
[0030]
在对每个图像块完成直方图均衡化后,如果直接对图像块进行拼接会导致合成的图像块出现块效应,为了避免块效应,通过二次线性插值将图像块拼接为增强图像。对于图像中的像素点p(i,j),通过双线性二次差值得到目标像素点的像素值。
[0031]
p(x,y)=f(p
11
)w
11
+f(p
21
)w
21
+f(p
12
)w
12
+f(p
22
)w
22
[0032]
其中p
11
,p
12
,p
21
和p
22
分别表示p(i,j)附近的四个像素坐标。
[0033]
(2)基于resnet的编码器:考虑到网络为二分支网络,其中深度估计网络主要用于为位姿网络提供具有长时间序列一致性的尺度信息,对于深度估计网络,采用resnet50提取图像时空特征。对于位姿估计网络,采用resnet18作为解码器,为了使输入图像同时输入两张图像,修改resnet第一层输入通道为6通道输入。
[0034]
在确定resnet网络的结构后,根据网络结构确定确定各隐含层层数、各层神经元个数、学习率,设置各层预训练迭代次数、微调迭代次数等网络参数;设置输出层的激活函数为sigmoid函数,其他非线性激活层激活函数为elu。
[0035]
在训练阶段,两个网络通过同一个损失函数联合训练,损失函数由光度一致性损失、边缘平滑损失和深度一致性损失三部分得来。
[0036]
(3)解码器:对于深度预测网络,采用dispresnet作为解码器,通过基于3x3卷积核的转置卷积逐层上采样恢复图像的尺度信息。对于位姿估计网络,如图4所示,采用
poseresnet设计四层卷积层得到6自由度预测位姿。在特征解码阶段,采用1x1和3x3二维卷积核对图像特征解码并得到最终的六自由度位姿。
[0037]
(4)基于遮挡掩码的掩膜:考虑到场景中的动态目标和遮挡违反了静态场景假设。由于动态目标和遮挡的存在,预测图像深度信息与真实图像深度会在动态目标区域产生明显的深度不一致性,进而影响深度网络和位姿网络参数的正确学习。基于预测的单视图深度信息,通过视图合成原理将目标视图翻转到源视图中得到合成的目标深度图,视图合成原理可以通过下式表征:
[0038][0039]
其中υ
ij
表示目标图像ii(x)和翻转源图像之间的像素值差异,翻转源图像通过目标图像和源图像之间的位姿变换信息及深度信息获得,其中位姿变换信息通过下式得到:
[0040][0041]
其中k为相机内参,是目标图像到源图像的位姿变换矩阵,是目标图像的深度信息,由深度预测网络得到。基于目标图像深度图dj(xj)和源图像深度图di(xi),基于尺度一致性的掩膜可以通过下式计算得到:
[0042][0043]
其中thre根据经验设置为0.25,d
i->j
(x)表示两幅图像之间的深度信息差异,具体通过下式计算:
[0044][0045]
基于深度一致性的二进制掩膜在动态目标区域差异值大而静态区域差异近乎零,借助二进制掩膜用于在计算损失前剔除动态目标和遮挡的干扰。
[0046]
(5)损失函数:为了提高深度估计网络和位姿估计网络的预测精度,考虑图像的时空特征,损失函数由三部分构成,在训练阶段对二分支网络进行联合训练,整体损失函数由三部分组成:
[0047]
lc=αl
photo
+βl
smooth
+γl
depth
[0048]
第一部分是光度一致性损失,用于约束相邻图像帧之间的光度损失:
[0049][0050]
其中ii(x)和表示参考图像和翻转源图像的灰度值。
[0051]
第二部分是边缘平滑度损失,用于弥补场景在低纹理或单一平面区域的预测精度:
[0052]
[0053]
其中表示空间方向的一阶导数。
[0054]
第三部分是尺度一致性损失,借助图深度信息约束网络在长序列位姿估计中保持位姿的尺度一致性。
[0055][0056]
其中ssim(i
i-ij)表示两幅图像的结构相似性差异。
[0057]
(6)在线阶段,采集测试场景的视频数据,导入已训练完毕的模型,推理模型对测试场景的边缘和纹理特征编码,通过四层转置卷积解码层最终得到6自由度位姿。
[0058]
本发明方法充分利用深度残差网络的特征表征和融合机制,得到了一种高精度的定位方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1