一种基于多分类G-WLSTSVM模型的流体管道泄漏识别方法
本发明属于管道泄漏识别,具体涉及一种基于多分类g-wlstsvm模型的流体管道泄漏识别方法。
背景技术:
1、管道是石油、天然气等资源运输和配送使用最广泛的基础设施之一。然而,管道因老化、腐蚀、焊缝缺陷、环境因素和外力干扰等因素而损坏,使得管道泄漏事件时有发生,易造成财政消耗、环境污染和公共健康风险。同时,不同的泄漏工况形成的泄漏规模会造成不同程度的危害,这影响抢修措施的制定。因此,流体管道泄漏识别的研究具有重大实际意义。
2、不同管道泄漏工况识别的本质实际是通过分析泄漏信号而实现多种泄漏工况的分类。它的实现主要是通过对采集的管道泄漏信号提取特征量,构建数据集并由分类模型进行分类和识别。其中,分类模型的性能直接决定管道泄漏工况的识别性能。当前的研究重点是寻找分类精度高和计算效率较高的分类算法,最大可能地提高管道泄漏工况的识别精度。中国专利cn110659482a公开了一种基于gapso-twsvm的工业网络入侵检测方法,它采用结合遗传算法(genetic algorithm,ga)与粒子群算法(particle swarm optimization,pso)的gapso算法优化孪生支持向量机(twin support vector machines,twsvm)的各个参数,最终提高了工业网络入侵检测的算法性能。但是,由于twsvm在训练时需要求解两个二次规划问题,故其具有较高的计算复杂度。为了进一步提高分类器的性能,kumar等提出了twsvm的最小二乘版本,即最小二乘孪生支持向量机(least squares twin supportvector machin,lstsvm),在最小二乘意义下修改了twsvm的原始二次规划问题,并用等式约束代替twsvm的不等式约束进行求解(m.arun kumar and m.gopal,“least squarestwin support vector machines for pattern classification,”expert syst.appl.,vol.36,no.4,pp.7535–7543,may 2009.)。在训练过程中,lstsvm只需要求解两个线性方程,简化了计算复杂度,其训练速度远快于twsvm,并且具有与twsvm相似的分类精度。但是,lstsvm的求解结果中存在对称半正定矩阵求逆项,很多时候这个矩阵是不可逆的,这将导致病态矩阵求逆问题的出现。同时,lstsvm在进行训练时容易被训练样本中的离群样本影响,从而导致训练得到的模型的分类精度不佳。由于管道各工况数据采集过程中不可避免的环境噪声使得泄漏样本中存在离群样本,它们往往远离所属工况的整体数据分布,而lstsvm对正常泄漏样本和离群样本赋予相同的权重,导致具有同等权重的离群样本会影响泄漏工况的分类趋势,从而导致误分类出现。
3、综上所述,现有技术问题是:
4、1.最小二乘孪生支持向量机求解结果中存在对称半正定矩阵求逆项,很多时候这个矩阵是不可逆的,这将导致病态矩阵求逆问题的出现;
5、2.最小二乘孪生支持向量机在进行训练时容易被训练样本中的离群样本影响,从而导致训练得到的模型的分类精度不佳;
6、3.管道各工况数据采集过程中不可避免的环境噪声使得泄漏样本中存在离群样本,它们往往远离所属工况的整体数据分布,而lstsvm对正常泄漏样本和离群样本赋予相同的权重,导致具有同等权重的离群样本会影响泄漏工况的分类趋势,从而导致误分类出现。
技术实现思路
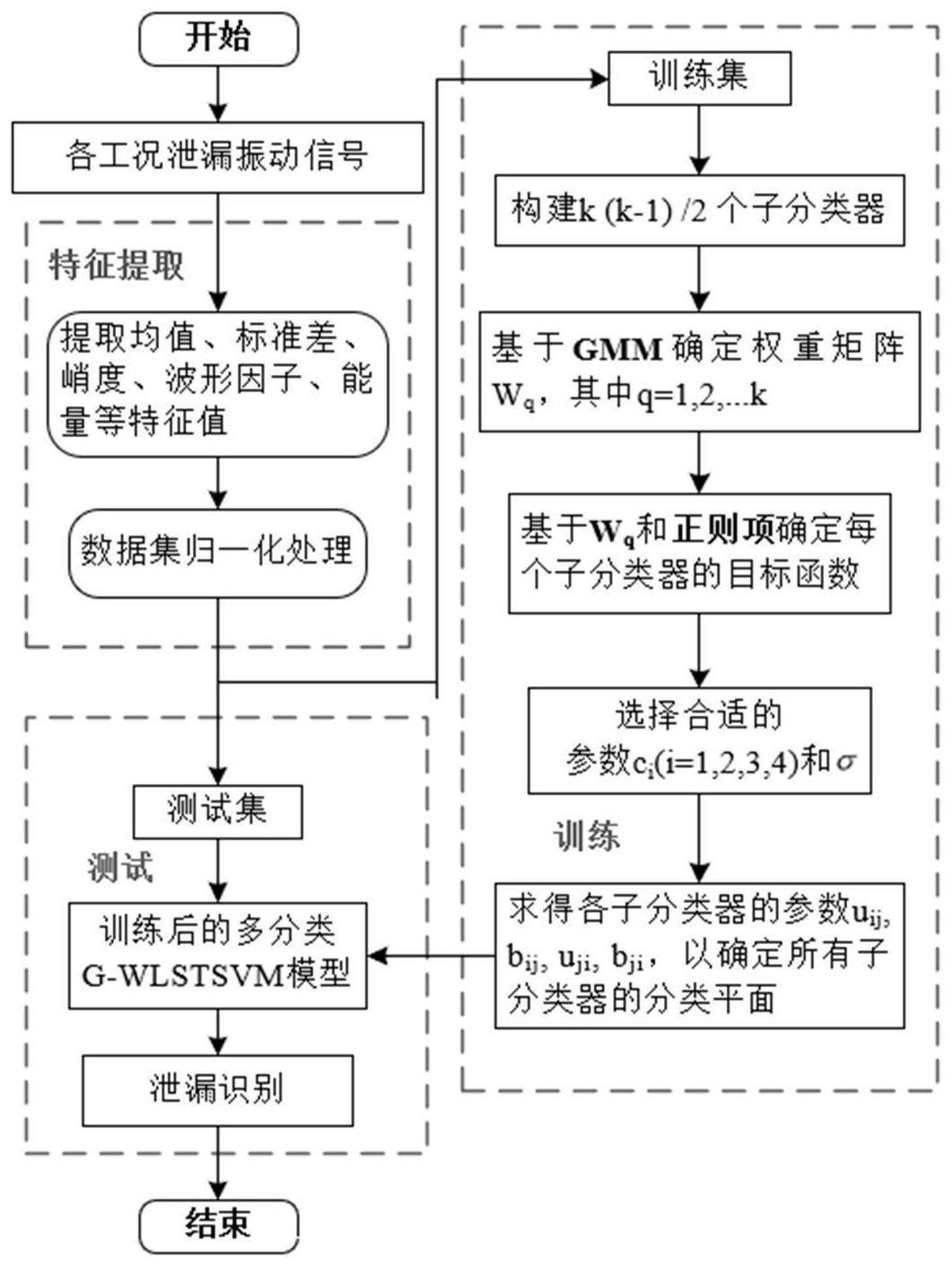
1、为解决上述技术问题,本发明提出一种基于多分类g-wlstsvm模型的流体管道泄漏识别方法,包括以下步骤:
2、s1:采集供水管道无泄漏、小泄漏、中度泄漏和严重泄漏四种工况下的管道振动信号;
3、s2:提取管道振动信号中的特征值,构建管道泄漏识别的数据集,并对数据集中的所有数据样本在区间[0,1]上做归一化处理;
4、s3:对归一化后的样本数据按照3:1的比例划分训练集和测试集;
5、s4:利用gmm模型确定训练集中各工况下的数据样本的权值,根据各工况下的数据样本的权值构建各个工况下的权重矩阵;
6、s5:利用正则项和权重矩阵改进非线性lstsvm模型,得到非线性g-wlstsvm模型,并根据“一对一”策略将非线性g-wlstsvm作为子分类器,构建用于管道工况识别的多分类g-wlstsvm模型;
7、s6:将训练集中的数据样本输入多分类g-wlstsvm模型,进行模型的训练;
8、s7:将测试集中的数据样本输入训练完成后的多分类g-wlstsvm模型,检测模型的识别准确率,得到最优的多分类g-wlstsvm模型;
9、s8:将待检测的数据输入最优的多分类g-wlstsvm模型,得到管道的泄漏情况。
10、优选的,利用gmm模型确定训练集中各工况下的数据样本的权值,表示为:
11、
12、其中,表示第i个样本数据x在第j个分模型下的权值,zj表示第j个高斯分模型的权重,∑j表示协方差矩阵的标准正态分布,xi表示第i个样本数据,μj表示均值,m表示样本数据总数,k表示gmm中分模型的个数,φ()表示高斯分布密度。
13、优选的,利用正则项和权重矩阵改进lstsvm模型的目标函数,得到非线性g-wlstsvm模型,表示为:
14、
15、受限制于w+[k(a,ct)u1+e1b1]=δ
16、w-{[k(b,ct)u1+e2b1]+e2}=ξ
17、
18、受限制于w-[k(b,ct)u2+e2b2]=δ*
19、w+{e1-[k(a,ct)u2+e1b2]}=η
20、其中,c表示正负类数据样本的组合矩阵,t表示转置操作,a表示正类的数据样本组成的矩阵,b表示负类的数据样本组成的矩阵,c1表示第一惩罚因子,c2表示第二惩罚因子,c3表示第三惩罚因子,c4表示第四惩罚因子,δ表示第一误差量,δ*表示第二误差量,ξ表示第三误差量,η表示第四误差量,w+表示和w-分别表示两类训练样本各自的权重矩阵,k()表示rbf核函数,e1表示第一全1向量,e2表示第二全1向量,u1、b1和u2、b2分别表示非线性g-wlstsvm两个核生成曲面的法向量和截距。
21、优选的,并根据“一对一”策略将非线性g-wlstsvm作为子分类器,构建用于管道工况识别的多分类g-wlstsvm模型,具体包括:
22、根据管道的泄漏工况,将任意两类工况下的数据样本匹配一个非线性g-wlstsvm分类器,k(k-1)/2个非线性g-wlstsvm子分类器组成用于管道工况识别的多分类g-wlstsvm模型,其中k表示管道的泄漏工况。
23、优选的,将训练集中的数据样本输入多分类g-wlstsvm模型,进行模型的训练,具体包括:
24、确定模型的初始参数,在区间[2-8,28]中选取该多分类模型的惩罚因子c1,c2,c3,c4和核参数σ,将训练集中的训练样本输入多分类g-wlstsvm模型,根据网格搜索方式确定c1,c2,c3,c4和σ最优组合下的各个子分类器的参数uij、bij、uji、bji,得到所有训练好的子分类器,固定最优参数,得到用于四种泄漏工况识别的最优多分类g-wlstsvm模型。
25、优选的,将测试集中的数据样本输入训练完成后的多分类g-wlstsvm模型,检测模型的识别准确率,具体包括:
26、利用投票法确定每一个测试样本的类别,每一个测试样本依次被每一个子分类器进行判别,若i、j两类间的决策函数将测试样本判断为第i类,则测试样本属于第i类的票数加1,反之第j类的票数加1,测试样本遍历完所有子分类器后,该样本的标签为被判定为票数最高的类别,最后将得到的所有测试样本的标签与实际标签进行对比,确定模型的识别准确率。
27、本发明的有益效果:
28、本发明通过给目标函数增加一个正则项以避免lstsvm求解目标函数时病态的矩阵求逆问题的出现,并且使得模型在经验风险最小化的同时实现结构风险最小化,提高了模型的泛化性能;同时,基于gmm为目标函数中的误差量增加权重矩阵,实现给正常泄漏样本分配较大权重,给离群样本分配较小权重,解决了由于lstsvm对正常泄漏样本和离群样本赋予相同的权重导致的离群样本对分类趋势的影响,并利用“一对一”策略将g-wlstsvm扩展为多分类g-wlstsvm,实现了在保证较高计算效率的前提下,减少了离群样本对分类模型性能的影响,提高了分类模型的泛化能力和识别精度。
- 还没有人留言评论。精彩留言会获得点赞!