数据视图生成方法、装置、计算机设备及可读存储介质与流程
1.本发明涉及数据处理技术领域,尤其涉及一种数据视图生成方法、装置、计算机设备及可读存储介质。
背景技术:
2.目前的大数据指标平台,由于创建的指标众多,指标形式多种多样,同时由于数据分析平台和元数据平台割裂,造成了数据孤岛,数据协同分析难,受限于数据分析平台的每秒查询率,当用户在使用大数据指标平台进行数据查询的时候,若指标查询粒度过低,就会导致数据查询链过长和数据查询效率较低的问题,用户体验感较差。
3.针对上述相关技术中由于指标形式多种多样,同时数据分析平台和元数据平台割裂,造成了指标查询粒度过低时导致的数据查询链过长和数据查询效率较低的问题,目前尚未提出有效的解决方案。
技术实现要素:
4.有鉴于此,本发明的目的是为了克服现有技术中的不足,提供一种数据视图生成方法、装置、计算机设备及可读存储介质,旨在解决当前用户在使用大数据指标平台进行数据查询的时候,若指标查询粒度过低导致的数据查询链过长和数据查询效率较低的问题。
5.本发明提供如下技术方案:
6.第一方面,本公开实施例中提供了一种数据视图生成方法,所述方法包括:
7.获取数据查询请求对应的指标;
8.根据所述指标生成至少一个sql语句;
9.根据所述sql语句生成至少一个sqlnode组;
10.将符合预设合并条件的sqlnode组合并,生成单一sqlnode树;
11.根据所述单一sqlnode树生成对应的sql数据视图。
12.进一步地,所述将符合预设合并条件的sqlnode组合并,生成单一sqlnode树之前,还包括:
13.获取预设的指标特性、属性关系、雪花模型关系、查询条件和用户元数据;
14.根据所述指标特性、所述属性关系、所述雪花模型关系、所述查询条件和所述用户元数据生成所述预设合并条件。
15.进一步地,所述根据所述单一sqlnode树生成对应的sql数据视图,包括:
16.利用数据分析平台,将所述单一sqlnode树进行方言转换,生成对应的sql数据视图。
17.进一步地,所述方法还包括:
18.对所述指标进行血缘分析,生成sqlnode树;
19.将所述sqlnode树进行度量合并、条件交叉,生成对应的sql查询视图。
20.进一步地,所述指标包括事实表、维表和度量,所述对所述指标进行血缘分析,生
成sqlnode树,包括:
21.根据所述指标的查询条件生成用户个性化配置;
22.获取预设的控制权限;
23.基于预设构建模型分析各个所述指标的事实表、维表、度量、控制权限和用户个性化配置,生成对应的sqlnode树。
24.进一步地,所述预设构建模型为雪花模型。
25.第二方面,本公开实施例中提供了一种数据视图生成装置,所述装置包括:
26.第一获取模块,用于获取数据查询请求对应的指标;
27.第一生成模块,用于根据所述指标生成至少一个sql语句;
28.第二生成模块,用于根据所述sql语句生成至少一个sqlnode组;
29.第三生成模块,用于将符合预设合并条件的sqlnode组合并,生成单一sqlnode树;
30.第四生成模块,用于根据所述单一sqlnode树生成对应的sql数据视图。
31.进一步地,所述装置还包括:
32.第二获取模块,用于获取预设的指标特性、属性关系、雪花模型关系、查询条件和用户元数据;
33.第五生成模块,用于根据所述指标特性、所述属性关系、所述雪花模型关系、所述查询条件和所述用户元数据生成所述预设合并条件。
34.第三方面,本公开实施例中提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现第一方面中所述数据视图生成方法的步骤。
35.第四方面,本公开实施例中提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现第一方面中所述数据视图生成方法的步骤。
36.本技术的实施例具有如下优点:
37.本技术实施例提供的数据视图生成方法,通过获取数据查询请求对应的指标;根据所述指标生成至少一个sql语句;根据所述sql语句生成至少一个sqlnode组;将符合预设合并条件的sqlnode组合并,生成单一sqlnode树;根据所述单一sqlnode树生成对应的sql数据视图。通过生成数据视图,简化了数据查询的关联关系,减少了查询量,打破了数据孤岛,提升了数据分析和加载的效率,解决了因指标查询粒度过低导致的数据查询链过长和数据查询效率较低的问题。在此基础上能快速展示用户所需要浏览的视图以及指标数据,从而使用户能够更快的做出决策。
38.为使本发明的上述目的、特征和优点能更明显和易懂,下文特举较佳实施例,并配合所附附图,做详细说明如下。
附图说明
39.为了更清楚地说明本发明的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对本发明保护范围的限定。在各个附图中,类似的构成部分采用类似的编号。
40.图1示出了本技术实施例提供的一种数据视图生成方法的流程图;
41.图2示出了本技术实施例提供的一种数据视图生成装置的结构示意图;
42.图3示出了本技术实施例提供的计算机设备的硬件架构示意图。
具体实施方式
43.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
44.需要说明的是,当元件被称为“固定于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。相反,当元件被称作“直接在”另一元件“上”时,不存在中间元件。本文所使用的术语“垂直的”、“水平的”、“左”、“右”以及类似的表述只是为了说明的目的。
45.在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
46.此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
47.除非另有定义,本文所使用的所有的技术和科学术语与属于本技术的技术领域的技术人员通常理解的含义相同。本文中在模板的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
48.实施例1
49.如图1所示,为本技术实施例中的一种数据视图生成方法的流程图,本技术实施例提供的数据视图生成方法包括以下步骤:
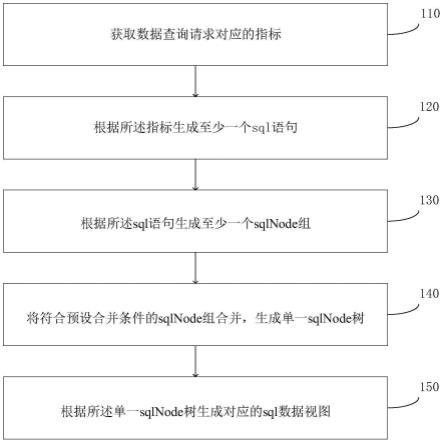
50.步骤110,获取数据查询请求对应的指标。
51.具体地,用户在利用计算机设备进行数据查询的时候,计算机设备会生成对应于数据查询请求的指标。通过对用户查询数据的理解分析,梳理出不同领域需要关注的内容,如梳理出各查询数据对应的业务线关注的内容。如对于金融业务来说,关注的内容包括但不限于投资金额、储蓄金额,可以将这些关注的内容作为指标,对于一个指标来说,可以通过指标名称、指标类型、指标数据类型、指标单位、指标负责人、指标安全信息等来对指标进行描述。
52.可以理解的是,所述指标包括原子指标、派生指标、衍生指标,其中,原子指标是粒度级别最小的指标,不可再进行拆分,例如订单总额;派生指标是由原子指标、时间周期、修饰词构成的,例如最近一周某分行某理财产品的订单总额;衍生指标是在至少一个派生指标的基础上,通过各种逻辑运算符合而成的,例如利润。本技术实施例中以原子指标为例进
行数据处理。
53.通过获取数据查询请求对应的指标,便于后续根据所述指标生成对应的sql语句,进而生成sql数据视图,简化了数据查询的关联关系,减少了查询量,提升了数据分析和加载的效率。
54.步骤120,根据所述指标生成至少一个sql语句。
55.进一步地,每个指标都对应生成至少一个sql语句,其中,sql(structured query language,结构化查询语言)是一种数据库查询和程序设计语言,sql语句可用于存取数据以及查询、更新和管理关系数据库系统。所述sql语句为符合标准sql语法的标准sql语句,例如其不包括注释、空格、结束符和换行符等特殊符号的sql语句。
56.步骤130,根据所述sql语句生成至少一个sqlnode组。
57.可以理解的是,每一个sql语句都会对应一个sqlnode,其中,sqlnode是指用于存储sql语句的node节点,多个sql语句对应的sqlnode可组成一个sqlnode组,多个查询指标则会产生多个sqlnode组。
58.通过根据所述sql语句生成至少一个sqlnode组,进而生成sql数据视图,简化了数据查询的关联关系,减少了查询量,提升了数据分析和加载的效率。
59.步骤140,将符合预设合并条件的sqlnode组合并,生成单一sqlnode树。
60.具体地,根据预设合并条件合并sqlnode组,进而生成单一sqlnode树,所述单一sqlnode树以树状的形式进行展示,单一sqlnode树上的每个节点都表示指标对应的sql语句,基于单一sqlnode树可以建立清晰的sql语句描述,非常有利于后续阶段的修改、变换。
61.通过合并所述sqlnode组,生成单一sqlnode树,进而生成sql数据视图,简化了数据查询的关联关系,减少了查询量,打破了数据孤岛,提升了数据分析和加载的效率。
62.步骤150,根据所述单一sqlnode树生成对应的sql数据视图。
63.进一步地,利用数据分析平台,将合并后的单一sqlnode树进行方言转换,生成对应的sql数据视图。在具体实施例中,数据分析平台采用olap(online analytical processing,联机分析处理)系统,可以理解的是,具体采用的数据分析平台可以根据实际需求设定,本技术实施例对此不做限定。
64.可以理解的是,不同类型数据库的sql语言之间,形式并不相同,进行方言转换可以将单一sqlnode树上的所有sql语句转化为特定数据库的方言的形式,实现sql语句形式的统一,从而生成形式统一的sql数据视图,使得用户在查询各个粒度级别的指标时,能够以完整的视图模式进行查询,进而简化了数据查询的关联关系,减少了查询量,打破了数据孤岛,提升了数据分析和加载的效率,解决了数据查询链过长的问题。
65.在一种可选地实施方式中,在所述将符合预设合并条件的sqlnode组合并,生成单一sqlnode树之前,还包括:
66.步骤141,获取预设的指标特性、属性关系、雪花模型关系、查询条件和用户元数据。
67.具体地,指标特性指的是指标的业务线、指标的派生条件、指标的衍生条件、指标的类型和指标的计算类型;属性关系指的是与指标关联的各个维度之间的类型关系;雪花模型关系指的是与指标关联的各个维度之间通过雪花模型建立的关键关系;查询条件指的是用户进行数据查询时的特定要求;用户元数据指的是从信息资源中抽取出来的用于说明
用户特征、信息的结构化数据。
68.步骤142,根据所述指标特性、所述属性关系、所述雪花模型关系、所述查询条件和所述用户元数据生成所述预设合并条件。
69.进一步地,根据获取到的指标特性、属性关系、雪花模型关系、查询条件和用户元数据,生成预设合并条件,进而基于符合预设合并条件,将符合预设合并条件的sqlnode组合并,生成单一sqlnode树。
70.在一种可选地实施方式中,上述方法还可以包括:
71.步骤160,对所述指标进行血缘分析,生成sqlnode树。
72.具体地,所述指标包括事实表、维表和度量,对所述指标进行血缘分析,即根据所述指标的查询条件生成用户个性化配置;获取预设的控制权限;基于预设构建模型分析各个所述指标的事实表、维表、度量、控制权限和用户个性化配置,生成对应的sqlnode树。其中,事实表指的是数据库中包含大量能够被统计和记录的数据的事实数据表;维表指的是对数据进行分析时所用的量,维度表中包含事实表中事实统计和记录的数据的特性,如维度表包含与事件有关的文本环境,用于描述与“谁、什么、哪里、何时、如何、为什么”有关的事件;度量指的是在事实表里面存放的数值型的、连续的字段;控制权限指的是指标对数据的不同的操作权限。
73.可以理解的是,本技术实施例中采用的预设构建模型为雪花模型,雪花模型可以最大限度地减少数据存储量以及联合较小的维表来改善查询性能,去除了数据冗余,需要指出的是,具体采用的构建模型可以根据实际需求设定,本技术实施例对此不做限定。
74.步骤170,将所述sqlnode树进行度量合并、条件交叉,生成对应的sql查询视图。
75.进一步地,所述sqlnode树包括多个节点,对sqlnode树的各个节点之间进行度量合并、条件交叉,生成对应的sql查询视图。根据所述sql查询视图,可以简化数据查询的关联关系,减少查询量,显著提升数据加载的速度。
76.本技术的实施例具有如下优点:
77.本技术实施例提供的数据视图生成方法,通过获取数据查询请求对应的指标;根据所述指标生成至少一个sql语句;根据所述sql语句生成至少一个sqlnode组;将符合预设合并条件的sqlnode组合并,生成单一sqlnode树;根据所述单一sqlnode树生成对应的sql数据视图。通过生成数据视图,简化了数据查询的关联关系,减少了查询量,打破了数据孤岛,提升了数据分析和加载的效率,解决了因指标查询粒度过低导致的数据查询链过长和数据查询效率较低的问题。在此基础上能快速展示用户所需要浏览的视图以及指标数据,从而使用户能够更快的做出决策。
78.实施例2
79.如图2所示,为本技术实施例中的一种数据视图生成装置200的结构示意图,其装置包括:
80.第一获取模块210,用于获取数据查询请求对应的指标;
81.第一生成模块220,用于根据所述指标生成至少一个sql语句;
82.第二生成模块230,用于根据所述sql语句生成至少一个sqlnode组;
83.第三生成模块240,用于将符合预设合并条件的sqlnode组合并,生成单一sqlnode树;
84.第四生成模块250,用于根据所述单一sqlnode树生成对应的sql数据视图。
85.可选地,上述数据视图生成装置还可以包括:
86.第二获取模块,用于获取预设的指标特性、属性关系、雪花模型关系、查询条件和用户元数据;
87.第五生成模块,用于根据所述指标特性、所述属性关系、所述雪花模型关系、所述查询条件和所述用户元数据生成所述预设合并条件。
88.可选地,上述数据视图生成装置还可以包括:
89.第四生成子模块,用于利用数据分析平台,将所述单一sqlnode树进行方言转换,生成对应的sql数据视图。
90.可选地,上述数据视图生成装置还可以包括:
91.第六生成模块,用于对所述指标进行血缘分析,生成sqlnode树;
92.第七生成模块,用于将所述sqlnode树进行度量合并、条件交叉,生成对应的sql查询视图。
93.可选地,上述数据视图生成装置还可以包括:
94.第八生成模块,用于根据所述指标的查询条件生成用户个性化配置;
95.第三获取模块,用于获取预设的控制权限;
96.第九生成模块,用于基于预设构建模型分析各个所述指标的事实表、维表、度量、控制权限和用户个性化配置,生成对应的sqlnode树。
97.本技术的实施例具有如下优点:
98.本技术实施例提供的数据视图生成装置,通过生成数据视图,简化了数据查询的关联关系,减少了查询量,打破了数据孤岛,提升了数据分析和加载的效率,解决了因指标查询粒度过低导致的数据查询链过长和数据查询效率较低的问题。在此基础上能快速展示用户所需要浏览的视图以及指标数据,从而使用户能够更快的做出决策。
99.实施例3
100.图3示出了本技术提供的计算机设备的硬件架构示意图,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现实施例1所述的数据视图生成方法的步骤。
101.本实施例中,计算机设备300是一种能够按照事先设定或者存储的指令,自动进行数值计算和/或信息处理的设备。例如,可以是机架式服务器、刀片式服务器、塔式服务器或机柜式服务器(包括独立的服务器,或者多个服务器所组成的服务器集群)等。如图3示,计算机设备300至少包括但不限于:可通过系统总线相互通信链接存储器310、处理器320、网络接口330。其中:
102.存储器310至少包括一种类型的计算机可读存储介质,可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,存储器310可以是计算机设备300的内部存储模块,例如该计算机设备300的硬盘或内存。在另一些实施例中,存储器310也可以是计算机设备300的外部存储设备,例如该计算机设备300上配备的插接式硬盘,智能存储卡(smartmedia card,简称为smc),安全数字(secure digital,简称为sd)卡,闪存卡
(flash card)等。当然,存储器310还可以既包括计算机设备300的内部存储模块也包括其外部存储设备。本实施例中,存储器310通常用于存储安装于计算机设备300的操作系统和各类应用软件,例如视频播放方法的程序代码等。此外,存储器310还可以用于暂时地存储已经输出或者将要输出的各类数据。
103.处理器320在一些实施例中可以是中央处理器(central processing unit,简称为cpu)、控制器、微控制器、微处理器、或其他数据处理芯片。该处理器320通常用于控制计算机设备300的总体操作,例如执行与计算机设备300进行数据交互或者通信相关的控制和处理等。本实施例中,处理器320用于运行存储器310中存储的程序代码或者处理数据。
104.网络接口330可包括无线网络接口或有线网络接口,该网络接口330通常用于在计算机设备300与其他计算机设备之间建立通信链接。例如,网络接口330用于通过网络将计算机设备300与外部终端相连,在计算机设备300与外部终端之间的建立数据传输通道和通信链接等。网络可以是企业内部网(intranet)、互联网(internet)、全球移动通讯系统(globalsystem of mobile communication,简称为gsm)、宽带码分多址(wideband code divisionmultiple access,简称为wcdma)、4g网络、5g网络、蓝牙(bluetooth)、wi-fi等无线或有线网络。
105.需要指出的是,图3仅示出了具有部件310-330的计算机设备,但是应理解的是,并不要求实施所有示出的部件,可以替代的实施更多或者更少的部件。
106.在本实施例中,存储于存储器310中的数据视图生成方法还可以被分割为一个或者多个程序模块,并由至少一个处理器(本实施例为处理器320)所执行,以完成本发明。
107.实施例4
108.本实施例还提供一种计算机可读存储介质,计算机可读存储介质其上存储有计算机程序,计算机程序被处理器执行时实现实施例中数据视图生成方法的步骤。
109.本实施例中,计算机可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,计算机可读存储介质可以是计算机设备的内部存储单元,例如该计算机设备的硬盘或内存。在另一些实施例中,计算机可读存储介质也可以是计算机设备的外部存储设备,例如该计算机设备上配备的插接式硬盘,智能存储卡(smart media card,简称为smc),安全数字(secure digital,简称为sd)卡,闪存卡(flash card)等。当然,计算机可读存储介质还可以既包括计算机设备的内部存储单元也包括其外部存储设备。本实施例中,计算机可读存储介质通常用于存储安装于计算机设备的操作系统和各类应用软件。此外,计算机可读存储介质还可以用于暂时地存储已经输出或者将要输出的各类数据。
110.在这里示出和描述的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制,因此,示例性实施例的其他示例可以具有不同的值。
111.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
112.以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1