一种数据处理方法、装置和电子设备与流程
1.本公开涉及人机交互技术领域,尤其涉及一种数据处理方法、装置和电子设备。
背景技术:
2.目前在人机交互技术领域,用户可以通过语音的方式向电子设备发出控制、问答、闲聊等请求,电子设备根据接收到的语音信息,确定对应该语音信息的答复信息,之后电子设备通过语音的方式播放该答复信息。随着科技的发展,单纯地通过语音的方式播放答复信息已不能满足用户的需求,用户更多地寻求能够动态地展示答复信息的方式,如通过数据虚拟人来播报答复信息。
3.因此,如何通过数据虚拟人来播报答复信息成为了一个亟待解决的问题。
技术实现要素:
4.为了解决上述技术问题,本公开提供了一种数据处理方法、装置和电子设备。
5.本公开的技术方案如下:
6.第一方面,本公开提供一种数据处理方法,包括:接收电子设备发送的用于触发人机交互的语音信息;对语音信息进行识别,确定语音信息的回复信息;将回复信息输入至文本驱动模型,确定目标关键点集合;其中,目标关键点集合中至少包括用于指示嘴巴和眼睛的关键点;向电子设备发送携带回复信息和目标关键点集合的目标信息,以便电子设备根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和目标关键点集合生成虚拟数字人的渲染图像,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
7.第二方面,本公开提供一种数据处理方法,包括:响应于对目标功能的选择操作,向服务器发送语音信息;接收服务器发送的回复信息;对回复信息进行合成,确定回复信息对应的语音信息;将语音信息输入至语音驱动模型,确定指定关键点集合;其中,指定关键点集合中至少包括用于指示嘴巴和眼睛的关键点;根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和目标关键点集合生成虚拟数字人的渲染图像;其中,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
8.第三方面,本公开提供一种数据处理装置,包括:接收单元,用于接收电子设备发送的用于触发人机交互的语音信息;处理单元,用于对接收单元接收的语音信息进行识别,确定语音信息的回复信息;处理单元,还用于将回复信息输入至文本驱动模型,确定目标关键点集合;其中,目标关键点集合中至少包括用于指示嘴巴和眼睛的关键点;处理单元,还用于控制发送单元向电子设备发送携带回复信息和目标关键点集合的目标信息,以便电子设备根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和目标关键点集合生成虚拟数字人的渲染图像,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
9.第四方面,本公开提供一种数据处理装置,包括:处理单元,用于响应于对目标功能的选择操作,控制发送单元向服务器发送语音信息;接收单元,用于接收服务器发送的回复信息;处理单元,用于对接收单元接收的回复信息进行合成,确定回复信息对应的语音信
息;处理单元,还用于将语音信息输入至语音驱动模型,确定指定关键点集合;其中,指定关键点集合中至少包括用于指示嘴巴和眼睛的关键点;处理单元,还用于根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和指定关键点集合生成虚拟数字人的渲染图像;其中,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
10.第五方面,本公开提供一种电子设备,包括:存储器和处理器,存储器用于存储计算机程序;处理器用于在执行计算机程序时,使得电子设备实现如上述第一方面提供的任一项数据处理方法。
11.第六方面,本公开提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,当计算机程序被计算设备执行时,使得计算设备实现如上述第一方面提供的任一项数据处理方法。
12.第七方面,本发明提供一种计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行如第一方面提供的任一项的数据处理方法。
13.第八方面,本公开提供一种电子设备,包括:存储器和处理器,存储器用于存储计算机程序;处理器用于在执行计算机程序时,使得电子设备实现如上述第二方面提供的任一项数据处理方法。
14.第九方面,本公开提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,当计算机程序被计算设备执行时,使得计算设备实现如上述第二方面提供的任一项数据处理方法。
15.第十方面,本发明提供一种计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行如第二方面提供的任一项的数据处理方法。
16.需要说明的是,上述计算机指令可以全部或者部分存储在第一计算机可读存储介质上。其中,第一计算机可读存储介质可以与数据处理装置的处理器封装在一起的,也可以与数据处理装置的处理器单独封装,本公开对此不作限定。
17.本公开中第三方面、第五方面、第六方面以及第七方面的描述,可以参考第一方面的详细描述;并且,第三方面、第五方面、第六方面以及第七方面的描述的有益效果,可以参考第一方面的有益效果分析,此处不再赘述。
18.本公开中第四方面、第八方面、第九方面以及第十方面的描述,可以参考第一方面的详细描述;并且,第四方面、第八方面、第九方面以及第十方面的描述的有益效果,可以参考第二方面的有益效果分析,此处不再赘述。
19.在本公开中,上述数据处理装置的名字对设备或功能模块本身不构成限定,在实际实现中,这些设备或功能模块可以以其他名称出现。只要各个设备或功能模块的功能和本公开类似,属于本公开权利要求及其等同技术的范围之内。
20.本公开的这些方面或其他方面在以下的描述中会更加简明易懂。
21.本公开提供的技术方案与现有技术相比具有如下优点:
22.本公开实施例提供的数据处理方法,当目标功能为语音交互功能时,用户在需要使用语音交互功能时,可以在电子设备对该语音交互功能进行选择操作并输入相应的语音信息,此时电子设备在接收到语音信息后,将该语音信息发送至服务器。服务器在对该语音信息进行识别后,确定该语音信息的回复信息。之后,通过将回复信息输入至文本驱动模型中,从而可以得到对应该回复信息的目标关键点集合,如:用于指示嘴巴的关键点。之后,向
电子设备发送携带回复信息、目标关键点集合以及虚拟数字人的脸部对应的预设关键点集合的目标信息,以便电子设备根据回复信息、目标关键点集合和预设关键点集合生成虚拟数字人的渲染图像。这样,电子设备就可以动态地来播放用户输入的语音信息对应的答复信息,从而解决了如何通过数据虚拟人来播报答复信息的问题。
附图说明
23.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
24.为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
25.图1为本技术实施例提供的数据处理方法的流程示意图之一;
26.图2为本技术实施例提供的数据处理方法中显示设备的结构示意图之一;
27.图3为本技术实施例提供的数据处理方法中显示设备的结构示意图之二;
28.图4为本技术实施例提供的数据处理方法的流程示意图之一;
29.图5为本技术实施例提供的数据处理方法的流程示意图之二;
30.图6为本技术实施例提供的数据处理方法的流程示意图之三;
31.图7为本技术实施例提供的数据处理方法的流程示意图之四;
32.图8为本技术实施例提供的数据处理方法的流程示意图之五;
33.图9为本技术实施例提供的数据处理方法的流程示意图之六;
34.图10为本技术实施例提供的数据处理方法的流程示意图之七;
35.图11为本技术实施例提供的服务器的结构示意图;
36.图12为本技术实施例提供的一种芯片系统的示意图之一;
37.图13为本技术实施例提供的显示设备的结构示意图;
38.图14为本技术实施例提供的一种芯片系统的示意图之二。
具体实施方式
39.为了能够更清楚地理解本公开的上述目的、特征和优点,下面将对本公开的方案进行进一步描述。需要说明的是,在不冲突的情况下,本公开的实施例及实施例中的特征可以相互组合。
40.在下面的描述中阐述了很多具体细节以便于充分理解本公开,但本公开还可以采用其他不同于在此描述的方式来实施;显然,说明书中的实施例只是本公开的一部分实施例,而不是全部的实施例。
41.需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除
在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
42.本公开实施例中的moviepy是一个用于视频编辑的python模块,它可被用于一些基本操作(如剪切、拼接、插入标题)、视频合成(即非线性编辑)、视频处理和创建高级特效。
43.本公开实施例中的audiotrack是安卓android中播放声音的一种方案,可以用于播放脉冲编码调制(pulse code modulation,pcm)数据流。
44.本公开实施例中的pyscenedetect是一款强大的视频场景检测库,能够将给定的视频所有的场景检测出来并保存为单独的视频文件。
45.本公开实施例中的videofileclip类是videoclip的直接子类,是从一个视频文件创建一个剪辑类,除了从父类继承的特性和方法外,videofileclip实现了自己的构造方法和close方法。
46.本公开实施例中的dlib工具,是指dlib库。
47.本公开实施例中的transformer结构是一种新的神经网络结构,其仅基于注意力机制attention,抛弃了传统的循环或卷积神经网络结构。其中,attention是神经网络中的一种机制:模型可以通过选择性地关注给定的数据集来学习做出预测。attention的个数是通过学习权重来量化的,输出则通常是一个加权平均值。
48.本公开实施例中的float是指浮点型数据类型,float数据类型用于存储单精度浮点数或双精度浮点数。
49.本公开实施例中的deepspeech是处理speech-to-text的基于深度学习框架的引擎。
50.本公开实施例中的reference损失函数是用来估量模型的预测值f(x)与真实值y的不一致程度。
51.本公开实施例中的reshape函数是matlab中将指定的矩阵变换成特定维数矩阵一种函数,且矩阵中元素个数不变,函数可以重新调整矩阵的行数、列数、维数。
52.本公开实施例中的opengl es(opengl for embedded systems)是opengl三维图形应用程序编程接口(application programming interface,api)的子集,针对手机、掌上电脑(personal digital assistant,pda)和游戏主机等嵌入式设备而设计。
53.本公开实施例中的mediapipe是一个用于构建机器学习管道的框架,用于处理视频、音频等时间序列数据。
54.本公开实施例中的reshape是脚本语言中的一个函数,用于变换维度。
55.图1为根据本技术一个或多个实施例的显示设备与控制装置之间操作场景的示意图,如图1所示,用户可通过移动终端300和控制装置100操作显示设备200。控制装置100可以是遥控器,遥控器和显示设备的通信包括红外协议通信、蓝牙协议通信,无线或其他有线方式来控制显示设备200。用户可以通过遥控器上按键,语音输入、控制面板输入等输入用户指令,来控制显示设备200。在一些实施例中,也可以使用移动终端、平板电脑、计算机、笔记本电脑、和其他智能设备以控制显示设备200。
56.在一些实施例中,移动终端300可与显示设备200安装软件应用,通过网络通信协议实现连接通信,实现一对一控制操作的和数据通信的目的。也可以将移动终端300上显示音视频内容传输到显示设备200上,实现同步显示功能显示设备200还与显示设备200通过多种通信方式进行数据通信。可允许显示设备200通过局域网(lan)、无线局域网(wlan)和
其他网络进行通信连接。显示设备200可以向显示设备200提供各种内容和互动。显示设备200,可以液晶显示器、oled显示器、投影显示设备。显示设备200除了提供广播接收电视功能之外,还可以附加提供计算机支持功能的智能网络电视功能。
57.在一些实施例中,本技术实施例提供电子设备可以为上述显示设备200。其中,用户需要使用语音交互功能时,可以通过按压控制装置100上的语音键,从而控制显示设备200启动目标功能(如语音交互功能),之后在按压语音控制按键的期间输入语音信息(如:今天天气怎么样)。或者,用户需要使用语音交互功能时,可以通过与该显示设备200建立通信连接的电子设备(如手机等),选择目标功能,之后输入语音信息。显示设备200响应于对目标功能(如语音交互功能)的选择操作,向服务器400发送用于触发人机交互的语音信息;服务器400在接收到显示设备200发送的语音信息后,采用自动语音识别技术(automatic speech recognition,asr)对语音信息进行识别,得到该语音信息对应的回复信息。之后,服务器400对该回复信息进行转换,得到该回复信息包含的至少一个词向量。之后,服务器400根据该词向量进行意图理解,得到意图识别结果。服务器400根据该意图识别结果,确定回复内容(如:今天天气晴朗,最低温度19
°
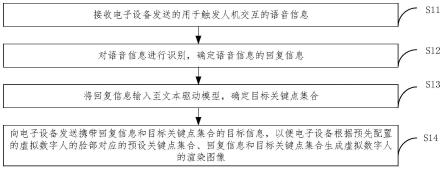
,最高温度28
°
)。之后,服务器400向显示设备200发送携带该回复内容的回复信息。显示设备200在接收到服务器400发送的回复信息后,对回复信息进行合成(如采用从文本到语音(text to speech,tts)对回复信息进行合成),确定回复信息对应的语音信息;将语音信息输入至语音驱动模型,确定指定关键点集合;根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和目标关键点集合生成虚拟数字人的渲染图像。从而,显示设备200可以通过虚拟数字人动态地回复用户:今天天气晴朗,最低温度19
°
,最高温度28
°
,提升用户的体验。
58.图2示出了根据示例性实施例中显示设备200的硬件配置框图。如图2所示显示设备200包括调谐解调器210、通信器220、检测器230、外部装置接口240、控制器250、显示器260、音频输出接口270、存储器、供电电源、用户接口280中的至少一种。控制器包括中央处理器,视频处理器,音频处理器,图形处理器,ram,rom,用于输入/输出的第一接口至第n接口。显示器260可为具有触控功能的显示器,如触控显示器。调谐解调器210通过有线或无线接收方式接收广播电视信号,以及从多个无线或有线广播电视信号中解调出音视频信号,如以及epg数据信号。检测器230用于采集外部环境或与外部交互的信号。控制器250和调谐解调器210可以位于不同的分体设备中,即调谐解调器210也可在控制器250所在的主体设备的外置设备中,如外置机顶盒等。
59.在一些实施例中,控制器250,通过存储在存储器上中各种软件控制程序,来控制显示设备的工作和响应用户的操作。控制器250控制显示设备200的整体操作。
60.在一些示例中,以申请一个或多个实施例的显示设备200为电视机1,并且电视机1的操作系统为android系统为例,如图3所示,电视机1从逻辑上可以分为应用程序(applications)层(简称“应用层”)21,应用程序框架(application framework)层(简称“框架层”)22,安卓运行时(android runtime)和系统库层(简称“系统运行库层”)23,以及内核层24。
61.其中,应用层21包括一个或多个应用。应用可以为系统应用,也可以为第三方应用。如,应用层21包括第一应用,第一应用可以提供语音交互功能。框架层22为应用层21的应用程序提供应用编程接口(application programming interface,api)和编程框架。系
统运行库层23为上层即框架层22提供支撑,当框架层22被使用时,安卓操作系统会运行系统运行库层23中包含的c/c++库以实现框架层22要实现的功能。内核层24作为硬件层和应用层21之间的软件中间件,用于管理和控制硬件与软件资源。
62.在一些示例中,内核层24包括第一驱动和第二驱动,第一驱动用于将检测器230采集的用户操作发送至第一应用,第二驱动用于控制显示器260显示显示单元213发送的显示信息。
63.电视机1中的第一应用启动。之后,第一驱动用于将检测器230采集的用户操作发送至第一应用进行识别。之后,第一应用的处理单元212响应于接收单元210接收的目标操作(如:对语音交互功能进行了选择操作),控制发送单元211向服务器400发送用于触发人机交互的语音信息(如:今天天气怎么样);服务器400的接收单元410在接收到显示设备200发送的语音信息后,处理单元411采用自动语音识别技术(automatic speech recognition,asr)对接收单元410接收的语音信息进行识别,得到该语音信息对应的语音文本。之后,服务器400的处理单元411对该语音文本进行转换,得到该语音文本包含的至少一个词向量。之后,服务器400的处理单元411根据该词向量进行意图理解,得到意图识别结果。服务器400的处理单元411根据该意图识别结果,确定回复内容(如:今天天气晴朗,最低温度19
°
,最高温度28
°
)。之后,服务器400的处理单元411控制发送单元412向显示设备200发送携带该回复内容的回复信息。显示设备200的接收单元210在接收到服务器400发送的回复信息后,显示设备200的处理单元211对接收单元210接收的回复信息进行合成(如采用从文本到语音(text to speech,tts)对回复信息进行合成),确定回复信息对应的语音信息;处理单元211将语音信息输入至语音驱动模型,确定指定关键点集合;处理单元211根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和指定关键点集合生成虚拟数字人的渲染图像。从而,显示设备200可以通过虚拟数字人动态地回复用户:今天天气晴朗,最低温度19
°
,最高温度28
°
,提升用户的体验。
64.具体的,服务器400中的存储单元413可用于存储服务器400的待存储数据以及服务器400的应用程序。
65.具体的,显示设备200中的存储单元213可用于存储显示设备200的待存储数据以及显示设备200的应用程序。
66.具体的,本公开实施例提供的电子设备可以是上述显示设备200,或者服务器400,此处不做限定。
67.本技术所涉及的语音信息均可以为经用户授权或者经过各方充分授权的数据。
68.以下实施例中以执行本公开实施例提供的数据处理方法的执行主体为上述服务器400为例,对本技术实施例的方法进行说明。
69.本技术实施例提供一种数据处理方法,如图4所示,该数据处理方法可以包括s11-s14。
70.s11、接收电子设备发送的用于触发人机交互的语音信息。
71.在一些示例中,用户通过对电子设备提供的目标功能进行选择操作,以触发语音控制、查询、问答、以及闲聊等服务。电子设备响应于对目标功能的选择操向服务器作发送语音信息,语音信息包括语音控制指令、查询指令、问答指令、闲聊指令等交互指令中的任一项。
72.s12、对语音信息进行识别,确定语音信息的回复信息。
73.在一些示例中,服务器400对语音信息进行识别时,可以根据语音信息中的关键词确定该语音信息对应的回复信息。如:语音信息为“今天天气怎么样”,之后服务器400确定语音信息中的关键词为“今天”、“天气”和“怎么样”。之后,服务器400根据关键词,确定该语音信息为问答类语音信息。服务器400查询“天气”,并在“天气”中寻找“今天”相关的。之后,生成与“今天”相关的“天气”的回复信息,如:今天天气晴朗,最低温度19
°
,最高温度28
°
。
74.或者,服务器400先采用asr对语音信息进行识别,确定该语音信息对应的语音文本,如:“今天天气怎么样”。之后,服务器400将语音文本按照预设词典进行分词,确定语音文本中包含的至少一个实际分词。之后,根据每个实际分词对应的历史分词所出现的概率,确定最大的概率对应的历史分词。
75.在电子设备当前登陆的用户账号对应的语音信息中包含该历史分词的情况下,查询该历史分词对应的历史答复信息,并根据该历史答复信息生成回复信息。
76.在电子设备当前登陆的用户账号对应的语音信息中不包含该历史分词的情况下,查询该历史分词对应的至少一个答复信息。从回复信息中任意选择一个答复信息,作为回复信息。其中,预设词典中包含至少一个分词。
77.具体的,历史分词为通过对电子设备发送的历史语音信息进行分词,所得到的。
78.s13、将回复信息输入至文本驱动模型,确定目标关键点集合。其中,目标关键点集合中至少包括用于指示嘴巴和眼睛的关键点。
79.在一些示例中,人在说话的时候,对应的面部表情也会存在差异。如:人在说不同的语音信息时,对应嘴巴的张合程度也是不同的。因此,可以通过获取带有人物正脸,且口齿清晰的视频数据(如指定主播的新闻播报视频)进行训练,从而使得文本驱动模型,可以识别出该指定主播在说不同的语音信息时,该指定主播的人脸图像中各个关键点。这样,后续再将回复信息输入至文本驱动模型时,此时文本驱动模型可以识别出该指定主播在说不同的回复信息时,该指定主播的人脸图像中各个关键点。
80.此外,虚拟数字人可以看作是一张静止的图像。为了让该静止的图像生成可以播放的动画,可以控制该虚拟数字人的指定部位进行运动,从而实现动画效果。如:指定部位可以是嘴巴。由于,文本驱动模型预测的人脸与虚拟数字人的标准脸可能存在差异,因此,需要通过将文本驱动模型预测的用于指示嘴巴的关键点,映射到虚拟数字人的标准脸上,从而使得虚拟数字人的嘴巴可以按照实际的回复内容进行播报,提升用户的体验。
81.s14、向电子设备发送携带回复信息和目标关键点集合的目标信息,以便电子设备根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和目标关键点集合生成虚拟数字人的渲染图像。其中,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
82.在一些示例中,目标关键点集合中包含的关键点种类与预设关键点集合中包含的关键点种类相同。如:本公开实施例提供的数据处理方法,采用人脸识别算法(如:deep-sdm、dlib、人脸对齐(face alignment)、mediapipe中的任一项)提取人脸图像的n(如:68、106、478)个关键点,然后对关键点在空间维度进行对齐,如:先将106个关键点按一定比例缩放到一定值域的空间,然后挑选一个标准人脸(眼睛鼻子中轴线在x=0),通过旋转和平移使得106个关键点与标准人脸上的眼角,鼻梁上的设置的关键点最大重叠,最终获得空间对齐后的人脸关键点坐标,即预设关键点集合。
83.在一些示例中,服务器在得到目标关键点集合后,还可以计算目标关键点集合中每个关键点与对应的指定人物在静止状态下的人脸图像对应的初始特征点之间的差值(也可以称为关键点偏移量)。之后,将关键点偏移量和回复信息发送至电子设备。这样,电子设备就可以根据预先配置的虚拟数字人的脸部对应的预设关键点集合中每个关键点和该关键点对应的关键点偏移量之和,得到修正后的关键点。并将该修正后的关键点作为顶点坐标,以生成虚拟数字人的渲染图像。
84.具体的,电子设备在显示虚拟数字人的渲染图像时,为了保证虚拟数字人更加逼真,电子设备可以通过控制audiotrack播放器传入音频字节流数据速度和顶点坐标更新速度,实现驱动图像和音频对齐,从而保证虚拟数字人的真实感。
85.具体的,电子设备根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和目标关键点集合生成虚拟数字人的渲染图像时,电子设备可以根据目标关键点集合中的关键点的实际坐标,确定至少一个顶点坐标。将预设关键点集合中每个关键点作为纹理坐标,确定至少三个纹理坐标。采用三角剖分法(delaunay triangulation algorithm,delaunay)对纹理坐标进行处理,确定纹理三角形。基于顶点坐标、纹理坐标、纹理三角形和回复信息,生成虚拟数字人的渲染图像。
86.在一些可实施的示例中,结合图4,如图5所示,本公开实施例提供的数据处理方法还包括:s15-s17。
87.s15、获取训练样本视频,和训练样本视频的标记结果。其中,指定人物在训练样本视频中讲话对应的实际文本数据,以及指定人物在讲话过程中实际文本数据对应的人脸图像,标记结果包括人脸图像的实际关键点。
88.在一些示例中,训练样本视频可以是新闻播报,脱口秀或者一些网络主播评论视频数据。其中,该视频数据中要求带有正脸唇齿清晰的图像。
89.下面以训练样本视频为新闻播报数据为例,获取新闻播报数据的过程如下:
90.采用正则方式提取特定网页中统一资源定位系统(uniform resource locator,url),利用一些网络爬虫工具如(you-get工具)爬取相应url链接视频。
91.之后,对爬取到的视频数据进行场景分割,如:本公开实施例提供的数据处理方法需要正脸播报视频数据,但如新闻联播,除了会有主持人播报场景外,还会穿插一些其它场景,所以需要对视频进行场景分割。本公开实施例提供的数据处理方法采用pyscenedetect获取不同场景起始时间点(场景切分包很多种,这里仅举例)。之后,根据得到的时间点,利用moviepy中videofileclip工具包对视频进行切割,切割后每段视频为同一场景的视频数据。
92.最后,对场景分割后的视频数据进行视频筛选,如:利用dlib工具中人脸检测器和人脸识别器,在某段视频中随机挑选两帧图片,当检测结构满足以下条件时保留视频,否则删除:
93.a、仅检测到一个人头。
94.b、两次随机检测人头检测框中心点位置不大于20像素点。
95.c、两次检测人脸识别为同一个人。
96.通过上述操作之后,便得到了训练样本视频。
97.此外,由于目标模型无法直接识别训练样本视频,因此需要对训练样本视频进行
处理,如:将训练样本视频中的语音数据转换为对应的文本数据,如:本公开实施例提供的数据处理方法采用moviepy在训练样本视频中提取音频数据后,用librosa将音频数据转化为单声道16k采样率的语音数据。之后,通过语音识别模型wenet对语音数据进行识别,得到该语音数据对应的文本数据。之后,通过对文本数据通过校验,从而将校验后的文本数据对应的音素和对应预先数据进行对齐,获取每个音素的时长,最后通过对每个音素进行编码获得因素特征向量。
98.之后,通过音素特征向量输入至目标模型,从而目标模型可以根据因素特征向量,学习训练样本视频中每帧图像对应的人脸关键点,如此目标模型便可以预测人脸关键点。
99.s16、将指定人物在静止状态下的人脸图像对应的初始特征点和训练文本数据至目标模型,确定目标模型预测的预测关键点。
100.在一些示例中,指定人物在静止状态下的人脸图像包括指定人物在静止状态下无表情、睁眼、闭嘴是对应的人脸图像。
101.在一些示例中,目标模型采用的模型架构为基于transformer结构的fastspeech/fastspeech2模型结构(用来做语音合成模型),在将训练文本数据至目标模型时,需要对对回复信息进行处理,确定回复信息对应的音素。对音素进行编码,确定每个音素对应的音素特征向量。将音素特征向量作为目标模型的输入,监督学习label(如:训练样本视频通过关键点检测得到的每一帧的关键点坐标序列)每帧视频检测到的人脸关键点,最终模型输出人脸的预测关键点。
102.具体的,文本驱动模型相较于语音驱动模型,将语音驱动模型中的mlp+bilstm模型架构替换为语音合成fastspeech模型架构;去除语音驱动模型中语音合成部分,将语音驱动模型中的mel谱合成部分替换为关键点合成,除了输入特征和模型差异,其它设置和语音驱动模型相同。
103.相较于语音驱动模型,文本驱动模型为transformer结构,生成关键点的连续性和稳定性更好。
104.fastspeech模型由于参数较多,模型较复杂,目前还无法实现端侧部署,需要通过云端的方式实现部署。
105.1、音素时间维度对齐:音素区间ct∈{"pad","/","aa0"
…
"x","z","zh"},共67个英文音素,120个中文音素加4个特殊符号(空格、静音、空位补齐(padding)、韵律边界),总共191个。将一段语音数据t长度,16000采样率,首先处理成mel频率倒谱系数(mel frequency cepstrum coefficient,mfcc),时间窗口为200,维度为39,得到mfcc[t
×
80,39]维度,将语音对应文本离散成音素列表phonemes,如:“你好
”‑
》{eos n i2 h aa3 uu3 eos}。然后我们将mfcc[t
×
80,39]及对应的phonemes基于时延神经网络(time-delay neural network,tdnn)的维特比强制对齐得到对应phonemes的时间列表durations{n1,n2
…
nm},m与phonemes长度相同,n1+n2+
…
nm=t
×
80。
[0106]
2、关键点空间对齐:视频帧率为25fps,提取人脸图像的关键点,如:用deep-sdm提取人脸106关键点,然后对关键点在空间维度进行对齐,对齐方式为首先将关键点按一定比例缩放到一定值域的空间,然后挑选一个标准人脸(眼睛鼻子中轴线在x=0),所有关键点通过旋转和平移做到与标准人脸上的眼角,鼻梁上的n(如:8)组关键点最大重叠,最终获得空间对齐后的人脸关键点坐标fls[t
×
25,318]。
[0107]
3、音画对齐:通过以上两步,我们获得a.phonemes({eos n i2 h aa3 uu3 eos})b.durations{n1,n2
…
nm}(n1+n2+
…
nm=t
×
80)及c.fls[t
×
25,318]。进入模型前需要对80
×
t和25
×
t在时间维度上进行对齐,本公开实施例提供的数据处理方法用双线性差值法将25
×
t
×
318关键点映射到80
×
t
×
318关键点实现对齐。最终我们得到模型输入所需的input{phonemes,durations,人脸关键点(face landmarks,fls)}。
[0108]
4、关键点驱动:音素驱动模型选用基于transformer结构的fastspeech模型,训练数据为6h新闻播报视频数据提取input{phonemes,durations,fls}。输入数据为:phonemes:{ph1,ph2...phm},durations{n1,n2
…
nm}和fls[t
×
80,318],输出为delta[t
×
80,318]维度关键点相对于reference关键点偏移量。loss设置为delta+reference与fls求算均方误差(mean square error,mse)。
[0109]
5、嘴部加权loss(可选):因为在语音驱动关键点任务中,闭嘴口型如“b,p,m,f”较难拟合,所以需要给到类似口型比较大的loss权重,将生成的delta+reference得到生成人脸关键点f,f维度为[t
×
80,318],reshape到[t
×
80,106,3],其中第二维度上101代表嘴巴上关键点,104为嘴巴下关键点,求取两个关键点距离得到嘴巴距离矩阵d[t
×
80,1],因为这些值di都是大于0小于0.2左右的数,我们希望di越小权重越大,所以最终权重w=1/(d
×
lamda+0.01),lamda为系数,我们设置其为1,加0.01保证不会出现除以0的情况。最终,嘴部加权loss=mse
×w[0110]
6、通过训练得到文本驱动模型,在推理过程种当输入一段文本,我们会通过音素库找到对应的音素序列和duration序列输入到文本驱动模型,得到对应语音片段的目标关键点集合。
[0111]
s17、基于预测关键点和实际关键点,调整目标模型的网络参数,直至目标模型收敛,得到文本驱动模型。
[0112]
在一些可实施的示例中,结合图5,如图6所示,上述s17具体可以通过下述s170-s173实现。
[0113]
s170、基于第一目标损失函数、预测关键点和实际关键点,确定用于指示嘴巴的关键点对应的面积差值。
[0114]
s171、对第二目标损失函数、预测关键点和实际关键点进行匹配,确定相匹配的两个关键点之间的距离。
[0115]
s172、基于第三目标损失函数、预测关键点和实际关键点进行匹配,确定相匹配的两个关键点之间的梯度差值。
[0116]
在一些示例中,第一目标损失函数、第二目标损失函数以及第三目标损失函数可以是回归损失函数,如l1 loss。s173、根据面积差值、距离和梯度差值,调整目标模型的网络参数,直至目标模型收敛,得到文本驱动模型。
[0117]
在一些可实施的示例中,结合图4,如图7所示,上述s13具体可以通过下述s130-s132实现。
[0118]
s130、对回复信息进行处理,确定回复信息对应的音素以及音素对应的音素时长。
[0119]
s131、对音素进行编码,确定每个音素对应的音素特征向量。
[0120]
在一些示例中,服务器400中预先存储了每个音素与音素特征向量的对应关系。之后,在需要确定音素对应的音素特征向量时,可以查询该对应关系,确定每个音素对应的音
素特征向量。
[0121]
或者,服务器400在对音素进行编码时,可以将该音素输入至音素模型中,确定该音素对应的音素特征向量。其中,音素模型的训练过程如下:
[0122]
获取训练样本数据和训练样本数据的标记结果。其中,训练样本数据中包括至少一个音素,标记结果包括音素对应的音素特征向量。
[0123]
将训练样本数据输入至神经网络模型中,得到神经网络模型对该训练样本数据中每个音素的预测结果。
[0124]
在预测结果和标记结果不同的情况下,调整神经网络模型的网络参数,直至预测结果和标记结果相同时,确定神经网络模型收敛,得到音素模型。
[0125]
s132、将音素特征向量和音素时长输入至文本驱动模型,确定目标关键点集合。
[0126]
以下实施例中以执行本公开实施例提供的数据处理方法的执行主体为上述显示设备200为例,对本技术实施例的方法进行说明。
[0127]
本技术实施例提供一种数据处理方法,如图8所示,该数据处理方法可以包括s21-s25。
[0128]
s21、响应于对目标功能的选择操作,向服务器发送语音信息。
[0129]
s22、接收服务器发送的回复信息。
[0130]
s23、对回复信息进行合成,确定回复信息对应的语音信息。
[0131]
s24、将语音信息输入至语音驱动模型,确定指定关键点集合。其中,指定关键点集合中至少包括用于指示嘴巴和眼睛的关键点。
[0132]
s25、根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和指定关键点集合生成虚拟数字人的渲染图像。其中,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
[0133]
在一些示例中,显示设备200通过调用端侧中央处理器(central processing unit,cpu)或特定图形处理器(graphics processing unit,gpu)执行本公开实施例提供的数据处理方法,如:显示设备200接收用户输入的一段语音信息,例如语音信息的长度为t,采样率16k,数据类型为float32则此段音频可用16000
×
t个float数表示。
[0134]
mfcc:帧长1024,帧移256,频率区间90-7600,bin size为80,窗口选择“汉宁窗(hanning)”,最终得到16000
×
t/256
×
80的2维特征数组。
[0135]
deepspeech(可选):预训练数据为x={(x(1),y(1)),(x(2),y(2)),
…
(x(n),y(n))},2中,n=16000
×
t/256,x(n)代表对于n位置的80维度梅尔谱特征向量,y(n)代表n位置对应音素概率分布p(ct|x),ct∈{"pad","/","aa0"
…
"x","z","zh"},共67个英文音素,120个中文音素加4个特殊符号(空格、静音、padding、韵律边界),总共191个。label以onehot形式产生,所以y(n)为维度为191的一维向量。deepspeech为循环神经网络(recurrent neural network,rnn)结构,输入为16000
×
t/256
×
80数组,输出为16000
×
t/256
×
191特征向量。
[0136]
数据对齐:语音驱动模型训练需要1.梅尔谱特征向量(16000
×
t/256
×
80维度)或者deepspeech输出向量(16000
×
t/256
×
191维度)2.关键点坐标(25
×
t
×
318),25为帧率,318为106关键点对应xyz坐标值。进入模型前需要对16000
×
t/256和25
×
t在时间维度上进行对齐,本公开实施例提供的数据处理方法用双线性差值法将25
×
t
×
318关键点映射到
16000
×
t/256
×
318关键点实现对齐。最终我们得到16000
×
t/256
×
80(或191)的语音特征向量和16000
×
t/256
×
318关键点坐标。
[0137]
关键点空间对齐:本公开实施例提供的数据处理方法用deep-sdm提取人脸106关键点,然后对关键点在空间维度进行对齐,对齐方式为首先将关键点按一定比例缩放到一定值域的空间,然后挑选一个标准人脸(眼睛鼻子中轴线在x=0),所有关键点通过旋转和平移做到与标准人脸上的眼角,鼻梁上的n(如:8)组关键点最大重叠,最终获得空间对齐后的人脸关键点坐标。
[0138]
帧对齐:每帧关键点坐标变化需要依赖上下文信息,需要对表示音频的梅尔谱或deepspeech提取的特征向量进行时间维度的编码,本公开实施例提供的数据处理方法设计了一个动态滑窗动态截取与当前关键点坐标对应的音频特征,窗口大小为18,步长为1。例如关键点坐标第i位置对应音频特征为第i-17到i位置,最终得到输入数据为[16000
×
t/256,18,80]或[16000
×
t/256,18,191]维度的音频特征和[16000
×
t/256,318]维度的关键点label。t表示显示设备接收的音频数据的总时长,256表示音频数据和mfcc二者之间的滑窗。
[0139]
关键点驱动:关键点驱动选用多层感知机(multilayer perceptron,mlp)+长短期记忆网络(long short-term memory,lstm)+mlp模型,训练数据为6h新闻播报视频数据提取训练音频数据和label。输入数据为[16000
×
t/256,18,80]或[16000
×
t/256,18,191]维度的音频特征和[16000
×
t/256,318]维度的关键点label,输出为delta[16000
×
t/256,318]维度关键点相对于reference的关键点偏移量。loss设置为delta+reference与label求算mse。
[0140]
其中,reference是指虚拟数字人对应的脸部对应的预设关键点集合,delta是指指定人物在静止状态下的人脸图像对应的每个初始特征点与指定关键点集合中每个关键点之间的差值,也称为关键点偏移量。如:在提取人脸图像的关键点时,均采用deep-sdm提取人脸106关键点,这样预设关键点集合中存在106个关键点、指定人物在静止状态下的人脸图像对应的初始特征点也是106个。之后,通过计算预设关键点集合中每个关键点与对应的指定人物在静止状态下的人脸图像对应的初始特征点之间的差值,得到delta。嘴部加权loss(可选):因为在语音驱动关键点任务中,闭嘴口型如“b,p,m,f”较难拟合,所以需要给到类似口型比较大的loss权重,将生成的delta+reference得到生成人脸关键点f,f维度为[16000
×
t/256,318],reshape到[16000
×
t/256,106,3],其中第二维度上101代表嘴巴上关键点,104为嘴巴下关键点,求取两个关键点距离得到嘴巴距离矩阵d[16000
×
t/256,1],因为这些值di都是大于0小于0.2左右的数,di越小权重越大,所以最终权重w=1/(d
×
lamda+0.01),lamda为系数,设置其为1,加0.01保证不会出现除以0的情况。最终,嘴部加权loss=mse
×
w。
[0141]
通过训练得到语音驱动模型,当语音驱动模型中输入一段语音片段,可得到对应语音片段的指定关键点集合。
[0142]
在一些可实施的示例中,结合图8,如图9所示,本公开实施例提供的数据处理方法还包括:s26-s28。
[0143]
s26、获取训练样本视频和训练监督视频。其中,训练样本视频包括指定人物在训练样本视频中讲话对应的实际语音数据,训练监督视频包括指定人物在讲话过程中实际语
音数据对应的人脸图像的实际关键点。
[0144]
在一些示例中,由于目标模型无法直接识别训练样本视频,因此需要对训练样本视频进行处理,如:提取训练样本视频中的音频数据,如:采用deepspeech/wenet等语音识别预训练模型的编码器encoder部分作为语音信号特征提取器,提取相应音频数据的特征向量(如mfcc),或者音频特征fbank等常用的谱信息对应的特征向量)。
[0145]
通过如deepspeech/wenet等语音识别预训练模型encoder部分作为语音信号特征提取器,提取相应语音信号的语音特征向量;
[0146]
s27、将指定人物在静止状态下的人脸图像对应的初始特征点和训练语音数据输入至预设模型中,得到预设模型预测的预测关键点。
[0147]
在一些示例中,预设模型采用模型架构为mlp+bilstm+mlp,在将语音信息输入至预设模型时,需要对语音信息进行处理,提取语音信息中的音频特征(如:mfcc,或者fbank等谱特征),得到音频特征对应的特征向量。之后,将该特征向量预设模型的输入,用于监督学习label每帧视频检测到的人脸关键点坐标,输出预测的人脸关键点。
[0148]
s28、基于预测关键点和实际关键点,调整预设模型的网络参数,直至预设模型收敛,得到语音驱动模型。
[0149]
在一些可实施的示例中,每个关键点对应一个实际坐标;结合图8,如图10所示,上述s25具体可以通过下述s250-s253实现。
[0150]
s250、根据指定关键点集合中的关键点的实际坐标,确定至少一个顶点坐标。其中,一个顶点坐标对应一个关键点。
[0151]
在一些示例中,电子设备还可以计算指定关键点集合中每个关键点与对应的指定人物在静止状态下的人脸图像对应的初始特征点之间的差值(也可以称为关键点偏移量)。之后,预先配置的虚拟数字人的脸部对应的预设关键点集合中每个关键点和该关键点对应的关键点偏移量之和,得到修正后的关键点,并将该修正后的关键点作为顶点坐标。
[0152]
s251、将预设关键点集合中每个关键点作为纹理坐标,确定至少三个纹理坐标。其中,一个纹理坐标对应一个关键点。
[0153]
s252、采用三角剖分法对纹理坐标进行处理,确定纹理三角形。
[0154]
s253、基于顶点坐标、纹理坐标、纹理三角形和回复信息,生成虚拟数字人的渲染图像。
[0155]
在一些示例中,可以将顶点坐标、纹理坐标、纹理三角形输入至opengl es中,并按一定的帧率进行渲染,同时控制顶点坐标的输入速度与回复信息的输入速度,以保证渲染图像和语音信息能够对齐,保证虚拟数字人的显示效果。
[0156]
在一些示例中,通过语音驱动模型或者文本驱动模型,获得与语音数据对应的关键点集合(如:用于指示人脸的关键点,或者用于指示眉毛的关键点,或者用于指示鼻子的关键点等)。由于,语音驱动模型或者文本驱动模型所预测的关键点集合所对应的人脸与虚拟数字人的标准脸存在差异,因此需要基于语音驱动模型或者文本驱动模型所预测的关键点集合,来指示虚拟数字人的标准脸进行相应的操作,如:
[0157]
1、图像关键点:通过deep-sdm对虚拟数字人对应的静态图像进行检测,得到虚拟数字人对应的静态图像关键点fls[106,3]维度。
[0158]
2、delta偏量:通过语音驱动模型或者文本驱动模型,得到预测的关键点集合,之
后,通过计算指定关键点集合中每个关键点与对应的指定人物在静止状态下的人脸图像对应的初始特征点之间的差值(也可以称为关键点偏移量),以得到delta[n,106,3]维度。
[0159]
3、delta空间对齐:首先需要将delta映射到和fls同一维度空间,这里设置两个参数缩放scale和偏移shift,scale为一浮点数,shift形如[x_,y_,z_],映射后的delta_=delta/scale
–
shift,两个参数根据不同的虚拟数字人对应的静态图像,手动多次调试获得。
[0160]
4、驱动关键点获得:fls为预设关键点集合中的关键点,delta为驱动模型获得关键点偏移量序列,通过计算预先配置的虚拟数字人的脸部对应的预设关键点集合中每个关键点和该关键点对应的关键点偏移量之和,得到修正后的关键点fls_gen=fls+delta。
[0161]
5、关键点挑选:关键点越多,在显示设备200渲染耗时就会越高,显示设备200渲染所占用的资源就会越高,所以一般会挑选对虚拟数字人对应的静态图像影响较大的关键点,如:用于指示嘴巴的关键点,用于指示眼睛的关键点,忽略其它关键点如用于指示鼻子的关键点、用于指示脸颊的关键点等。本公开实施例提供的数据处理方法中,挑选用于指示眼睛的12关键点和用于指示嘴巴的8关键点,同时在虚拟数字人对应的静态图像的脸部四周增加4个锚点,在虚拟数字人对应的静态图像四周增加4个锚点,总共28关键点,最终得到关键点坐标为fls_gen_select[n,28,3]。
[0162]
6、纹理三角形:根据上述关键点挑选所得到的关键点,获得fls_select[28,3],用delaunay获取驱动图像关键点三角剖分结果得到剖分三角形序列tra[49,3]维度,代表49个三角形和对应的关键点序号。
[0163]
7、纹理坐标:纹理坐标值域为0-1,所以需要将fls_select[28,3]值域缩放到0-1空间,缩放方式为除以拉伸图片(方形图片)宽度w。
[0164]
8、顶点坐标:顶点坐标值域为-1到1,需要将(fls_gen_select[n,28,3]
–
0.5
××
w)/0.5w。
[0165]
9、最终将纹理坐标、纹理三角形、顶点坐标及图片传入opengl es渲染器,并通过传入但顶点坐标速度控制音画对齐。
[0166]
示例性的,当视频的帧率为80fps时,此时视频的传入速度为12.5ms/帧。
[0167]
在一些示例中,当电子设备生成的虚拟数字人的渲染图像的帧率为80fps时,传输该渲染图像的压力较大。为了降低传输该渲染图像的压力,可以通过降低渲染图像的帧率来降低传输该渲染图像的压力,如可以每间隔四帧在渲染图像中挑选一帧,从而将虚拟数字人的渲染图像的帧率变为20fps。
[0168]
10、(可选)如果虚拟数字人对应的静态图像为带有头部动作的视频,则需要通过空间对齐算法将驱动关键点序列与视频关键点序列对齐。
[0169]
在一些示例中,设置opengl es按一定帧率渲染,通过播放速度控制模块控制顶点坐标和语音信息的传入速度,顶点坐标通过控制模块存入顶点缓冲区,音频信号存入音频缓冲区等待audiotrack调用。音频播放和视频播放异步实现,仅通过播放速度控制模块对齐音频信号和顶点坐标,最终实现音视频同步播放。
[0170]
具体的,可以通过调整顶点坐标和纹理坐标关键点个数,来控制本公开实施例提供的数据处理方法对显示设备200算力要求。如:通过deep-sdm获得人脸的68个关键点。为了降低本公开实施例提供的数据处理方法对显示设备200算力要求,通常在该68个关键点
中,仅保留用于指示左右眼睛的12个关键点,以及用于指示嘴巴的8个关键点,以及用于指示脸颊16个关键点其它关键点可用锚点替代。
[0171]
上述主要从方法的角度对本技术实施例提供的方案进行了介绍。为了实现上述功能,其包含了执行各个功能相应的硬件结构和/或软件模块。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,本技术能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0172]
本技术实施例可以根据上述方法示例对数据处理装置进行功能模块的划分,例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理单元中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。需要说明的是,本技术实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
[0173]
如图11所示,本技术的实施例提供一种服务器400的结构示意图。包括通信器101和处理器102。
[0174]
通信器101,用于接收电子设备发送的触发人机交互的语音信息;处理器102,用于对通信器101接收的语音信息进行识别,确定语音信息的回复信息;处理器102,还用于将回复信息输入至文本驱动模型,确定目标关键点集合;其中,目标关键点集合中至少包括用于指示嘴巴和眼睛的关键点;处理器102,还用于控制通信器101向电子设备发送携带回复信息和目标关键点集合的目标信息,以便电子设备根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和目标关键点集合生成虚拟数字人的渲染图像,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
[0175]
在一些可实施的示例中,通信器101,还用于获取训练样本视频,和训练样本视频的标记结果;其中,训练样本视频包括指定人物在训练样本视频中讲话对应的实际文本数据,以及指定人物在讲话过程中实际文本数据对应的人脸图像,标记结果包括人脸图像的实际关键点;处理器102,还用于将指定人物在静止状态下的人脸图像对应的初始特征点和通信器101获取的训练文本数据至目标模型,确定目标模型预测的预测关键点;处理器102,还用于基于预测关键点和通信器101获取的实际关键点,调整目标模型的网络参数,直至目标模型收敛,得到文本驱动模型。
[0176]
在一些可实施的示例中,处理器102,具体用于基于第一目标损失函数、预测关键点通信器101获取的实际关键点,确定用于指示嘴巴的关键点对应的面积差值;处理器102,具体用于对第二目标损失函数、预测关键点和通信器101获取的实际关键点进行匹配,确定相匹配的两个关键点之间的距离;处理器102,具体用于基于第三目标损失函数、预测关键点和通信器101获取的实际关键点进行匹配,确定相匹配的两个关键点之间的梯度差值;处理器102,具体用于根据面积差值、距离和梯度差值,调整目标模型的网络参数,直至目标模型收敛,得到文本驱动模型。
[0177]
在一些可实施的示例中,处理器102,具体用于对回复信息进行处理,确定回复信息对应的音素以及音素的音素时长;处理器102,具体用于对音素进行编码,确定每个音素对应的音素特征向量;处理器102,具体用于将音素特征向量和音素时长输入至文本驱动模
型,确定目标关键点集合。
[0178]
其中,上述方法实施例涉及的各步骤的所有相关内容均可以援引到对应功能模块的功能描述,其作用在此不再赘述。
[0179]
当然,本技术实施例提供的服务器400包括但不限于上述模块,例如服务器400还可以包括存储器103。存储器103可以用于存储该服务器400的程序代码,还可以用于存储服务器400在运行过程中生成的数据,如写请求中的数据等。
[0180]
作为一个示例,结合图3,服务器400中的结果单元410和发送单元412实现的功能通信器101的功能相同,处理单元411实现的功能与处理器102的功能相同,存储单元413实现的功能与存储器103的功能相同。
[0181]
如图12所示,本技术实施例还提供一种芯片系统,该芯片系统可以应用于前述实施例中的服务器400。该芯片系统包括至少一个处理器1501和至少一个接口电路1502。该处理器1501可以是上述服务器400中的处理器。处理器1501和接口电路1502可通过线路互联。该处理器1501可以通过接口电路1502从上述服务器400的存储器接收并执行计算机指令。当计算机指令被处理器1501执行时,可使得服务器400执行上述实施例中服务器400执行的各个步骤。当然,该芯片系统还可以包含其他分立器件,本技术实施例对此不作具体限定。
[0182]
本技术实施例还提供一种计算机可读存储介质,用于存储上述服务器400运行的计算机指令。
[0183]
本技术实施例还提供一种计算机程序产品,包括上述服务器400运行的计算机指令。
[0184]
如图13所示,本技术的实施例提供一种显示设备200的结构示意图。包括通信器201和处理器202。
[0185]
处理器202,用于响应于对目标功能的选择操作,控制通信器201向服务器发送语音信息;通信器201,用于接收服务器发送的回复信息;处理器202,用于对通信器201接收的回复信息进行合成,确定回复信息对应的语音信息;处理器202,还用于将语音信息输入至语音驱动模型,确定指定关键点集合;其中,指定关键点集合中至少包括用于指示嘴巴和眼睛的关键点;处理器202,还用于根据预先配置的虚拟数字人的脸部对应的预设关键点集合、回复信息和指定关键点集合生成虚拟数字人的渲染图像;其中,预设关键点集合至少包括用于指示嘴巴和眼睛的关键点。
[0186]
在一些可实施的示例中,通信器201,还用于获取训练样本视频和训练监督视频;其中,训练样本视频包括指定人物在训练样本视频中讲话对应的实际语音数据,训练监督视频包括指定人物在讲话过程中实际语音数据对应的人脸图像的实际关键点;处理器202,还用于指定人物在静止状态下的人脸图像对应的初始特征点和通信器201获取的训练语音数据输入至预设模型中,得到预设模型预测的预测关键点;处理器202,还用于基于预测关键点和通信器201获取的实际关键点,调整预设模型的网络参数,直至预设模型收敛,得到语音驱动模型。
[0187]
在一些可实施的示例中,每个关键点对应一个实际坐标;处理器202,具体用于根据指定关键点集合中的关键点的实际坐标,确定至少一个顶点坐标;其中,一个顶点坐标对应一个关键点;处理器202,还用于将预设关键点集合中每个关键点作为纹理坐标,确定至少三个纹理坐标;其中,一个纹理坐标对应一个关键点;处理器202,还用于采用三角剖分法
对纹理坐标进行处理,确定纹理三角形;处理器202,还用于基于顶点坐标、纹理坐标、纹理三角形和回复信息,生成虚拟数字人的渲染图像。
[0188]
其中,上述方法实施例涉及的各步骤的所有相关内容均可以援引到对应功能模块的功能描述,其作用在此不再赘述。
[0189]
当然,本技术实施例提供的显示设备200包括但不限于上述模块,例如显示设备200还可以包括存储器203。存储器203可以用于存储该显示设备200的程序代码,还可以用于存储显示设备200在运行过程中生成的数据,如写请求中的数据等。
[0190]
作为一个示例,结合图3,显示设备200中的接收单元210和发送单元211实现的功能通信器101的功能相同,处理单元212实现的功能与处理器102的功能相同,存储单元213实现的功能与存储器103的功能相同。
[0191]
如图14所示,本技术实施例还提供一种芯片系统,该芯片系统可以应用于前述实施例中的显示设备200。该芯片系统包括至少一个处理器2501和至少一个接口电路2502。该处理器2501可以是上述显示设备200中的处理器。处理器2501和接口电路2502可通过线路互联。该处理器2501可以通过接口电路2502从上述显示设备200的存储器接收并执行计算机指令。当计算机指令被处理器2501执行时,可使得显示设备200执行上述实施例中显示设备200执行的各个步骤。当然,该芯片系统还可以包含其他分立器件,本技术实施例对此不作具体限定。
[0192]
本技术实施例还提供一种计算机可读存储介质,用于存储上述显示设备200运行的计算机指令。
[0193]
本技术实施例还提供一种计算机程序产品,包括上述显示设备200运行的计算机指令。
[0194]
以上所述仅是本公开的具体实施方式,使本领域技术人员能够理解或实现本公开。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本公开的精神或范围的情况下,在其它实施例中实现。因此,本公开将不会被限制于本文所述的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1