一种基于双模态融合的低见度道路目标的检测方法
1.本发明属于目标检测技术领域,尤其涉及一种基于双模态融合的低见度道路目标的检测方法。
背景技术:
2.随着人工智能和汽车传感器技术的快速发展,智能车辆目标检测在良好的道路环境中达到了较高的水平。然而,在夜间等低见度道路环境中的目标检测仍然存在很大的挑战。
3.由于可见光具有较详细的纹理信息和较高的空间分辨率,而红外光具有较强的穿透力,不受光照影响。为提高对夜间等低见度交通环境下道路运动目标的检测精度,运用车载相机捕获可见光图像(提供目标纹理、颜色等信息)、红外相机捕获红外光图像(提供目标空间位置、轮廓等信息),将两种配准后的双模态图像按时间序列输入到双模态图像融合算法进行图像的预处理,从而得到具有纹理细节以及辐射信息的高质量图像,提升单阶段目标检测技术在低见度场景下的目标检测的鲁棒性。
4.虽然双模态图像融合技术得到了快速发展和普及,但是,多数算法融合结果的背景区域的纹理细节受到热辐射信息的干扰,无法保留目标的锐化边缘,难以做到既保留可见图像的纹理细节又保持显著目标的强度。此外在融合效率上难以满足道路目标检测的实时性要求。如何在兼顾融合效果的同时提高融合效率是亟待解决的工程问题。
技术实现要素:
5.本发明的目的在于提供一种基于双模态融合的低见度道路目标的检测方法,旨在解决以低见度道路目标检测精度低、实时性低等问题。
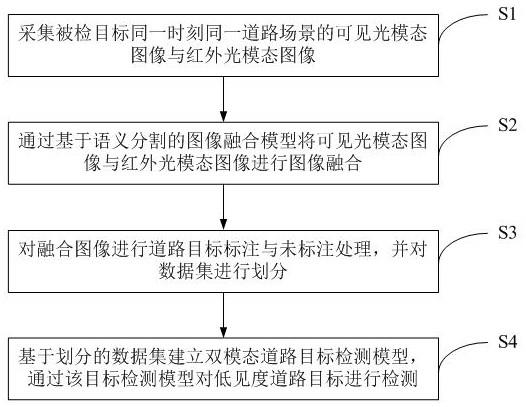
6.本发明是这样实现的,一种基于双模态融合的低见度道路目标的检测方法,该方法包括以下步骤:s1、采集被检目标同一时刻同一道路场景的可见光模态图像与红外光模态图像;s2、通过基于语义分割的图像融合模型将可见光模态图像与红外光模态图像进行图像融合;s3、对融合图像进行道路目标标注与未标注处理,并对数据集进行划分;s4、基于划分的数据集建立双模态道路目标检测模型,通过该目标检测模型对低见度道路目标进行检测。
7.优选地,步骤s1具体包括以下步骤:(1)通过车载相机与红外相机获取不同时刻、场景的低见度道路视频流;(2)使用 opencv 对视频流进行读取处理,设定当前一帧图像中无道路目标时系统隔 1 s 取下一帧图像,前一帧图像有道路目标时间隔 30 ms 取下一帧图像,从而获得可见光模态图像与红外光模态图像;(3)对所述可见光模态图像与红外光模态图像进行配准处理。
8.优选地,所述步骤s2包括以下具体步骤:(1)分别提取不同模态的图像源的特征,通过concat操作将两种模态的特征进行融合;(2)对融合的特征进行多轮的卷积与激活操作得到融合的图像,将融合的图像输入到语义分割网络架构中得到语义分割结果;其中,通过语义分割的结果与labels之间的语义损失将分割所需的语义信息传回图像融合网络,以使融合网络保留源图像中的语义信息,以及,通过图像融合的结果与图像源的内容损失约束图像融合网络的优化。
9.优选地,步骤s3具体包括以下步骤:(1)设定常见道路运动目标;(2) 通过标签工具make sence或者labelimg对一部分融合图像的道路运动目标进行框选与定义,完成标签制作,另一部分融合图像不进行标签制作;(3)打过标签的融合图像按比例划分为训练集与验证集作为训练数据集,将未打标签的融合图像作为测试数据集。
10.优选地,在步骤s4中,所述双模态道路目标检测模型的构建构成包括以下步骤:(1)对训练数据集进行mosaic数据增强、随机翻转、遮挡处理;(2)初始学习率设为0.01,最终学习率以one_cycle形式从0.01衰减至0.01*0.2;warmup_epochs设为5,使用预热使模型收敛速度变快;epochs设为300,batch-size设为16;(3)选定深度学习预训练模型;(4)将预训练模型中的主干提取网络改用mobilenet-v2,在保证精度的情况下,减少参数量、降低模型大小。
11.相比于现有技术的缺点和不足,本发明具有以下有益效果:(1)本发明检测方法采用搭载红外相机和车载相机的机器视觉获取同一时刻的目标双模态图像,解决了传统机器视觉只能检测单模态图像而无法获得具有丰富特征的图像造成道路目标难以检测的问题;(2)本发明解决了双模态融合图像背景区域的纹理细节受到热辐射信息的干扰,无法保留目标的锐化边缘,难以做到既保留可见图像的纹理细节又保持显著目标的强度的问题;(3)本发明利用语义损失引导高级语义信息流回图像融合模块,有效提升了高级视觉任务在融合图像上的性能,解决了现有的融合算法片面关注融合图像的视觉质量和统计指标,而忽略了高级视觉任务的需求,减少了图像融合和高级视觉任务之间的差距;(4)本发明的双模态图像融合部分采用gpu加速,融合速度明显高于其他融合算法;(5)本发明通过将yolo的主干网络cspdarknet53替换为mobilenet-v2,在保证精度的前提下减少了检测模型参数量,从而减少推理时间,不仅方便移植还能满足实时检测的需求。
附图说明
12.图1是本发明实施例中检测方法的步骤流程图;图2是本发明实施例中检测方法的检测操作的流程图;
图3是本发明实施例中配准后的可见光模态图像;图4是本发明实施例中配准后的红外光模态图像;图5是本发明实施例中图像融合模型中的梯度残差密集块的结构示意图;图6是本发明实施例中基于语义分割的图像融合模型的结构示意图;图7是本发明实施例中的融合图像;图8是本发明实施例中的mosaic数据增强结果。
具体实施方式
13.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
14.本发明实施例公开了一种基于双模态融合的低见度道路目标的检测方法,如图1、图2所示,该方法应用于检测低见度下道路目标为车辆、行人和骑车人的检测,具体包括以下步骤:s1、采集被检目标同一时刻同一道路场景的可见光模态图像与红外光模态图像步骤s1具体过程为:(1)通过车载相机与红外相机获取不同时刻、场景的低见度道路视频流;(2)使用 opencv 对视频流进行读取处理,设定当前一帧图像中无道路目标时系统隔 1 s 取下一帧图像,前一帧图像有道路目标时间隔 30 ms 取下一帧图像,从而获得双模态图像;(3)对可见光模态图像与红外光模态图像进行配准处理,获得配准后的双模态图像,如图3、图4所示,其中,图3为配准后的可见光模态图像,图4为配准后的红外光模态图像。
15.s2、通过基于语义分割的图像融合模型将可见光模态图像与红外光模态图像进行图像融合在步骤s2中,依赖pytorch框架强大的gpu加速,首先建立基于语义分割的图像融合模型中的梯度残差密集块(grdb),如图5所示,梯度残差密集块是 resblock的变体,其中主流采用密集连接,残差流集成梯度操作。主流部署了两个3
×
3的 lrelu 卷积层和一个内核大小为1
×
1的普通卷积层。将密集连接引入主流以充分使用由各种卷积层提取的特征。残差流采用梯度运算来计算特征的梯度幅度,并采用1
×
1卷积层来消除通道维度差异。然后,通过逐元素加法添加主密集流和残余梯度流的输出,以集成深度特征和细粒度细节特征。grdb 将可学习的卷积特征与梯度幅度信息聚合在一起。
16.其次,建立基于语义分割的图像融合模型,如图6所示,其具体过程为:(1)分别将不同模态的图像源进行特征提取,通过concat操作将两种模态的特征进行融合;(2)对融合的特征进行多轮的卷积与激活操作得到融合的图像,将融合的图像输入到语义分割网络架构中得到语义分割结果。
17.其中,语义分割的结果与labels之间的损失为语义损失,这样语义损失能够将分割所需的语义信息反传回融合网络从而促使融合网络能够有效地保留源图像中的语义信
息;而图像融合的结果与图像源的损失为内容损失,这两种损失共同约束网络的优化。
18.具体的,内容损失定义如下:l
content
由强度损失l
int
与纹理损失l
texture
线性加权组成,而强度损失用于优化双模态图像融合的表观强度、纹理损失则强制融合图像包含更多的细粒度信息,为平衡强度损失与纹理损失的权重系数。其中h,w表示输入图像的高度与宽度,表示sobel算子,运用最大选择策略来融合红外光与可见光的强度分布,而最优纹理则是红外光与可见光纹理的最大聚合。
19.语义损失定义如下:l
semantic
由主损失l
main
与辅损失l
aux
线性加权组成,其中为平衡主损失与辅损失的权重系数。
20.融合网络总的损失为:融合网络总的损失为:是表征语义损失的超参数。
21.s3、对融合图像进行道路目标标注与未标注处理,并对数据集进行划分步骤s3具体包括以下步骤:(1)设定三种常见道路运动目标,分别为车辆、行人以及骑车人;(2)通过标签工具makesence或者labelimg对一部分融合图像的道路目标进行框选与定义,完成标签制作,另一部分图像不进行标签制作;(3)打过标签的融合图像按照9:1的比例划分为训练集与验证集作为训练数据集,将未打标签的融合图像作为测试数据集,如图7所示。
22.s4、基于划分的数据集建立双模态道路目标检测模型,通过该目标检测模型对低见度道路目标进行检测步骤s4中,双模态道路目标检测模型的构建过程为:(1)对训练数据集进行mosaic数据增强、随机翻转、遮挡等处理,结果如图8所示;(2)初始学习率设为0.01,最终学习率,以one_cycle形式从0.01衰减至0.01*0.2;warmup_epochs:设为5,使用预热有助于使模型收敛速度变快,效果更佳;epochs设为300,batch-size设为16。
23.(3)选定深度学习预训练模型;在本发明实施例中,改进预训练模型中的主干提取网络改用mobilenet-v2,在保证精度的情况下,减少参数量、降低模型大小,从而缩短推理时间提高模型检测效率。
24.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1