一种无监督低光照域自适应训练方法及检测方法
1.本发明属于数字图像低光照增强领域和机器视觉领域,涉及一种基于深度凹曲线的无监督低光照域自适应训练方法及检测方法。
背景技术:
2.低光照是一种常见的图像降质,光照不足通常由低光照拍摄环境、相机故障、参数设置错误等原因造成。低光照环境下的视觉任务,包括物体分类、人脸检测、行为识别和光流估计等,一直受到学术界和工业界的关注。传统的低光照视觉任务模型训练需要大规模标注训练集,但在低光照环境下,数据难以标注,并且业内已有大量正常光照训练数据集及预训练模型,新搭建低光照数据集并重新训练模型会重复消耗人力物力。如何充分利用已有的具备标注的正常光照训练数据集及正常光照预训练模型,并在不额外引入低光照标注的条件下训练得到能够应用在低光照环境下的模型,即通过无监督域自适应的方法将正常光照预训练模型迁移至低光照环境,具有广泛的现实意义和应用价值。
3.传统无监督低光照域自适应方法可以分为三类。基于提亮的方法对低光照图像进行提亮,从而提升在正常光照图像上训练的模型的性能。基于特征迁移的方法通过对比学习方法对齐正常光图像与低光图像的特征,从而使模型能够运用于低光环境。基于对抗学习的方法通过生成对抗网络生成暗光图像,并利用伪标签将模型迁移到低光环境。
4.但是,基于提亮的方法忽略了人类视觉与机器视觉的差异,基于特征迁移的方法忽略了像素级别调整的重要性,基于对抗学习的方法需要来自多个域的数据且忽略了输入图像自身的特征。已有的无监督域自适应方法效果不佳,均无法满足实际应用的需求。
技术实现要素:
5.针对上述问题,本发明的目的在于提供一种基于深度凹曲线的无监督低光照域自适应训练方法及检测方法。本发明运用自监督训练策略训练深度凹曲线模型进行亮度增强,综合地提升了模型在低光环境下的性能。
6.本发明采用的技术方案如下:
7.一种无监督低光照域自适应训练方法,其步骤包括:
8.1)收集有标注的正常光照训练数据、无标注的低光照训练数据和预训练模型;所述预训练模型为有标注的正常光照训练数据训练后的视觉任务模型;在所述预训练模型的特征提取器之后连接一多层感知器,得到第一模型;所述多层感知器用于将特征提取器提取的特征映射到自监督任务的表示空间;在本方案采用的基于旋转拼图的自监督学习中,多层感知器的输出为一个30维向量,代表被打乱后的图像在所有图像块排列组合方案中的字典序号;
9.2)利用所述有标注的正常光照训练数据训练所述第一模型,训练过程中锁定所述特征提取器的参数,仅训练所述多层感知器;
10.3)构建深度凹曲线模型,用于预测输入图像的每个像素值在亮度增强后的像素
值;将所述深度凹曲线模型置于所述第一模型中所述特征提取器之前,得到第二模型;
11.4)利用所述低光照训练数据训练所述第二模型;训练过程中锁定所述特征提取器的参数以及所述多层感知器中的参数,仅训练所述深度凹曲线模型;
12.5)利用训练后的所述深度凹曲线模型对所述低光照训练数据进行提亮后输入所述预训练模型,预测得到所述低光照训练数据的标签;将预测所得标签作为所述低光照训练数据的伪标签;
13.6)利用所述有标注的正常光照训练数据及带伪标签的低光照训练数据,对所述预训练模型进行训练,得到微调后的预训练模型。
14.进一步的,所述多层感知器采用“全连接层-批规范化层-线性整流函数-全连接层”的网络结构;利用所述正常光照训练数据训练所述第一模型的方法为:首先将一正常光照训练数据依次进行旋转、分块,得到多个图像块;然后将图像块的顺序打乱后输入所述特征提取器进行特征提取,并将所提取特征发送给所述多层感知器;所述多层感知器根据输入的特征数据预测各所述图像块的顺序;其中,训练所述第一模型所采用的损失函数为lc为交叉熵损失函数,是正常光照图像n被打乱的顺序在所有图像块排列组合方案中的字典序号,是多层感知器预测的拼图顺序。
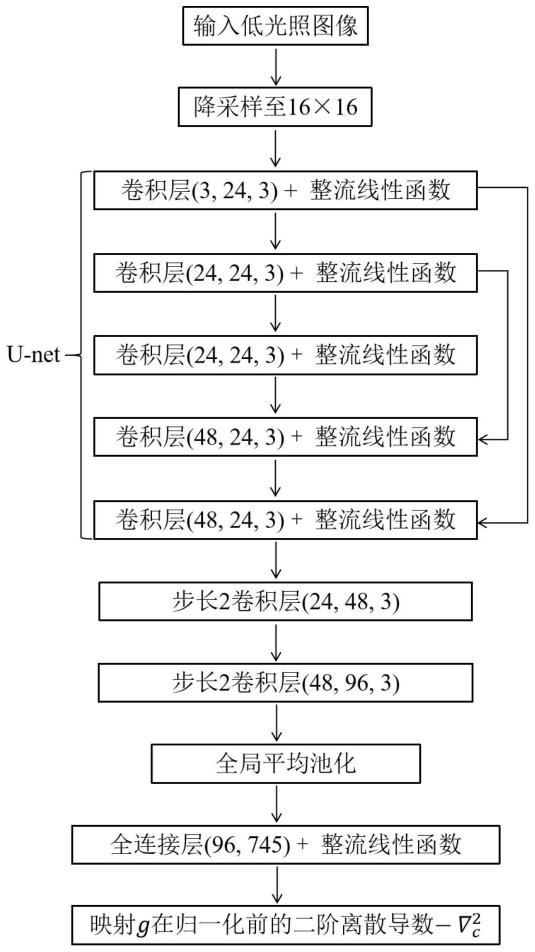
15.进一步的,所述深度凹曲线模型依次包含降采样层、u-net网络、卷积层、全局池化层和全连接层;其中,所述降采样层用于对输入图像进行降采样并输入所述u-net网络,所述u-net网络用于对输入数据进行特征提取并将其输入所述卷积层,所述卷积层对输入特征数据进行进一步特征提取并将所提取特征依次输入所述全局池化层、全连接层,得到预测结果。
16.进一步的,利用所述低光照训练数据训练所述第二模型的方法为:首先采用所述深度凹曲线模型对所述低光照训练数据进行提亮,得到提亮后的图像;然后对提亮后的图像依次进行旋转、分块,得到多个图像块;然后将图像块的顺序打乱后输入所述特征提取器进行特征提取,并将所提取特征发送给所述多层感知器;所述多层感知器根据输入的特征数据预测各所述图像块的顺序;其中训练所述第二模型所采用的损失函数为lc为交叉熵损失函数,是低光照图像l被打乱的顺序在所有图像块排列组合方案中的字典序号,是多层感知器预测的拼图顺序。
17.进一步的,所述深度凹曲线模型包括两个卷积层;即所述深度凹曲线模型依次包含降采样层、u-net网络、第一卷积层、第二卷积层、全局池化层和全连接层。
18.进一步的,对于分类任务,所述预训练模型采用resnet-18;对于人脸检测任务,所述预训练模型采用dsfd;对于行为识别任务,所述预训练模型采用i3d;对于光流估计任务,所述预训练模型采用pwc-net。
19.一种无监督低光照域图像视觉任务检测方法,其步骤包括:
20.1)收集有标注的正常光照训练数据、无标注的低光照训练数据和预训练模型;所述预训练模型为有标注的正常光照训练数据训练后的视觉任务模型;在所述预训练模型的特征提取器之后连接一多层感知器,得到第一模型;所述多层感知器采用“全连接层-批规范化层-线性整流函数-全连接层”的网络结构;
21.2)利用所述有标注的正常光照训练数据训练所述第一模型,训练过程中锁定所述特征提取器的参数,仅训练所述多层感知器;
22.3)构建深度凹曲线模型,用于预测输入图像的每个像素值在亮度增强后的像素值;将所述深度凹曲线模型置于所述第一模型中所述特征提取器之前,得到第二模型;
23.4)利用所述低光照训练数据训练所述第二模型;训练过程中锁定所述特征提取器的参数以及所述多层感知器中的参数,仅训练所述深度凹曲线模型;
24.5)利用训练后的所述深度凹曲线模型对所述低光照训练数据进行提亮后输入所述预训练模型,预测得到所述低光照训练数据的标签;将预测所得标签作为所述低光照训练数据的伪标签;
25.6)利用所述有标注的正常光照训练数据及带伪标签的低光照训练数据,对所述预训练模型进行训练,得到微调后的预训练模型;
26.7)对于待处理的低光照图像,将其输入训练后的所述深度凹曲线模型进行提亮后输入微调后的预训练模型,输出对应的视觉任务检测结果。
27.一种服务器,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行上述方法中各步骤的指令。
28.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述方法的步骤。
29.与现有技术相比,本发明的积极效果为:
30.本发明显著提升正常光照模型在低光照环境下的性能,在codan低光照分类基准测试集上,能够将通用分类模型resnet-18的准确率从60.96%提升至63.92%;在dark face低光照人脸检测基准测试集上,能够将通用人脸检测器dual shot face detector的平均精确度(mean of average precision)由44.44提升至46.91;在低光照行为识别基准测试集arid上,能够将识别准确率由50.18%提升至52.13%;在低光光流估计基准测试机vbof上,能够将终点错误(end-point error)由8.99降低至7.44。
附图说明
31.图1为深度凹曲线模型的结构图。
32.图2为深度凹曲线模型的训练流程图。
33.图3为将预训练模型迁移至低光域的流程图。
具体实施方式
34.为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
35.本实施例公开一种应用在低光分类任务上的无监督低光照域自适应方法,具体说明如下:
36.步骤1:搜集带标注的正常光照图像,组成训练数据集{xn,yn};搜集低光照图像,组成低光照训练数据集{x
l
}。其中,正常光照训练数据集中的样本xn需包含类别信息yn,低光照训练数据集中的样本无需包含类别信息。获取正常光照图像上的预训练模型,该模型中
包含特征提取器。预训练模型采用残差卷积网络resnet-18,也可以采用其他预训练模型。对于分类任务,预训练模型采用resnet-18;对于人脸检测任务,预训练模型采用dsfd;对于行为识别任务,预训练模型采用i3d;对于光流估计任务,预训练模型采用pwc-net。
37.步骤2:构建并训练多层感知器。多层感知器采用“全连接层-批规范化层-线性整流函数-全连接层”的网络结构。固定步骤1中获取的特征提取器的参数,将多层感知器接在特征提取器后,通过自监督训练方法,利用正常光照数据集{x
l
}训练多层感知器。自监督训练方法可以使用旋转拼图的策略,即先对图像进行旋转,再将图像分为3
×
3的9个图像块,对图像块进行顺序打乱,并训练多层感知器恢复图像块原本的顺序。这一步骤的损失函数项为:
[0038][0039]
式中,lc为交叉熵损失函数,是正常光照图像n被打乱的顺序在所有图像块排列组合方案中的字典序号,是多层感知器预测的拼图顺序。训练批大小为64,首先使用学习率0.01进行150000次迭代,再使用学习率0.001进行150000次迭代。
[0040]
步骤3:构建深度凹曲线模型,该深度凹曲线模型以无标注的低光照图像作为输入,用来预测映射g。g是从原图像像素值到新图像像素值的映射。例如,对于8比特灰度图像,由于色彩域中有256种数值,g是一个256维的向量。深度凹曲线模型的输出是g在归一化前的离散二阶导数的相反数,为255维的向量,依据该输出可以积分并归一化得到g。对于8比特三通道彩色图像,深度凹曲线模型对三个通道对应的g分别进行预测,即输出为765维向量。深度凹曲线模型末层为整流线性函数,以保证输出为非负值,进而保证g为凹曲线。深度凹曲线模型的详细结构如附图1所示,依次包含降采样层、u-net网络、两个3
×
3卷积层、全局池化层和全连接层。其中,降采样层将输入图像的分辨率降低为16*16,u-net网络以降采样层的输出作为输入,提取数据的特征,输出与输入大小相等。两个卷积层以u-net网络输出作为输入,进一步提取特征。全局池化层和全连接层以卷积层的输出作为输入,输出深度凹曲线模型的预测结果,即765维向量。
[0041]
步骤4:训练深度凹曲线模型,流程图如附图2所示。本步骤中,特征提取器和多层感知器的参数保持不变,仅训练深度凹曲线模型。训练利用低光照数据集{x
l
},采用自监督范式。自监督训练方法可以使用旋转拼图的策略,即先对图像进行旋转,再将图像分为3
×
3的9个图像块,对图像块进行顺序打乱,并训练模型恢复图像块原本的顺序。这一步骤的损失函数项为:
[0042][0043]
式中,lc为交叉熵损失函数,是低光照图像l被打乱的顺序在所有图像块排列组合方案中的字典序号,是多层感知器预测的拼图顺序。训练批大小为64,初始学习率设置为0.01,共迭代20000次。学习率在第5000和第10000次迭代后以比率0.1衰减。
[0044]
步骤5:获取低光照训练数据的伪标签。该步骤中,先将低光图像数据集{x
l
}输入深度凹曲线预测模型得到提亮后的低光图像数据集{e(x
l
)},然后将低光图像数据集{e(x
l
)}输入步骤1中得到的预训练模型预测得到标签在获得的标签中,置信度低于0.98
的标签将被丢弃。本步骤得到包含伪标签的低光照数据集
[0045]
步骤6:利用步骤1收集的包含标签的正常光数据集和步骤6得到的包含伪标签的低光照数据集,将预训练模型迁移至低光域。具体流程图如附图3所示。预训练模型的训练采用交叉熵损失函数,批大小为64,训练过程共计7000次迭代,初始学习率为0.001,并在第2000,4000,6000次迭代后以比率0.1衰减。训练采用sgd优化器,动量设置为0.9,权重衰减设置为0.00001。训练采用的数据增强方法包括随机裁剪,水平翻转,颜色抖动和随机旋转。
[0046]
步骤7:推理阶段,对于待分类的低光照图像,首先使用步骤4中训练得到的深度凹曲线预测进行提亮,然后输入步骤6训练得到的低光照分类模型(即微调后的预训练模型),得到预测结果,即一个大小等同于数据集中分类类别数的向量。
[0047]
对于人脸检测任务,预训练模型采用双重检测人脸识别器dsfd;对于待检测的低光照图像,首先使用步骤4中训练得到的深度凹曲线预测进行提亮,然后输入步骤6训练微调后的dsfd,得到预测的人脸检测框坐标。
[0048]
对于行为识别任务,预训练模型采用双流膨胀3d卷积网络i3d;对于待检测的低光照图像,首先使用步骤4中训练得到的深度凹曲线预测进行提亮,然后输入步骤6训练微调后的i3d,得到视频每一帧的行为识别预测结果,即一个大小等同于数据集中行为种类数的向量。
[0049]
对于光流估计任务,预训练模型采用金字塔-形变-立体匹配光流估计网络pwc-net;对于待检测的低光照图像,首先使用步骤4中训练得到的深度凹曲线预测进行提亮,然后输入步骤6训练微调后的pwc-net,得到图像中每个像素在下一时刻的位置偏移量。
[0050]
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1