一种组件生成方法、装置、电子设备及存储介质与流程
本发明涉及计算机,具体涉及一种组件生成方法、装置、电子设备及存储介质。
背景技术:
1、在大型应用开发中,由于业务复杂性较高,往往会存在较重的依赖,例如直播业务开发过程中使用到了电商业务和基础框架业务提供的功能,那么在编译生成直播业务的二进制组件之前会需要先编译电商业务和基础框架业务的代码,得到依赖方的二进制组件。在这个过程中,由于每个组件都在快速迭代,接口和内部实现变化非常快,同时每个组件的每次变化都会带来新版本,导致同一工程即使在不同时间点其内部依赖的各组件版本都不尽相同,所以对于每个组件而言,对它的依赖组件版本控制至关重要。如果依赖错了版本,相关组件内部的实现不对,很可能带来线上的崩溃或者逻辑性错误,带来灾难性的损失。
2、一个复杂的大型业务模块,依赖的组件往往都在几十甚至上百,一般常规的组件管理平台,都是手动指定组件相关依赖方的版本,在网页上挨个检查、添加删除和改动相关的组件版本。效率低下,且容易出错,是一种中心化的版本控制系统。
技术实现思路
1、针对上述问题,本技术实例提供了一种组件生成方法,方法应用于开发系统的开发端,通过去中心化的版本控制方式,根据第一工程自动指定组件相关依赖版本,大幅提升大型组件生产的效率,减少组件生产的出错率,并节省了组件的存储成本。
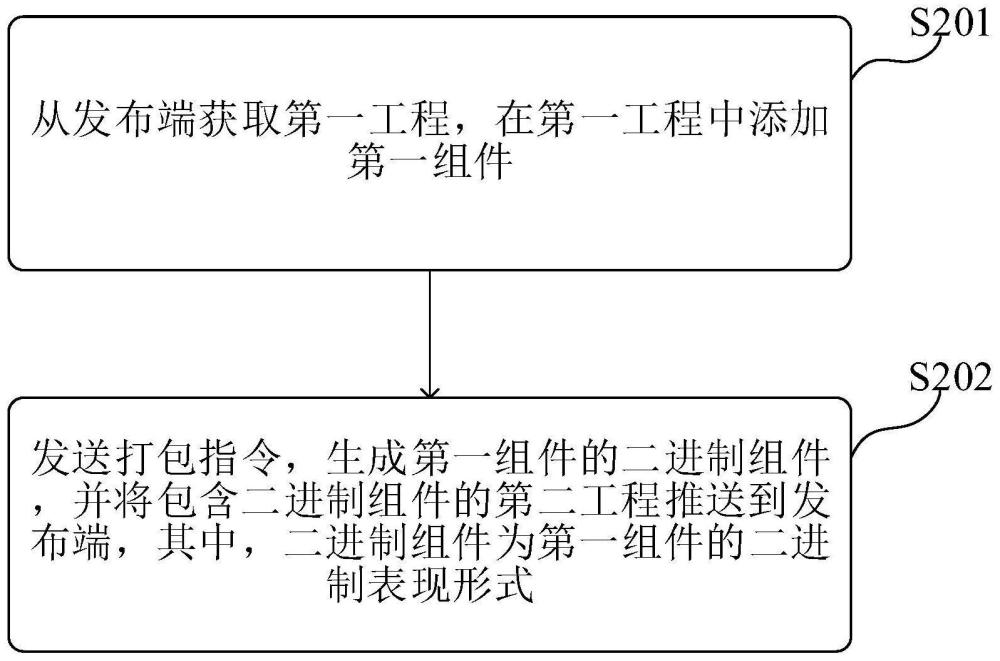
2、为实现上述目的,第一方面,本技术实施例提供了一种组件生成方法,该方法应用于开发系统的开发端,开发系统包括开发端和发布端,该方法包括:从发布端获取第一工程,在第一工程中添加第一组件;发送打包指令,生成第一组件的二进制组件,并将包含二进制组件的第二工程推送到发布端,其中,二进制组件为第一组件的二进制表现形式。
3、可见,在本技术实施例中,开发端获取完整的第一工程,并在第一工程的基础上进行第一组件开发,实现了由每个开发端自身确定开发的新组件与原工程中的依赖组件满足依赖关系,而不需要再将添加了新组件的一系列依赖组件发送到中心设备上,再判断该新组件与依赖库的依赖组件是否满足依赖关系。达成了去中心化开发的效果,提升了组件打包的效率。
4、结合第一方面,在一种可能的实施例中,第一工程包括第一版本号,在将包含二进制组件的第二工程推送到发布端时,该方法还包括:获取发布端当前工程对应的版本号,若当前工程对应的版本号为第一版本号,则确定第二工程推送成功;指示发布端将第一工程替换为第二工程,并在第二工程中添加第二版本号;若当前工程对应的版本号不为第一版本号,则确定第二工程推送失败。
5、可见,在本技术实施例中,在推送添加了新组件的第二工程到发布端后,开发端可以根据从发布端获取的第一工程的第一版本号和从发布端获取的当前工程的版本号确定第二工程能否推送成功。这个过程只需要进行版本号之间的对比,而不需要进行依赖组件之间的对比,大大降低了进行对比的时间。提升了开发端确定是否需要重传新工程的效率。
6、结合第一方面,在一种可能的实施例中,在确定第二工程推送失败后,方法还包括:确定推送失败的次数是否大于第一预设次数;若推送失败的次数不大于第一预设次数,则从发布端获取当前工程,在当前工程中添加第一组件;发送打包指令,生成第一组件的二进制组件,并将包含二进制组件的第三工程推送到发布端;若推送失败的次数大于第一预设次数,则指示将当前工程对应的版本号更新为第二版本号,并指示将当前工程配置为暂停更新状态;从发布端获取当前工程,在当前工程中添加第一组件;发送打包指令,生成第一组件的二进制组件,并将包含二进制组件的第三工程推送到发布端;指示发布端将当前工程替换为第三工程,并指示将第三工程配置为可更新状态。
7、可见,在本技术实施例中,对于多次推送工程不成功的开发端,可以指示在发布端锁定工程版本号,再更新该工程版本号对应的工程,提升推送工程成功的概率。也使得整个工程发布系统能够更合理地安排对开发端工程的推送过程。
8、结合第一方面,在一种可能的实施例中,第一组件与第一工程中的任意组件满足依赖关系。
9、结合第一方面,在一种可能的实施例中,开发端存在第零工程,第零工程为第一工程的前序版本工程,从发布端获取第一工程包括:从发布端获取更新组件,更新组件为第一工程相比与第零工程进行更新后的组件;根据更新组件更新第零工程,获得第一工程。
10、结合第一方面,在一种可能的实施例中,在第一工程中添加第一组件之后,该方法还包括:获取第一组件的依赖库,依赖库包括第一组件,以及与第一组件存在依赖关系的至少一个依赖组件;确定依赖组件为进行更新后的组件,或者为未更新的组件;若依赖组件为未更新的组件,则根据未更新的组件对应的唯一标识从获取未更新的组件的编译缓存;根据对第一组件、更新后的组件的编译结果,以及未更新的组件的编译缓存,获得第一组件的依赖库的编译结果;确定第一组件的依赖库的编译结果正确。
11、在本技术实施例中,第一工程中添加第一组件之后,对第一组件的依赖库的各个组件添加唯一标识,并将依赖库的各个组件的编译结果存储到存储空间内。同一个开发端进行开发时,大概率是对同一个种类或同一个组件进行反复迭代更新,因此,开发端下次进行组件更新时,多半是对第一组件的迭代更新。因此可以利用第一组件的依赖库组件的唯一标识,获得未更新的组件的编译缓存。提高了组件编译效率,进而大幅提高了大型组件的生产效率。
12、结合第一方面,在一种可能的实施例中,编译缓存存储在开发端的第一存储器或第二存储器上,第一存储器的读取速率高于第二存储器,其中:将首次编译组件的编译缓存优先存储在第一存储器中,在第一存储器剩余空间不足的情况下,将其他编译缓存存储到第二存储器中;若首次编译组件为第一组件,则当第一组件的编译缓存在第一预设时长内的调用频次不大于0,则将第一组件的编译缓存迁移到第二存储器中;若首次编译组件为除第一组件之外的其他组件,则当其他组件的编译缓存在第二预设时长内的调用频次排序低于预设排序,则将其他组件的编译缓存迁移到第二存储器中;将其他编译缓存中,在第一预设时长内的调用频次大于0的第一组件的编译缓存,或者在第二预设时长内的调用频次排序高于预设排序的其他组件的编译缓存迁移到第一存储器中。
13、可以看出在本技术实施例中,将依赖库中的第一组件,和与第一组件存在依赖关系的依赖组件分别按照不同的方法存储在第一存储器和第二存储器上,将在第一预设时长内的调用频次大于0的第一组件的编译缓存和在第二预设时长内的调用频次排序高于预设排序的其他依赖组件的编译缓存存储在读取速率较高第一存储器中。将在第一预设时长内的调用频次不大于0的第一组件的编译缓存和在第二预设时长内的调用频次排序低于于预设排序的其他依赖组件的编译缓存存储在读取速率较低第二存储器中。合理分配了存储器的存储空间,并根据实际的调用情况对不同的编译缓存进行转移存储,提高了存储器的利用率,提高了组件的生成效率并节省了组件的存储成本。
14、第二方面本技术实施例提供了一种组件生成装置,该装置用于执行组件生成方法,该组件生成装置包括:
15、获取单元:用于从发布端获取第一工程,在第一工程中添加第一组件;
16、打包单元:用于发送打包指令,生成第一组件的二进制组件,并将包含二进制组件的第二工程推送到发布端,其中,二进制组件为第一组件的二进制表现形式。
17、第三方面,本技术实施例提供了一种电子设备,包括处理器、存储器、通信接口,以及一个或多个程序,所述一个或多个程序被存储在所述存储器中,并且被配置由处理器执行,所述一条或多条指令适于由所述处理器加载并执行如第一方面的方法的部分或者全部。
18、第四方面,本技术实施例提供了一种计算机可读存储介质,其存储用于电子数据交换的计算机程序,其中,计算机程序使得计算机执行如第一方面的方法的部分或者全部。
- 还没有人留言评论。精彩留言会获得点赞!