一种交通场景多目标检测方法及装置与流程
1.本发明涉及目标检测技术领域,具体提供一种交通场景多目标检测方法及装置。
背景技术:
2.随着经济与科技的快速发展,汽车逐渐走入家家户户,给人们生活带来了极大便利,但一系列道路交通拥堵、交通事故等问题也接踵而至。近年来,为了保证驾驶安全,自动驾驶成为了各大汽车公司的研究热点,如何针对城市道路等复杂场景设计高实时性的目标检测系统成为了重点突破方向。研究适用于交通场景的目标检测系统对于辅助驾驶系统具有重大意义,可以有效缓解交通事故,降低驾驶员因车速过快、疲劳驾驶等引发的安全隐患,保证人们的生命财产安全。
3.深度学习的发展为自动驾驶技术中的目标检测系统带来了相当便利,但依然还存在许多挑战与难点,交通场景复杂多变,受角度、光照,目标姿态、尺度、遮挡等不利因素影响,当前大部分算法的鲁棒性不强,难以兼顾检测的实时性与准确率。车载系统往往只有有限的存储和处理空间,对于深度神经网络模型的参数量和计算量有一定的限制,针对移动和嵌入式设备的轻量级网络,虽然进一步减少了网络的参数量,加快网络速度,但这些模型缺乏有效实现。
技术实现要素:
4.本发明是针对上述现有技术的不足,提供一种实用性强的交通场景多目标检测方法。
5.本发明进一步的技术任务是提供一种设计合理,安全适用的交通场景多目标检测装置。
6.本发明解决其技术问题所采用的技术方案是:
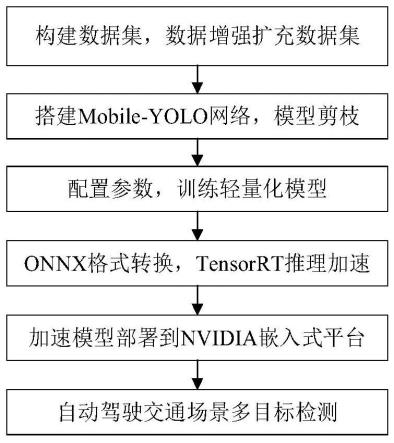
7.一种交通场景多目标检测方法,具有如下步骤:
8.s1、构建交通场景检测目标数据集;
9.s2、搭建mobile-yolo交通目标检测网络,深层网络层标准卷积更改为深度可分离卷积,对模型进行剪枝操作,除去权重低的通道;
10.s3、配置训练参数,训练检测模型,得到轻量级模型;
11.s4、轻量级模型转化为为onnx格式,输入tensorrt框架进行网络层和张量融合,半精度或整型推理加速;
12.s5、将加速模型部署到nvidia嵌入式平台;
13.s6、获取交通场景中的待检测图像,输入步骤s5嵌入式平台中的加速模型进行交通目标识别检测,输出检测结果信息。
14.进一步的,在步骤s1中,所述数据集基于bdd100k数据库,筛选归并待检测目标类别,并使用数据增强技术对原始图像进行平移、旋转和翻转处理来扩充数据集。
15.进一步的,在步骤s2中,mobile-yolo交通场景目标检测网络基于yolov5框架进行
构建,包括backbone,neck,head三部分;
16.主干网络backbone选用轻量化mobilenetv3网络进行特征提取;
17.nect部分将网络中普通卷积替换成深度可分离卷积以进一步减少网络参数量,利用spp模块以5
×
5、9
×
9和13
×
13的最大池化来融合不同尺度大小的特征图,利用自顶向下的fpn特征金字塔及自底向上的pan特征金字塔来提升网络的特征提取能力;
18.head输出端采用eiou_loss做bounding box的损失函数。
19.进一步的,在步骤s2中,mobile-yolo的网络骨干mobilenetv3在v2版本block的基础上引入通道注意力机制se模块,使用新的h-swish激活函数;
20.利用全局平均池化将网络末端的卷积改为1
×
1的卷积。
21.进一步的,在步骤s2中,eiou_loss是在ciou_loss的基础上分别计算宽高的差异值取代了纵横比,同时引入了focal loss优化了边界框,公式为:
22.l
focal_eiou
=iou
γ
l
eiou
23.其中γ为控制异常值抑制程度的参数,iou越高的损失越大;
24.eiou_loss损失函数包含三个部分重叠损失、中心距离损失和宽高损失,重叠损失和中心距离损失延续ciou_loss,新增宽高损失直接使目标框与锚框的宽度和高度之差最小,加快收敛速度:
[0025][0026]
其中,b和b
gt
分别代表预测框b和目标框b
gt
的中心点,hw和hc是覆盖两个框的最小外接框的宽度和高度。
[0027]
进一步的,对模型进行剪枝操作时,在bn层中,给每个通道引入缩放因子α,代表对应通道的激活程度,对参数进行稀疏正则化训练,使冗余通道比例因子在训练中趋向于0或等于0,计算公式为:
[0028][0029]zin
为输入,z
out
为输出;μc和σc分别为输入激活值的均值和方差;
[0030]
α和β分别为对应激活通道的缩放系数和偏移系数;
[0031]
在损失函数中添加惩罚因子,对bn层的缩放系数进行约束,得到最终损失函数:
[0032]
loss=l
focal_eiou
+λσr(φ)
[0033]
λ是正则化系数,数值越大,约束力度越大,g(φ)是针对尺度因子φ的稀疏惩罚;
[0034]
稀疏处理后,基于函数sort(
·
)对所有的尺度因子φ进行统计和排序,生成剪枝阈值:θ=sort(φ),然后移除小于设定阈值对应的次要通道;
[0035]
最后通过模型微调来弥补精度损失,并经过性能评估后再进行修剪迭代,得到轻量级模型。
[0036]
进一步的,在步骤s4中,轻量级模型转化为tensorrt可以读取的onnx形式,mobile-yolo基于pytorch框架实现,通过pytorch框架自带模块torch.onnx一键转化即可。
[0037]
进一步的,构建的tensorrt加速器处理过程中,轻量级模型通过网络层及张量融合、低精度或整型推理进行推理加速,具体步骤包括:
[0038]
通过横向合并,将参数相同的convolution层、bias层和relu层组合成一个更宽的cbr层;通过纵向合并,将网络结构相同但参数不同的层组合成一个cbr层;
[0039]
将模型在训练过程中使用的fp32张量降低为精度更低的fpl6及int8精度。
[0040]
进一步的,在步骤s5中,选用nvidia xavier nx嵌入式平台,搭载了48个tensor core的384核nvidia volta
tm
gpu,可利用nvidia软件堆栈以低至10瓦的功率开发多模态ai应用程序。
[0041]
一种交通场景多目标检测装置,包括:至少一个存储器和至少一个处理器;
[0042]
所述至少一个存储器,用于存储机器可读程序;
[0043]
所述至少一个处理器,用于调用所述机器可读程序,执行一种交通场景多目标检测方法。
[0044]
本发明的一种交通场景多目标检测方法及装置和现有技术相比,具有以下突出的有益效果:
[0045]
本发明利用模型重构和模型剪枝对模型参数量进行压缩,然后再部署到嵌入式设备jetson xavier nx上,使用tensor rt以fpl6及int8的优化精度对模型进行快速推理,计算量和参数量都大大减少,实现移动端的车辆行人等的实时检测,为后续轻量化目标检测系统在自动驾驶平台进行快速和高效的部署推理提供可能。
附图说明
[0046]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0047]
附图1是一种交通场景多目标检测方法的流程示意图;
[0048]
附图2是一种交通场景多目标检测方法中mobile-yolo网络结构图;
[0049]
附图3是一种交通场景多目标检测方法中模型剪枝流程图;
[0050]
附图4是一种交通场景多目标检测方法中tensorrt推理加速层间融合示意图。
具体实施方式
[0051]
为了使本技术领域的人员更好的理解本发明的方案,下面结合具体的实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例都属于本发明保护的范围。
[0052]
下面给出一个最佳实施例:
[0053]
如图1所示,本实施例中的一种交通场景多目标检测方法,具有如下步骤:
[0054]
s1、构建交通场景检测目标数据集;
[0055]
其中,数据集基于bdd100k数据库,目前最大、最多样化的开放驾驶视频数据集。筛选归并待检测目标类别:行人、车辆(小汽车、公共汽车、自行车、摩托车)、交通(标志及信号灯);并使用数据增强技术对原始图像进行平移,旋转和翻转处理来扩充数据集。数据集涵盖不同的天气条件:晴天、阴天和雨天,以及不同的时间:白天和晚上,能让模型能够识别多种场景,具备更多的泛化能力。
[0056]
s2、搭建mobile-yolo交通目标检测网络,深层网络层标准卷积更改为深度可分离卷积,对模型进行剪枝操作,除去权重低的通道;
[0057]
如图2所示,mobile-yolo交通场景目标检测网络基于yolov5框架进行构建,包括backbone,neck,head三部分,主干网络backbone选用轻量化mobilenetv3网络进行特征提取;
[0058]
nect部分将网络中普通卷积替换成深度可分离卷积以进一步减少网络参数量,利用spp模块以5
×
5、9
×
9和13
×
13的最大池化来融合不同尺度大小的特征图,利用自顶向下的fpn特征金字塔及自底向上的pan特征金字塔来提升网络的特征提取能力。
[0059]
head输出端采用eiou_loss做bounding box的损失函数。
[0060]
mobile-yolo的网络骨干mobilenetv3在v2版本block的基础上引入通道注意力机制se模块,使用新的h-swish激活函数;利用全局平均池化将网络末端7
×
7的卷积改成1
×
1,再次减小了网络参数量。
[0061]
eiou_loss是在ciou_loss的基础上分别计算宽高的差异值取代了纵横比,解决了纵横比的模糊定义,同时引入了focal loss优化了边界框回归任务中的样本不平衡问题,有效缓解密集及拥挤场景存在的漏检问题:
[0062]
l
focal_eiou
=iou
γ
l
eiou
[0063]
其中γ为控制异常值抑制程度的参数,iou越高的损失越大。
[0064]
eiou_loss损失函数包含三个部分重叠损失、中心距离损失和宽高损失,前两个损失延续ciou_loss,新增宽高损失直接使目标框与锚框的宽度和高度之差最小,加快收敛速度:
[0065][0066]
其中,b和b
gt
分别代表预测框b和目标框b
gt
的中心点,hw和hc是覆盖两个框的最小外接框的宽度和高度。
[0067]
如图3所示,模型剪枝操作具体包括:在bn层中,给每个通道引入缩放因子α,代表对应通道的激活程度,对参数进行稀疏正则化训练,使冗余通道比例因子在训练中趋向于0或等于0,计算公式为:
[0068]
[0069]zin
为输入,z
out
为输出;μc和σc分别为输入激活值的均值和方差;α和β分别为对应激活通道的缩放系数和偏移系数;
[0070]
在损失函数中添加惩罚因子,对bn层的缩放系数进行约束,得到最终损失函数:
[0071]
loss=l
focal_eiou
+λ∑r(φ)
[0072]
λ是正则化系数,数值越大,约束力度越大,g(φ)是针对尺度因子φ的稀疏惩罚。
[0073]
稀疏处理后,基于函数sort(
·
)对所有的尺度因子φ进行统计和排序,生成剪枝阈值:θ=sort(φ),然后移除小于设定阈值对应的次要通道;
[0074]
最后通过模型微调来弥补精度损失,并经过性能评估后再进行修剪迭代,得到轻量级模型。
[0075]
s3、配置训练参数,训练检测模型,得到轻量级模型;
[0076]
s4、轻量级模型转化为为onnx格式,输入tensorrt框架进行网络层和张量融合,半精度或整型推理加速;
[0077]
轻量化模型需转化为tensorrt可以读取的onnx形式,mobile-yolo是基于pytorch框架实现的,通过框架自带模块torch.onnx一键转化即可。
[0078]
构建的tensorrt加速器处理过程中,轻量级模型通过网络层及张量融合、低精度/整型推理等进行推理加速,具体步骤包括:
[0079]
通过横向合并,将参数相同的convolution层、bias层和relu层组合成一个更宽的cbr层;通过纵向合并,将网络结构相同但参数不同的层组合成一个cbr层。使用的tensorrt推理加速层间融合策略如图4所示,整个模块的层数极大地减少。
[0080]
将轻量级模型在训练过程中使用的fp32张量降低为精度更低的fpl6及int8精度,更低的数据精度内存占用更小,模型的参数量也更小。
[0081]
s5、将加速模型部署到nvidia嵌入式平台;
[0082]
选用nvidia xavier nx嵌入式平台,一款功能强大的嵌入式ai计算设备,其性能是上一代jetson tx2的10倍以上,搭载了48个tensor core的384核nvidia volta
tm
gpu,可利用nvidia软件堆栈以低至10瓦的功率开发多模态ai应用程序。
[0083]
s6、获取交通场景中的待检测图像,输入步骤s5嵌入式平台中的加速模型进行交通目标识别检测,输出检测结果信息。
[0084]
基于上述方法,本实施例中的一种交通场景多目标检测装置,包括:至少一个存储器和至少一个处理器;
[0085]
至少一个存储器,用于存储机器可读程序;
[0086]
至少一个处理器,用于调用所述机器可读程序,执行一种交通场景多目标检测方法。
[0087]
上述具体的实施方式仅是本发明具体的个案,本发明的专利保护范围包括但不限于上述具体的实施方式,任何符合本发明的一种交通场景多目标检测方法及装置权利要求书的且任何所述技术领域普通技术人员对其做出的适当变化或者替换,皆应落入本发明的专利保护范围。
[0088]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1