一种基于transformer的维汉机器翻译方法与流程
1.本发明属于语言翻译技术领域,更具体地说,特别涉及一种基于 transformer的维汉机器翻译方法。
背景技术:
2.目前语言翻译主要依靠机器进行翻译,机器翻译即是利用计算机将源语言自动转换为目标语言的技术,维吾尔语与汉语间相互翻译的需求越发明显,目前常用的翻译方法为统计机器翻译和神经机器翻译,神经机器翻译对英语与法语、英语与德语等资源丰富的语言对的翻译性能显著优于统计机器翻译,但由于维吾尔语-汉语平行语料缺乏以及语言差异较大,因此在维吾尔语-汉语的翻译性能上神经机器并不如统计机器翻译。
3.神经机器翻译技术一般通过循环神经网络的编码器将源端语句编码为一个稠密的特征向量,然后使用解码器将该向量解码为目标端语句,此外通过长短时记忆和注意力机制等方法能有效处理长距离依赖问题,并捕获需要生成的目标词汇;
4.但是不同于汉语和英语等常见孤立语和曲折语,维吾尔语具有黏着性的特点,语言形态变化十分丰富,词干连接不同构形词缀进行形态变化,其表示以词干意义为主的不同语法功能,并且词缀还可以进行多层连接,维吾尔语词汇可由词干连接多个词缀来表达丰富的语义,因此维吾尔语单词往往能够表达汉语中短语或者短句的意义,这个特点导致维吾尔语单词数量非常庞大,若采用统计机器学习的方法工作量大,翻译质量较差。
5.于是,有鉴于此,针对现有的结构及缺失予以研究改良,提供一种基于 transformer的维汉机器翻译方法,以期达到更具有更加实用价值性的目的。
技术实现要素:
6.为了解决上述技术问题,本发明提供一种基于transformer的维汉机器翻译方法,以解决现在的维吾尔语单词数量非常庞大,采用统计机器学习的方法工作量大,翻译质量较差的问题。
7.本发明基于transformer的维汉机器翻译方法的目的与功效,由以下具体技术手段所达成:
8.一种基于transformer的维汉机器翻译方法,所述基于transformer的维汉机器翻译方法主要由编码器和解码器组成翻译模型,所述翻译方法包括以下步骤:
9.s1:通过用户在翻译软件中输入需要翻译的维语文本;
10.s2:基于transformer的维汉机器翻译模型中的所述编码器获取维语文本的每一个单词,并以向量x表示,其中x由单词的词嵌入和单词位置的词嵌入相加得到,单词向量矩阵用x
n*d
表示,n是句子中单词个数,d是表示向量的维度;
11.s3:将步骤s2中得到的单词表示向量x矩阵传入所述编码器中,经过编码器后可以得到句子所有单词的编码信息矩阵c;
12.s4:将步骤s3中输出的编码信息矩阵c传递到所述解码器中,所述解码器依次会根
据当前翻译过的前i单词翻译第i+1个单词;
13.s5:通过词粒度对翻译文本进行检测,以识别出中文本中错误;
14.s6:将步骤s5中的翻译错误的句子修正,然后所述解码器基于softmax函数输出最相关的汉语单词。
15.优选的,步骤s2中,在编码器处给一个长度为m的输入序列,从一个矩阵开始,这个矩阵的行被初始化为d维,用来表示序列h0∈r
m*d
的每个位置的符号的d维嵌入;
16.翻译模型中注意力计算有三个输入向量,q表示查询向量、k表示键向量、 v表示值向量,计算公式attention(scaleddot-productattention,缩放点积注意力)为:
[0017][0018]
然后使用多头自注意力机制迭代地并行计算t步中m个位置的表示h
t
,得到一个transition函数,并在每个功能块添加残差连接,应用了dropout和层归一化,得到:
[0019]
multiheadsel fattention(h
t
)=concat(head1,
…
,headk)woꢀꢀꢀ
(2)
[0020]
headi=attention(h
twiq
,h
twik
,h
twiv
)
ꢀꢀꢀ
(3)
[0021]
其中d是q、k、v的列数,利用k头注意力,以及学习到的参数矩阵 wq∈rd×
djk
、wk∈rd×
djk
、wv∈rd×
djk
和wo∈rd×d来将h
t
映射到q,k,v中,在 t步中,使用下面的式子来修正m个输入位置h
t
∈rm×d的表征:
[0022]ht
=laynorm(a
t
+transition(a
t
))
ꢀꢀꢀ
(4)
[0023]at
=laynorm(h
t-1
+p
t
)+multiheadselfattention(h
t-1
+p
t
)
ꢀꢀꢀ
(5)
[0024]
transition函数为可分离的卷积或全连接的神经网络,这个神经网络包含了一个在两个仿射变换之间的用于校正的线性激活函数,并且应用于a
t
的每一行。
[0025]
优选的,所述p
t
∈rm×d是固定的、恒定的二维坐标嵌入,通过分别计算每一个向量维度1≤j≤d在位置1≤i≤m和时间步1≤t≤t的正弦位置嵌入向量,编码器的最终输出是输入序列的m个符号的d维向量表示矩阵h
t
∈rm×d。
[0026]
优选的,所述解码器部分有着和所述编码器相同的基本递归结构,所述解码器使用multiheadsel fattention(h
t
)=concat(head1,
…
,headk)wo多头注意力函数来关注输入序列中每一个位置最后的编码器表示矩阵h
t
,其中q来自解码器, k、v来自编码器,并使用teacher-forcing进行训练。
[0027]
其中基于teacher-forcing进行训练,在数据生成时,解码器一次产生一个符号,解码器会消耗先前产生的输出位置;在训练期间,解码器的输入是来自输入的target值,从左至右移动,最后,每个输出位置符号的目标分布的生成方式是将最终解码器的状态进行一个仿射变换o∈rd×v,转换到大小为v的输出词汇表中,然后使用softmax生成一个(m
×
v)维的输出矩阵,并对其进行标准化得到的:
[0028]
p(y
pos
|y
[1:pos-1]
,h
t
)=softmax(oh
t
)1ꢀꢀꢀ
(6)
[0029]
模型生成结果的方式是,编码器首先会对输入序列运行一次,然后解码器反复地运行,消耗所有已经生成的符号,同时在每次迭代的下一个输出位置上为符号在词汇表上生成一个分布,我们通常抽样或选择概率最高的符号作为下一个符号。
[0030]
优选的,基于transformer翻译模型中为每个步骤添加一个动态act自适应时间机制。
[0031]
优选的,所述act用于根据模型为每个步骤预测标量停止概率,动态调节标准递归神经网络中用于处理每个输入符号所需的计算步骤数;
[0032]
在序列处理系统中,确定的符号(比如单词或者音素)通常比其他符号更加模棱两可,因此给这些符号分配更多的资源是合理的,一旦每个符号循环块停止,它的状态就被简单地复制到下一步,直到所有块停止,或者我们达到最大步数。
[0033]
优选的,步骤s5中,词粒度检测过程中,基于n-gram语言模型,其中n-gram 语言模型中一个字符的概率只取决于紧接在前面的那个词,字符串的概率由如下一系列条件概率的乘积近似:
[0034][0035]
上式中每一项的概率可由最大似然估计计算:
[0036][0037]
其中,n(c
l-1
,c
l
)和n(c
l-1
),分别表示字符串“c
l-1
,c
l”和“c
l-1”在给定语料库中出现的次数
[0038]
与现有技术相比,本发明具有如下有益效果:
[0039]
1.本发明通过在现有统计机器翻译的基础上,首先使用回译的方法进行数据增强,然后利用训练好的汉维翻译transformer模型,从维语的单语语料中取出一部分来反向翻译得到维语数据,从而获得额外的双语数据,以此解决现在的维吾尔语单词数量非常庞大,采用统计机器学习的方法工作量大,翻译质量较差的问题。
[0040]
2.本发明通过基于n-gram语言模型对字符串进行检测,通过利用词粒度进行错误检测,实现及时发现并纠正,错误检测定位所有的疑似错误后,取所有疑似错字的音拟、形拟候选词,使用候选词替换,我们使用得分最高的p(c) 值对应的二元组词作为正确的字符串来覆盖旧的字符串,以此完成纠错得到最优纠正词。
附图说明
[0041]
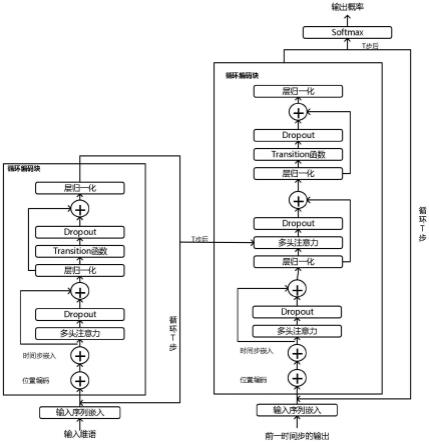
图1是本发明transformer的维汉机器翻译模型结构示意图。
[0042]
图2是本发明翻译流程运行示意图。
具体实施方式
[0043]
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例用于说明本发明,但不能用来限制本发明的范围。
[0044]
如图1至图2所示:
[0045]
本发明提供一种基于transformer的维汉机器翻译方法,通过在现有统计机器翻译的基础上,首先使用回译的方法进行数据增强,然后利用训练好的汉维翻译transformer模型,从维语的单语语料中取出一部分来反向翻译得到维语数据,从而获得额外的双语数据;其次对于未登录词,目前通常需要去查稀有词汇表,但因为一个词可能对应多个意思,
导致在实际场景中并不知道改用哪个,因此通过引入字节对编码技术用来解决未登录词的问题,字节对编码分词通过不断合并出现次数最多的字符对来捕捉这种可能识别的字词,从而克服未登录词问题。
[0046]
模型结构如图1所示,transformer翻译模型由循环编码块与循环解码块组成,循环编码块由两个子层构成,多头注意力层和transition层,子层之间进行层归一化后,再通过残差连接,循环解码块相比于解码块多了一层多头注意力层;
[0047]
通过将集成了act可以动态调整输入符号处理次数、循环神经网络的循环归纳偏置的以及transformer可以并行处理的特点的模型用于维汉翻译。
[0048]
实施例一:
[0049]
第一步,通过用户在翻译软件中输入需要翻译的维语文本,然后基于 transformer翻译模型对维语文本中的句子进行标记和分解。
[0050]
第二步,然后transformer翻译模型中编码器获取输入句子中每一个单词的表示向量x,表示向量x由单词的词嵌入和单词位置的词嵌入相加得到,单词向量矩阵用xn×d表示,n是句子中单词个数,d是表示向量的维度,用以编码器可以快速识别出维语文本中单词,并进行快速翻译;
[0051]
第三步,在编码器处给一个长度为m的输入序列,从一个矩阵开始,这个矩阵的行被初始化为d维,用来表示序列h0∈r
m*d
的每个位置的符号的d维嵌入;
[0052]
翻译模型中注意力计算有三个输入向量,q表示查询向量、k表示键向量、v表示值向量,计算公式attention(scaleddot-productattention,缩放点积注意力)为:
[0053][0054]
然后使用多头自注意力机制迭代地并行计算t步中m个位置的表示h
t
,得到一个transition函数,并在每个功能块添加残差连接,应用了dropout和层归一化,得到:
[0055]
multiheadsel fattention(h
t
)=concat(head1,
…
,headk)woꢀꢀꢀ
(2)
[0056]
headi=attention(h
twiq
,h
twik
,h
twiv
)
ꢀꢀꢀ
(3)
[0057]
其中d是q、k、v的列数,利用k头注意力,以及学习到的参数矩阵 wq∈rd×
djk
、wk∈rd×
djk
、wv∈rd×
djk
和wo∈rd×d来将h
t
映射到q,k,v中,在 t步中,使用下面的式子来修正m个输入位置h
t
∈rm×d的表征:
[0058]ht
=laynorm(a
t
+transition(a
t
))
ꢀꢀꢀ
(4)
[0059]at
=laynorm(h
t-1
+p
t
)+multiheadselfattention(h
t-1
+p
t
)
ꢀꢀꢀ
(5)
[0060]
transition函数为可分离的卷积或全连接的神经网络,这个神经网络包含了一个在两个仿射变换之间的用于校正的线性激活函数,并且应用于a
t
的每一行。
[0061]
所述p
t
∈rm×d是固定的、恒定的二维(位置、时间)坐标嵌入,通过分别计算每一个向量维度1≤j≤d在位置1≤i≤m和时间步1≤t≤t的正弦位置嵌入向量,编码器的最终输出是输入序列的m个符号的d维向量表示矩阵 h
t
∈rm×d;从而以此获得编码信息矩阵c。
[0062]
第四步,将编码信息矩阵c传递到解码器中,transformer翻译模型中的解码器部分有着和所编码器相同的基本递归结构,解码器使用 multiheadsel fattention(h
t
)=concat(head1,
…
,headk)wo多头注意力函数来关注输入序列中每一个位置最后的编码器表示矩阵h
t
,其中q来自解码器,k、v来自编码器,并使用teacher-forcing进行训练。
[0063]
其中基于teacher-forcing进行训练,在数据生成时,解码器一次产生一个符号,解码器会消耗先前产生的输出位置;在训练期间,解码器的输入是来自输入的target值,从左至右移动,最后,每个输出位置符号的目标分布的生成方式是将最终解码器的状态进行一个仿射变换o∈rd×v,转换到大小为v的输出词汇表中,然后使用softmax生成一个(m
×
v)维的输出矩阵,并对其进行标准化得到的:
[0064]
p(y
pos
|y
[1:pos-1]
,h
t
)=softmax(oh
t
)1ꢀꢀꢀ
(6)
[0065]
模型生成结果的方式是,编码器首先会对输入序列运行一次,然后解码器反复地运行,消耗所有已经生成的符号,同时在每次迭代的下一个输出位置上为符号在词汇表上生成一个分布,我们通常抽样或选择概率最高的符号作为下一个符号。
[0066]
解码器基于teacher-forcing进行训练成熟后,当编码信息矩阵c传输到解码器中后,解码器依次会根据当前翻译过的前i单词翻译第i+1个单词,从而实现对维语的快速翻译,实现从维语的单语语料中取出一部分来反向翻译得到维语数据,从而获得额外的双语数据,以此解决现在的维吾尔语单词数量非常庞大,采用统计机器学习的方法工作量大,翻译质量较差的问题。
[0067]
第五步,通过词粒度对翻译文本进行检测,以查找出其中的错误,然后通过解码器输出最合适的汉语单词;
[0068]
其中在序列处理系统中,确定的符号(比如单词或者音素)通常比其他符号更加模棱两可,因此给这些符号分配更多的资源是合理的;因此基于 transformer翻译模型中为每个步骤添加一个动态act自适应时间机制,通过act用于根据模型为每个步骤预测标量停止概率,动态调节标准递归神经网络中用于处理每个输入符号所需的计算步骤数;在transformer中为每个位置添加了一个动态act停止机制,一旦每个符号循环块停止,它的状态就被简单地复制到下一步,直到所有块停止,或者我们达到最大步数。
[0069]
实施例二:
[0070]
目前很多维语到汉语使用的是音译的方法,因此在翻译时存在谐音字词、混淆音字词、字词顺序颠倒、形似字错误、中文拼音全拼、中文拼音缩写和语法错误等问题;
[0071]
为了解决这些问题,本发明使用了基于n-gram语言模型对字符串进行检测,通过利用词粒度进行错误检测,实现及时发现并纠正;
[0072]
对于给定的中文字符串c=c1,c2,
…
,c
l
,若句子有任何错误,错误词就会出现在连续的单个词中,经过中文分词后就会出现错误词;n-gram语言模型中一个字符的概率只取决于紧接在前面的那个词,其中字符串的概率由如下一系列条件概率的乘积近似:
[0073][0074]
上式中每一项的概率可由最大似然估计计算:
[0075][0076]
其中,n(c
l-1
,c
l
)和n(c
l-1
),分别表示字符串“c
l-1
,c
l”和“c
l-1”在给定语料库中出现的次数。
[0077]
通过错误检测定位所有的疑似错误后,取所有疑似错字的音拟、形拟候选词,使用候选词替换,我们使用得分最高的p(c)值对应的二元组词作为正确的字符串来覆盖旧的字符串,以此完成纠错得到最优纠正词。
[0078]
本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1