一种基于访问日志的ABAC策略提取及优化方法
本发明涉及访问控制,具体为一种基于访问日志的abac策略提取及优化方法。
背景技术:
1、随着边缘计算、社会网络、区块链等新兴计算与信息技术的飞速发展,传统访问控制模型不能满足细粒度以及实际应用场景的功能需求;基于属性的访问控制(attribute-based access control,abac)提供了一种灵活解决复杂、动态系统授权需求的方法;为了成功实施abac机制,确定一个合适的授权策略并构建一个好的abac系统显得非常重要;为此,提出了基于abac的策略工程技术,以及自顶向下与自底向上两种构造方法;相比于耗时、费力且容易出错的自顶向下人工处理方式,自底向上方法采用自动化或半自动化方式挖掘策略规则,将非abac模型迁移至abac系统,能够降低成本、时间以及策略开发与管理等方面的差错,近年来在学术界和工业界均得到了广泛关注与深入研究;
2、自底向上策略工程方法又称策略挖掘,是由kuhlmann等人最早提出并使用数据挖掘技术从给定的权限分配关系中构造角色集,称之为角色挖掘;尽管提出了大量角色挖掘方法,但它们并不适用于abac策略的提取;为此,xu和stoller从给定访问控制日志(或列表)及其实体的属性数据集出发,首次提出abac策略研究问题及其挖掘方法;之后,研究者们相继提出了各种不同的策略工程方法;然而,现有些方法存在以下主要问题:(1)abac策略规则既包含肯定条件,还可以包含否定条件,使用否定属性条件可以使得授权策略变得更加灵活、方便;然而,现有方法不支持带否定条件的策略挖掘;(2)abac策略规则应尽可能简洁、准确,不一致或错误的策略决定将导致原先被授权的访问请求被拒绝,或者原先未被授权的请求被允许;然而,现有方法未对初始挖掘的策略进行优化处理,存在大量冗余和错误的策略规则。
技术实现思路
1、本发明的目的在于提供一种基于访问日志的abac策略提取及优化方法,本发明对于给定的包含用户访问请求及系统授权决定的访问日志集,使用聚类划分技术确定初始策略规则数,能够降低策略提取规模;支持如肯定型、否定型的属性条件,从而使策略描述更加灵活方便,增强了策略的可解释性。
2、本发明的目的可以通过以下技术方案实现:
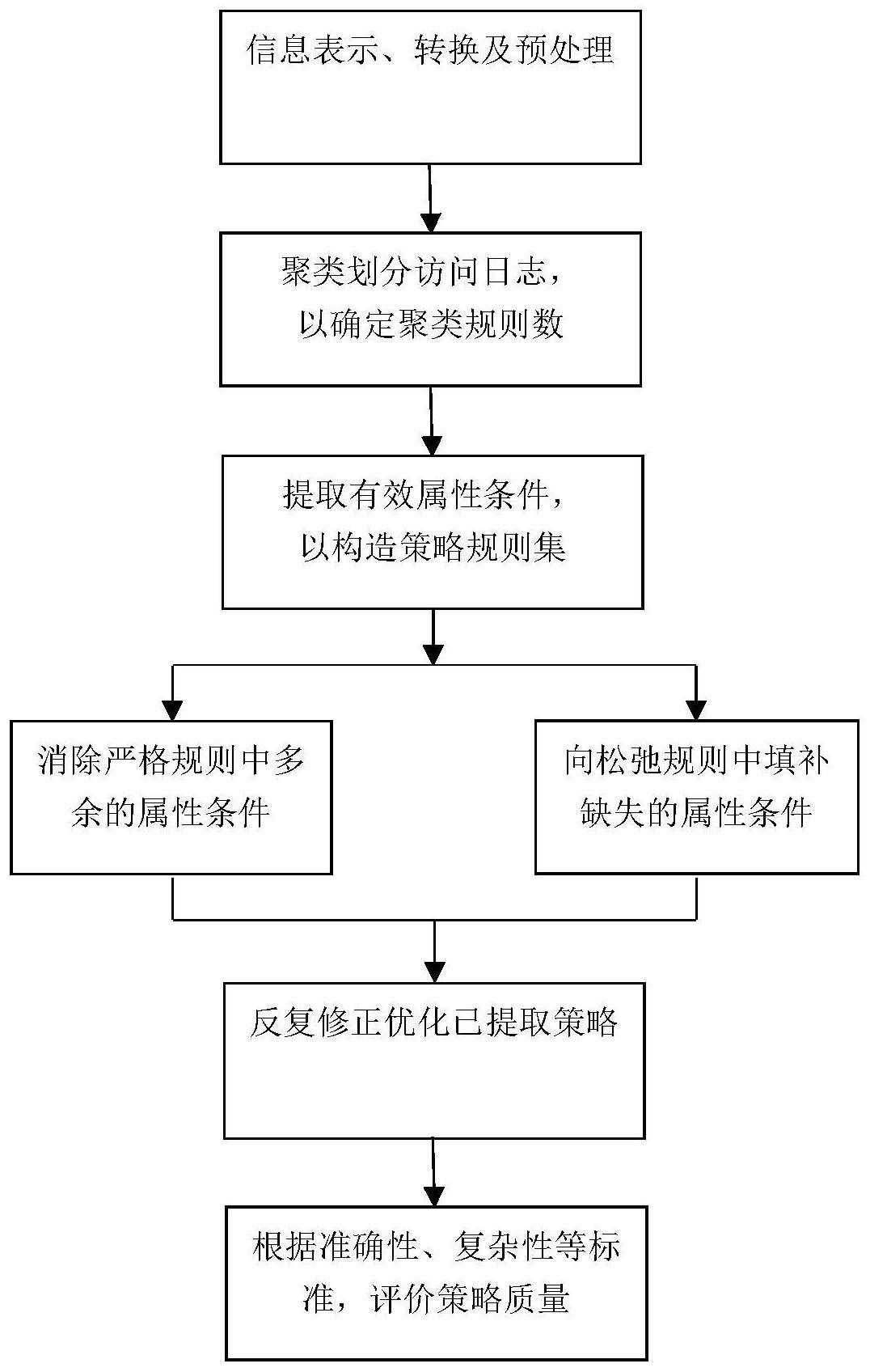
3、一种基于访问日志的abac策略提取及优化方法,包括以下步骤:
4、步骤一,数据预处理:用集合、关系和函数等形式化表示访问日志中的实体及联系,并将所有数值型变量转换成与之对应的分离型变量;
5、步骤二,访问日志的聚类划分:确定与策略规则相关的所有授权访问日志;使用数据挖掘技术将访问日志集划分成不同聚类,使得每个含若干记录的聚类对应一条abac规则;
6、步骤三,规则提取:通过从记录特征,即访问授权元组的属性条件中寻找相似模式,提取每个规则中的属性条件,即不同属性-值对的组合;
7、步骤四,策略优化:相比于原始规则,从访问日志提取的规则存在过于严格或过于松弛的问题;如果提取规则比原始规则包含更多更复杂的属性条件,那么认为它是严格的;相反,如果规则中只包含某些简单的属性条件,那么认为它是松弛的;基于原始访问日志反复修正已提取策略,进一步提高abac策略质量
8、作为本发明进一步的方案:所述步骤一中,数据预处理阶段的具体步骤如下:
9、步骤1a:用u,o,s,op分别表示系统中用户集或主体集,对象集,会话集和操作集;au,ao,as分别表示用户u,对象o,会话s的属性;e,a分别表示系统中所有实体和所有实体属性的集合,其中e=u∪o∪s,a=au∪ao∪as;va表示系统中属性a所有可能取值的集合;fa_e(e,a)表示实体e的属性a的取值函数;
10、步骤1b:用形如<a,□v>的二元组表示属性-值对表达式,其中a为属性名,v为属性值,□={“=”,”!”,”>”,”<”}为关系运算符的集合,表示a与v之间取值关系;例如,<a,=v>表示a可以取值v,称为肯定的属性表达式,简记为<a,v>;<a,!v>表示a可取v之外的值,称为否定的属性表达式;为方便描述,本发明只讨论前两种取值关系,并用ac表示所有属性条件的集合,eav表示所有实体与属性条件之间的分配关系;
11、步骤1c:在abac中,会话属性与时间、地点或访问控制场景等动态因素有关;进行预处理时,将这些连续型属性变量分解成离散类型,访问时间转换成工作时长或非连续工作时间段,以便提取形如<e,a,op,eav,ac>的abac策略π。
12、作为本发明进一步的方案:所述步骤二中,使用聚类技术划分访问日志集al,具体步骤如下:
13、步骤2a:利用与k-means算法相似的围绕中心点划分方法(pam),将访问日志数据集al分割成k个不同的划分c1,c2,…ck,并随机选择聚类划分的k个初始中心点;
14、步骤2b:分别计算任意聚类c的中心点ali到其它非中心点的距离:
15、
16、
17、其中,associate(ali)表示聚类中与中心点ali相关联的所有其它记录;
18、步骤2c:比较dis(ali,associate(ali))与dis(alj,associate(ali)\{alj}∪{ali}),判断是否交换ali与alj,并确定新中心点,使其满足:
19、步骤2d:对于不同的k值,反复运行聚类划分算法并计算模型的准确性与差错率;选择能较好平衡策略准确性与复杂性之间的关系的k值,将其作为初始策略规则数。
20、作为本发明进一步的方案:所述步骤三中,提取每个规则中的属性条件,即不同属性-值对的组合;具体步骤如下:
21、步骤3a:定义有效的肯定或否定属性-值对;称<a,v|!v>为规则ρ对应于聚类ci的有效属性-值对,当且仅当对于给定的阈值tp或tn,属性值v出现在ci日志的频率高于或低于其出现在原始日志集的频率,并将<a,v|!v>添加到授权规则ρ=<ac,op>的属性条件,称为有效属性条件,记为eacρ;所有规则的集合表示为p;
22、步骤3b:根据有效属性条件的定义,对于任意给定的聚类ci,给出有效属性条件的提取过程,如算法1所示;
23、算法1.有效属性条件提取:
24、
25、
26、作为本发明进一步的方案:所述步骤四中,具体步骤如下:
27、步骤4a:将原始访问日志al={<rq,d>}分为肯定型日志和否定型日志:
28、al+={<rq,d>|<rq,d>∈al∧d=permitted};
29、al-={<rq,d>|<rq,d>∈al∧d=denied};
30、al=al+∪al-.
31、其中,<rq,d>表示授权(或访问)记录,它描述了系统对访问请求rq的授权决定d,可以取值”permitted”称之为允许访问或”denied”称之为拒绝访问;
32、步骤4b:根据原始日志al+、al-,以及原始提取策略πm,分别确定“正确的肯定”(tp),“错误的肯定”(fp),“正确的否定”(tn)及“错误的否定”(fn)等类型记录;其中:
33、表示对于al中肯定型日志al+的访问请求rq,π做出的授权决定dπ(rq)也是允许访问;
34、fp∏|al={<rq,d>|<rq,d>∈al-:d∏(rq)=permitted},表示对于al中否定型日志al-的访问请求rq,π做出的授权决定dπ(rq)却是允许访问;
35、tnπ|al={<rq,d>|<rq,d>∈al-:dπ(rq)=denied},表示对于al中否定型日志al-的访问请求rq,π做出的授权决定dπ(rq)也是拒绝访问;
36、fnπ|al={<rq,d>|<rq,d>∈al+:dπ(rq)=denied},表示对于al中允许型日志al+的访问请求rq,π做出的授权决定dπ(rq)却是拒绝访问;
37、步骤4c:以fn与fp记录日志作为训练数据集,分别提取策略模式πfn和πfp;
38、步骤4d:将∏fn、πfp与πm进行比较,从严格规则中消除多余的属性条件,或向松弛规则中添加缺失的属性条件;在每次优化过程中,选择∏m中与∏fn、∏fp具有相似性的规则,并按以下两种方式执行:
39、对于∏fn中任意规则ρi,如果∏m中存在一个与ρi相似的规则ρj,那么将多余的属性条件从ρj中删除;如果∏m中不存在与ρi相似的规则,即ρi是一个缺失的规则,直接将其添加到∏m;
40、对于πfp中任意规则ρi,如果πm中存在一个与ρi相似的规则ρj,那么将缺失的属性条件添加到ρj。
41、作为本发明进一步的方案:所述步骤四中,优化过程如算法2所示:
42、算法2.策略优化
43、
44、
45、本发明的有益效果:
46、(1)对于给定的包含用户访问请求及系统授权决定的访问日志集,使用聚类划分技术确定初始策略规则数,能够降低策略提取规模;
47、(2)支持如肯定型、否定型的属性条件,从而使策略描述更加灵活方便,增强了策略的可解释性;
48、(3)基于正确性和简洁性原则,给出策略质量评价标准,并在构造与真实数据集上验证了本发明的有效性与效率,所提取策略的质量更高,具有有显著的经济和社会效益。
- 还没有人留言评论。精彩留言会获得点赞!