一种基于关系矩阵的文档级关系抽取方法和装置
1.本发明属于自然语言处理技术领域,具体涉及一种基于关系矩阵的文档级关系抽取方法和装置。
背景技术:
2.文档级的关系抽取在自然语言处理过程中至关重要,现有的文档级关系抽取从任务上分为两类,第一类是分类范式,即通过获得实体的嵌入表征后,再对实体之间的嵌入表征进行关系分类,如专利文献cn113723074a公开的一种基于证据检验增强的文档级关系抽取方法,再如专利文献cn114818682a公开的一种基于自适应实体路径感知的文档级实体关系抽取方法。另一类是词汇生成范式,即将文档中提取的实体进行嵌入编码后,依据实体之间的相似度等确定关系类别。
3.以上两类文档级关系抽取任务,在进行关系抽取时,均用到了实体嵌入向量和关系嵌入向量,在实际应用中,当实体和关系比较长时,对应的实体嵌入向量和关系嵌入向量也很长,由于现有的词汇生成范式的模型长度有限,当文档长即包含大量实体和关系时,模型无法实现基于数量多且嵌入向量长的文本进行解码来抽取关系,导致生成的性能远低于基于分类范式的方法,文档级关系抽取效率低。
技术实现要素:
4.鉴于上述,本发明的目的是提供一种基于关系矩阵的文档级关系抽取方法和装置,实现同时兼容分类范式和词汇生成范式的文档级关系的抽取,来提高文档级关系抽取的效率。
5.为实现上述发明目的,实施例提供的一种基于关系矩阵的文档级关系抽取方法,包括以下步骤:
6.获取待抽取的输入文档;
7.对输入文档进行实体序列化,包括:根据文档级抽取的标注数据按照实体在输入文档中出现的顺序,依次在实体的前后位置插入标记实体位置和id占位符,得到序列化实体;
8.根据实体出现顺序构造实体级别的关系矩阵,包括:为关系定义标志符,构建标志符和关系的映射关系,将所有实体的id占位符按照实体出现顺序均作为关系矩阵的横纵坐标,并将实体之间的关系对应的标志符作为关系矩阵中两实体约束位置的元素值;
9.以关系矩阵作为监督标签,以序列化实体作为样本数据,进行监督学习,以优化文档级关系抽取模型的参数;
10.利用文档级关系抽取模型实现文档级关系的抽取,并输出抽取的文档级关系。
11.优选地,在对输入文档进行实体序列化处理时,在实体的前后位置标注相同的唯一id占位符,以标记实体位置,其中,id占位符的索引与实体在输入文档中第一次出现的顺序索引相同。
12.优选地,根据实体出现顺序构造实体级别的关系矩阵时,当实体之间不存在关系时,则在关系矩阵中两实体对应的元素位置记录表示空的其他符号。
13.优选地,所述文档级关系抽取模型为gpt系列的预训练语言模型,以序列化实体作为样本数据,以关系矩阵作为监督标签,基于序列生成关系任务来优化预训练语言模型参数,使得预训练语言模型包含的解码模块能够顺序输出成对的表示实体的id占位符以及表示实体间关系的标志符。
14.优选地,所述文档级关系抽取模型为分类模型,所述分类模型包括嵌入表示模块、语义分割模块以及分类模块,以序列化实体作为样本数据输入至分类模型,经过嵌入表示模块计算得到实体的上下文嵌入表示,并根据实体的上下文嵌入表示构建实体矩阵,该实体矩阵经过语义分割模块编码得到实体语义向量,该实体语义向量经过分类模块计算得到实体间的预测关系,根据实体间的预测关系与关系矩阵中的关系构建损失来优化分类模型的参数,使得分类模型能够根据输入的序列化实体分类输出预测关系。
15.优选地,根据实体嵌入表示构建实体矩阵时,将所有实体的id占位符按照实体出现顺序均作为实体矩阵的横纵坐标,将两个实体的上下文嵌入表示的拼接结果作为两实体约束位置的元素值。
16.优选地,所述嵌入表示模块包括bert模型,分类模块包括至少1个全连接层。
17.优选地,利用文档级关系抽取模型实现文档级关系的抽取,包括:
18.对待抽取的输入文档进行实体序列化处理,以得到序列化实体;
19.将序列化实体输入至参数优化的文档级关系抽取模型,经计算预测实体之间的关系,依据实体之间的关系构建关系矩阵,完成文档级关系抽取。
20.为实现上述发明目的,实施例还提供了一种基于关系矩阵的文档级关系抽取装置,包括:
21.获取单元,用于获取待抽取的输入文档;
22.实体序列化单元,用于对输入文档进行实体序列化,包括:根据文档级抽取的标注数据按照实体在输入文档中出现的顺序,依次在实体的前后位置插入标记实体位置和id的id占位符,得到序列化实体;
23.关系矩阵构建单元,用于根据实体出现顺序构造实体级别的关系矩阵,包括:为关系定义标志符,构建标志符和关系的映射关系,将所有实体的id占位符按照实体出现顺序均作为关系矩阵的横纵坐标,并将实体之间的关系对应的标志符作为关系矩阵中两实体约束位置的元素值;
24.参数优化单元,用于以关系矩阵作为监督标签,以序列化实体作为样本数据,进行监督学习,以优化文档级关系抽取模型的参数;
25.关系抽取单元,用于利用文档级关系抽取模型实现文档级关系的抽取,并输出抽取的文档级关系。
26.与现有技术相比,本发明具有的有益效果至少包括:
27.通过设计符号化的id占位符显示实体在输入文档中的位置以及提出实体级关系矩阵可以显示学习文档中实体的上下文表征,且基于实体级关系矩阵的关系预测可以更好地捕获实体间的信息交互和联系。
28.设计的实体级关系矩阵不仅可以高效地应用于gpt系列的预训练语言模型,同样
适应于bert等遮蔽语言模型,编码获得实体表征向量然后拼为三维实体矩阵后做分类。
29.将输入文档中的实体序列化,以id占位符表示实体,同时以标志符表示实体间的关系,这样在文档级抽取任务中,大大缩减了实体和关系的向量维度,实现同时兼容分类范式和词汇生成范式的文档级关系的抽取,与现有的基于词汇生成的文档级关系抽取模型相比,本发明可以应对更长的文档序列,并产生更好的文档级关系抽取效率。
附图说明
30.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
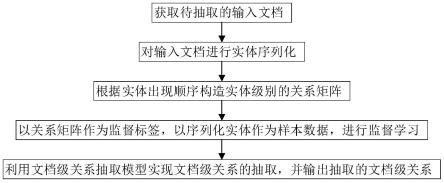
31.图1是实施例提供的基于关系矩阵的文档级关系抽取方法的流程图;
32.图2是实施例提供的文档级关系抽取的示例图;
33.图3是实施例提供的基于关系矩阵的文档级关系抽取装置的结构示意图。
具体实施方式
34.为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
35.实施例提供了一种基于关系矩阵的文档级关系抽取方法和装置,具体通过定义实体id占位符显式提示实体在输入文档中的位置以及出现顺序且因此构造实体级关系矩阵进行关系抽取。基于预先定义的实体级关系矩阵,可以使用生成式模型进行基于符号的序列化的实体关系矩阵预测,这相较于词汇生成范式更高效且性能更加;同时实体级关系矩阵也可以应用于分类模型,即对基于实体表征编码的实体矩阵进行分类预测,相较于传统的关系分类模型,实施例提供的方法能捕获实体间的信息交互和联系以提高抽取性能,即提高关系抽取准确性和效率。
36.图1是实施例提供的基于关系矩阵的文档级关系抽取方法的流程图。如图1所示,实施例提供的基于关系矩阵的文档级关系抽取方法,包括以下步骤:
37.步骤1,获取待抽取的输入文档。
38.实施例中,抽取的输入文档是包含多个实体和关系的文本,其中,实体和关系均可以为单个词汇或者由多个词汇组成的短语。
39.步骤2,对输入文档进行实体序列化。
40.实施例中,对输入文档进行实体序列化时,根据文档级抽取的标注数据按照实体在输入文档中出现的顺序,依次在实体的前后位置插入标记实体位置和id占位符,得到序列化实体。
41.其中,标注数据是指需要标注的实体数据。在对输入文档进行实体序列化处理时,在实体的前后位置标注相同的唯一id占位符,如《e1》,《e2》等等,以标记实体位置,其中,id占位符的索引与实体在输入文档中第一次出现的顺序索引相同。
42.如图2所示,第一方框表示实体序列化文档,在第一个实体“the eminem show”的
前后标记了id占位符《e1》,在第二个实体“eminem”的前后标记了id占位符《e2》。
43.步骤3,根据实体出现顺序构造实体级别的关系矩阵。
44.实施例中,根据实体出现顺序构造实体级别的关系矩阵时,首先,为关系定义标志符,构建标志符和关系的映射关系。该标志符是区别于id占位符的特殊符号,通过为关系定义标志符,这样在抽取过程中基于标志符进行计算,由于标志符相对于关系表示简单,缩短了表示向量长度。
45.然后,将所有实体的id占位符按照实体出现顺序均作为关系矩阵的横纵坐标,如关系矩阵的横纵坐标均表示《e1》,《e2》,
…
《en》,n表示输入文档中按顺序出现的第n个不重复实体,并将实体之间的关系对应的标志符作为关系矩阵中两实体约束位置的元素值。其中,两实体约束位置是指关系矩阵中两个实体交叉的元素坐标位置,即元素坐标为(《ei》,《ej》)处的元素值为实体间关系的标志符。
46.具体地,根据实体出现顺序构造实体级别的关系矩阵时,当实体之间不存在关系时,则在关系矩阵中两实体对应的元素位置记录表示空的其他符号,例如null。
47.示例性地,如图2所示,右侧的关系矩阵中,横纵坐标均为表示实体位置的id占位符《e1》,《e2》,
…
《en》,元素值《6》,《12》,《31》表示关系的标志符。
48.步骤4,以关系矩阵作为监督标签,以序列化实体作为样本数据,进行监督学习。
49.实施例中,在构建关系矩阵和序列化实体的基础上,以关系矩阵作为监督标签,以序列化实体作为样本数据,进行监督学习,以优化文档级关系抽取模型的参数。
50.在一种实施方式中,文档级关系抽取模型为gpt(generative pre-training,生成式的预训练)系列的预训练语言模型,以序列化实体作为样本数据,以关系矩阵作为监督标签,基于序列生成关系任务来优化预训练语言模型参数,使得预训练语言模型包含的解码模块能够顺序输出成对的表示实体的id占位符以及表示实体间关系的标志符。
51.示例性地,如图2所示,中间虚框表示gpt系列的预训练语言模型输出顺序输出成对的表示实体的id占位符以及表示实体间关系的标志符,如《e1》《e2》《6》,表示通过id占位符《e1》和《e2》表示的两实体间的预测关系为标志符《6》。
52.在另一种实施方式中,文档级关系抽取模型为分类模型,该分类模型包括嵌入表示模块、语义分割模块以及分类模块,以序列化实体作为样本数据输入至分类模型,经过嵌入表示模块计算得到实体的上下文嵌入表示,并根据实体的上下文嵌入表示构建实体矩阵,该实体矩阵经过语义分割模块编码得到实体语义向量,该实体语义向量经过分类模块计算得到实体间的预测关系,根据实体间的预测关系与关系矩阵中的关系构建损失来优化分类模型的参数,使得分类模型能够根据输入的序列化实体分类输出预测关系。
53.具体地,根据实体嵌入表示构建实体矩阵时,将所有实体的id占位符按照实体出现顺序均作为实体矩阵的横纵坐标,将两个实体的上下文嵌入表示的拼接结果作为两实体约束位置的元素值。其中,两实体约束位置是指实体矩阵中两个实体交叉的元素坐标位置,即元素坐标为(《ei》,《ej》)处的元素值为两实体上下文嵌入表示的拼接结果,由于拼接结果存在一定维度,所以实体矩阵是一个三维矩阵。
54.其中,嵌入表示模块可以是bert模型,分类模块可以是至少1个全连接层。基于bert模型提取实体的上下文嵌入表示,基于全连接层进行关系分类。
55.步骤5,利用文档级关系抽取模型实现文档级关系的抽取,并输出抽取的文档级关
系。
56.实施例中,利用文档级关系抽取模型实现文档级关系的抽取,包括:
57.首先,对待抽取的输入文档进行实体序列化处理,以得到序列化实体;
58.然后,将序列化实体输入至参数优化的文档级关系抽取模型,经计算预测实体之间的关系,依据实体之间的关系构建关系矩阵,完成文档级关系抽取。
59.基于同样的发明构思,实施例还提供了一种基于关系矩阵的文档级关系抽取装置,如图3所示,包括:
60.获取单元,用于获取待抽取的输入文档;
61.实体序列化单元,用于对输入文档进行实体序列化,包括:根据文档级抽取的标注数据按照实体在输入文档中出现的顺序,依次在实体的前后位置插入标记实体位置和id的id占位符,得到序列化实体;
62.关系矩阵构建单元,用于根据实体出现顺序构造实体级别的关系矩阵,包括:为关系定义标志符,构建标志符和关系的映射关系,将所有实体的id占位符按照实体出现顺序均作为关系矩阵的横纵坐标,并将实体之间的关系对应的标志符作为关系矩阵中两实体约束位置的元素值;
63.参数优化单元,用于以关系矩阵作为监督标签,以序列化实体作为样本数据,进行监督学习,以优化文档级关系抽取模型的参数;
64.关系抽取单元,用于利用文档级关系抽取模型实现文档级关系的抽取,并输出抽取的文档级关系。
65.需要说明的是,上述实施例提供的基于关系矩阵的文档级关系抽取装置在进行基于关系矩阵的文档级关系抽取方法时,应以上述各功能模块的划分进行举例说明,可以根据需要将上述功能分配由不同的功能模块完成,即在终端或服务器的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的基于关系矩阵的文档级关系抽取装置与基于关系矩阵的文档级关系抽取方法实施例属于同一构思,其具体实现过程详见基于关系矩阵的文档级关系抽取方法实施例,这里不再赘述。
66.以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1