基于超图卷积的源代码过程间漏洞检测方法和装置
1.本发明涉及软件分析领域,尤其涉及到软件源代码漏洞检测技术领域,更具体地说涉及一种基于超图卷积的源代码过程间漏洞检测方法和装置。
背景技术:
2.软件程序规模的爆炸式增长,是对软件安全提出的严峻挑战。一方面,软件开发人员话费超过50%的时间检测代码缺陷,他们依靠自动化代码审计工具,通过检测和修复代码漏洞来提高软件代码的安全性和可靠性;另一方面,软件供应链攻击以650%的速率增加。此类攻击通常具有广泛的影响并且难以检测,因为攻击者将漏洞或恶意代码注入受信任供应商的软件源代码中。因此,尽早识别源代码漏洞以确保软件安全至关重要。静态检测已被证明是漏洞或错误检测的有效措施。它可以轻松应用于漏洞检测,因为不需要执行代码,其可以覆盖更广泛的代码错误。尽管已经存在用于代码漏洞检测的静态方法,但目前的静态检测方法误报率仍普遍较高,因为这些方法为了确保检测的性能和扩展能力通常只分析较小范围的漏洞相关代码,这使得检测结果不准确进而无助于提高软件安全性。
3.根据触发漏洞的代码范围软件漏洞可分为过程内漏洞和过程间漏洞。过程内漏洞是代码的交互仅涉及单个程序。由于此类漏洞的相关代码仅在一个过程内,并且处理边界相对简单,因此大量研究集中在处理此类漏洞上,针对此类漏洞已有多个研究成果。然而,一些统计数据表明,过程间漏洞也值得关注。
4.meta公司统计了5个漏洞类型的近100次修复,其中49.9%是跨过程代码漏洞。另一项研究使用infer分析了openssl项目的4002次提交,发现在359192个潜在漏洞中,只有13437个涉及单个过程,而96.26%的漏洞是由多个执行过程引起。这些数据表明,在实际的软件项目中,过程间漏洞不容忽视,其严重威胁着软件的安全。
5.过程间漏洞涉及多个过程,这些过程可能涵盖单个文件中的不同函数,或甚至跨越多个文件中的多个执行函数。因此,在检测过程间漏洞时需要检测模型具有协同分析多个执行过程的能力。但这会带来两个严峻的挑战,挑战1:合理界定漏洞代码涉及的范围很复杂。实际程序通常具有跨越多个执行过程的多个执行路径,而与漏洞相关的代码仅涉及执行路径的一部分,因此很难合理地界定漏洞代码涉及的范围。挑战2:融合分析在多个过程中传递的句法语义信息具有挑战性。直观上一个执行过程内的代码间有很强的关系,多个执行过程的相互交互可以传达更丰富的语义信息。
6.对于挑战1,一种常见的方法是使用与漏洞相关的关键词对程序进行切片,但这在很大程度上取决于关键词库的大小和质量,使得其不能有效界定漏洞所涉及的代码。分离逻辑具有对程序进行过程间分析的特性。基于分离逻辑的漏洞检测器infer可以更好地定位过程间漏洞代码的轨迹,但是其误报率通常较高。
7.对于挑战2,普遍的思路是训练一个有效的模型来捕捉软件代码的语法语义特征。一些工作通过挖掘漏洞代码模式或测试可疑代码与漏洞代码的相似性来检测代码漏洞。
8.然而,这两种方法都只能以粗粒度捕获代码的语法特性,无法达到代码语义的理
解,且其难以应对过程检测分析。另一些工作使用深度学习技术来学习源代码的抽象语法语义信息。输入数据的形态和深度学习模型的选择是这类工作的关键,部分工作抽取代码的执行序列作为输入并配合不同的循环神经网络模型来学习代码的语法语义特性,但是由于代码复杂的特性这类方法通常无法充分地获取代码的语义信息。代码语句之间本身具有复杂的关系,因此一些工作使用图神经网络从更具表现力的代码图结构中学习高阶的代码语法语义特性,但是目前的方法不能有效地处理多个执行过程间交换的信息。总之,有效地界定过程间漏洞涉及的代码范围并准确捕获跨过程的语法语义信息是一项具有挑战的任务,现有的方法不能有效地应对过程间漏洞的检测。
技术实现要素:
9.为了克服上述现有技术中存在的缺陷和不足,本发明提供了一种基于超图卷积的源代码过程间漏洞检测方法和装置。本发明的发明目的在于提供一种基于超图卷积的源代码过程间漏洞检测方法(a code inter-procedural vulnerabilities detection method based on hypergraph convolution简称为hgivul),用于针对软件系统中代码跨过程的漏洞进行检测,以更好地满足代码中复杂漏洞检测的需求,扩展代码漏洞检测的范围,提高源代码漏洞检测的效果,进而为增强代码软件系统的安全提供支撑。
10.为了解决上述现有技术中存在的问题,本发明是通过下述技术方案实现的。
11.本发明第一方面提供了一种基于超图卷积的源代码过程间漏洞检测方法,该检测方法具体包括以下步骤:
12.s1、使用基于分离逻辑的工具对待检测源代码进行过程间分析,并利用基于分离逻辑的工具对待检测源代码中存在的可疑漏洞进行初步定位;
13.s2、根据s1步骤中基于分离逻辑的工具初步定位到的可疑漏洞对应代码的trace重构弱过程间控制流图;
14.s3、将s2步骤重构的弱过程间控制流图中节点代码中所具有的初始特征信息进行向量化表示;具体的,提取节点代码初始的语义信息,并向量化节点代码的语法信息,将节点代码初始的语义信息和语法信息拼接,形成初始化的弱过程间控制流图节点特征信息的向量化表示;
15.s4、首先在s3步骤初始化后的弱过程间控制流图上,进行简单图卷积操作,以捕获过程内代码的特征;然后在s3步骤初始化后的弱过程间控制流图上运用超图卷积以捕获过程间代码的特征,以实现对弱过程间控制流图中多级信息的细粒度捕获;
16.s5、读出经s4步骤卷积操作更新后的弱过程间控制流图的嵌入作为整个图的特征表示,然后将获得的特征表示输入到多层全连接层构建的检测器中进行检测,根据检测器输出的检测结果判断是否存在漏洞。
17.进一步的,s2步骤中,重构弱过程间控制流图具体包括以下子步骤:
18.s201、根据s1步骤中基于分离逻辑的工具初步定位到的可疑漏洞对应代码的trace,定位代码涉及的每一个执行过程,并重构每一个过程的控制流图;
19.s202、根据trace中的代码执行顺序,确定过程间的调用点,然后依据确定的调用点位置在每个调用点增加调入和调出两条连边,将多个过程的控制流图连接起来形成弱过程间控制流图。
20.进一步的,s3步骤中,将s2步骤重构的弱过程间控制流图中节点代码中所具有的初始特征信息进行向量化表示,具体包括:
21.s301、使用词法分析器抽取节点代码中的基本单元,并对基本单元中存在的变量名和函数名进行符号化处理;
22.s302、对符号化处理后的基本单元,使用预先训练好的word2vec模型抽取对应的初始嵌入,捕获代码初始的语义信息;将节点代码中存在的多个基本单元对应的嵌入按相同维度计算平均值,形成节点代码初始的语义嵌入;
23.s303、对节点代码抽取规范的llvm语法树基本单元,每个节点对应的多个规范基本单元构成一个集合;
24.s304、统计每个节点对应的llvm基本单元集合中不同类型基本单元的数量,对每一类基本单元的数量进行归一化处理,然后按特定的基本单元类型顺序进行one-hot编码,形成节点初始的语法嵌入;
25.s305、将s302步骤中获取的节点代码初始的语义嵌入和s304步骤中获取的节点初始的语法嵌入拼接,形成节点初始的特征表示,即初始化的弱过程间控制流图节点特征信息的向量化表示。
26.进一步优选的,s4步骤中,简单图卷积操作,具体是指:
27.将s3步骤初始化后的弱过程间控制流图视为简单图g=(v,e),其中,v表示节点集,e表示边集;初始化后的弱过程间控制流图中所有节点的初始嵌入表示为其中,d表示词嵌入向量的维度,表示是实数集,其维度为|v|
×
|d|;
28.对于节点vi,初始的嵌入表示为k-1次卷积后节点vi的特征嵌入表示为因此节点vi在k次卷积后的特征嵌入表示为
29.具体地,在简单图上进行卷积操作由以下公式计算:
30.式中,n(i)表示节点vi邻居节点的集合,表示对节点vi的任意邻居节点vj,其k-1次卷积后的特征嵌入表示为m(
·
)为聚合均值聚合函数,w表示可训练的权重,σ(
·
)表示激活函数;初始化后的弱过程间控制流图在进行简单图卷积后的特征嵌入表示为x
simple
。
31.在上述简单图卷积操作的基础上,将弱过程间控制流图视为超图gh=(v,eh),其中eh表示超边的集合,对于一条超边e∈eh,e={v1,...,v
p
},vi∈v,2≤p≤|v|,vi表示节点集合v中的第i个节点,v
p
表示节点集合v中的第p个节点;超图上的共现矩阵表示节点集合v中的第p个节点;超图上的共现矩阵表示是实数集,其维度为|v|
×
|eh|,且每个共现矩阵的元素h
(v,e)
定义由以下公式确定:
[0032][0033]
简单图的度矩阵ds是一个对角矩阵是一个对角矩阵表示实数集且其维度为|v|
×
|v|,每个对角元素由以下公式计算:
[0034]
超图的度矩阵dh也是一个对角矩阵也是一个对角矩阵表示实数集且其维度为
|eh|
×
|eh|,每个对角元素由以下公式计算:dh(v,v)=∑
v∈v
h(v,e)。
[0035]
在弱过程间控制流图上进行超图卷积,由以下公式计算:
[0036][0037]
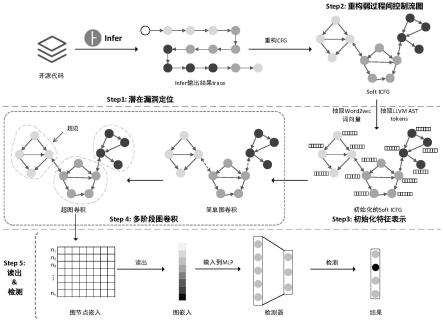
其中,h
t
表示h的转置,令上述公式可简化为:
[0038]
式中,k表示在超图上进行k次卷积,x表示节点特征表示的集合,当k=0时,x0=x
simple
;经以上多级图卷积更新后的节点特征表示为x
′
。
[0039]
更进一步的,所述s5具体包括:
[0040]
s501、读出经s4步骤卷积操作更新后的弱过程间控制流图的嵌入作为整个图的特征表示,按对应维度选用最大值读出方式,具体由以下公式计算:
[0041]
r=max({x
′1,x
′1,
…
,x
′i}),x
′i∈x
′
,其中,r表示整个弱过程间控制流图的特征表示;
[0042]
s502、将获取的特征表示r输入到一个多层全连接网络中进行检测,具体由以下公式计算:
[0043]
式中,表示最终的检测结果,mlp表示多层全连接网络,使用sigmoid函数输出最后的检测结果。
[0044]
更进一步的,所述s1步骤中,利用基于分离逻辑的工具infer对待检测源代码进行初步的过程间分析,基于infer输出的结果初步筛选出潜在的漏洞,初步定位漏洞涉及的范围。
[0045]
本发明第二方面提供一种基于超图卷积的源代码过程间漏洞检测装置,该装置包括:
[0046]
潜在漏洞定位模块,所述潜在漏洞定位模块使用基于分离逻辑的工具对待检测源代码进行过程间分析,并利用基于分离逻辑的工具对待检测源代码中存在的可疑漏洞进行初步定位;
[0047]
重构弱过程间控制流图模块,根据潜在漏洞定位模块初步定位到的可疑漏洞对应代码的trace重构弱过程间控制流图;
[0048]
初始化特征表示模块,用于提取节点代码初始的语义信息,并向量化节点代码的语法信息,将节点代码初始的语义信息和语法信息拼接,形成初始化的弱过程间控制流图节点特征信息的向量化表示;
[0049]
多阶段卷积模块,用于对初始化后的弱过程间控制流图,依次进行简单图卷积操作和超图卷积操作,实现对弱过程间控制流图中多级信息的细粒度捕获;
[0050]
读出检测模块,读出经多阶段卷积模块更新后的弱过程间控制流图的嵌入作为整个图的特征表示,然后将获得的特征表示输入到多层全连接网络构建的检测器中进行漏洞检测。
[0051]
与现有技术相比,本发明所带来的有益的技术效果表现在:
[0052]
1、本发明具有合理界定过程间漏洞涉及的代码范围的能力,利用基于分析逻辑的工具infer处理的结果,更好地界定过程间漏洞涉及的多个过程的代码范围。
[0053]
2、本发明具有更全面的代码初始信息抽取能力,以图结构的方式将初始代码转化
成中间表示,并充分抽取代码初始的语法和语义信息,为学习代码的高阶信息提供支撑。
[0054]
3、本发明可更有效的学习多过程间高阶语法语义信息,进行多阶段图卷积可实现对代码过程内和过程间复杂关系的有效捕获,抽取高价值的代码语法语义信息,进而提高过程间漏洞检测效果。
附图说明
[0055]
图1为本发明方法hgivul的整体架构图。
[0056]
图2为初始化特征表示模块示例流程图。
[0057]
图3为在数据集dataset 1上hgivul与多种方法对比的漏洞检测效果。
[0058]
图4为在数据集dataset 2上vuldeepecker对10类漏洞的分类的混淆矩阵。
[0059]
图5为在数据集dataset 2上sysevr对10类漏洞的分类的混淆矩阵。
[0060]
图6为在数据集dataset 2上c-bert对10类漏洞的分类的混淆矩阵。
[0061]
图7为在数据集dataset 2上deepwukong对10类漏洞的分类的混淆矩阵。
[0062]
图8为在数据集dataset 2上hgivul对10类漏洞的分类的混淆矩阵。
具体实施方式
[0063]
下面将结合本发明说明书附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0064]
实施例1
[0065]
作为本发明较佳实施例,参照说明书附图1所示,本实施例公开了一种基于超图卷积的源代码过程间漏洞检测方法,该检测方法具体包括以下步骤:
[0066]
s1、使用基于分离逻辑的工具infer对待检测源代码进行过程间分析,并利用基于分离逻辑的工具infer对待检测源代码中存在的可疑漏洞进行初步定位。
[0067]
s2、根据s1步骤中基于分离逻辑的工具初步定位到的可疑漏洞对应代码的trace重构弱过程间控制流图;首先根据infer输出的trace定位漏洞代码涉及的多个过程;然后对每一个涉及的过程构造出对应的控制流图;接着,根据trace中代码的执行顺序,确定过程间的调用点(call site);最后,根据确定的调用点位置在每个调用点增加调入(call in)和调出(call out)两条连边,将多个过程的控制流图相连接起来形成弱过程间控制流图。
[0068]
s3、将s2步骤重构的弱过程间控制流图中节点代码中所具有的初始特征信息进行向量化表示;具体的,提取节点代码初始的语义信息,并向量化节点代码的语法信息,将节点代码初始的语义信息和语法信息拼接,形成初始化的弱过程间控制流图节点特征的向量化表示;
[0069]
更具体的,使用预训练的word2vec模型来提出代码初始的语义信息,另一方面,基于代码对应的llvm语法树基本单元token来向量化节点的语法信息。最后,将代码初始的语义和语法信息拼接,形成初始化的弱过程间控制流图节点特征信息的向量化表示。
[0070]
s4、首先在s3步骤初始化后的弱过程间控制流图上,进行简单图卷积操作,以捕获
过程内代码的特征;然后在s3步骤初始化后的弱过程间控制流图上运用超图卷积以捕获过程间代码的特征,以实现对弱过程间控制流图中多级信息的细粒度捕获;
[0071]
s5、读出经s4步骤卷积操作更新后的弱过程间控制流图的嵌入作为整个图的特征表示,然后将获得的特征表示输入到多层全连接层构建的检测器中进行检测,根据检测器输出的检测结果判断是否存在漏洞。
[0072]
实施例2
[0073]
作为本发明又一较佳实施例,本实施例是对上述实施例1中s2步骤具体实施方式的一种详细阐述,在本实施例中,s2步骤中,重构弱过程间控制流图具体包括以下子步骤:
[0074]
s201、根据s1步骤中基于分离逻辑的工具初步定位到的可疑漏洞对应代码的trace,定位代码涉及的每一个执行过程,并重构每一个过程的控制流图;
[0075]
s202、根据trace中的代码执行顺序,确定过程间的调用点,然后依据确定的调用点位置在每个调用点增加调入和调出两条连边,将多个过程的控制流图连接起来形成弱过程间控制流图。
[0076]
实施例3
[0077]
作为本发明又一较佳实施例,本实施例是对上述实施例1中s3步骤具体实施方式的一种详细阐述,在本实施例中,s3步骤中,将s2步骤重构的弱过程间控制流图中节点代码中所具有的初始特征信息进行向量化表示,具体包括:
[0078]
s301、使用词法分析器抽取节点代码中的基本单元,并对基本单元中存在的变量名和函数名进行符号化处理;
[0079]
s302、对符号化处理后的基本单元,使用预先训练好的word2vec模型抽取对应的初始嵌入,捕获代码初始的语义信息;将节点代码中存在的多个基本单元对应的嵌入按相同维度计算平均值,形成节点代码初始的语义嵌入;
[0080]
s303、对节点代码抽取规范的llvm语法树基本单元,每个节点对应的多个规范基本单元构成一个集合;
[0081]
s304、统计每个节点对应的llvm基本单元集合中不同类型基本单元的数量,对每一类基本单元的数量进行归一化处理,然后按特定的基本单元类型顺序进行one-hot编码,形成节点初始的语法嵌入;
[0082]
s305、将s302步骤中获取的节点代码初始的语义嵌入和s304步骤中获取的节点初始的语法嵌入拼接,形成节点初始的特征表示,即初始化的弱过程间控制流图节点特征信息的向量化表示。
[0083]
实施例4
[0084]
作为本发明又一较佳实施例,参照说明书附图1,本实施例公开了一种基于超图卷积的源代码过程间漏洞检测方法,包括以下步骤:
[0085]
s1、使用基于分离逻辑的工具infer对待测源代码进行过程间分析,并利用infer对可疑漏洞进行初步定位。
[0086]
s2、重构弱过程间控制流图(soft icfg,soft inter-procedural control flow graph)。根据infer输出的可疑代码的trace重构过程间控制流图。首先根据infer输出的trace定位漏洞代码涉及的多个过程;然后对每一个涉及的过程构造出对应的控制流图;接着,根据trace中代码的执行顺序,确定过程间的调用点(call site);最后,根据确定的调
用点位置在每个调用点增加调入(call in)和调出(call out)两条连边,将多个过程的控制流图相连接起来形成弱过程间控制流图(soft icfg)。
[0087]
s3、初始化soft icfg节点特征表示。初始化节点特征表示是将节点的初始特征信息进行向量化表示,向量化节点属性是自动化漏洞检测的重要一步。hgivul从两个角度初始化节点的特征表示。一方面,hgivul使用预训练的word2vec模型来提出代码初始的语义信息,另一方面,hgivul基于代码对应的llvm语法树token来向量化节点的语法信息。最后,将代码初始的语义和语法信息拼接,形成初始的soft icfg节点特征表示。
[0088]
s4、多阶段图卷积。这一步用于获取高阶有价值的代码特征,hgivul首先在soft icfg进行简单图卷积操作来捕获过程内的代码特征,然后在soft icfg上运用超图卷积来捕获过程间代码的特征,进而实现对soft icfg中多级信息的细粒度捕获。
[0089]
s5、读出更新后的特征表示并进行检测。首先读出更新后soft icfg的嵌入作为整个图的特征表示。然后将获得的高阶特征表示输入到多层全连接层构建的检测器进行检测。最后输出检测结果。
[0090]
进一步的,所述s2步骤具体包括:
[0091]
步骤201:基于infer输出的trace,定位代码涉及的每一个执行过程(函数),并重构每一个过程的控制流图(cfg,control flow graph);
[0092]
步骤202:根据trace中的代码执行顺序,确定过程间的调用点(call site),然后依据确定的调用点将多个过程的cfg连接,形成soft icfg。注意在每一个调用点分别增加调入(call in)和调出(call out)两条连边。
[0093]
更进一步的,所述步骤3中初始化节点特征表示包括:
[0094]
步骤301:使用词法分析器抽取节点代码中的基本单元token,并对token中存在的变量名和函数名进行符号化处理,以避免不同命名习惯对代码语义信息带来的影响;
[0095]
步骤302:对符号化处理后的节点token,使用预先训练好的word2vec模型抽取对应的初始嵌入,以捕获代码初始的语义信息。并将节点代码中存在的多个token对应的嵌入按相同维度计算平均值,形成节点初始的语义嵌入;
[0096]
步骤303:对节点的初始代码抽取规范的llvm语法树token,每个节点对应的多个规范token构成一个集合;
[0097]
步骤304:统计每个节点对应的llvm token集合中不同类型token的数量,对每一类token的数量进行归一化处理,然后按特定的token类型顺序进行one-hot编码,形成节点初始的语法嵌入;
[0098]
步骤305:将步骤302中获取的节点初始语义嵌入和步骤304中获取的节点初始语法嵌入拼接,形成节点初始的特征表示。
[0099]
更进一步的,所述s4步骤中多阶段图卷积具体包括:
[0100]
s401、首先在soft icfg上进行简单图卷积
[0101]
将s3步骤初始化后的弱过程间控制流图视为简单图g=(v,e),其中v表示节点集,e表示边集;初始化后的弱过程间控制流图中所有节点的初始嵌入表示为其中d表示词嵌入向量的维度,表示是实数集,其维度为|v|
×
|d|;
[0102]
对于节点vi,初始的嵌入表示为k-1次卷积后节点vi的特征嵌入表示为因
此节点vi在k次卷积后的特征嵌入表示为
[0103]
具体地,在简单图上进行卷积操作由以下公式计算:
[0104]
式中,n(i)表示节点vi邻居节点的集合,表示对节点vi的任意邻居节点vj,其k-1次卷积后的特征嵌入表示为m(
·
)为聚合均值聚合函数,w表示可训练的权重,σ(
·
)表示激活函数;初始化后的弱过程间控制流图在进行简单图卷积后的特征嵌入表示为x
simple
;
[0105]
s402、构造用于超图卷积的贡献矩阵h
[0106]
在上述简单图卷积操作的基础上,将弱过程间控制流图视为超图gh=(v,eh),其中eh表示超边的集合,对于一条超边e∈eh,e={v1,...,v
p
},vi∈v,2≤p≤|v|,vi表示节点集合v中的第i个节点,v
p
表示节点集合v中的第p个节点;超图上的共现矩阵表示节点集合v中的第p个节点;超图上的共现矩阵表示是实数集,其维度为|v|
×
|eh|,且每个共现矩阵的元素h
(v,e)
定义由以下公式确定:
[0107][0108]
s403、计算简单图的度矩阵阵ds[0109]
简单图的度矩阵ds是一个对角矩阵是一个对角矩阵表示实数集且其维度为|v|
×
|v|,每个对角元素由以下公式计算:
[0110]
s404、计算超图的度矩阵dh[0111]
超图的度矩阵dh也是一个对角矩阵也是一个对角矩阵表示实数集且其维度为|eh|
×
|eh|,每个对角元素由以下公式计算:dh(v,v)=∑
v∈v
h(v,e)。
[0112]
s405、进行超图卷积
[0113]
在弱过程间控制流图上进行超图卷积,由以下公式计算:
[0114][0115]
其中,h
t
表示h的转置,令上述公式可简化为:
[0116]
式中,k表示在超图上进行k次卷积,x表示节点特征表示的集合,当k=0时,x0=x
simple
;经以上多级图卷积更新后的节点特征表示为x
′
。
[0117]
更进一步的,所述s5步骤中读出更新后的特征表示并进行检测具体包括:
[0118]
s501、读出经s4步骤卷积操作更新后的弱过程间控制流图的嵌入作为整个图的特征表示,按对应维度选用最大值读出方式,具体由以下公式计算:
[0119]
r=max({x
′1,x
′1,
…
,x
′i}),x
′i∈x
′
,其中,h表示整个弱过程间控制流图的特征表示;
[0120]
s502、将获取的特征表示r输入到一个多层全连接网络中进行检测,具体由以下公式计算:
[0121]
式中,表示最终的检测结果,mlp表示
多层全连接网络,使用sigmoid函数输出最后的检测结果。
[0122]
实施例5
[0123]
作为本发明又一较佳实施例,参照说明书附图1,本实施例公开了一种基于超图卷积的源代码过程间漏洞检测装置,整体架构如图1所示,装置主要由潜在漏洞定位模块、重构弱过程间控制流图模块、初始化特征表示模块、多阶段图卷积模块、读出检测模块五个部分组成。其中潜在漏洞定位模块用于界定潜在漏洞代码涉及的范围,重构弱过程间控制流图模块将代码转化为更具表现能力的图形结构,初始化特征表示模块用于向量化代码的初始语法语义信息,多阶段卷积模块用于捕获过程内和过程间的高阶信息,读出检测模块用于输出过程间漏洞的检测结果。
[0124]
潜在漏洞定位模块使用基于分离逻辑的工具infer对项目代码进行过程间分析,并利用infer的输出结果初步界定漏洞代码所涉及的多个过程(函数)。
[0125]
重构弱过程间控制流图模块基于infer输出的结果重构出弱过程间控制流图。首先,hgivul根据infer输出的trace定位漏洞代码涉及的多个过程;然后,对每一个涉及的过程构造出对应的控制流图;接着,根据trace中代码的执行顺序,确定过程间的调用点(call site);最后,根据确定的调用点位置在每个调用点增加调入(call in)和调出(call out)两条连边,将多个过程的控制流图相连接起来形成弱过程间控制流图。完整的过程间控制流图在每个一个调用点都会连接一个目标函数的控制流图,其可能会存在多次连接相同函数控制流图的情况,这会导致大量的存储和计算开销。与之相比,弱过程间控制流图只连接目标函数调用点第一次出现的位置。
[0126]
初始化特征表示模块是将弱过程间控制流图中节点代码中所具有的初始特征信息进行向量化表示。向量化节点属性是自动化漏洞检测的重要一步。节点的初始属性是代码文本,为了更全面地获取代码初始的语法语义信息,hgivul从两方面来初始化节点的特征表示。一方面,hgivul使用预训练的word2vec模型来提出代码初始的语义信息,另一方面,hgivul基于代码对应的llvm语法树token来向量化节点的语法信息。最后,将代码初始的语义和语法信息拼接,形成初始的soft icfg节点特征信息的向量化表示。
[0127]
图2展示了初始化特征表示的示例流程。首先,使用词法分析器抽取节点代码中的基本单元token,并对token中存在的变量名和函数名进行符号化处理(例如,变量名“dst”、“di”、“si”分别被符号化为“var1”、“var2”、“var3”),以避免不同命名习惯对代码语义信息带来的影响;然后,使用预先训练好的word2vec模型抽取对应的初始嵌入,以捕获代码初始的语义信息。对于节点包含多个token的情况,计算每个token对应维度的平均值形成一个新的向量,作为节点初始的语义嵌入;接着,抽取节点初始代码对应的llvm语法树token表达式,统计每个节点对应的llvm token集合中不同类型token的数量,并进行归一化处理;其次,按特定的token类型顺序进行one-hot编码,形成节点初始的语法嵌入;最后,将获取的节点初始语义嵌入和初始语法嵌入拼接形成节点的初始特征表示。
[0128]
多阶段图卷积模块在初始化后的弱过程间控制流图上,进行简单图卷积和超图卷积,来学习高阶有价值的代码特征表示。
[0129]
首先,如图1中多阶段图卷积所示,在soft icfg上进行简单图卷积。将初始化后的弱过程间控制流图视为简单图g=(v,e),其中v表示节点集,e表示边集;初始化后的弱过程间控制流图中所有节点的初始嵌入表示为其中d表示词嵌入向量的维度,表示
是实数集,其维度为|v|
×
|d|;
[0130]
对于节点vi,初始的嵌入表示为k-1次卷积后节点vi的特征嵌入表示为因此节点vi在k次卷积后的特征嵌入表示为
[0131]
具体地,在简单图上进行卷积操作由以下公式计算:
[0132]
式中,n(i)表示节点vi邻居节点的集合,表示对节点vi的任意邻居节点vj,其k-1次卷积后的特征嵌入表示为m(
·
)为聚合均值聚合函数,w表示可训练的权重,σ(.)表示激活函数;初始化后的弱过程间控制流图在进行简单图卷积后的特征嵌入表示为x
simple
;然后从soft icfg中构造用于超图卷积的共现矩阵h、简单图的度矩阵ds、和超图的度矩阵dh。
[0133]
在上述简单图卷积操作的基础上,将弱过程间控制流图视为超图gh=(v,eh),其中eh表示超边的集合,对于一条超边e∈eh,e={v1,...,v
p
},vi∈v,2≤p≤|v|,vi表示节点集合v中的第i个节点,v
p
表示节点集合v中的第p个节点;超图上的共现矩阵表示节点集合v中的第p个节点;超图上的共现矩阵表示是实数集,其维度为|v|
×
|eh|,且每个共现矩阵的元素h
(v,e)
定义由以下公式确定:
[0134][0135]
简单图的度矩阵ds是一个对角矩阵是一个对角矩阵表示实数集且其维度为|v|
×
|v|,每个对角元素由以下公式计算:
[0136]
超图的度矩阵dh也是一个对角矩阵也是一个对角矩阵表示实数集且其维度为|eh|
×
|eh|,每个对角元素由以下公式计算:dh(v,v)=∑
v∈v
h(v,e)。
[0137]
最后,在弱过程间控制流图上进行超图卷积,由以下公式计算:
[0138][0139]
其中,h
t
表示h的转置,令上述公式可简化为:
[0140]
式中,k表示在超图上进行k次卷积,x表示节点特征表示的集合,当k=0时,x0=x
simple
;经以上多级图卷积更新后的节点特征表示为x
′
。
[0141]
读出检测模块将整个图的特征表示读出,并将读出的特征表示输入到检测器中进行检测。首先,读出经过以上卷积操作更新后soft icfg的嵌入作为整个图的特征表示,本发明按对应维度选用最大值读出方式,由以下公式计算:
[0142]
r=max({x
′1,x
′1,
…
,x
′i}),x
′i∈x
′
h=max({x
′1,x
′2,...,x
′i}),x
′i∈x
′
,其中,r表示整个弱过程间控制流图的特征表示;然后,将获取的特征表示r输入到一个多层全连接网络中进行检测,具体由以下公式计算:
[0143]
式中,表示最终的检测结果,mlp表示多层全连接网络,使用sigmoid函数输出最后的检测结果。
[0144]
本发明在多阶段卷积模块和读出检测模块都存在训练和检测两个不同的状态。在
训练状态中,使用训练数据训练特征表示抽取模型和漏洞检测模块。在实际的检测状态中,直接使用训练好的检测模型抽取漏洞代码的特征表示,并运用训练好的检测器进行检测。
[0145]
hgivul的过程间漏洞检测效果评测在d2a数据集上进行。d2a是一个包含代码过程间信息且由实际开源项目构成的数据集,其包含了openssl、nginx、libtiff、httpd、libav、ffmpeg共6个开源项目的多个漏洞样本。因ffmpeg和libav有较多重复样本,评测中取掉ffmpeg项目的样本,仅保留另外5个项目的样本。经过处理后,在的d2a中包含566968个可用样本,其中可用的漏洞样本12290个,可用的正常样本554678个,为了方便描述此数据集命名为dataset 1。另外,为了验证hgivul对漏洞的识别效果,在d2a中选取了出现最多的10类漏洞样本,构造了数据集dataset 2。选取的10类样本包括“整数溢出”、“缓存区溢出”、“空指针”等多种常见的漏洞类型,构造的数据集dataset包含12003个漏洞样本。此外,样本按照8:1:1的比例划分训练集、验证集、和测试集,选用accuracy(acc)、precision(pre)、recall、f1-score(f1)、false positive rate(fpr),false negative rate(fnr)这6项指标来进行评估,并选用5种相关的方法进行对比验证。
[0146]
图3展示的是hgivul与5种相关方法在数据集dataset 1上漏洞检测的效果。其中横坐标表示不同的方法,纵坐标表示检测结果的百分比值,不同的柱状代表的是对应评测指标的具体百分比值。整体上,hgivul相比于其他5种方法有更好的检测效果。另外,从图3中可以有如下发现:首先,infer的检测效果最差,其fpr高达98.01%,因为d2a数据集是利用infer构造的,导致其recall和fnr数值上最好。其次,利用代码序列进行模型学习的方法相较于infer有更好的检测性能,vuldeepecker和sysevr的检测效果要明显优于infer,vuldeepecker的fpr最低到达1.17%,其原因可能是数据驱动的方法可以发掘人工专家无法获取的高阶信息。然后,将代码视为自然语言序列进行处理在一定程度上有助于提升检测效果,对c-bert模型微调后获得较好的检测效果。最后,基于图结构的检测方法有更好的检测效果,并且进行多阶段图卷积操作的hgivul优于其他5种方法,其accuracy为96.87%,precision为67.89%,recall为64.85%,f1为66.33%都优于其他方法,并且fnr和fpr都相对较低。hgivul从分地利用了代码的结构属性,并细粒度地获取了代码过程内和过程间的语法语义特征信息,因此相比于现有的方法有更好的过程间漏洞检测效果。
[0147]
图4、图5、图6、图7和图8分别展示了5种方法对数据集dataset 2中10类常见漏洞类型的识别效果。为了验证hgivul识别不同类型漏洞的能力,将vuldeepecker、sysevr、c-bert、deepwukong、hgivul的模型调整为多分类任务。图4至图8展示了5种方法识别10类漏洞的混淆矩阵,横坐标表示预测的漏洞类型,纵坐标表示实际的漏洞类型,并使用加权的f1值来整体评估识别效果。整体上,hgivul对不同类型的漏洞的识别效果要优于其他方法,其加权的f1值可达到79.58%。对比多个方法的识别结果可以发现,对代码进行不同形式的处理对分类结果有较大的影响。基于代码序列的方法的分类效果要差于基于图形结构化处理的方法,vuldeepecker和sysevr的加权f1值分别66.14%和71.30%,要低于其他方法。而基于图形结构化处理的方法要优于基于序列的方法,deepwukong和hgivul的加权f1值分别为76.21%和79.58%,要优于其他方法。另外,不同方法对不同类型的漏洞识别能力也存在差异,5种方法都对“integer_overflow_l5”,“nullptr_dereference”,“inferbo_alloc_ma y_be_big”3种漏洞的识别效果相对较好,而对部分漏洞识别相对较差,如“integer_overflow_u5”和“buffer_overrun_u5”,其原因是这些漏洞形态变化多样。综上可知,
hgivul因为能获取丰富的多过程的代码语法语义信息,其比现有的方法具有更好的漏洞分类识别性能。
[0148]
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1