一种基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法
1.本发明涉及一种基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法,属于人工智能与机器学习技术领域。
背景技术:
2.近年来,移动计算、无线通信和位置获取技术的进步,促进了基于位置的社交网络(location-based social networks,lbsns)的普及和发展。国内外已有一大批成熟的基于位置的社交网络平台,如国外的foursquare、gowalla、facebook、twitter和yelp等,国内的大众点评、新浪微博以及微信朋友圈等,越来越多的人们通过智能手机使用在线社交网络。据2022年2月中国互联网络信息中心(cnnic)发布的第49次《中国互联网络发展状况统计报告》显示:截至2021年12月,中国网民规模已达10.32亿,其中网民使用手机上网的比例达99.7%。基于位置的社交网络已经成为了人们分享和传递信息的新型传媒形态,一方面,用户在lbsns中建立社交关系,发布感兴趣的内容,随时随地地分享他们当前所在的位置、图片、音频、视频及评论等;另一方面,当面对海量信息资源时,为了缓解信息过载(information overload)问题,用户可以通过使用lbsns中提供的个性化服务来获得符合用户偏好的推荐内容,例如位置、朋友、音乐和广告等。
3.在lbsns中,位置签到服务是一个重要且应用广泛的服务。lbsns通过gps全球定位系统或wifi定位与地理位置系统相结合来确定用户当前的位置。随着城市的快速发展,出现了越来越多的地点,例如旅游景点、剧院、酒店、银行和商场等,人们常常根据个人的兴趣偏好在各种各样的地点中做出去哪里的选择。这些在物理世界中真实存在的、用户感兴趣的地点,称为兴趣点(point-of-interest,poi)。然而,每个用户访问过的兴趣点只是有限的极少数地点,当用户面临海量的没有去过的地点或者访问陌生城市时,就产生了“地点信息过载”和“选择恐慌”难题,如何在现实世界的大量地点中为用户推荐出符合其兴趣偏好的位置是lbsns面临的一个亟需解决的问题。兴趣点推荐(pois recommendation)作为一个新兴的推荐领域,能够有效解决位置信息过载给用户带来的选择困扰问题,有助于提升用户在社交网络和现实生活中的体验,并能够帮助商家分析和挖掘潜在用户来进行广告推送服务,已经成为了一个研究热点。
4.考虑到兴趣点推荐作为推荐系统的一个重要分支,无论是发展历程还是关键技术,都与传统推荐系统一脉相承,因此,部分的兴趣点推荐研究将位置看作类似于电影、音乐等的普通项目,利用传统推荐方法生成推荐结果。根据设计策略,传统推荐方法主要包括协同过滤算法、基于内容的推荐算法和混合推荐算法。协同过滤算法又包括基于记忆的协同过滤算法(如基于用户的协同过滤ubcf、基于项目的协同过滤ibcf)和基于模型的协同过滤算法(如奇异值分解svd、聚类模型和概率潜在语义分析等)。其中,基于内容的兴趣点推荐技术从被访问地点中提取相关信息,比如标签、分类和用户评论;从用户的配置文件中提取用户偏好,然后与位置配置文件匹配,以获得准确的推荐。协同过滤技术将用户的签到行
为转换为用户-兴趣点评分矩阵,利用已有的签到记录寻找与当前活跃用户相似的用户或与活跃用户之前喜欢的地址高度相似的位置,根据用户之间或地址之间的相似度预测活跃用户对未签到地点的评分,将预测评分最高的兴趣点推荐给当前用户。奇异值分解(svd)是矩阵分解的经典代表,其主要任务是生成低秩近似。用svd技术分解后的低维正交矩阵在原始矩阵的基础上降低了噪音,且可以更有效地揭示用户和商品的潜在关联。
5.以上传统推荐技术均忽略了位置社交网络中的社交关系、地理距离和位置在不同时间的流行度对用户签到行为的影响。然而,事实上用户的签到习惯总是与关系、位置和时间上下文密切相关。例如,用户与他的朋友往往会在同一个兴趣点签到;用户在游玩旅游景点时,更愿意去附近的酒店居住;餐饮类的兴趣点在12点和18点左右被访问量最大(流行度最高),酒吧的流行度则从21点以后开始上升。如何在推荐算法中引入社交关系、地理特征和位置流行度,在特定时间段为用户提供合适的兴趣点推荐列表已成为各类社交应用平台的迫切需求。
6.目前,已有一些兴趣点推荐技术解决方案考虑了地理影响、时间影响、社交影响等一个或多个因素,但是仍存在一些缺点和不足,归纳起来有以下几点:
7.(1)忽略了位置流行度的时间维动态特征。与社交关系、地理特征等其他类别的上下文相比,关注位置流行度特征的兴趣点推荐技术相对较少,且为数不多的相关研究仅从宏观角度去分析位置的总体流行度(将位置的被访问次数与数据集中的总访问次数进行比较),忽略了微观层面位置流行度的时间维动态特征,事实上,在一天中的不同时间段使用全局的位置流行度是不符合事实规律的。因此,如何挖掘位置流行度随着时间的推移而发生的变化规律是一个值得思考的问题。
8.(2)位置流行度计算方法的片面性。当前已有的流行度计算方法仅将兴趣点的被访问次数与其他位置的被访问次数进行横向比较,若当前位置的被访问频率相对较高,则认为该位置具有较高的流行度。然而,此类方法局限于目标位置与其他位置的横向比较结果,忽略了将目标位置在当前时间的流行度与其他时间段内的流行度进行纵向比较,具有一定的片面性,降低了位置流行度估计的精确度,影响了位置推荐系统的推荐准确性。
9.(3)用户-时间-兴趣点三维矩阵计算的高时间复杂度问题。传统推荐系统中的评分矩阵只包含用户和项目二维信息,为了探索用户在目标时间段的行为模式,兴趣点推荐系统需要将用户-兴趣点二维矩阵扩充至用户-时间-兴趣点三维评分矩阵,这无疑加剧了推荐过程的计算复杂度。随着计算数据量呈现指数级增长态势,计算代价已成为制约推荐系统快速发展的瓶颈之一。因此,必须探讨能够降低计算复杂度的推荐方法,以提升推荐系统的运行效率。
10.以上所述为现有的兴趣点推荐技术的不足,在不同的位置社交网络平台的设计、开发、部署与运行中带来较大弊端,尤其是在海量项目信息的网络平台上造成推荐系统服务质量的下降,进而影响电子商务系统的销售业绩。
技术实现要素:
11.本发明目的在于针对上述现有技术的不足,提供了一种基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法,该方法能够根据用户的社交关系、位置的动态流行度以及位置之间的地理距离,为用户实时生成兴趣点推荐列表。考虑到用户-时间-兴趣
点三维矩阵的大数据量及高计算复杂度问题,本发明基于友谊关系对评分矩阵进行数据预处理,为每个用户生成个性化评分矩阵,改进传统的基于用户的协同过滤算法,以达到提升推荐效率的目的;同时,本发明创新地提出了兴趣点动态流行度的计算方法,通过提取兴趣点在不同时间段的不同流行度,提升评分预测的有效性,强化推荐系统的服务质量。
12.本发明解决其技术问题所采用的技术方案是:一种基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法,该方法包括如下步骤:
13.步骤1:收集、整理原始签到数据集和社交关系数据集,分别将其转换成用户-时间-兴趣点三维评分矩阵以及二维关系矩阵;
14.步骤2:选取基于位置的社交网络中某活跃用户作为推荐服务对象。为该目标用户删除评分矩阵中的弱相关行和弱相关列,改进传统的基于用户的协同过滤算法,为目标用户生成基于友谊的预测评分;
15.步骤3:统计各个兴趣点在每个时间槽内的被访问次数,将其同时与兴趣点在所有时间的总访问次数和所有兴趣点在某时间的被访问次数进行比较,计算各个兴趣点基于时间感知的动态流行度;
16.步骤4:根据签到数据集中位置的经纬度信息,计算不同兴趣点之间的地理距离,基于幂律分布模型挖掘地理特征对兴趣点访问概率的影响;
17.步骤5:综合考虑用户社交关系、位置动态流行度和地理距离对用户访问行为的影响,融合基于友谊的预测评分、兴趣点的动态流行度以及基于距离的访问概率,为目标用户生成未访问地址的最终预测评分。对所有未访问地址按最终预测评分排序,为目标用户提供排名靠前的若干个地址组成的推荐列表;
18.步骤6:使用精确率precision、召回率recall和综合精度指标f1作为推荐系统的准确性评价指标,对比本发明提出的推荐方法与其他相关的经典推荐方法的预测准确度,评价所提出技术的适用性和有效性。
19.有益效果:
20.1、本发明能够根据用户的历史访问兴趣、用户之间的社交关系、位置之间的地理距离和在当前时间下位置的流行度为用户实时推荐若干个兴趣点,同时,也能够帮助商家给潜在客户精准推送广告,具有重要的实际应用价值。
21.2、本发明利用用户社交关系网络对三维签到矩阵进行数据预处理,为每个目标用户生成个性化评分矩阵,缩小了评分数据规模,降低了推荐算法的计算复杂度,提升了推荐系统的运行效率,从而提高了用户和商家对社交网络平台的使用满意度,在实际应用中具有非常重要的意义。
22.3、本发明挖掘了位置流行度的时间维动态特征,在微观层面将兴趣点在当前时间段的被访问次数同时与其他统计数据进行纵向比较和横向比较,计算兴趣点基于时间感知的动态流行度,充分挖掘了位置流行度随着时间的推移而发生的变化规律,有效提升了推荐系统预测用户行为模式的准确性。该方法具有一定的普适性与移植性,不仅可以应用于兴趣点推荐系统,也适用于其他传统项目的个性化推荐领域,具有广阔的工业化应用前景。
附图说明
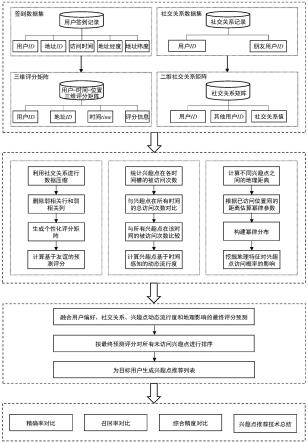
23.图1是本发明提出的基于社交关系融合位置动态流行度和地理特征的兴趣点推荐
方法的概要示意图。
24.图2是本发明提出的基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法的具体步骤流程图。
25.图3是本发明实施案例中用户在位置社交网络中的签到记录示意图。
26.图4是本发明实施案例中用户在位置社交网络中的社交关系记录示意图。
27.图5是本发明实施案例中被访问次数最多的前三名兴趣点在各个时间槽中的被访问概率示意图。
28.图6是本发明实施案例中所有用户在同一天内访问的相邻兴趣点之间的地理距离的概率分布示意图。
29.图7是实施案例中本发明提出的推荐方法和经典的基于用户的协同过滤方法ubcf、基于社交关系的协同过滤方法scf、基于幂律分布的访问概率预测方法pld、基于核密度估计的访问概率预测方法kde的精确率precision对比的柱状图。
30.图8是实施案例中本发明提出的推荐方法和经典的基于用户的协同过滤方法ubcf、基于社交关系的协同过滤方法scf、基于幂律分布的访问概率预测方法pld、基于核密度估计的访问概率预测方法kde的召回率recall对比的柱状图。
31.图9是实施案例中本发明提出的推荐方法和经典的基于用户的协同过滤方法ubcf、基于社交关系的协同过滤方法scf、基于幂律分布的访问概率预测方法pld、基于核密度估计的访问概率预测方法kde的综合精度指标f1值对比的柱状图。
具体实施方式
32.下面结合说明书附图对本发明创造作进一步地详细说明。
33.如图1-图2所示,本发明提供了一种基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法,该方法具体包括:对三维评分矩阵进行预处理,为目标用户删除评分矩阵中的弱相关行(与目标用户无社交关系的其他用户)和弱相关列(目标用户及其朋友均未访问过的地址),生成个性化评分矩阵;改进传统的基于用户的协同过滤算法,生成基于友谊的预测评分;将一天分为24个时间槽,根据时间标签分别统计每个兴趣点在各个时间槽内的签到次数,将兴趣点的被访问次数与其他位置的被访问次数进行横向比较,同时,将目标位置在当前时间的流行度与其他时间段内的流行度进行纵向比较,计算目标位置基于时间感知的动态流行度;采用幂律分布模型模拟位置间的地理距离对兴趣点被访问概率的影响;综合以上三类上下文(社交关系、动态流行度和地理距离)对用户访问行为的影响,计算所有未访问地址的预测评分并对其进行排序,选择排名靠前的若干个兴趣点推荐给用户,如图1所示。
34.本发明具体步骤包括如下:
35.步骤1:收集、整理原始签到数据集和社交关系数据集,分别将其转换成用户-时间-兴趣点三维评分矩阵以及二维关系矩阵。操作步骤如下:
36.步骤1-1:整理原始签到数据集c,获得n条签到记录,记作c={c1,c2,
…
,cn}。签到数据集c中的所有用户形成用户集合u,所有兴趣点形成地址集合l,用户数量和兴趣点数量分别记作nu和nl。对签到记录中的签到时间进行取整,将离散的签到时间转换为24个时间槽,时间槽集合t={0,1,2,
…
,23}。
37.步骤1-2:在签到数据集c中统计某用户u在时间槽t时访问某地址l的次数,若签到次数为0,则用户u在时间槽t时对地址l的评分r
u,t,l
为0,否则,r
u,t,l
=1。汇总所有评分,形成用户-时间-兴趣点三维评分矩阵r={r
u,t,l
},其中,u∈u,t∈[0,23],l∈l,u和l分别是用户集合和兴趣点集合。
[0038]
步骤1-3:整理原始的社交关系数据集f,获得m条社交关系记录,记作f={f1,f2,
…
,fm}。将每一条社交关系记录形式化为《用户u
x
,用户uy》二元组,x∈[1,nu],y∈[1,nu],nu是数据集中所有用户的数量。
[0039]
步骤1-4:构建二维用户社交关系矩阵s={s
xy
},该矩阵的行数和列数均为用户数量nu,x∈[1,nu],y∈[1,nu],其元素s
xy
代表了用户u
x
与uy之间是否存在社交关系:
[0040][0041]
步骤2:选取基于位置的社交网络中某活跃用户作为推荐服务对象。为该目标用户删除评分矩阵中的弱相关行和弱相关列,改进传统的基于用户的协同过滤算法,为目标用户生成基于友谊的预测评分。具体操作步骤如下:
[0042]
步骤2-1:确定位置社交网络中某目标用户ua作为推荐服务对象,搜索社交关系矩阵s中目标用户ua所在的行,获取该行中元素值为1的列号,形成目标用户ua的朋友集合fa,fa集合中的元素个数记为fnuma,同时记录下该行中元素值为0的列号,形成与目标用户ua无社交关系的用户集合unfa。
[0043]
在用户-时间-兴趣点三维评分矩阵r中,若用户ui∈unfa,则在r中删除用户ui的评分信息,得到删除与目标用户ua无社交关系的用户(弱相关行)后的评分矩阵r1={r
i',t,j
},i'∈[1,fnuma],t∈[0,23],j∈[1,nl],其中i'表示用户编号,t表示时间槽的值,j表示地址编号,fnuma表示目标用户ua的朋友个数,nl表示兴趣点总数,r
i',t,j
表示用户u
i'
在时间槽t时对地址lj的评分。
[0044]
通过社交关系的筛选,有效降低了原始评分矩阵r的行规模,即|i'|=fnuma《《nu,nu表示用户总数。
[0045]
步骤2-2:在评分矩阵r1中,逐个计算每个地址在所有时间槽内的评分总和,若评分总和等于0,则表示目标用户ua的所有朋友在任何时间内均未访问过此地址,将该地址加入到unvisit_fa集合中。
[0046]
若地址lj∈unvisit_fa,则在r1中删除lj的评分信息,得到删除无关地址(弱相关列)后的评分矩阵r2={r
i',t,j'
},i'∈[1,fnuma],t∈[0,23],j'∈[1,nl-|unvisit_fa|],其中i'表示用户编号,t表示时间槽的值,j'表示地址编号,fnuma表示目标用户ua的朋友个数,nl表示兴趣点总数,|unvisit_fa|表示目标用户的所有朋友均未访问过的地址数量,r
i',t,j'
表示用户u
i'
在时间槽t时对地址l
j'
的评分。
[0047]
通过无关地址的删除,在评分矩阵r1的基础上进一步降低了列规模,即|j'|=nl-|unvisit_fa|《《nl,nl表示用户总数。
[0048]
步骤2-3:基于预处理后的评分矩阵r2计算目标用户ua与其朋友用户之间的评分相似度。若用户v∈fa,则目标用户ua和用户v的评分相似度为:
[0049][0050]
其中,ua是推荐系统当前服务的目标对象,v为目标用户ua的一个朋友用户,t是某个时间槽,t是时间槽集合,l是所有兴趣点用集合,unvisit_fa表示目标用户ua的所有朋友在任何时间内均未访问过的地址集合,和r
v,t,l
分别表示用户ua和用户v在时间t时对兴趣点l的评分。
[0051]
步骤2-4:改进传统的基于用户的协同过滤算法,利用数据压缩后的评分矩阵r2,基于社交关系计算目标用户ua在tr时访问兴趣点l的预测评分:
[0052][0053]
其中,ua是推荐系统当前服务的目标对象,tr是当前推荐时间对应的时间槽,l是位置社交网络中目标用户尚未访问过的一个兴趣点,unvisit_fa表示目标用户ua的所有朋友在任何时间内均未访问过的地址集合,v为目标用户ua的一个朋友用户,fa表示目标用户ua的朋友集合,sim(ua,v)为步骤2-3中得到的用户ua和用户v的评分相似度,表示用户v在时间tr时对兴趣点l的评分。
[0054]
步骤3:统计各个兴趣点在每个时间槽内的被访问次数,将其同时与兴趣点在所有时间的总访问次数和所有兴趣点在某时间的被访问次数进行比较,计算各个兴趣点基于时间感知的动态流行度。实现步骤如下:
[0055]
步骤3-1:在原始签到数据集c中统计兴趣点l在时间槽t时的被访问次数cnum
l,t
:
[0056]
cnum
l,t
=∑
u∈u
cnum
u,t,l
ꢀꢀꢀ
公式4
[0057]
步骤3-2:在签到数据集c中统计兴趣点l被访问的总次数cnum
l
:
[0058]
cnum
l
=∑
t∈t
∑
u∈u
cnum
u,t,l
ꢀꢀꢀ
公式5
[0059]
步骤3-3:统计签到数据集c中在时间槽t的内发生的所有被访问次数cnum
t
:
[0060]
cnum
t
=∑
l∈l
∑
u∈u
cnum
u,t,l
ꢀꢀꢀ
公式6
[0061]
在公式4、公式5、公式6中,u为所有用户集合,l为所有地址集合,t为时间槽集合,cnum
u,l,t
表示在签到数据集c中某用户u在时间槽t内访问兴趣点l的次数。
[0062]
步骤3-4:通过计算兴趣点l在时间槽t的被访问次数与兴趣点l在所有时间被访问的总次数的比值得到兴趣点的纵向流行度:
[0063][0064]
其中,cnum
l,t
表示兴趣点l在时间槽t的被访问次数,cnum
l
表示兴趣点l在所有时间被访问的总次数。
[0065]
步骤3-5:通过计算兴趣点l在时间槽t的被访问次数与所有兴趣点在时间槽t的被访问次数的比值得到兴趣点的横向流行度:
[0066][0067]
其中,cnum
l,t
表示兴趣点l在时间槽t的被访问次数,cnum
t
表示所有兴趣点在时间槽t的被访问次数。
[0068]
步骤3-6:综合以上纵向比较和横向比较的结果,得出兴趣点l在时间槽t的基于时间感知的动态流行度:
[0069]
popu(l,t)=popu1(l,t)
×
popu2(l,t)
ꢀꢀꢀ
公式9
[0070]
其中,popu1(l,t)是兴趣点l在时间槽t的纵向流行度结果,popu2(l,t)是兴趣点l在时间槽t的横向流行度结果。
[0071]
汇总每个兴趣点在各个时间槽的基于时间感知的动态流行度,形成nl行24列的兴趣点-时间二维流行度矩阵p。
[0072]
步骤4:根据签到数据集中位置的经纬度信息,计算不同兴趣点之间的地理距离,基于幂律分布模型挖掘地理特征对兴趣点访问概率的影响。实现步骤如下:
[0073]
步骤4-1:假设目标用户ua已访问过的兴趣点集合为l_ua,l'∈l_ua,在签到数据集c中获取l'的地理经度lng
l'
和纬度lat
l'
,记作l'=《lng
l'
,lat
l'
》,l为目标用户从未访问过的某兴趣点,l=《lng
l
,lat
l
》。计算兴趣点l与l'之间的地理距离dist(l,l'):
[0074][0075]
其中,r是地球半径,r=6371km。
[0076]
步骤4-2:用户在不同地点的签到概率符合幂律分布,构建基于地理距离的幂律函数:
[0077]
pr(dist(l,l'))=a
×
dist(l,l')bꢀꢀꢀ
公式11
[0078]
其中,a和b是幂律函数的两个参数,可以通过极大似然估计方法得到这两个参数的数值。
[0079]
步骤4-3:计算当用户目前在兴趣点l'时,用户访问候选兴趣点l的条件概率pr(l|l'):
[0080][0081]
其中,l是所有地址的集合。
[0082]
步骤4-4:利用朴素贝叶斯方法,计算目标用户ua访问候选兴趣点l的概率:
[0083][0084]
其中,l_ua是目标用户ua已访问过的兴趣点集合。
[0085]
步骤5:综合考虑用户社交关系、位置动态流行度和地理距离对用户访问行为的影响,融合基于友谊的预测评分、兴趣点的动态流行度以及基于距离的访问概率,为目标用户生成未访问地址的最终预测评分。对所有未访问地址按最终预测评分排序,为目标用户提供排名靠前的若干个地址组成的推荐列表。实现步骤如下:
[0086]
步骤5-1:确定位置社交网络中某目标用户ua作为推荐服务对象,将当前推荐时间timer转换为时间槽tr。
[0087]
步骤5-2:综合考虑用户社交关系、位置动态流行度和地理距离对用户访问行为的影响,计算目标用户ua在tr时访问兴趣点l的预测评分:
[0088][0089]
其中,ua是推荐系统当前服务的目标对象,tr是当前推荐时间对应的时间槽,l是位置社交网络中目标用户尚未访问过的一个兴趣点,是基于社交关系计算目标用户ua在tr时访问兴趣点l的预测评分,popu(l,tr)是兴趣点l在tr时的实时流行度,pr(l|l_ua)是利用幂律分布模型挖掘地理距离影响得到的预测访问概率,l_ua是目标用户ua已访问过的兴趣点集合。
[0090]
步骤5-3:对目标用户ua未访问过的所有地址按照预测分排序,将排名靠前的n个位置组成推荐列表,并将推荐列表topnlista返回给目标用户。
[0091]
步骤6:使用精确率precision、召回率recall和综合精度指标f1作为推荐系统的准确性评价指标,对比本发明提出的推荐方法与其他相关的经典推荐方法的预测准确度,评价所提出技术的适用性和有效性。实现步骤如下:
[0092]
步骤6-1:随机选取nu
×
20%个用户作为目标用户集testu,nu表示用户总数量。为testu集合中的每个目标用户分别运行各推荐方法,生成推荐列表。
[0093]
步骤6-2:计算推荐方法在时间槽t内的精确率和召回率:
[0094][0095][0096]
其中,testu是所有目标用户的集合,r(u,t)是推荐方法在t时刻提供给某目标用户u的推荐列表,like(u,t)是用户u在t时刻真正访问过的兴趣点集合。
[0097]
步骤6-3:计算推荐方法的总体精确率和召回率,其值为各个时间槽中对应评估指标的平均值:
[0098][0099][0100]
其中,t是时间槽集合,precision(t)和recall(t)分别是推荐方法在时间槽t内的精确率和召回率。
[0101]
步骤6-4:计算推荐系统的综合准确度f1值:
[0102][0103]
其中,precision和recall分别是推荐方法运行一次的总体精确率和召回率。
[0104]
步骤6-5:重复执行步骤6-1~步骤6-4ntimes次,推荐方法的最终预测准确度(精确率precision、召回率recall和综合精度指标f1的值)为ntimes次对应指标结果的平均值。
[0105]
步骤6-6:对比分析各指标结果:如果本发明提出的基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法的精确率precision大于其他推荐方法的precision值,则说明本发明提出的技术能够帮助用户更准确地找到感兴趣的地址;如果本发明提出的技术的召回率recall大于其他推荐方法的recall值,则说明本发明提出的技术能够更全面地覆盖用户感兴趣的地址;如果本发明提出的方法的f1值大于其他推荐方法的f1值,则说明本发明提出的技术在预测准确度方面具有更强的综合能力。
[0106]
如图3-图9所示,以具体的基于位置的社交网络为例,详细说明本发明中的基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法是如何运行的。
[0107]
美国斯坦福大学snap实验室针对国外流行的位置社交网站gowalla进行了一段时间的用户签到记录收集,形成了著名的公开数据集gowalla。gowalla数据集包含了196591个用户在2009年2月至2010年10月期间在1256379个地址上的6442892条签到行为。196591个用户之间形成了950327条社交关系。本发明选择gowalla数据集中签到数据量最丰富的travis县为例进行实例化说明。
[0108]
步骤1:收集、整理原始签到数据集和社交关系数据集,分别将其转换成用户-时间-兴趣点三维评分矩阵以及二维关系矩阵。操作步骤如下:
[0109]
步骤1-1:收集、整理示例数据集gowalla中travis县的签到数据和社交数据,获得3280个用户在3335个地址上的200817条签到记录,形成签到数据集c={c1,c2,
…
,c
200817
},每一条签到记录均是由用户id、签到时间time、地理纬度、地理经度以及兴趣点id组成,如图3所示。用户之间形成了36050条社交关系,用户在gowalla网络中的社交关系记录示意图如图4所示。
[0110]
签到数据集c中的所有用户形成用户集合u,所有兴趣点形成地址集合l,用户数量nu为3280,兴趣点数量nl为3335。
[0111]
对签到记录中的签到时间进行取整,将离散的签到时间转换为24个时间槽,例如,签到时间time=00:01:25对应的时间槽为t=0,签到时间time=23:11:56对应的时间槽为t=23。时间槽集合t={0,1,2,
…
,23}。
[0112]
步骤1-2:在签到数据集c中统计某用户u在时间槽t时访问某地址l的次数,若签到次数为0,则用户u在时间槽t时对地址l的评分r
u,t,l
为0,否则,r
u,t,l
=1。汇总所有评分,形成用户-时间-兴趣点三维评分矩阵r={r
u,t,l
},其中,u∈[1,3280],t∈[0,23],l∈[1,3335]。
[0113]
步骤1-3:整理原始的社交关系数据集f,获得36050条社交关系记录,记作f={f1,f2,
…
,f
36050
}。将每一条社交关系记录形式化为《用户u
x
,用户uy》二元组,x∈[1,3280],y∈[1,3280]。
[0114]
步骤1-4:构建二维用户社交关系矩阵s={s
xy
},该矩阵的行数和列数均为3280,x∈[1,3280],y∈[1,3280],其元素s
xy
代表了用户u
x
与uy之间是否存在社交关系:
[0115][0116]
步骤2:选取基于位置的社交网络中某活跃用户作为推荐服务对象。为该目标用户删除评分矩阵中的弱相关行和弱相关列,改进传统的基于用户的协同过滤算法,为目标用户生成基于友谊的预测评分。具体操作步骤如下:
[0117]
步骤2-1:确定位置社交网络中某目标用户ua作为推荐服务对象,搜索社交关系矩阵s中目标用户ua所在的行,获取该行中元素值为1的列号(用户id),形成目标用户ua的朋友集合fa,fa集合中的元素个数记为fnuma,同时记录下该行中元素值为0的列号(用户id),形成与目标用户ua无社交关系的用户集合unfa。
[0118]
在用户-时间-兴趣点三维评分矩阵r中,若用户ui∈unfa,则在r中删除用户ui的评分信息,得到删除与目标用户ua无社交关系的用户(弱相关行)后的评分矩阵r1={r
i',t,j
},i'∈[1,fnuma],t∈[0,23],j∈[1,3335],其中i'表示用户编号,t表示时间槽的值,j表示地址编号,fnuma表示目标用户ua的朋友个数,r
i',t,j
表示用户u
i'
在时间槽t时对地址lj的评分。
[0119]
通过社交关系的筛选,有效降低了原始评分矩阵r的行规模,即|i'|=fnuma《《3280。
[0120]
步骤2-2:在评分矩阵r1中,逐个计算每个地址在所有时间槽内的评分总和,若评分总和等于0,则表示目标用户ua的所有朋友在任何时间内均未访问过此地址,将该地址加入到unvisit_fa集合中。
[0121]
若地址lj∈unvisit_fa,则在r1中删除lj的评分信息,得到删除无关地址(弱相关列)后的评分矩阵r2={r
i',t,j'
},i'∈[1,fnuma],t∈[0,23],j'∈[1,3335-|unvisit_fa|],其中i'表示用户编号,t表示时间槽的值,j'表示地址编号,fnuma表示目标用户ua的朋友个数,|unvisit_fa|表示目标用户的所有朋友均未访问过的地址数量,r
i',t,j'
表示用户u
i'
在时间槽t时对地址l
j'
的评分。
[0122]
通过无关地址的删除,在评分矩阵r1的基础上进一步降低了列规模,即|j'|=3335-|unvisit_fa|《《3335。
[0123]
步骤2-3:基于预处理后的评分矩阵r2计算目标用户ua与其朋友用户之间的评分相似度。若用户v∈fa,则目标用户ua和用户v的评分相似度为:
[0124][0125]
其中,ua是推荐系统当前服务的目标对象,v为目标用户ua的一个朋友用户,t是某个时间槽,unvisit_fa表示目标用户ua的所有朋友在任何时间内均未访问过的地址集合,|unvisit_fa|表示unvisit_fa集合中的地址数量,r
ua,t,l
和r
v,t,l
分别表示用户ua和用户v在时间t时对兴趣点l的评分。
[0126]
步骤2-4:改进传统的基于用户的协同过滤算法,利用数据压缩后的评分矩阵r2,基于社交关系计算目标用户ua在tr时访问兴趣点l的预测评分:
[0127][0128]
其中,ua是推荐系统当前服务的目标对象,tr是当前推荐时间对应的时间槽,l是位置社交网络中目标用户尚未访问过的一个兴趣点,unvisit_fa表示目标用户ua的所有朋友在任何时间内均未访问过的地址集合,v为目标用户ua的一个朋友用户,fa表示目标用户ua的朋友集合,sim(ua,v)为步骤2-3中得到的用户ua和用户v的评分相似度,表示用户v在时间tr时对兴趣点l的评分。
[0129]
步骤3:统计各个兴趣点在每个时间槽内的被访问次数,将其同时与兴趣点在所有时间的总访问次数和所有兴趣点在某时间的被访问次数进行比较,计算各个兴趣点基于时间感知的动态流行度。实现步骤如下:
[0130]
步骤3-1:在签到数据集c中统计兴趣点l在时间槽t时的被访问次数cnum
l,t
:
[0131]
cnum
l,t
=∑
u∈[1,3280]
cnum
u,t,l
ꢀꢀꢀ
公式23
[0132]
步骤3-2:在签到数据集c中统计兴趣点l被访问的总次数cnum
l
:
[0133]
cnum
l
=∑
t∈[0,23]
∑
u∈[1,3280]
cnum
u,t,l
ꢀꢀꢀ
公式24
[0134]
本发明实施案例中被访问次数最多的前三名兴趣点在各时间槽中的被访问概率示意图如图5所示。图5说明兴趣点的访问概率在不同时间槽中的差异较大。因此,探索兴趣点在各时间槽中的动态流行度非常有必要,基于时间感知挖掘兴趣点的动态流行度能够有效提高兴趣点推荐的准确度。
[0135]
步骤3-3:统计签到数据集c中在时间槽t的内发生的所有被访问次数cnum
t
:
[0136]
cnum
t
=∑
l∈[1,3335]
∑
u∈[1,3280]
cnum
u,t,l
ꢀꢀꢀ
公式25
[0137]
在公式23、公式24、公式25中,cnum
u,l,t
表示在签到数据集c中某用户u在时间槽t内访问兴趣点l的次数。
[0138]
步骤3-4:通过计算兴趣点l在时间槽t的被访问次数与兴趣点l在所有时间被访问的总次数的比值得到兴趣点的纵向流行度:
[0139][0140]
其中,cnum
l,t
表示兴趣点l在时间槽t的被访问次数,cnum
l
表示兴趣点l在所有时间被访问的总次数。
[0141]
步骤3-5:通过计算兴趣点l在时间槽t的被访问次数与所有兴趣点在时间槽t的被访问次数的比值得到兴趣点的横向流行度:
[0142][0143]
其中,cnum
l,t
表示兴趣点l在时间槽t的被访问次数,cnum
t
表示所有兴趣点在时间槽t的被访问次数。
[0144]
步骤3-6:综合以上纵向比较和横向比较的结果,得出兴趣点l在时间槽t的基于时间感知的动态流行度:
[0145]
popu(l,t)=popu1(l,t)
×
popu2(l,t)
ꢀꢀꢀ
公式28
[0146]
其中,popu1(l,t)是兴趣点l在时间槽t的纵向流行度结果,popu2(l,t)是兴趣点l在时间槽t的横向流行度结果。
[0147]
汇总每个兴趣点在各个时间槽的基于时间感知的动态流行度,形成3335行24列的兴趣点-时间二维流行度矩阵p。
[0148]
步骤4:根据签到数据集中位置的经纬度信息,计算不同兴趣点之间的地理距离,基于幂律分布模型挖掘地理特征对兴趣点访问概率的影响。实现步骤如下:
[0149]
步骤4-1:假设目标用户ua已访问过的兴趣点集合为l_ua,l'∈l_ua,在签到数据集c中获取l'的地理经度lng
l'
和纬度lat
l'
,记作l'=《lng
l'
,lat
l'
》,l为目标用户从未访问过的某兴趣点,l=《lng
l
,lat
l
》。计算兴趣点l与l'之间的地理距离dist(l,l'):
[0150][0151]
其中,r是地球半径,r=6371km。
[0152]
步骤4-2:本发明实施案例中所有用户在同一天内访问的相邻兴趣点之间的地理距离的概率分布示意图如图6所示。可以看出,用户在不同地点的签到概率符合幂律分布。构建基于地理距离的幂律函数:
[0153]
pr(dist(l,l'))=a
×
dist(l,l')bꢀꢀꢀ
公式30
[0154]
其中,a和b是幂律函数的两个参数,可以通过极大似然估计方法得到这两个参数的数值:
[0155]
首先对公式30左右两边同时取对数:
[0156]
log2(pr(dist(l,l')))=log2(a)+b
×
log2(dist(l,l'))
ꢀꢀꢀ
公式31
[0157]
令y=log2(pr(dist(l,l'))),x=log2(dist(l,l')),ω0=log2(a),ω1=b,ω=(ω0,ω1),实现线性回归:
[0158]
y(ω,x)=ω0+ω1×
x
ꢀꢀꢀ
公式32
[0159]
在学习参数ω的过程中,采用最小二乘法解决线性曲线拟合问题,定义线性回归模型损失函数为:
[0160][0161]
其中,xn是与x'n对应的真实值,λ是正则项,m是输入数据量。以最小化损失函数的值为优化目标,找到对应的参数ω的取值,进而获得幂律参数a和b的值。例如,在实施案例中,根据某一组测试用户已访问的地址之间的距离,按上述方法推算出该组测试用户幂律分布模型中的幂律参数a=0.145587,b=-0.985544。
[0162]
步骤4-3:计算当用户目前在兴趣点l'时,用户访问候选兴趣点l的条件概率pr(l|l'):
[0163][0164]
其中,l是所有地址的集合。
[0165]
步骤4-4:利用朴素贝叶斯方法,计算目标用户ua访问候选兴趣点l的概率:
[0166][0167]
其中,l_ua是目标用户ua已访问过的兴趣点集合。
[0168]
步骤5:综合考虑用户社交关系、位置动态流行度和地理距离对用户访问行为的影响,融合基于友谊的预测评分、兴趣点的动态流行度以及基于距离的访问概率,为目标用户生成未访问地址的最终预测评分。对所有未访问地址按最终预测评分排序,为目标用户提供排名靠前的若干个地址组成的推荐列表。实现步骤如下:
[0169]
步骤5-1:确定位置社交网络中某目标用户ua作为推荐服务对象,将当前推荐时间timer转换为时间槽tr。
[0170]
步骤5-2:综合考虑用户社交关系、位置动态流行度和地理距离对用户访问行为的影响,计算目标用户ua在tr时访问兴趣点l的预测评分:
[0171][0172]
其中,ua是推荐系统当前服务的目标对象,tr是当前推荐时间对应的时间槽,l是位置社交网络中目标用户尚未访问过的一个兴趣点,是基于社交关系计算目标用户ua在tr时访问兴趣点l的预测评分,popu(l,tr)是兴趣点l在tr时的实时流行度,pr(ll_ua)是利用幂律分布模型挖掘地理距离影响得到的预测访问概率,l_ua是目标用户ua已访问过的兴趣点集合。
[0173]
步骤5-3:对目标用户ua未访问过的所有地址按照预测分排序,将排名靠前的n个位置组成推荐列表,并将推荐列表topnlista返回给目标用户。n可以取值为10的倍数,通常情况下,n分别取值为10,20,30,40,50。
[0174]
步骤6:使用精确率precision、召回率recall和综合精度指标f1作为推荐系统的准确性评价指标,对比本发明提出的推荐方法与其他相关的经典推荐方法的预测准确度,评价所提出技术的适用性和有效性。实现步骤如下:
[0175]
步骤6-1:随机选取656个用户作为目标用户集testu,为656个目标用户分别运行本发明提出的基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法、经典的基于用户的协同过滤方法ubcf、基于社交关系的协同过滤方法scf、基于幂律分布的访问概率预测方法pld、基于核密度估计的访问概率预测方法kde,生成推荐列表。
[0176]
步骤6-2:计算各推荐方法在时间槽t内的精确率和召回率:
[0177][0178]
[0179]
其中,testu是所有目标用户的集合,r(u,t)是推荐方法在t时刻提供给某目标用户u的推荐列表,like(u,t)是用户u在t时刻真正访问过的兴趣点集合。
[0180]
步骤6-3:计算推荐方法的总体精确率和召回率,其值为各个时间槽中对应评估指标的平均值:
[0181][0182][0183]
其中,precision(t)和recall(t)分别是推荐方法在时间槽t内的精确率和召回率。
[0184]
步骤6-4:计算推荐系统的综合准确度f1值:
[0185][0186]
其中,precision和recall分别是推荐方法运行一次的总体精确率和召回率。
[0187]
步骤6-5:重复执行步骤6-1~步骤6-4共100次,推荐方法的最终预测准确度(精确率precision、召回率recall和综合精度指标f1的值)为100次对应指标结果的平均值。
[0188]
当n分别取值为10,20,30,40,50时,各推荐方法的精确率precision、召回率recall和综合精度指标f1结果分别如表1、表2和表3所示,其中,每一行带有加粗格式的数值表示该行指标的最大值:
[0189]
表1不同推荐方法的精确率precision指标值
[0190][0191]
表2不同推荐方法的召回率recall指标值
[0192][0193]
表3不同推荐方法的推荐精度f1指标值
[0194][0195]
在本案例中,本发明提出的推荐方法和经典的基于用户的协同过滤方法ubcf、基于社交关系的协同过滤方法scf、基于幂律分布的访问概率预测方法pld、基于核密度估计的访问概率预测方法kde的精确率precision、召回率recall和综合精度指标f1对比的柱状图分别如图7、图8和图9所示。
[0196]
步骤6-6:对比分析各指标结果:本发明提出的基于社交关系融合位置动态流行度和地理特征的兴趣点推荐方法的精确率precision大于其他所有方法的precision值,说明本发明提出的技术能够帮助用户更准确地找到感兴趣的地址;本发明提出的技术的召回率recall大于其他推荐方法的recall值,说明本发明提出的技术能够更全面地覆盖用户感兴趣的地址;本发明提出的方法的f1值大于其他推荐方法的f1值,说明本发明提出的技术在预测准确度方面具有更强的综合能力。
[0197]
有别于常规的兴趣点推荐方法,本发明以构建实时、准确、动态的兴趣点推荐系统为目标,着重考虑用户的社交关系、位置的动态流行度以及地理距离对用户签到行为的影响,创新地利用社交关系进行数据压缩,为每个用户生成个性化评分矩阵,以提高推荐系统的运行效率,同时,本发明创新地提出了兴趣点动态流行度的计算方法,通过提取兴趣点在不同时间段的不同流行度,提升评分预测的有效性,强化推荐系统的服务质量。本发明提出的技术具有广阔的应用前景,有望在国内外基于位置的社交网络市场中获得广泛的应用。
[0198]
以上所述技术流程,仅是本发明的较佳实施方式,但并不能代表本发明的所有细节。任何熟悉本技术领域的专业人员在本发明揭露的技术范围内,在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1