一种基于聚焦学习的CT血管造影智能成像方法与流程
一种基于聚焦学习的ct血管造影智能成像方法
技术领域
1.本发明涉及人工智能技术领域,尤其涉及一种基于聚焦学习的ct血管造影智能成像方法。
背景技术:
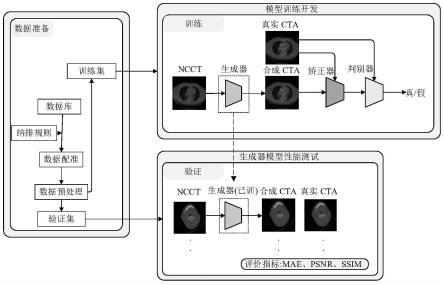
2.ct血管造影(ct angiography,cta)由于使用流程中需要造影剂,使得往返的ct扫描占用大量时间并增加相关费用,因此,需通过相关技术或手段来解决上述问题,考虑通过人工智能技术,通过构建聚焦学习的对抗网络模型,实现平扫ct(ncct)到cta的图像转换,进而减少cta检查流程,提供更快更经济的成像选择。
3.近年,随着人工智能技术的发展,出现了以pix2pix网络[isola p,et al.proceedings of the ieee conference on computer vision and pattern recognition.2017:1125-1134.]为代表的图像转换模型,较好实现了成对图像之间的模态转换。针对实际难以获得大量高质量成对的医学图像问题,研究者们尝试将cyclegan模型[zhu j y,proceedings of the ieee international conference on computer vision.2017:2223-2232.]应用于非配对医学图像模态转换中,但所取得效果有限。针对医学图像难以获得严格配对数据,非配对数据无监督学习效果有限的痛点,近来开发出了以reggan[kong l,et al..advances in neural information processing systems,2021,34:1964-1978.]为代表医学图像模态转换模型。由于当前相关模型没有考虑不同组织区域重要性差异,使得在此条件下训练获得的模型无法凸显重要区域的图像数据。
技术实现要素:
[0004]
为解决上述技术问题,本发明提供了一种基于聚焦学习的ct血管造影智能成像方法,采用了如下所述技术方案:
[0005]
一种基于聚焦学习的ct血管造影智能成像方法,其特征在于,包括以下步骤:
[0006]
步骤1、采集ncct图像和对应的真实cta图像并归一化处理,归一化后的ncct图像和对应的归一化真实cta图像作为样本对,将样本对划分为训练集、验证集和测试集;
[0007]
步骤2、构建对抗网络模型,对抗网络模型包括生成器、矫正器以及判别器;
[0008]
步骤3、构建生成器与矫正器的联合聚焦学习损失函数,构建判别器损失函数;
[0009]
步骤4、利用训练集对对抗网络模型进行训练,利用验证集对训练后的对抗网络模型进行验证;
[0010]
步骤5、将测试集中的样本对输入到生成器,生成对应的归一化合成cta图像,将获得的归一化合成cta图像进行测试评估,获得最佳测试性能的生成器;
[0011]
步骤6、加载步骤5获得的生成器,将待处理的归一化ncct图像作为生成器输入,输出归一化合成cta图像。
[0012]
如上所述生成器包括输入层、编码器、中心残差模块、解码器以及输出层,在生成器中:
[0013]
归一化ncct图像输入到输入层,
[0014]
编码器包括多层下采样卷积层,
[0015]
中心残差模块包括多个残差块,
[0016]
解码器包括多层上采样卷积层,
[0017]
除输出层以外,输入层、下采样卷积层、残差块和上采样卷积层均使用了归一化和功能激活函数,输出层将上采样卷积层的输出进行2d卷积操作并经过激活函数输出归一化合成cta图像。
[0018]
如上所述矫正器包括编码器、中心残差模块、解码器及输出端,输出端包括提炼模块和输出层,在矫正器中:
[0019]
生成器输出的归一化合成cta图像和归一化真实cta图像输入到编码器,
[0020]
编码器包括多层下采样卷积层,
[0021]
中心残差模块包括多个残差块,
[0022]
解码器包括多层上采样卷积层,
[0023]
提炼模块包括残差块和卷积层
[0024]
编码器的下采样卷积层和对应的解码器的上采样卷积层之间通过跳转连接线进行连接,
[0025]
除输出端的提炼模块和输出层,编码器的下采样卷积层、中心残差模块的残差块和解码器的上采样卷积层均使用了归一化和功能激活函数,输出层输出矫正空间矩阵。
[0026]
如上所述判别器包括多层下采样卷积层和一个2维卷积输出层,判别器的输入为归一化真实cta图像或合成的归一化cta图像,判别器输出单通道图像矩阵块,单通道图像矩阵块经平均池化后,获得对应的池化值。
[0027]
如上所述步骤3中的生成器与矫正器的联合聚焦学习损失函数l
gr
定义为:
[0028][0029]
l
gan
(g,d)=e
x
[(1-d(g(x)))2]
[0030][0031][0032]
l
gan
(g,d)为对抗损失函数,d为判别器,g为生成器,m为聚焦尺度数,bi为第i个的加权系数,为矫正损失函数,γ为l
smoot h
的加权系数,l
smoot h
为平滑损失函数;e(.)为期望运算符,下标为输入变量,x为生成器g输入的归一化的ncct图像,y为归一化真实cta图像,
°
对应于重采样操作,r为矫正器,为梯度运算符为,||.|||1为l1距离运算符。
[0033]
如上所述步骤3中判别器损失函数l
adv
(g,d)定义为:
[0034]
minl
adv
(g,d)=ey[(1-d(y))2]+e
x
[d(g(x))2]。
[0035]
如上所述步骤4中的对抗网络模型进行训练具体包括以下步骤:
[0036]
首先,判别器参数固定不变,计算最小化的联合聚焦学习损失函数l
gr
的值,进而实现对生成器和矫正器的参数更新;
[0037]
其次,生成器与矫正器参数保持固定不变,计算最小化的判别器损失函数l
adv
(g,d)的值,进而对判别器参数进行优化更新。
[0038]
如上所述步骤5中的测试性能包括归一化合成cta图像的平均绝对误差(mae)和峰值信噪比(psnr),还包括归一化合成cta图像与归一化真实cta图像的结构相似度(ssim)。
[0039]
本发明相对于现有技术,具有以下有益效果:
[0040]
1、本发明提供了基于聚焦学习的ct血管造影智能成像方法,减少造影剂使用的必要性;
[0041]
2、本发明构建了生成器与矫正器的联合聚焦学习损失函数,使得所述生成器合成cta图像能够更好的凸显血管组织;
[0042]
3、本发明引入了矫正器,使得ncct图像与cta图像之间更好的配准对齐,从而更好的建立ncct图像与cta图像之间的映射关系,合成cta图像质量更好;
[0043]
4、本发明具有较好的鲁棒性和扩展性,易于模块化集成和分布式使用。
附图说明
[0044]
图1为本发明的对抗网络模型的网络架构示意图;
[0045]
图2为本发明的生成器g的网络架构示意图;
[0046]
图3为本发明的矫正器r的网络架构示意图;
[0047]
图4为本发明的判别器d的网络架构示意图。
具体实施方式
[0048]
为了便于本领域普通技术人员理解和实施本发明,下面结合实例对本发明作进一步的详细描述,此处所描述的实施示例仅用于说明和解释本发明,并非是对本发明的限制。
[0049]
实施例1
[0050]
如图1所示,一种基于聚焦学习的ct血管造影智能成像方法,包括以下步骤:
[0051]
步骤1、采集ncct图像和对应的真实cta图像并依次进行质量检查、归一化处理,归一化后的ncct图像和对应的归一化真实cta图像作为样本对,将样本对划分为训练集、验证集和测试集:
[0052]
质量检查准则按照以下纳排规则中的一种或者多种:(1)ncct图像与对应的真实cta图像的扫描间隔时间不超过1个月;(2)ncct图像与对应的真实cta图像的层厚和层数一致,且层面对应;(3)ncct图像和对应的真实cta图像是否规则存放;(4)ncct图像或真实cta图像不存在严重伪影;(5)ncct图像或真实cta图像扫描正常,成像充盈;(6)动脉未进行过手术,如动脉瘤术等;
[0053]
将ncct图像和对应真实cta图像的原始灰阶空间由[-1024 3071]归一化至[-1 1],以加速模型训练收敛;
[0054]
将归一化后的ncct图像和对应的真实cta图像作为样本对,将各个样本对按照6:1:3比例,随机划分为训练集、验证集和测试集以供模型的训练、验证和测试。
[0055]
步骤2、基于非线性组合理论构建对抗网络模型:利用卷积网络分别构建生成器、矫正器、判别器:
[0056]
步骤2.1构建生成器,本实施例所述的生成器模型框架如图2所示,生成器结构依次包括输入层、编码器、中心残差模块、解码器以及输出层。进一步的,编码器包括2层下采样卷积层,中心残差模块包括9个残差块,解码器包括2层上采样卷积层。
[0057]
输入层通道数变化为1-》64,编码器的2层下采样卷积层通道数变化依次为64-》128和128-》256,中心残差模块中各个残差块的通道数均为256,解码器的2层上采样卷积层的通道数变化依次为256-》128和128-》64,输出层通道数变化为64-》1。生成器的输入层和输出层的卷积核为7
×
7,卷积步长为1,卷积补零数为3。编码器与解码器的卷积核均为3
×
3,卷积步长为2,卷积补零数为1。中心残差模块各残差块的卷积核均为3
×
3,卷积步长和卷积补零数均为1。除输出层,输入层、下采样卷积层、残差块和上采样卷积层都使用了instancenormal2d归一化和relu功能激活函数,最终输出层将上采样卷积层的输出进行2d卷积操作并经过tanh激活函数输出归一化合成cta图像。
[0058]
输入层和输出层的维度均为样本批次数目
×
图像通道数
×
图像宽度
×
图像高度。其中本实施例一次训练的样本批次数目为1,输入至输入层的图像通道数与输出层输出的图像通道数均为1,图像宽度为512,图像高度为512;输入层的输入为归一化ncct图像,输出层的输出为归一化合成cta图像。
[0059]
编码器实现将输入的归一化ncct图像编码为深层特征,中心残差模块将编码的深层特征进行多次卷积操作后获得更具目标图像的深层特征,解码器则将中心残差模块输出的特征解码为目标图像。
[0060]
步骤2.2构建矫正器,本实施例所述的矫正器模型框架如图3所示,矫正器主干网络包括编码器、中心残差模块、解码器及输出端,输出端包括一个提炼模块和输出层。矫正器的输入为生成器输出的归一化合成cta图像和归一化真实cta图像,其输出为归一化合成cta图像与归一化真实cta图像之间的矫正空间矩阵。
[0061]
编码器包括多层下采样卷积层,解码器包括多层上采样卷积层,下采样卷积层的层数与上采样卷积层的层数相同,编码器的下采样卷积层和对应的解码器的上采样卷积层之间通过跳转连接线进行连接。本实施例中编码器包括7个下采样卷积层,中心残差模块包括3个残差块,解码器包括7个上采样卷积层,提炼模块包括1个残差块和一个卷积层。中心残差模块前后分别带有一个卷积核为1
×
1,卷积步长为1,无卷积补零数的卷积层。下采样卷积层、中心残差模块的残差块、上采样卷积层以及提炼模块的残差块的卷积核均为3
×
3,卷积步长均为1,卷积补零数均为1,激活函数均为leakyrelu。提炼模块中卷积层的卷积核为1
×
1,步长为1,卷积补零数为0。输出层的卷积核为3
×
3,卷积步长为1,补零数为1,无激活函数。
[0062]
如图3所示,由于编码器的下采样卷积层和对应的解码器的上采样卷积层之间跳转连接,解码器的各个上采样卷积层的输入来源包括两方面:上一级的输出和当前级上采样卷积层对应的编码器的下采样卷积层的输出,故解码器的上采样卷积层的输入通道数为c1+c2形式:c1表示上一级的输出通道数,如第1级解码器的上采样卷积层对应的c1值为中心残差模块后卷积层输出的通道数,第2级解码器的上采样卷积层对应的c1值为第1级解码器的上采样卷积层的输出通道数,以此类推;c2为当前级解码器的上采样卷积层对应的编码器的下采样卷积层的输出通道数;解码器的上采样卷积层输出的通道数与当前级上采样卷积层对应的编码器下采样卷积层的输出通道数相同。
[0063]
本实施例中具体为,编码器的7个下采样卷积层通道数变化依次为2-》32、32-》64、64-》64、64-》64、64-》64、64-》64、64-》64,编码器的输入为生成器输出的归一化合成cta图像和归一化真实cta图像,故第一级下采样卷积层输入的通道数为2,中心残差模块前卷积
层通道数变化为64-》128,中心残差模块中各个残差块的通道数为128,中心残差模块后卷积层的通道数变化为128-》64,解码器的7个上采样卷积层通道数变化依次为64+64-》64、64+64-》64、64+64-》64、64+64-》64、64+64-》64、64+64-》64、64+32-》32。提炼模块的通道数为32。输出层的通道数变化为32-》2。除输出端的提炼模块和输出层,编码器的下采样卷积层、中心残差模块的残差块和解码器的上采样卷积层均使用了instancenormal2d归一化和leakyrelu功能激活函数,最终由输出层输出矫正空间矩阵。
[0064]
本实施例输出的矫正空间矩阵的维度为[样本批次数目,输出层的通道数,图像宽度,图像高度],本实施例中为[1,2,512,512]。
[0065]
步骤2.3判别器的构建,用于判别给定图像是否为归一化真实cta图像。
[0066]
本实施例的判别器模型框架如图4所示,判别器包括4层下采样卷积层和一个2维卷积输出层。每个下采样卷积层使用了leakyrelu功能激活函数和instancenormal2d归一化,判别器所有卷积操作均使用4
×
4卷积核。前三层下采样卷积步长为2,补零数为1,第4层下采样和输出卷积层的卷积步长为1,补零数为1。判别器的输入为归一化真实cta图像或归一化合成cta图像,通过判别器的多层卷积操作之后,输出获得62
×
62的单通道图像矩阵块。其单通道图像的矩阵块经过torch的avg_pool2d函数(池化层)平均池化后,获得对应的池化值。
[0067]
步骤3、针对构建的对抗网络模型设计:生成器与矫正器的联合聚焦学习损失函数、判别器损失函数。通过对矫正损失的聚焦设计,使得生成器与矫正器的联合学习聚焦于目标区域。
[0068]
生成器与矫正器的联合聚焦学习损失函数lar定义为:
[0069][0070]
l
gan
(g,d)=e
x
[(1-d(g(x)))2]
[0071][0072][0073]
其中:
[0074]
l
gan
(g,d)为对抗损失函数;d为判别器;g为生成器;m为聚焦尺度数,本实施例中m=2;bi为第i个的加权系数,本实施例中b1=20,b2=2,为矫正损失函数,不同i值对应不同的聚焦区域,本实施例中i取值为1、2,i=1时计算y和g(x)
°
r(g(x),y)的全图像损失,i=2时计算y和g(x)
°
r(g(x),y)的区域滤波图像损失,将真实cta图像的dicom文件的默认窗中的归一化图像hu值大于0.65阈值的区域定义为滤波区域,即区域滤波图像;γ为l
smoot h
的加权系数,本实施例中γ取值为10,l
smoot h
为平滑损失函数;e(.)为期望运算符,下标为输入变量;x为生成器g输入的归一化ncct图像,g(x)为生成器的输出,即归一化合成cta图像;y为归一化真实cta图像;
°
对应于torch库中的grid_sample()重采样操作;r为矫正器,r(g(x),y))为矫正器训练输出的矫正空间矩阵,用于对生成器的输出g(x)进行矫正,获得矫正后的归一化合成cta图像g(x)
°
r(g(x),y);为梯度运算符,||.|||1为l1距离运算符。
[0075]
判别器损失函数l
adv
(g,d)定义为:
[0076]
minl
adv
(g,d)=ey[(1-d(y))2]+e
x
[d(g(x))2]。
[0077]
其符号含义同生成器及矫正器中的损失函数符号含义。
[0078]
步骤4、利用训练集对构建好的对抗网络模型进行训练,利用验证集对中间训练模型进行验证,具体步骤为:
[0079]
首先,判别器参数固定不变,依据归一化合成cta图像、矫正后的归一化合成cta图像以及归一化真实cta图像计算最小化的联合聚焦学习损失函数l
gr
的值,进而实现对生成器和矫正器参数更新。
[0080]
其次,生成器与矫正器的参数保持固定不变,将归一化合成cta图像和归一化真实cta图像分别送入已构建好的判别器计算得到最小化的判别器损失函数l
adv
(g,d)的值,利用计算所获得的损失值对判别器参数进行优化更新。
[0081]
最后,利用验证集数据对训练更新后的中间模型进行验证测试,评估其模型迭代更新的正确性和有效性。
[0082]
本实例实验平台为nvidia geforce rtx3090ti gpu及64gb内存的linux系统服务器,python版本为3.8。
[0083]
所述模型构建选用pytorch作为深度学习框架,优化器为adam,生成器、矫正器以及判别器的初始学习率均为0.0001,没有衰减策略,模型迭代次数epoch=80。
[0084]
步骤5、模型测试
[0085]
使用测试集对步骤4得到的的对抗网络模型的生成器进行测试评估:将归一化ncct图像输入步骤4得到的对抗网络模型的生成器,获得归一化合成cta图像,同归一化真实cta图像进行测试评估,将获得最佳测试性能的模型定为最终的使用模型。
[0086]
所述性能测试指标包括归一化合成cta图像的平均绝对误差(mae)和峰值信噪比(psnr),还包括归一化合成cta图像与归一化真实cta图像的结构相似度(ssim)。
[0087]
步骤6、模型使用
[0088]
加载步骤5得到的生成器,将待处理的归一化ncct图像作为生成器的输入,输出即为归一化合成cta图像。
[0089]
将所述生成器输出的归一化[-1 1]合成cta图像依据归一化反操作重构至原始灰阶空间[-1024 3071],获得原始灰阶下的合成图像。
[0090]
将原始灰阶空间下的合成图像转为二进制格式并赋值dicom头文件中的pixeldata,其它dicom头文件信息与ncct图像的头文件保持一致,自此获得合成cta图像。
[0091]
一种基于聚焦学习的ct血管造影智能成像装置,包括第一模块、第二模块、第三模块、第四模块、第五模块和第六模块,上述步骤1至步骤6分别由第一至第六模块实现。
[0092]
本发明并不限于上述实施方式,上述实施例仅是对本发明的优选实施例进行描述,并非对本发明的构思进行限定,上述实施例中的实施方案可以进一步组合或者替换,本领域技术人员对本发明的技术方案作出的各种变化和改进,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1