一种多方向邻域搜索嵌入的多目标演化算法及智慧物流SaaS系统
一种多方向邻域搜索嵌入的多目标演化算法及智慧物流saas系统
技术领域
1.本发明涉及智慧物流技术领域,尤其涉及一种多方向邻域搜索嵌入的多目标演化算法及智慧物流saas系统。
背景技术:
2.随着城市人口激增,城市配送需求市场日渐旺盛。面对日益复杂的物流场景,传统方法已不能满足客户和商家日益增长的物流需求。近些年来,依赖于城市物流saas(software as a service)平台,无车承运模式越来越受到从业者的重视。无车承运平台所涉及的利益相关者众多,包括平台、合同司机、临时司机、市民和政府等。如何均衡多方利益相关者的利益关切是无车承运平台有序有效运行的关键。
3.相较于精确方法,计算智能方法论中的演化计算方法可有效解决智慧物流诸多场景中的若干组合优化问题。演化计算方法较少地依赖模型表示,可以快速找到复杂优化问题的可行解。然而,随着问题规模的增大,解空间也随之增大,单纯依赖演化计算方法很难找到全局最优解。另一方面,计算规模的增大也增加了计算资源的计算负担,这将会导致计算设备性能的弱化,造成了现实环境中算法鲁棒性下降。
4.最早被用于处理多目标车辆路径问题的优化技术主要有聚合技术和两阶段优化技术。以上两种技术均需要提前确定目标的优先级别,甚至是权重值,算法性能较大依赖于决策者的偏好。gong等(2012)提出了基于集合的离散粒子群算法,用反正弦函数标准化行驶距离,并将标准化的距离值加到车辆数目上形成聚合目标函数。gong等(2012)的方法避免了权重值的设定,但仍然保有对车辆数目的偏好信息。另外,基于聚合技术和两阶段优化技术的多目标优化方法一般仅能提供单一解,无法保证pareto集合的多样性。
5.基于支配的和基于分解的多目标演化算法是求解多目标优化问题常用的算法框架,起源性研究主要包括nsga-ii和moea/d。基于以上两种多目标优化框架,研究者和从业者们开发了若干有效的多目标优化算法用于求解多目标车辆路径问题。然而,无车承运saas物流系统所涉及的利益相关者往往超过三个,所对应的优化问题为高维多目标优化问题。
6.传统多目标优化算法在处理高维优化问题时具有一定的局限性:随优化目标增多,非支配解集中解的数目一般会急剧增多,造成算法丧失进化压力。另一方面,目前采用高维多目标演化算法解决高维组合优化问题的研究尚不多见,更少见于车辆路径优化领域。最近,anwar等(2020)提出了改进的dbea算法用于求解带车辆拖延时间的取送货车辆路径问题。该研究中优化目标为六个,这也是为数不多的高维多目标车辆路径问题相关研究之一。
7.从技术瓶颈上分析,关于多目标演化算法在复杂多目标离散优化问题上应用较少的原因大致有二:(1)大多数组合优化问题解的表示方式与一般演化算法解的表示方法不完全一致,一般实数映射的方法对复杂组合优化问题编码效率低,即使是整数编码方法也
存在频繁修复的现象;(2)邻域搜索算法是提高(高维)多目标演化算法精度的有效技术手段,而传统邻域搜索方法论却难以用于高维多目标演化算法精英解在多个目标上的改进。
技术实现要素:
8.本发明的目的在于提出一种有效解决传统多目标演化算法收敛慢问题的多方向邻域搜索嵌入的多目标演化算法及智慧物流saas系统。
9.为达到上述目的,本发明提出一种多方向邻域搜索嵌入的多目标演化算法,建立基于种群的多方向邻域搜索算法;所述多方向邻域搜索算法对当前种群所有个体进行排序,多层pareto前沿参与多方向变邻域搜索;所述多方向变邻域搜索算法所采用的局部搜索算子分别针对高维多目标车辆路径问题模型的多个目标;
10.所述多方向邻域搜索算法如下:
11.输入:当前种群pop
t
;目标个数m
ma
;领域结构n
μ
,μ=1,2,....,μ
max
12.newpop
←
pop
t
13.对newpop非支配排序:(pf1,pf2,...,pf
lmax
)=nondominatedsort(newpop)
14.#l
max
为非支配前沿个数
[0015][0016]
newpop=crowdupdate({pf
l
})#拥挤距离排序后,删除多余个体
[0017]
输出:newpop;
[0018]
将所述多方向变邻域搜索算法嵌入高维多目标演化算法,所述高维多目标演化算法如下:
[0019]
input:案例参数:目标个数为m;算法参数:种群规模为n,参考集规模为h,最大迭代次数为itermax
[0020]
初始化种群pop1={popi}
[0021]
for t=1:itermax
[0022]
基于参数点zs或理想点za,生成h个结构化的参考向量
[0023]
j=1
[0024]
锦标赛选择后执行交叉算子:q
t
=recombination(pop
t
)
[0025]
按照概率执行变异算子,更新种群q
t
[0026]ut
=pop
t
∪q
t
[0027]
非支配排序(f1,f2,...)=nodominatedsort(u
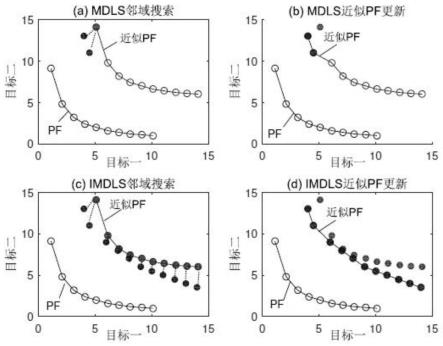
t
)
[0028]
repeats
t
=s
t
∪fj,j=j+1.until|s
t
|≥n
[0029]
最后一个被加入到s
t
的帕累托前沿记为f
l
[0030]
if|s
t
|=nthen
[0031]
pop
t+1
=s
t
,break
[0032]
else
[0033][0034]
计算从f
l
上选择点的个数:k=n-|pop
t+1
|
[0035]
标准化目标函数,生成参考集合:zr[0036]
使与参考点关联
[0037]
计算参考点的小生境
[0038]
从f
l
中选择k个个体用以扩充种群pop
t+1
[0039]
end if
[0040]
判断是否满足多方向领域搜索条件,若满足则执行领域搜索过程
[0041]
end for
[0042]
output:ps和pf。
[0043]
进一步的,所述高维多目标车辆路径问题模型的目标包括成本目标、服务水平目标、等待时间目标和公平性目标。
[0044]
本发明还一种智慧物流saas系统,包括以下步骤:
[0045]
步骤1:建立优化的高维多目标车辆路径问题模型;
[0046]
所述模型包括成本目标、服务水平目标、等待时间目标和公平性目标的计算;
[0047]
步骤2:获取客户信息;
[0048]
步骤3:采用路径内和路径间relocate操作,并针对每个优化目标进行变邻域下降搜索;
[0049]
步骤4:建立多方向搜索的变邻域搜索算法;
[0050]
步骤5:将所述多方向变邻域搜索算法嵌入高维多目标演化算法,对模型多目标进行优化;
[0051]
步骤6:采用可变长度的矩阵编码方法结合基于路径的交叉方法,高效地产生子代解。
[0052]
进一步的,在步骤1中,所述成本目标包括固定出车成本、油耗成本和碳排放成本;
[0053]
所述固定出车成本为:
[0054]
所述油耗成本为:
[0055]
所述碳排放成本为:
[0056]
进一步的,在步骤1中,所述服务水平目标的计算方法为:
[0057]
式中,pri为客户i∈c配送优先权值,采用专家打分的方法,标准化到[1,100]区间,越大客户越重要ui的计算方法;
[0058]
进一步的,等待时间目标为:
[0059]
为刻画公平性,提出了针对任意司机p'公平感知系数
[0060]
其中,fai
p
和fai
p'
分别为p和p'的单位时间收益。
[0061]
进一步的,公平性目标为:
[0062]
进一步的,所述高维多目标车辆路径问题模型的约束条件包括:司机工作时间约束、车辆行驶里程约束和车载量约束。
[0063]
进一步的,在步骤2中,从订单管理软件获取客户信息,包括客户点位置、需求量以及服务时间窗;通过地图api获取待服务客户的距离矩阵。
[0064]
进一步的,所述路径的交叉方法的原理为:通过交换染色体中的优良路径,以实现种群的进化。
[0065]
与现有技术相比,本发明的优势之处在于:本发明研究利用了一种变长度矩阵编码技术对解进行编码,并打通了演化搜索过程和邻域搜索过程。由于本发明对种群的多个非支配解集分别进行邻域搜索,种群在加速收敛的同时也保证了多样性。
附图说明
[0066]
图1为本发明实施例中编码及解码的示意图;
[0067]
图2为本发明实施例中路径的交叉方法示意图;
[0068]
图3为本发明实施例中mdls改进示意图。
具体实施方式
[0069]
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案作进一步地说明。
[0070]
为方便描述,将本发明所优化的高维多目标车辆路径问题记为maovrp。为方便阅读,现将maovrp相关参量符号化,如表1所示。
[0071]
表1(a)集合及其含义
[0072]
符号含义符号含义n包括客户点和车场的点集a弧集合
c客户集合p合同车辆集合k临时车辆集合ku被使用临时车辆集合0车场
ꢀꢀ
[0073]
表1(b)参数及其含义
[0074][0075][0076]
maovrp建模于完全图g=(n,a)。任意弧(i,j)∈a均对应点i和点j之间的行驶时间t
ij
和行驶距离d
ij
,且均满足三角不等式。对于任一点i∈n,均对应时间窗(ei,li),需求量qi和服务时间si。maovrp中的车辆为相同车型,但合同车辆较临时车辆有如下两点差异:1)合同车辆有车辆数目限制;2)合同车辆的单日出车成本要低于临时车辆。maovrp的优化目标有四个,包括成本目标、服务水平目标、等待时间目标和公平性目标。
[0077]
本发明所研究问题的成本目标包括固定出车成本、油耗成本和碳排放成本。
[0078]
固定出车成本为:
[0079]
油耗成本为:
[0080]
为建模方便,本章采用xiao(2012)等的线性油耗模型,如公式:
[0081]
借助xiao(2012)等的线性油耗模型易于计算系统的碳排放成本:
[0082][0083]
考虑到现实物流配送过程中客户具有异质性:一方面,客户的重要程度不同;另一方面,客户对延迟交货的敏感度不同。本发明采用了一种兼顾客户优先权和交货及时度的服务指标。服务水平目标计算方法为:
[0084]
其中,pri为客户i∈c配送优先权值,采用专家打分的方法,标准化到[1,100]区间,越大客户越重要ui的计算方法。早到对满意度影响较小,晚于客户提交的时间窗上限,满意度非线性下降,在时间窗内交付完全满意。计算方法如公式(6)所示:
[0085][0086]
为从时间维度刻画交货的便利性,需考虑服务等待时间,等待时间目标为:
[0087]
为刻画公平性,本发明提出了针对任意司机p'公平感知系数其中,fai
p
和fai
p'
分别为p和p'的单位时间收益。公平性目标为
[0088]
maovrp的约束条件包括:1)司机工作时间约束;2)车辆行驶里程约束;3)车载量约束(载重与体积)。
[0089]
参数设定:
[0090]
为验证本文高维多目标优化技术的优势,maovrp相关参数如表2所示。其中,nsga-iii参数参考原始文献。
[0091]
表2关键参数
[0092]
参数含义值单位wt最长工作时间10小时td总行驶距离200公里qw最大载重量2吨qv最大装载体积3立方米μ0空载油耗率8升/公里
μ
*
满载油耗率10升/公里ef碳排放转化因子2.37千克/升
[0093]
由于传统多目标演化算法在求解高维多目标车辆路径问题的局限性,本发明提出了基于种群的多方向搜索嵌入的高维多目标演化方法。
[0094]
信息的获取:从订单管理软件获取客户信息,包括客户点位置、需求量以及服务时间窗;通过地图api获取待服务客户的距离矩阵。
[0095]
编码方法及交叉方法:本发明采用可变长度的矩阵编码方法,以利于演化算法和邻域搜索的信息传递。编码解码示意图如图1所示。其中,第一行为路径编号部分,每一位对应一条配送路径;客户自上到下配送优先权依次增加;cd表示合同司机,括号后编号为具体司机;od表示临时司机,括号后编号为具体司机。
[0096]
本发明采用基于路径的交叉方法,示意图如图2所示,该方法原理为:通过交换染色体中的优良路径(基因),以实现种群的进化。
[0097]
具体步骤为:
[0098]
·
随机挑选两染色体作为父代染色体(如图中的parent 1和parent 2);
[0099]
·
分别找出两个染色体的有优良路径。优良路径挑选的一般标准为单位客户服务成本(路径总服务成本/客户点个数)。为简化起见,假定parent 1的优良路径为“6-10”,假定parent 2的优良路径为“1-3-7”;
[0100]
·
分别将优良路径插入到另一个染色体中;
[0101]
·
针对重复点问题,进行染色体修复:对于那些在原染色体路径中存在,也在新插入路径中存在的客户点,将其从老路径中删除(如红色方框中客户点)。
[0102]
多方向搜索的邻域操作算子:本发明采用路径内和路径间relocate操作,并针对每个优化目标进行变邻域下降搜索(variable neighborhood descent,vnd)。
[0103]
多方向搜索的变邻域搜索算法:
[0104]
如果邻域解x'∈n(x)至少在一个目标上优于当前解x,则说明:或者是x'支配x或者是x'与x不可比较。因此,在多目标优化过程中,一次充分提升一个目标则可能发现理想的邻域解。受此启发,tricoire(2012)提出了多方向邻域搜索算法(multi-direction local search,mdls)。随后,lian等(2016)改进了mdls,提出了imdls:1)pareto前沿面pf上多个非支配解同时执行多方向搜索;2)为减少计算开销,整个多方向搜索过程中维持前沿面上非支配解数目为一常数;3)拥挤距离排序用于前沿面pf上解的维护。mdls与imdls对比示意图如图3所示。
[0105]
通过图3可以看出,相较于mdls,imdls可深度搜索最优帕累托前沿,提升了收敛速度。然而,imdls技术如果嵌入基于种群的演化算法,极易造成种群多样性的下降。为了充分利用种群信息,避免种群提前陷入局部最优,本发面提出了基于种群的多方向邻域搜索算法,并记为pmdls(population-based mdls,pmdls),主要有如下改进:1)对当前种群所有个体进行排序,多层pareto前沿参与多方向变邻域搜索;2)多方向变邻域搜索所采用的局部搜索算子分别针对maovrp的四个目标。pmdls算法框架如算法所示。
[0106]
输入:当前种群pop
t
;目标个数m
max
;领域结构n
μ
,μ=1,2,....,μ
max
newpop
←
pop
t
[0107]
对newpop非支配排序:(pf1,pf2,...,pf
lmax
)=nondominatedsort(newpop)
[0108]
#l
max
为非支配前沿个数;为第l个帕累托前沿
[0109][0110]
对所有帕累托前沿进行非支配排序newpop=crowdupdate({pf
l
})#拥挤距离排序后,删除多余个体
[0111]
输出:newpop。
[0112]
为便于阐述本发明所提出的多方向邻域搜索策略嵌入高维多目标演化算法的有效性,本研究拟采用求解约束优化问题的nsga-iii算法作为基本算法。
[0113]
总体上来说,nsga-iii和nsga-ii具有类似的框架,二者区别主要在于选择机制上的差异。nsga-ii主要靠拥挤度进行排序,而nsga-iii则是通过引入广泛分布的参考点来维持种群的多样性。而且,nsga-iii采用了一种约束支配准则:1)可行解对不可行解具有支配性;2)小违反量的解对大违反量的解具有支配性。
[0114]
多方向邻域搜索嵌入的高维多目标演化算法:
[0115]
input:案例参数:目标个数为m;算法参数:种群规模为n,参考集规模为h,最大迭代次数为itermax
[0116]
初始化种群pop1={popi}
[0117]
for t=1:iter
max
[0118]
基于参数点zs或理想点za,生成h个结构化的参考向量j=1
[0119]
锦标赛选择后执行交叉算子:q
t
=recombination(pop
t
)
[0120]
按照概率执行变异算子,更新种群q
t
[0121]ut
=pop
t
∪q
t
[0122]
非支配排序(f1,f2,...)=nodominatedsort(u
t
)
[0123]
repeat s
t
=s
t
∪fj,j=j+1.until|s
t
|≥n
[0124]
最后一个被加入到s
t
的帕累托前沿记为f
l
[0125]
if|s
t
|=nthen
[0126]
pop
t+1
=s
t
,break
[0127]
else
[0128][0129]
计算从f
l
上选择点的个数:k=n-|pop
t+1
|
[0130]
标准化目标函数,生成参考集合:zr[0131]
使与参考点关联
[0132]
计算参考点的小生境
[0133]
从f
l
中选择k个个体用以扩充种群pop
t+1
[0134]
end if
[0135]
判断是否满足多方向领域搜索条件,若满足则执行领域搜索过程
[0136]
end for
[0137]
output:帕累托解集ps和帕累托前沿pf。
[0138]
上述仅为本发明的优选实施例而已,并不对本发明起到任何限制作用。任何所属技术领域的技术人员,在不脱离本发明的技术方案的范围内,对本发明揭露的技术方案和技术内容做任何形式的等同替换或修改等变动,均属未脱离本发明的技术方案的内容,仍属于本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1