一种基于字符串文本特征相似度的黑名单模糊匹配方法与流程
1.本发明涉及电子信息技术领域,特别涉及一种基于字符串文本特征相似度的黑名单模糊匹配方法。
背景技术:
2.在数字信贷中如何侦测出注册文字是否存在违规字样是一个非常重要的问题。用户在申请贷款的过程中,往往需要填写姓名,出生地,居住地等信息。而针对某些出现过问题的历史客户,或者一些可疑的用户信息,往往需要在贷前就发送提醒给审核人员。
3.为了精准快速识别通常的方法会针对敏感的字符串建立一个黑名单库。当确认输入字符串是否合法时,会查询一遍黑名单库,若字符串在黑名单中,则会拒绝申请。传统的方法往往对字符串进行分割并对产生的小字符串或字符两两匹配进行查询。
4.然而如何切割字符串是一个技术难点,当前的方法往往针对某一类场景,比如地址,姓名等场景建立一个有先验知识的字符串库,根据这些字符串库进行字符串匹配补全,再分词。比如,在地址信息中根据
‘
省’,市,这类字符进行切割。或者找到
‘
上海’,
‘
北京’这类词,在后面这类方法解释性强,但是泛用性不强,遇到未知场景时效果不佳。
5.同时有些欺诈团伙为了躲避黑名单会修改部分字符串。比如“张三”,变成“张三1”,“张三a”,
‘
张_三’等等变种字符串,那么传统的分词和匹配方法会往往会失效。现在主流的对抗方法有如使用模糊代码等方法对字符串进行编码,但是这种方法需要对分词方法有先验知识。或者又有如
‘
fuzzywuzzy’,
‘
sequencematcher’等根据,寻找最长连续子序列,或者字符的出现频率这类方法去查找,但是当字符串颠倒顺序,或者字符串过短时,容易失效。
6.再同时如果字符串中同时还有多种语言的字符,尤其是当注册时用拼音代替原中文字符时,用一种语言音译成另一种语言时,往往就能绕过黑名单,完成注册。同时中文字符串如姓名,出生地等字符串过短,可能导致编码困难,使得匹配过程中对此类字符不敏感。
7.最后,针对不同的字符串处理方式,如何在黑名单海量字符串中找到对应的字符串也是需要关注的问题。现在常见的场景是构建哈希表,再根据之前编码的形态或者分词方法来决定匹配方法,但是主要的问题还是在于之前的方法可能具有较强的针对性,不适用于通用场景。
8.所以针对黑名单匹配的主要难点在于:一、如何对各种场景的字符串进行分割,二、如何识别被修改微调的字符串,提高针对变种字符串的抗干扰能力;三、如何处理各种语言的字符,提高针对多语言字符串的抗干扰能力;四、如何在大规模的黑名单中实时匹配到目标字符串。
技术实现要素:
9.本发明要解决的技术问题是克服现有技术的缺陷,针对在信贷申请过程中输入的
字符串若存在于黑名单中,如何提前对黑名单进行预处理、分词并且编码,并且在实时字符串输入后,能够给出在黑名单中存在的对应相似字符及其变种。本发明将公开一种基于文本特征相似度的黑名单模糊匹配方法,在离线情况下针对整个黑名单库,先使用英文注音针对字符量较少的非英文字符串进行语义补充,去除空格字符统一大小写,然后使用按不同长度的间隔切割字符串再合并切割结果的方法进行分词,并使用深度学习技术实现对被分割的字符串编码,在离线情况下完成黑名单特征的编码,并获得编码字典。在实时运作时,将输入的字符串进行相同的字符串分割操作,并根据编码字典进行编码,最后并使用余弦相似度找出在黑名单中编码最相似的10个单词,完成一次模糊匹配。
10.本发明提供了如下的技术方案:
11.本发明提供一种基于字符串文本特征相似度的黑名单模糊匹配方法,包括以下步骤:
12.s1:黑名单字符串预处理模块,在离线情况下对已有的黑名单中过短的非英文字符串进行注音;再去除所有空格字符,并将所有英文字符全部变为小写字符;
13.s2:黑名单字符串分割模块,在离线情况下将预处理后的黑名单中每个字符串按不同长度进行文字分割,得到对应的短字符串组;最后将短字符串组合并,得到与原字符串对应的分割完的字符串组;
14.s3:黑名单文字特征训练编码模块,在离线情况下对分割完的字符串组进行特征训练,得到特征编码库;并根据特征编码库对预处理后黑名单中的字符串进行编码;
15.s4:数据采集预处理模块,接收在线输入的字符串,并类似s1规则若是过短的非英文字符串则注音;再将字符串进行与s2相同的字符串分割方法得到对应字符串组;
16.s5:输入字符串特征编码模块,将s3得到的字符串组根据离线情况下获得的特征编码库d中寻找每个字符串对应的特征并累加;最后再把累加得到的特征进行归一化;
17.s6:相似度检索与输出模块,将s4得到的输入字符串的特征,与黑名单的每个字符串编码计算余弦相似度;再按得到的值的大小排序,选出最小的十个字符串,得到最后的模糊匹配结果。
18.作为本发明的一种优选技术方案,上述步骤s1中包含:
19.s1.1:将已有的黑名单a中的少于8个字符的字符串(不包括空格字符)通过音译,统一在原名单后加上英文注音。
20.由于黑名单中可能出现多种语言,而某些语言的名字字符串可能过短,如中文,日文等往往名字仅有3到5个字。同时中文名,日文名字符特异性比较高,有些字符的出现频率不高。在黑名单中又可能出现同音字代替原字符,导致不利于后面的特征训练。这个方法可以有效解决多语言和过短字符串的问题。
21.s1.2:针对s1.1处理后的黑名单,再直接删除所有空格字符,并且把所有英文字符变为中文,得到预处理后的黑名单a2。
22.空格字符会影响分割过程中的结果,同时也会使分割后的字符串总长度增加,不利于训练,因此对a中所有的字符串直接删除所有空格字符。同时把所有的英语大写字符变为小写字符。并把得到的字符串代替原字符串,得到黑名单a2。
23.作为本发明的一种优选技术方案,上述步骤s2中包含以下:
24.s2.1:将黑名单a2中每个字符串z1视为一组,分别以1,2,3,4个字符为间隔进行文
字分割,得到四个对应的四种长度的短字符串组z1,z2,z3,z4。
25.遍历黑名单中的字符串,针对每次取出的长字符串z,采取不同长度的分割,得到多种长度的短字符串组,丰富了字符串的语义信息。同时这个分割方法适用于任何的场景,具有泛化性。
26.s2.2:将s1.2的四个短字符串组z1,z2,z3,z4合并,得到与原字符串z1对应的分割完的字符串群组z2。
27.所有被分割完的字符串都属于原字符串,这样原字符串中既保留了文字前后顺序信息,又保留所有单个字符串块的信息,又可以有效针对可能出现的替换,颠倒,增减字符。
28.作为本发明的一种优选技术方案,上述步骤s3中包含以下:
29.s3.1:使用深度学习的方法将s2.2得到的分割完的字符串组进行特征训练,得到每个短字符串的特征编码字典d。
30.具体的,先将s2.2获得的所有短字符串组整合成一个没有重复字符串的字典,给所有的短字符串赋予一个随机的长度为128维的向量。再把这些短字符串整合成一个特征编码字典d,然后遍历z2,取出每个短字符串组q,把q里的短字符串标记为1,其余在d中的短字符串标记为0。然后计算q中短字符串与d中的短字符串的余弦相似度。具体公式如下:
[0031][0032]
其中,x,y是s4.2中得到特征向量,然后使用交叉熵损失函数更新特征。具体公式如下:
[0033][0034]
其中,yi是样本i的标记,为1或0。pi为预测出来的余弦相似度;
[0035]
s3.2:将z2所有的短字符串找到d中对应的编码,并把编码全部相加,得到z1的编码c1,再将c1进行l2归一化,得到z1的最终编码c2,把a2的全部字符串对应的编码保存成编码集合b。同时保存特征编码字典d;
[0036]
具体的,z2所有的短字符串在d中都会找到一个对应的编码,然后把这些编码直接线性相加,得到一个128维的向量,再使用l2归一化,使得向量的模长都为1。这样就得到了z1的最终编码c2。把所有的z1和对应编码集合起来就变成了黑名单特征库b。
[0037]
作为本发明的一种优选技术方案,上述步骤s4中包含以下:
[0038]
s4.1:实时接收输入的字符串x,并同s1.1,s1.2的步骤,若输入字符串少于8个字符,则在原字符串后加上英文注音,再去除空格。
[0039]
s4.2:同s2.1,s2.2步骤,再把x分别以1,2,3,4个字符为间隔进行文字分割,得到四个对应的四种长度的短字符串组x1,x2,x3,x4并合并,得到对应的分割完的字符串群组x1。
[0040]
作为本发明的一种优选技术方案,上述步骤s5中包含以下:
[0041]
s5.1:s4.2得到的字符串组x1中的每个短字符串x,在特征编码字典d中寻找对应的特征c,若不在特征编码库d中则记为0。
[0042]
具体的,针对字符串组x1的每个短字符串x,若在特征编码字典d中没有对应x的编
码,则x对应的编码则为0。这样相当于仅仅对黑名单中存在的短字符串产生反应,而对未知的部分则没有产生相似度影响,提高了算法抗干扰能力。
[0043]
s5.2:将每个短字符串x的特征c直接相加,得到x的特征编码c3,再将c3进行l2归一化,得到x的最终编码c4。
[0044]
作为本发明的一种优选技术方案,在上述步骤s6中,由于之前的编码方式是把字符串特征均匀地分布在高维空间上,所以可直接使用余弦距离表示两个字符串的相似度。同时由于可能存在复数的相似黑名单,或者当干扰项过多导致结果偏差过大,所以结果将返回最相似的10个字符串作为最后的模糊匹配结果。
[0045]
与现有技术相比,本发明的有益效果如下:
[0046]
本发明可以对任意字符串使用一致的字符串分割方法,而不局限于词语的语义和长度或者语种,使得本发明能在更加广泛的场景被使用。
[0047]
同时,本发明使用的深度学习训练被分解的字符串特征,再聚合所有被分解的字符串特征,从而使得提炼出的原字符串特征具有多重语义,从而找出与黑名单相似又不一定完全相同的字符串。同时对较短的字符串有良好的语义表达能力。
[0048]
最后,本发明在匹配环节使用余弦距离判断字符串之间的相似度,能够进行大批量地计算,批量返回可能的相似结果,具有一定实时性。通过这一步骤,可以协助检测人员快速寻找可疑的字符串。
附图说明
[0049]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0050]
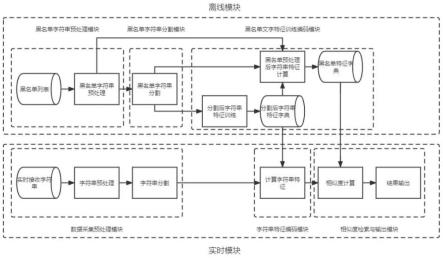
图1是本发明的系统总体示意图;
[0051]
图2是本发明的黑名单字符串预处理模块示意图;
[0052]
图3是本发明的黑名单字符串分割模块示意图;
[0053]
图4是本发明的字符串分割示例图;
[0054]
图5是本发明的是黑名单文字特征训练编码模块示意图;
[0055]
图6是本发明的数据采集预处理模块示意图;
[0056]
图7是本发明的输入字符串特征编码模块示意图;
[0057]
图8是本发明的相似度检索与输出模块示意图。
具体实施方式
[0058]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
[0059]
实施例1
[0060]
如图1-8,本发明提供一种基于字符串文本特征相似度的黑名单模糊匹配方法,包括以下步骤:
[0061]
s1:黑名单字符串预处理模块,在离线情况下对已有的黑名单中过短的非英文字符串进行注音;再去除所有空格字符,并将所有英文字符全部变为小写字符;
[0062]
s2:黑名单字符串分割模块,在离线情况下将预处理后的黑名单中每个字符串按不同长度进行文字分割,得到对应的短字符串组;最后将短字符串组合并,得到与原字符串对应的分割完的字符串组;
[0063]
s3:黑名单文字特征训练编码模块,在离线情况下对分割完的字符串组进行特征训练,得到特征编码库;并根据特征编码库对预处理后黑名单中的字符串进行编码;
[0064]
s4:数据采集预处理模块,接收在线输入的字符串,并类似s1规则若是过短的非英文字符串则注音;再将字符串进行与s2相同的字符串分割方法得到对应字符串组;
[0065]
s5:输入字符串特征编码模块,将s3得到的字符串组根据离线情况下获得的特征编码库d中寻找每个字符串对应的特征并累加;最后再把累加得到的特征进行归一化;
[0066]
s6:相似度检索与输出模块,将s4得到的输入字符串的特征,与黑名单的每个字符串编码计算余弦相似度;再按得到的值的大小排序,选出最小的十个字符串,得到最后的模糊匹配结果。
[0067]
上述步骤s1中包含:
[0068]
s1.1:将已有的黑名单a中的少于8个字符的字符串(不包括空格字符)通过音译,统一在原名单后加上英文注音。
[0069]
由于黑名单中可能出现多种语言,而某些语言的名字字符串可能过短,如中文,日文等往往名字仅有3到5个字。同时中文名,日文名字符特异性比较高,有些字符的出现频率不高。在黑名单中又可能出现同音字代替原字符,导致不利于后面的特征训练。这个方法可以有效解决多语言和过短字符串的问题。
[0070]
s1.2:针对s1.1处理后的黑名单,再直接删除所有空格字符,并且把所有英文字符变为中文,得到预处理后的黑名单a2。
[0071]
空格字符会影响分割过程中的结果,同时也会使分割后的字符串总长度增加,不利于训练,因此对a中所有的字符串直接删除所有空格字符。同时把所有的英语大写字符变为小写字符。并把得到的字符串代替原字符串,得到黑名单a2。
[0072]
上述步骤s2中包含以下:
[0073]
s2.1:将黑名单a2中每个字符串z1视为一组,分别以1,2,3,4个字符为间隔进行文字分割,得到四个对应的四种长度的短字符串组z1,z2,z3,z4。
[0074]
遍历黑名单中的字符串,针对每次取出的长字符串z,采取不同长度的分割,得到多种长度的短字符串组,丰富了字符串的语义信息。同时这个分割方法适用于任何的场景,具有泛化性。
[0075]
s2.2:将s1.2的四个短字符串组z1,z2,z3,z4合并,得到与原字符串z1对应的分割完的字符串群组z2。
[0076]
所有被分割完的字符串都属于原字符串,这样原字符串中既保留了文字前后顺序信息,又保留所有单个字符串块的信息,又可以有效针对可能出现的替换,颠倒,增减字符。
[0077]
上述步骤s3中包含以下:
[0078]
s3.1:使用深度学习的方法将s2.2得到的分割完的字符串组进行特征训练,得到每个短字符串的特征编码字典d。
[0079]
具体的,先将s2.2获得的所有短字符串组整合成一个没有重复字符串的字典,给所有的短字符串赋予一个随机的长度为128维的向量。再把这些短字符串整合成一个特征
编码字典d,然后遍历z2,取出每个短字符串组q,把q里的短字符串标记为1,其余在d中的短字符串标记为0。然后计算q中短字符串与d中的短字符串的余弦相似度。具体公式如下:
[0080][0081]
其中,x,y是s4.2中得到特征向量,然后使用交叉熵损失函数更新特征。具体公式如下:
[0082][0083]
其中,yi是样本i的标记,为1或0。pi为预测出来的余弦相似度;
[0084]
s3.2:将z2所有的短字符串找到d中对应的编码,并把编码全部相加,得到z1的编码c1,再将c1进行l2归一化,得到z1的最终编码c2,把a2的全部字符串对应的编码保存成编码集合b。同时保存特征编码字典d;
[0085]
具体的,z2所有的短字符串在d中都会找到一个对应的编码,然后把这些编码直接线性相加,得到一个128维的向量,再使用l2归一化,使得向量的模长都为1。这样就得到了z1的最终编码c2。把所有的z1和对应编码集合起来就变成了黑名单特征库b。
[0086]
上述步骤s4中包含以下:
[0087]
s4.1:实时接收输入的字符串x,并同s1.1,s1.2的步骤,若输入字符串少于8个字符,则在原字符串后加上英文注音,再去除空格。
[0088]
s4.2:同s2.1,s2.2步骤,再把x分别以1,2,3,4个字符为间隔进行文字分割,得到四个对应的四种长度的短字符串组x1,x2,x3,x4并合并,得到对应的分割完的字符串群组x1。
[0089]
上述步骤s5中包含以下:
[0090]
s5.1:s4.2得到的字符串组x1中的每个短字符串x,在特征编码字典d中寻找对应的特征c,若不在特征编码库d中则记为0。
[0091]
具体的,针对字符串组x1的每个短字符串x,若在特征编码字典d中没有对应x的编码,则x对应的编码则为0。这样相当于仅仅对黑名单中存在的短字符串产生反应,而对未知的部分则没有产生相似度影响,提高了算法抗干扰能力。
[0092]
s5.2:将每个短字符串x的特征c直接相加,得到x的特征编码c3,再将c3进行l2归一化,得到x的最终编码c4。
[0093]
在上述步骤s6中,由于之前的编码方式是把字符串特征均匀地分布在高维空间上,所以可直接使用余弦距离表示两个字符串的相似度。同时由于可能存在复数的相似黑名单,或者当干扰项过多导致结果偏差过大,所以结果将返回最相似的10个字符串作为最后的模糊匹配结果。
[0094]
示例如下:
[0095]
针对用户注册用户名的场景,具体操作如下:
[0096]
首先在离线状态下,将黑名单按图2所示,把长度小于8的非英文字符加上英文注音,再去除所有空格字符,把英文全部固定成小写。例如“张三”变成“张三zhangsan”。而对于其他标点符号则不必要改动,因为最后的特征对输入的其他标点符号不敏感。这样可以
得到预处理后的黑名单。
[0097]
如图3所示将预处理后的黑名单中每个字符串单独拿出,按照4个长度分割字符串,再将分割完的短字符串组合并,合并后的字符串组作为原长字符串的对应分割后的字符串。具体的分词方法实例如图4所示。
[0098]
如图5所示,对短字符串进行特征训练,再通过短字符串的特征叠加来表示原长字符串。首先把所有字符串中的短字符串全部取出,组成一个字典,对每个短字符串赋予随机的128维的特征向量。然后开始遍历原长字符串,将其所对应的短字符串表示为1,其余字符串表示为0。然后开始将对应的短字符串一一和字典中的所有短字符串计算余弦相似度。使用交叉熵作为损失函数,反向传播更新权重。使短字符串中的词语之间余弦相似度更接近1,而其余的更接近0。当字符串全部遍历完之后,就可以得到短字符串字典特征库。然后再重新遍历原长黑名单字符串,把其对应的短字符串特征全部相加,最后对得到长字符串的特征使用l2归一化。整合可以得到一个短字符串字典特征库和黑名单特征库。就此离线部分的操作完成
[0099]
如图6所示,在实时检测用户输入的用户名时,首先按离线模式的字符串处理方式获得对应的短字符串组。然后如图7所示,在之前获取的短字符串字典特征库中找到对应的特征,若找不到则跳过或者置零。然后把短字符串的特征相加,得到特征再l2归一化。获得对应的字符串的特征。
[0100]
最后如图8所示,在黑名单特征库中找出余弦相似度最大的10个字符串,返回字符串和对应余弦相似度作为最终模糊匹配的结果。
[0101]
进一步的,本发明中具备以下特点:
[0102]
1.本发明主要是提出了一种基于文本特征相似度的黑名单模糊匹配方法,通过字符串分割与特征训练相结合,能实时给出批量的与黑名单内字符串相似的字符串候选,这是传统其他类似发明所不具备的;
[0103]
2.本发明在提取字符串特征前,先通使用一致的字符串分割方法,得到只含有较短字符串,再进行特征训练,使得字符串特征信息更加丰富,是其他类似发明所不具备的;
[0104]
本发明对于提取字符串的特征使用了深度学习的方法,并且同时使用余弦距离判断字符串相似度,能够实时找出所有可能的在黑名单中相似的字符串,对变体的字符串也有很强的侦查能力,是其他类似发明所不具备的。
[0105]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1