一种基于Transformer编码器和空洞卷积的车道线检测方法
一种基于transformer编码器和空洞卷积的车道线检测方法
技术领域
1.本发明涉及视觉车道线检测领域,尤其涉及一种基于transformer编码器和空洞卷积的车道线检测方法。
背景技术:
2.车道检测是一项具有挑战性的工作,因为它受到很多因素的影响,如光照条件、其他车辆遮挡、道路上不相关标记的存在以及车道本身固有的狭长特性。此外,考虑到车道检测是在基于车辆的系统上运行的,计算资源非常有限,车道检测方法的计算成本也应该被视为整体性能的关键指标。同时,作为高级驾驶辅助系统(adas)的基础功能,车道检测必须具备高精确度、高实时性与鲁棒性等的条件。因此,车道检测不仅是一项重要而复杂的任务,而且是开发任何自动驾驶车辆系统的关键因素。
3.车道线检测网络框架通常采用编码器-解码器的形式,目前关于车道线识别的研究主要集中在解码器上,然而提取清晰可靠的车道线特征具有同样的重要性,提取出清晰的车道线特征必然会对后续的检测部分减少很多负担。大多数算法中的编码器部分利用堆叠的卷积神经网络对图片的局部区域进行特征提取的同时对图片进行下采样,但卷积块在提取图像特征时只对局部像素进行运算而忽略了图片上的全局信息。现有方法通过对特征图进行切片,然后利用相邻行和列之间按顺序的卷积叠加在特征图上传递信息,但由于序列信息的传递操作耗时较长,导致推理速度较慢。同时,在相邻行或列之间顺序传递信息需要多次迭代,在长距离传播过程中会丢失部分信息。
4.堆叠的卷积神经网络进行了多次下采样,降低了进行后处理的特征图的分辨率,导致微小的车道线目标信息被忽略。为了解决多尺度目标检测问题,特征金字塔通过不同的方式融合了不同尺度的特征图。目前特征金字塔主要分为单向和双向,fpn通过将上层特征图的大小加倍并将其添加到下层,自顶而下融合特征图。lizhe liu等[1]采用fpn在车道检测网络中融合多尺度特征,但缺乏可解释性,计算效率低。panet[2]在fpn的基础上添加了一个自底向上的特征融合,利用双向融合骨干网络保证特征的多样性和完整性,但其无法权衡各特征的重要性。nas-fpn[3]采用神经架构搜索来寻找更好的跨尺度特征网络拓扑,但是在搜索过程中需要花费大量时间,并且发现的网络不规则,难以解释或修改。bifpn[4]对不同尺度的特征图进行双向加权特征融合,并利用网络学习权重的大小来优化特征融合。
[0005]
另外,交通图像数据多样性与数量对于深度学习来说的非常重要,但在某些特定的驾驶场景如遮挡、阴影、夜间等数据只占整个驾驶数据集中的一小部分,形成长尾数据,降低了深度学习神经网络对此部分数据的学习效果。通过采集特定场景下的交通图像作为新数据集来解决在此场景下的车道线检测问题,但这种方法耗时耗力,降低了算法迭代效率。在应对长尾数据上,seokju lee等[5]建立了一个新的数据集,包含17个车道和道路标记类,适用于四种不同的长尾场景:无雨、下雨、大雨和夜间,但收集长尾数据是耗时耗力的工作,不满足高速发展的技术需要。风格迁移将一张图片的风格转换成另一张图片的,同时
保留原图片的内容不变,gayts[6]通过重复运用vgg网络来提取图像的纹理信息和内容信息,使生成的图片保留内容值得同时具有新的纹理效果。pix2pix[7]通过生成对抗网络来实现图像风格转换,它需要成对的数据进行训练。但实际道路交通图片中极少存在成对的数据,如环境、交通流等完全相同的黑夜和白天道路场景图,因此上述两种方法不适用。而cyclegan[8]通过引入循环一致性损失来保证内容不变,使其不需要一一对应的图片作为输入。unit[9]在cyclegan的基础上进行了改进,它认为两个域图像可以由他们的联合分布转化得出,并利用vae-gan结构保留内容细节,但是实际道路交通图片中很难获取到成对的不同风格图片。
[0006]
参考文献:
[0007]
[1]lizhe liu,xiaohao chen,siyu zhu.condlanenet:a top-to-down lane detection framework based on conditional convolution[j].arxiv preprint arxiv:2105.05003,2021.
[0008]
[2]liu s,qi l,qin h et a1.path aggregation network for instance segmentation[c].ieee conference on computer vision and pattern recognition(cvpr),2018.
[0009]
[3]ghiasi g,lin ty,le qv.nas-fpn:learning scalable feature pyramid architecture for object detection[c]//2019ieee/cvf conference on computer vision and pattern recognition(cvpr).ieee,2019.
[0010]
[4]tan m,pang r,le qv.efficientdet:scalable and efficient object detection[c]//2020 ieee/cvf conference on computer vision and pattern recognition(cvpr).ieee,2020.
[0011]
[5]seokju lee,junsik kim,jae shin yoon,et al.vpgnet:vanishing point guided network for lane and road marking detection and recognition[c]//2017 ieee international conference on computer vision(iccv).ieee,2017.
[0012]
[6]gatys la,ecker as,bethge m.image style transfer using convolutional neural networks[c]//2016 ieee conference on computer vision and pattern recognition(cvpr).ieee,2016.
[0013]
[7]phillip isola,jun-yan zhu,tinghui zhou et al.image-to-image translation with conditional adversarial networks[j]//2017 ieee conference on computer vision and pattern recognition(cvpr).ieee,2017.
[0014]
[8]jun-yan zhu,taesung park,phillip isola et al.unpaired image-to-image translation using cycle-consistent adversarial networks[c]//ieee conference on computer vision and pattern recognition(cvpr),2017:2223-2232.
[0015]
[9]ming-yu liu,thomas breuel,jan kautz.unsupervised image-to-image translation networks[c]//31st conference on neural information processing systems(nips 2017),long beach,ca,usa.
技术实现要素:
[0016]
针对现有技术所存在的问题,本发明提供一种基于transformer编码器和空洞卷
积的车道线检测方法,该算法将克服堆叠的卷积神经网络无法获得图像的全局信息、难以识别微小车道线目标识别的局限,并且通过风格迁移生成夜间数据,克服了长尾数据数据量不足的问题,提高了模型的检测效率和精度,并使模型适用于多种复杂道路交通场景。
[0017]
为了达到上述目的,本发明通过使用空洞卷积来提取不同尺度的局部特征,并利用transformer编码器对车道线的细长线形结构进行全局关联,最后通过双向加权特征金字塔对局部和全局信息进行加权融合,以适用于复杂交通环境中的车道线检测。此外,本发明还利用无监督风格迁移生成对抗网络进行夜间行驶图像的生成,提高了车道线检测网络在夜间、阴暗交通环境下的检测能力。
[0018]
具体的,本发明提供的一种基于transformer编码器和空洞卷积的车道线检测方法,包括以下步骤:
[0019]
使用unit无监督风格迁移方法,利用白天交通图像生成夜间交通场景数据;
[0020]
构建主干特征提取网络,且在主干特征提取网络中用空洞卷积代替原来的卷积,以提取车道线多尺度局部特征;
[0021]
构建transformer编码器,利用位置编码和自注意力机制获取全局特征;
[0022]
使用双向特征金字塔对所提取出来的局部和全局特征进行自顶而下和自底而上的加权融合;
[0023]
采用基于实例分割的方法构建车道线检测头;
[0024]
利用数据集对模型进行训练,使模型收敛获得车道线检测网络参数;
[0025]
将模型安装在车载摄像头上,用于对车道线进行实时检测,得到车道线实例分割图。
[0026]
进一步地,在进行unit无监督风格迁移前,还包括步骤:获取网络公开道路交通数据集,所述数据集中包含车道线及其标签。
[0027]
进一步地,为了应对不同的交通场景,所述的数据集应为culane数据集,里面包括正常场景、拥堵场景、转弯场景、眩光场景、夜晚场景、无车道线场景、阴影场景和道路有箭头标记场景。
[0028]
进一步地,所述使用unit无监督风格迁移方法,利用白天交通图像生成夜间交通场景,包括:
[0029]
设b=(x,y),其中x为原图像,y为原图像的标签,b为原始数据及其标签的组合;
[0030]
假设bg=(xg,yg),其中xg为生成的图像,yg为生成图像的标签,则:
[0031]
xg=g(e(x))
[0032]
yg=y
[0033]
其中,g为生成器;e为编码器,bg为生成的数据及其标签的组合。
[0034]
由于风格迁移只通过白天的图像生成了夜间图像,并没有改变图像中车道线和环境等细节的分布,因此生成图像的标签可以直接使用原图像的标签。
[0035]
进一步地,通过将主干特征提取网络的卷积步长减小为1来保持特征图的分辨率不变。
[0036]
进一步地,所述主干特征提取网络中用空洞卷积代替原来的卷积,包括:
[0037]
将主干特征提取网络的后两个模块的卷积修改为空洞卷积,假设输入w为输入图片的宽、h为输入图片的高,在经过空洞卷积进行特征提取之后,输
出特征图卷积输入输出的尺寸关系为:
[0038][0039]
其中,w
in
为输入的尺寸;w
out
为输出的尺寸;p为填充数;k为卷积核大小;d为卷积空洞数;s为卷积步长。
[0040]
进一步地,在transformer编码器中,特征图首先经过一个卷积核大小为3,步长为1的卷积层来得到特征图嵌入f
′
,并对其加入固定位置编码pe,在自注意力模块中,通过点积计算注意力值,最后通过残差连接在不增加太多计算成本的基础下添加更多的特征,并利用单层的卷积网络作进一步的特征整合;
[0041]
其中,位置编码使用不同频率的sin和cos计算得到:
[0042]
pe(pos,2i)=sin(pos/10000
2i/d
)
[0043]
pe(pos,2i+1)=cos(pos/10000
2i/d
)
[0044]f″
=f
′
+pe
[0045]
其中,pos为像素的位置;i为当前维度;d为总维度大小;f
″
为加入位置编码后的特征图嵌入,pe(pos,2i)为第2i个维度上位置为pos的像素的位置编码。
[0046]
进一步地,在双向特征金字塔中,通过快速标准化权重融合来约束了权重的范围,所述快速标准化权重融合公式为
[0047][0048]
进行双向加权融合后的输出为:
[0049]
o=conv(ω
io
·fi
)
[0050]
其中,ωi为第i个输入的初始权重,∈为一预设的极小的数,防止分母为0,ωj为第j个输入的权重,ω
io
为快速标准化权重融合后第i个输入的权重,fi为第i个输入,conv为3x3卷积,o为融合后的输出。
[0051]
进一步地,总的损失函数包括实例分割损失和车道线存在情况损失。
[0052]
进一步地,在车道线检测中,实例分割损失通过cross entropy损失函数计算,车道线存在情况损失通过binary cross entropy损失函数计算;
[0053]
进一步地,在对模型进行训练时,使用sgd优化器对网络进行优化,学习率设置为0.03,动量设置为0.9,权重衰减率为5e-4。每次训练的批量为16,训练轮次为12。
[0054]
进一步地,设置有至少一个双向特征金字塔。
[0055]
本发明的基于transformer和空洞卷积的车道线检测算法与现有技术相比,至少具备以下有益效果:
[0056]
该方法采用空洞卷积提取车道线局部特征,基于transformer编码器来获取全局特征,并通过双向加权特征金字塔加强了特征的融合,提高了在不同场景下多尺度细长车道线特征提取和融合的能力。此外,使用了无监督风格迁移生成对抗网络来扩充数据集,将白天样式的图像转换为夜间,这增强了模型在长尾场景中检测车道的能力。
附图说明
[0057]
图1为本发明实施例中的基于transformer和空洞卷积的车道线检测方法的模型整体结构示意图;
[0058]
图2为本发明实施例中的无监督风格迁移生成对抗网络结构示意图;
[0059]
图3为本发明实施例中的空洞卷积与普通卷积的对比图;
[0060]
图4为本发明实施例中的transformer编码器结构示意图;
[0061]
图5为本发明实施例中的特征融合器结构示意图;
[0062]
图6为本发明实施例提供的一种基于transformer编码器和空洞卷积的车道线检测方法的流程示意图。
具体实施方式
[0063]
以下将结合本发明实施例中的附图,对本发明实施例中的技术方案进行说明,所描述的优选实施例仅仅是本发明的一部分实施例,而不是全部实施例,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
[0064]
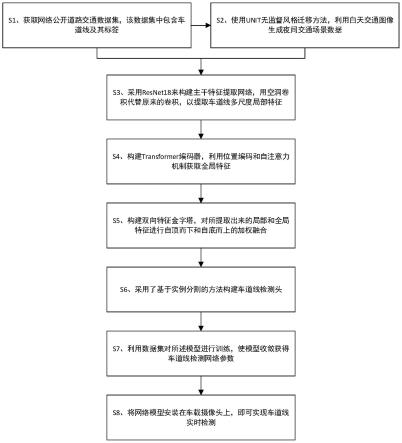
请参阅图1,本发明提供的一种基于transformer编码器和空洞卷积的车道线检测方法,具体步骤包括:
[0065]
s1、下载网络公开道路交通数据集culane,它是专用于车道线检测的大型数据集,包含了正常场景和拥挤、眩光、阴影、地面箭头、弯道、十字路口、夜晚道路等高挑战性的场景,其中训练集包含88880张道路交通图片,测试集包含34680张道路交通图片。
[0066]
s2、使用unit无监督风格迁移方法,利用白天交通图像生成夜间交通场景来进行数据增广;
[0067]
如图2所示,unit首先通过编码器e1和e2将两个不同的域(定义为x1域和x2域)的图片共同编码到潜在隐藏空间z域中,再通过生成器g1和g2将z域的数据分别转换到x1和x2域,图中为由x1域编码解码得到的x1域图片、为由x2域编码解码得到的x1域图片、为由x1域编码解码得到的x2域图片、为由x2域编码解码得到的x2域图片,然后计算和x1,和x2的循环一致性损失,保留图片的细节信息,最后用判别器d1和d2判别生成图片和真实图片的真伪,以对抗训练的方式提高图片风格迁移后的真实性。
[0068]
在本发明的其中一些实施例中,设b=(x,y),其中x为原图像,y为原图像的标签,b为原始数据及其标签的组合。
[0069]
风格迁移只通过白天的图像生成了夜间图像,并没有改变图像中车道线和环境等细节的分布,因此生成图像的标签可以直接使用原图像的标签;
[0070]
假设bg=(xg,yg),其中xg为生成的图像,yg为生成图像的标签,则:
[0071]
xg=g(e(x))
[0072]
yg=y
[0073]
其中,bg为生成的数据及其标签的组合,g为生成器;e为编码器。
[0074]
s3、构建主干特征提取网络,用空洞卷积代替原来的卷积,以提取车道线多尺度局部特征;
[0075]
在本发明的其中一些实施例中,采用resnet18来构建主干特征提取网络。当然,在
其他实施例中,也可以采用vgg16等常用网络来构建主干特征提取网络。
[0076]
在本发明的其中一些实施例中,在步骤1中,将主干特征提取网络后两个模块的卷积修改为空洞卷积,如图3所示,空洞卷积与普通卷积相比,能够让每个卷积块的输出都包含较大范围的信息,在增大了卷积感受野的同时防止特征图过小而丢失小目标的信息。其中,假设输入即x为三维输入,其尺寸为(3,w,h)。其中,w为输入图片的宽、h为输入图片的高,在经过空洞卷积进行特征提取之后,输出特征图即f的尺寸为(512,w/8,h/8),卷积输入输出的尺寸关系为:
[0077][0078]
其中,w
in
为输入的尺寸;w
out
为输出的尺寸;p为填充数;k为卷积核大小;d为卷积空洞数;s为卷积步长。
[0079]
在本发明的其中一些实施例中,在步骤1中,将主干特征提取网络的卷积步长减小为1,来保持特征图的分辨率不变。
[0080]
s4、构建transformer编码器,利用位置编码和自注意力机制获取全局特征;
[0081]
在本发明的其中一些实施例中,如图3所示,特征图f首先经过一个卷积核大小为3,步长为1的输入嵌入卷积层来得到特征图嵌入f
′
;
[0082]
随后加入位置编码pe,由于特征图嵌入f
′
与位置编码pe具有相同的维度,因此位置信息的加入可以通过特征图嵌入与位置编码相加来完成,位置编码使用不同频率的sin和cos计算得到:
[0083]
pe(pos,2i)=sin(pos/10000
2i/d
)
[0084]
pe(pos,2i+1)=cos(pos/10000
2i/d
)
[0085]f″
=f
′
+pe
[0086]
其中,pos为像素的位置;i为当前维度;d为总维度大小,当d为奇数时,i=0,1,...,当d为偶数时,i=0,1,...,f
″
为加入位置编码后的特征图嵌入,pe(pos,2i)为第2i个维度上位置为pos的像素的位置编码。
[0087]
在位置编码pe后加入自注意力模块,在自注意力模块中,加入位置编码后的特征图嵌入f
″
经过线性变换和尺寸调整后得到查询向量q、关键字和特征值v,其中dk=128为q和k的维度;通过点积计算注意力值attention,即像素与像素之间关联的强弱:
[0088][0089]
然后将注意力值attention与特征值v相乘得到自注意力模块的输出fo:
[0090]fo
=v
·
attention
[0091]
并且输入嵌入卷积层和自注意力模块的输出之间通过残差连接,通过残差连接在不增加太多计算成本的基础下添加更多的特征,并进一步地利用单层的卷积网络作进一步的特征整合。
[0092]
s5、使用双向特征金字塔对所提取出来的局部和全局特征进行自顶而下和自底而
上的加权融合。
[0093]
双向特征金字塔设置有至少一个。当设置两个及以上的双向特征金字塔时,上一个特征金字塔的输出是下一个特征金字塔的输入。在本发明的其中一些实施例中,考虑到实时性,只设置一个双向特征金字塔。
[0094]
图1中实线部分是实际的应用,虚线部分是可应用但考虑了实时性而未应用的,因此双向特征金字塔的输入为顶层的transformer编码器输出的全局特征和第二、三层空洞卷积直接输出的多尺度局部特征。
[0095]
由于对主干特征提取网络行了修改,使后三层输出特征图的尺寸大小相同,因此双向特征金字塔无需对特征图进行线性插值扩张或池化缩小,避免了信息的丢失。
[0096]
在本发明的其中一些实施例中,通过快速标准化权重融合来约束权重的范围,使融合后的权重值ω
io
落在0~1之间,并通过学习的方式让网络对权重的大小进行自动调整。此权重融合方法可以防止权重值过大导致的训练不稳定,同时在gpu上运行速度更快。
[0097]
其中,快速标准化权重融合公式为
[0098][0099]
如图4所示,进行双向加权融合后的输出为:
[0100][0101]
其中,ωi为第i个输入的初始权重,∈为一预设的极小的数,防止分母为0,ωj为第j个输入的权重,ω
io
为快速标准化权重融合后第i个输入的权重,fi为第i个输入,conv为3x3卷积,o为融合后的输出。
[0102]
如图5所示,三个特征图f1、f2、f3输入双向特征金字塔,并以箭头方向进行融合,如f5的融合过程为:
[0103][0104]
ω1、ω4分别为第1个输入和第4个输入的权重;
[0105]
在本发明的其中一些实施例中,∈=0.0001,防止数值出现不稳定的情况。
[0106]
s6、采用基于实例分割的方法构建车道线检测头,通过卷积输出车道线实例分割图;
[0107]
总的损失函数包括实例分割损失和车道线存在情况损失,在本发明的其中一些实施例中,实例分割损失通过cross entropy损失函数计算,车道线存在情况损失通过binary cross entropy损失函数计算,当然,在其他实施例中,也可以采用其他损失函数。
[0108]
损失函数公式为:
[0109][0110]
[0111]
l=αl
seg
+βl
exit
[0112]
其中,l
seg
为实例分割损失;yi为实例分割真值;pi为预测为第i条车道线实例的概率;l
exit
为车道线存在情况损失;qi为车道线存在情况真值;ei为车道线存在情况预测值;α、β分别为实例分割损失和为车道线存在情况损失的权重系数,l为总的损失函数。
[0113]
s7、利用道路交通原始数据集和风格迁移生成的数据集对所述模型(主干特征提取网络、transformer编码器、双向特征金字塔、基于实例分割的检测头组成的车道线检测网络模型)进行训练,使模型收敛获得车道线检测网络参数。
[0114]
在本发明的其中一些实施例中,在步骤7中,使用sgd优化器对网络进行优化
[0115]
学习率设置为0.03;
[0116]
动量设置为0.9;
[0117]
权重衰减率为0.0005;
[0118]
每次训练的批量为16;
[0119]
训练轮次为12。
[0120]
在一台配备一张nvidia geforce rtx2080ti显卡的服务器上训练。
[0121]
s8、将网络模型安装在车载摄像头上,即可实现车道线的实时检测。此步骤只需要车载摄像头获取道路图像,然后输入到训练好的网络模型文件中,将输出车道线实例分割图。
[0122]
本发明前述实施例提供的车道线检测方法,具体是利用transformer编码器可以高效提取图片全局特征和空洞卷积可以扩大卷积感受野并提取多尺度局部特征的特点,基于深度学习算法,以道路交通图像作为模型的输入,通过局部和全局特征提取后,利用双向加权特征金字塔对提取到的特征进行融合,最后采用实例分割检测头输出车道线实例分割图片,实现车道线检测。为了提高模型在夜间和阴暗场景下的车道线检测能力,采用无监督风格迁移将白天场景的图像转换为夜间加入数据集中。所提算法提高了不同场景下车道线特征提取的精度与计算效率,同时可以方便地整合到其他现有车道线检测算法中进行端到端训练。
[0123]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1