基于序列感知与特征增强的无人机视角目标跟踪方法
1.本发明属于图像处理技术领域,更进一步涉及到目标跟踪技术领域中的一种基于序列感知与特征增强的无人机视角目标跟踪方法。本发明可利用无人机对城市安防、自动驾驶和智慧交通中行动的行人和车辆等进行跟踪。
背景技术:
2.无人机视角目标跟踪的任务就是在给定无人机视角视频序列初始帧中某一目标大小和位置的情况下,预测该目标在后续帧中的大小和位置。导致无人机视角目标跟踪任务失败的原因有两点,第一,由于无人机在拍摄时的飞行高度较高,被拍摄的目标在图像中的尺寸较小,特征模糊且容易被环境遮挡;第二,无人机在拍摄目标时为了保证目标持续被相机捕捉到,需要经常调整相机角度,导致目标在视频中出现剧烈运动的情况。
3.贵州大学在其申请的专利文献“一种新的无人机目标跟踪算法”(专利申请号:cn114972439a,申请公布号:cn 110517291 a)中公开了将一种基于自我注意机制的特征相关网络用于无人机视角目标跟踪的方法。该方法首先将模板图像、搜索区域图像和动态模板更新图像输入特征提取网络,再将输出特征输入基于注意机制的网络获取全局特征信息,最后将模板特征和搜索区域特征输入特征相关网络解码得到跟踪结果。该方法存在的不足之处是,由于该方法没有考虑到视频序列的上下文信息,无法解决上述小目标问题和相机运动问题,当目标尺寸较小特征不足时,以及无人机相机运动导致目标在图像中的位置发生剧烈变化时,跟踪器很容易丢失目标,导致跟踪失败。
4.goutam和martin等人在其发表的论文“know your surroundings:exploiting scene information for object tracking”(会议名称:european conference on computer vision’2020)中公开了一种可用于无人机视角目标跟踪的基于序列信息的方法,该方法首先将当前帧,之前帧和之前状态向量输入网络模型,再将当前帧输入图像特征提取网络,得到外观特征,同时将当前帧、之前帧和之前状态向量一起输入聚合网络模型,对之前状态向量进行更新,最后将更新后的状态向量和外观特征一起输入解码器得到跟踪结果。由于该方法使用的之前状态向量包含了序列信息,所以该方法在一定程度上解决了贵州大学在其申请的专利文献“一种新的无人机目标跟踪算法”方法没有利用视频序列上下文信息的不足,但是,该方法仍然存在的不足之处是,该方法在处理无人机视角目标跟踪过程中的小目标问题与相机运动问题时无法得到准确的跟踪结果,表明该方法的跟踪网络结构的设计限制了其对序列特征的提取与表征。
技术实现要素:
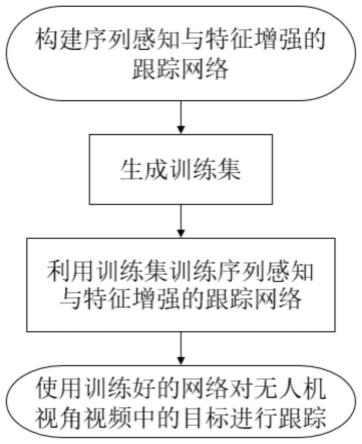
5.本发明的目的是针对上述现有技术存在的不足,提出一种基于序列感知与特征增强的无人机视角目标跟踪方法,用于解决无人机视角目标跟踪过程中网络对小目标的特征不足,以及相机运动引起目标在图像中位置发生剧烈变化导致的跟踪失败的问题。
6.实现本发明目的的思路是:构建序列感知与特征增强的跟踪网络,首先使用序列
特征感知子网络提取视频序列特征,根据序列特征中包含的隐式的相机运动信息学习相机的运动模式。再使用图像特征增强子网络增强图像特征,利用序列特征在时序维度对小目标的特征进行补充。从而解决无人机视角目标跟踪过程中的相机运动问题和小目标问题。
7.本发明的实现步骤如下:
8.步骤1,构建序列感知与特征增强的跟踪网络:
9.步骤1.1,构建序列特征计算子网络;
10.搭建一个包括第一卷积层、第二卷积层、第三卷积层和第四卷积层组成的序列特征计算子网络,其中,第一卷积层与第二卷积层串联组成第一串联模块,第三卷积层与第四卷积层串联组成第二串联模块,再将第一串联模块与第二串联模块并联组成序列特征计算子网络,将第一至第四卷积层的卷积核个数均设置为64,卷积核尺寸均设置为1
×
1;
11.步骤1.2,构建图像特征增强子网络;
12.搭建一个包括第一卷积层、第二卷积层和第三卷积层组成的图像特征增强子网络,其中,第一卷积层、第二卷积层与第三卷积层依次串联组成图像特征增强子网络,将第一至第三卷积的卷积核个数依次设置为1、1、512,卷积核尺寸依次设置为3
×
3、3
×
3、、1
×
1;
13.步骤1.3,将图像特征提取子网络resnet50与序列特征计算子网络并联后与图像特征增强子网络、dimp跟踪模型解码器依次串联组成序列感知与特征增强的跟踪网络;
14.步骤2,生成训练集;
15.步骤2.1,从自然图像视频中随机采集至少100000个图像对,每对图像对由视频中相邻的两帧图像构成且两帧图像中均存在同一个不限种类的目标,两帧图像分别称为当前帧图像和前一帧图像;
16.步骤2.2,对每对图像对进行预处理,以每对图像对的当前帧图像中目标的位置中心为裁剪中心,将图像对中两幅图像的尺寸均裁剪为[288
×
288
×
3],再将裁剪后的图像对进行随机平移或缩放处理;
[0017]
步骤2.3,对于每对预处理后的图像对,以位置框的形式标注目标在当前帧图像中的位置,所述位置框用[c,w,h]表示,c、w和h为位置框的中心、宽度和高度,将[c,w,h]作为图像对的目标真实位置框,同时以c为中心生成高斯标签图作为图像对的目标分类标签图;
[0018]
步骤2.4,将所有预处理后的图像对及其对应的目标分类标签图和目标真实位置框组成训练集;
[0019]
步骤3,训练网络:
[0020]
将训练集中的图像对输入到序列感知与特征增强的跟踪网络中,使用sgd优化算法,离线迭代训练序列感知与特征增强的跟踪网络的参数,直到损失函数收敛为止,得到训练好的网络;
[0021]
步骤4,使用训练好的网络对无人机视角视频中的目标进行在线跟踪。
[0022]
本发明与现有技术相比,具有以下优点:
[0023]
第一,本发明通过构建的序列特征感知子网络,解决了现有方法对序列信息表征不足的缺点,使得本发明根据序列特征学习相机运动信息,具有在无人机相机运动后仍然不会丢失跟踪目标的优点。
[0024]
第二,本发明通过构建的图像特征增强子网络,解决了现有方法对小目标表征不
足的缺点,使得本发明利用序列特征对小目标的外观特征进行补充,具有在跟踪小目标时不会因为外观特征不足丢失跟踪目标的优点。
附图说明
[0025]
图1是本发明的流程图;
[0026]
图2是本发明的仿真结果图。
具体实施方式
[0027]
下面结合附图和实施例,对本发明做进一步的详细描述。
[0028]
参照图1和实施例,对本发明的具体实现步骤做进一步的详细描述。
[0029]
步骤1,构建序列感知与特征增强的跟踪网络。
[0030]
步骤1.1,构建序列特征计算子网络。
[0031]
搭建一个包括第一卷积层、第二卷积层、第三卷积层和第四卷积层组成的序列特征计算子网络,其中,第一卷积层与第二卷积层串联组成第一串联模块,第三卷积层与第四卷积层串联组成第二串联模块,再将第一串联模块与第二串联模块并联组成序列特征计算子网络,将第一至第四卷积层的卷积核个数均设置为64,卷积核尺寸均设置为1
×
1。
[0032]
步骤1.2,构建图像特征增强子网络。
[0033]
搭建一个包括第一卷积层、第二卷积层和第三卷积层组成的图像特征增强子网络,其中,第一卷积层、第二卷积层与第三卷积层依次串联组成图像特征增强子网络,将第一至第三卷积的卷积核个数依次设置为1、1、512,卷积核尺寸依次设置为3
×
3、3
×
3、、1
×
1。
[0034]
步骤1.3,将图像特征提取子网络resnet50与序列特征计算子网络并联后与图像特征增强子网络、dimp跟踪模型解码器依次串联组成序列感知与特征增强的跟踪网络。
[0035]
上述图像特征提取子网络resnet50由第一卷积层、第一残差网络模块、第二残差网络模块和第三残差网络模块依次串联组成。dimp跟踪模型解码器由分类预测模块和位置回归模块并联组成。
[0036]
步骤2,生成训练集。
[0037]
步骤2.1,从自然图像视频数据集got10k、lasot、imagenet和trackingnet中随机采集100000个图像对,每对图像对由视频中相邻的两帧图像构成且两帧图像中均存在同一个不限种类的目标,两帧图像分别称为当前帧图像和前一帧图像。
[0038]
步骤2.2,对每对图像对进行预处理,以每对图像对的当前帧图像中目标的位置中心为裁剪中心,将图像对中两幅图像的尺寸均裁剪为[288
×
288
×
3],再将裁剪后的图像对进行随机平移或缩放处理。
[0039]
步骤2.3,对于每对预处理后的图像对,以位置框的形式标注目标在当前帧图像中的位置,所述位置框用[c,w,h]表示,c、w和h为位置框的中心、宽度和高度,将[c,w,h]作为图像对的目标真实位置框,同时以c为中心生成高斯标签图作为图像对的目标分类标签图。
[0040]
步骤2.4,将所有预处理后的图像对及其对应的目标分类标签图和目标真实位置框组成训练集。
[0041]
步骤3,训练网络。
[0042]
步骤3.1,将训练集中的图像对输入序列感知与特征增强的跟踪网络中,使用序列特征计算子网络计算当前帧图像和前一帧图像的序列特征,再使用图像特征增强子网络利用序列特征对当前帧图像的图像特征进行增强,最后使用dimp跟踪模型解码器解码增强特征,得到预测的分类响应图和预测的目标位置框。
[0043]
以图像对ic和i
p
在序列感知与特征增强的跟踪网络中的传播过程为例对步骤3.1作进一步的说明。
[0044]
将ic和i
p
分别输入图像特征提取子网络resnet50第一卷积层中,该卷积层输出当前帧图像第一卷层积特征和前一帧图像第一卷层积特征代表特征图的尺寸,width,hight和channel分别代表特征图的宽度、高度和通道数。再将依次输入第一残差网络模块,第二残差网络模块和第三残差网络模块,得到当前帧图像第二残差网络模块特征和当前帧图像第二残差网络模块特征
[0045]
根据和计算序列特征,将依次输入序列特征计算子网络第一卷积层和第二卷积层得到当前帧关键特征同时将依次输入序列特征计算子网络第三卷积层和第四卷积层得到之前帧关键特征将转置后与相乘得到初始序列特征将中的元素值在通道维度相加并取平均得到最终序列特征
[0046]
根据序列特征f
c,p
对图像特征进行增强,将f
c,p
分别输入图像特征增强子网络第一卷积层、第二卷积层和第三卷积层,第二卷积层和第三卷积层分别输出第一下采样特征和第二下采样特征再将和分别与和特征进行拼接,得到初始化增强特征和再将和分别输入图像特征增强子网络第四卷积层模块和第五卷积层模块得到增强特征和
[0047]
将增强特征输入dimp跟踪模型解码器分类预测模块得到预测的分类响应图,再将和同时输入dimp跟踪模型解码器位置回归模块得到预测的目标位置框。
[0048]
步骤3.2,使用sgd优化算法,离线迭代训练序列感知与特征增强的跟踪网络的参数,直到损失函数收敛为止,得到训练好的网络。
[0049]
所述损失函数l如下:
[0050][0051]
其中,n表示训练集中图像对的总数,i表示训练集中图像对的序号,∩表示交集操作,∪表示并集操作,y
cls
和分别表示目标分类标签图和网络预测的分类响应图,y
bbox
和表示目标真实位置框和网络预测的目标位置框。
[0052]
步骤4,使用训练好的网络对无人机视角视频中的目标进行在线跟踪。
[0053]
步骤4.1,根据无人机视角视频第一帧中给定的目标位置与目标尺寸确定待跟踪
目标。
[0054]
步骤4.2,从第二帧开始,以前一帧中目标位置的中心为裁剪中心,将当前帧与前一帧的尺寸裁剪为[288
×
288
×
3]后输入训练好的序列感知与特征增强的跟踪网络,得到预测分类响应图和预测目标位置框;如果预测分类响应图中的值均大于0.6,则视为对目标跟踪成功,执行步骤4.3;如果预测分类响应图中的值均小于0.6,否则视为对目标跟踪失败,执行4.4。
[0055]
步骤4.3,将当前帧图像的增强特征、预测分类响应图和预测目标位置框组成训练对,并将训练对存入记忆特征集合set
suc
。
[0056]
步骤4.4,根据记忆特征集合set
suc
中训练对中预测分类响应图的值对的训练对进行递减排序,使用排序后前20个训练对训练dimp跟踪模型解码器的参数,若记忆特征集合set
suc
中训练对的个数不足20个,则用排序后第1个训练对进行补充。
[0057]
步骤4.5,判断当前帧是否为跟踪视频的最后一帧,若是,则执行步骤4.2,否则,完成目标跟踪过程。
[0058]
下面结合仿真实验对本发明的效果做进一步的描述:
[0059]
1.仿真实验条件:
[0060]
本发明的仿真实验的软件平台为:本发明的仿真是在cpu为intel(r)core(tm)i7-11700k,显卡为nvidia 3090,内存为32g的ubuntu18.04系统上,使用python3.7软件以及pytorch1.8深度学习工具包上进行的。
[0061]
本发明仿真实验使用自行采集的无人机视角数据集中的50个视频序列进行目标跟踪方法测试,上述数据集中68%的视频序列中的目标为小尺寸目标(目标像素值个数小于900个),52%的视频序列中存在相机运动情况。
[0062]
2.仿真内容及其结果分析:
[0063]
本发明仿真实验是采用本发明和两个现有技术(基于序列信息的跟踪方法kys方法和基于判别预测模型的跟踪方法dimp方法),分别对上述50个视频序列中的目标进行跟踪,其结果如图2所示。图2仅显示50个视频序列中一段具有代表性的视频序列中的6帧关键帧的仿真结果,6帧关键帧分别为第1帧、第40帧、第56帧、第93帧、第196帧和第203帧,帧序号被标记在每帧图像的左上角。
[0064]
在本发明的仿真实验中,采用的两个现有技术是指:
[0065]
现有技术基于序列信息的跟踪方法kys方法是指,goutam和martin等人在其发表的论文“know your surroundings:exploiting scene information for object tracking”(会议名称:european conference on computer vision’2020)中公开了一种可用于无人机视角目标跟踪的基于序列信息的方法。
[0066]
现有技术基于判别预测模型的跟踪方法dimp方法是指,goutam和martin等人在其发表的论文“learning discriminative model prediction for tracking”(会议名称:computer vision and pattern recognition’2019)中公开了一种可用于无人机视角目标跟踪的基于序列信息的方法。
[0067]
下面结合图2的仿真图对本发明的效果做进一步的描述。
[0068]
图2中的绿色位置框代表仿真前真实目标的位置框,红色、黄色和蓝色位置框分别代表采用本发明方法、kys方法和dimp方法预测得到的目标位置框。从图2可以看出,虽然在
视频序列第1帧、第40帧、第56帧、第93帧和第196帧中本发明方法、kys方法和dimp方法均能跟踪到目标,但是在第196帧图像中相机发生了运动,上述三种方法都短暂丢失了目标,从第203帧图像中可以看到,由于相机运动较为剧烈且目标尺寸较小,kys方法和dimp方法均无法在后续帧中跟踪到目标,只有本发明方法在相机稳定后跟踪到了目标。
[0069]
为了验证本发明的仿真结果,利用两个评价指标(预测中心距离cle和预测位置框重合面积iou)分别对上述三种方法的目标跟踪结果进行评价。利用下面公式,cle和iou计算真实目标的位置框和三种方法预测得到的目标位置框的中心距离和重合面积,将所有计算结果绘制成表1:
[0070][0071][0072]
其中,frame为所述自建无人机视角数据集中的50个视频序列的总帧数,和分别为序号为f的视频帧中目标位置中心横坐标和纵坐标的网络预测值,和分别为序号为f的视频帧中目标位置中心横坐标和纵坐标的真实值。和为序号为f的视频帧中目标的位置框的网络预测值和真实值。
[0073]
表1.仿真实验中本发明和先进技术目标跟踪结果的定量分析表
[0074] cleioukys91.360.65dimp28.760.68本发明方法20.550.71
[0075]
结合表1可以看出,本发明的目标跟踪结果相较于kys方法和dimp方法均有提升,证明了本发明方法的先进性。
[0076]
以上仿真实验表明:本发明的基于序列感知与特征增强的无人机视角目标跟踪方法,通过构建序列特征计算子网络和图像特征增强子网络,提取视频序列特征对无人机相机的运动模式进行学习,并利用序列特征在时序维度对小目标的特征进行补充。从而解决无人机视角目标跟踪过程中的相机运动问题和小目标问题。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1