一种基于改进Transformer模型的时尚趋势预测方法
transformer模型的时尚趋势预测方法。
7.为解决以上技术问题,本发明采用以下技术方案:
8.一种基于改进transformer模型的时尚趋势预测方法,包括以下步骤:
9.步骤1、建立cpf数据集,所述cpf数据集中的每个样本数据均包括时 尚趋势数据和每个时尚趋势数据对应的用户信息;
10.步骤2、对cpf数据集中的数据进行预处理,对每个样本数据的处理方 式为,对用户信息数据采用prelu激活函数进行非线性处理后再进行标准化 处理,将时尚趋势数据输入线性投影层,随后使用全连接的方式将数据线性 映射到指定的维度上,形成一个矢量,再对矢量进行扩展因果卷积处理;对 用户信息数据和时尚趋势数据处理完成后,对处理后的数据进行位置编码, 将编码后的各个结果进行拼接,得到多维的编码信息,得到预处理后的样本 数据;
11.步骤3、将预处理后的样本数据作为训练集输入基于改进transformer 的cpft模型,通过最小化时尚元素关联模块所构建的损失函数对基于改进 transformer的cpft模型进行训练,得到训练好的cpft模型;
12.步骤4、利用训练好的cpft模型对输入数据进行预测,得到时尚趋势预 测结果。
13.进一步的,所述用户信息包括用户的年龄、性别和地区信息。
14.进一步的,所述时尚元素关联模块所构建的损失函数为:
[0015][0016][0017]
其中,其中是时尚元素s在cpft解码器输出的结果,是s 在训练数据中的目标序列,σ是确定正则化项权重的超参数,yk,y
p
分别是 任意两个时尚元素k,p的时间趋势矢量表示,代表t时间时两个矢量的 曼哈顿距离,t表示时尚元素的时间序列的长度,t’表示待预测的未来时段 的长度。
[0018]
进一步的,所述基于改进transformer模型的cpft模型为采用 probsparse self-attention方法,将计算复杂度从o(l2)降低到o(l log l)的 cpft模型。
[0019]
本发明采用以上技术方案后,与现有技术相比,具有以下优点:
[0020]
本发明构建了一个基于transformer的预测模型cpft,为了避免长序列 的趋势数据预测带来的庞大计算量,对自注意力机制进行优化,将其时间复 杂度由o(n2)减少到o(log n),在预测能力上带来了更大的改进。此外,构建 了一个包含了最新的时间趋势数据的数据集,具备着更多服装元素的描述信 息,此外,本发明设计了一个新的损失函数,可以考虑不同时尚元素间的关 联信息,对时尚元素间的复杂关联信息细致描述,以更精确的对时尚趋势进 行预测。
[0021]
在本发明的transformer模型中,针对不同的输入特征采用了多种处理 手段,将用户信息等不包含时间要素的静态特征进行非线性转换,对时间趋 势序列使用扩展因果卷积来保留顺序信息,保证在transformer进行编码过 程时能够对上下文信息产生更高的
敏感性,提高模型最终的预测性能。
[0022]
下面结合附图和实施例对本发明进行详细说明。
附图说明
[0023]
图1为本发明的方法总体流程图;
[0024]
图2为cpft编码器-解码器结构示意图;
[0025]
图3为门尼粘度预测效果示意图;
[0026]
图4为时尚元素间关系模块图;
[0027]
图5为时尚元素趋势预测效果示意图。
具体实施方式
[0028]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本 发明,并非用于限定本发明的范围。
[0029]
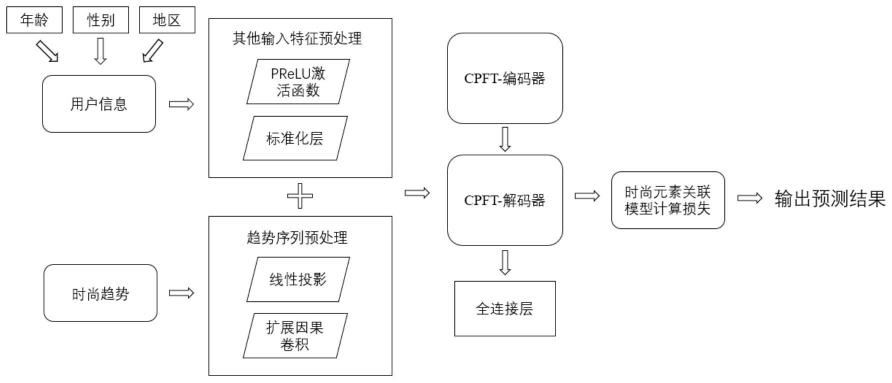
一、本发明的总体技术方案如图1所示,具体如下叙述:
[0030]
1.本发明的框架为一个改良的transformer框架,通过transformer模型 对输入序列模型的输入取自本发明所制作的数据集cpf,一共由两个部分组 成:用户信息、时尚趋势数据。用户信息包含取自社交平台instagram上的 用户的年龄,性别和地区三个部分内容,时尚趋势数据是对所采用该用户发 帖的时尚图片中的时尚元素的流行度计算得出。对于输入的多个模块,分别 进行预处理,然后其进行位置编码,将编码后的各个结果进行拼接,得到多 维的编码信息,作为编码器组件的输入。
[0031]
2.cpft模型保留了transformer的编码器和解码器结构,不同的是,为 了应对长序列的预测任务带来的庞大计算量和内存使用,对cpft编码器和解 码器内部所采用的多头自注意力机制进行优化,通过采用informer论文中所 介绍的probsparse self-attention方法,实现了将计算复杂度从o(l2)降低 到o(l log l)。cpft使用编码器和解码器内部分别堆叠三层,更好地学习并提 高算法的预测能力,且保证了不会过度拟合并使训练过程变得昂贵。
[0032]
3.通过对多个输入的位置编码通过cpft的编码器解码器层,将解码器模 块最后输出的结果通过一个全连接层,在这之后我们通过找出时尚元素之间 的关联信息构建了一个全新的损失函数来训练我们的模型,最后输出预测的 结果,有关时尚元素关联模型的介绍会在第5.2节实现方法里详细介绍。
[0033]
二、实现方法
[0034]
本发明采用了一种新的名为cpft的时尚趋势预测框架并在此工作中制 作了一个新的数据集cpf,大致分为四个部分:1.cpf数据集的收集与描述; 2.cpft模型输入预处理;3.时尚元素关联模型;4.基于transformer模型 的变体模型cpft。
[0035]
三、cpf数据集的收集与描述
[0036]
为了更好的预测时尚趋势,不仅需要获得详细准确的趋势数据,而且能 够对复杂的时尚数据进行充分且有意义的描述。基于这种想法,选自社交平 台instagram作为cpf数据集的数据来源,社交平台是当下人们信息交互的 主要方式,想要更好的了解和描述复杂的时尚趋势数据,离不开社交网络上 的大量信息。
[0037]
因此,本发明采集instagram上的数百万张帖子,获取发帖日期作为时 间依据,筛选出约80000张图像,并利用现有的技术对其进行时尚特征提取 工作,提取出图像中的服装属性和风格,总计204个不同的时尚元素。随后 以一个月为一个跨度计算每个时尚元素的流行度,以连衣裙为例,在一个月 内的图像数据中,连衣裙出现的次数占总图像的比例即为连衣裙在这半个月 的流行度。共收集了从2014年7月到2021年7月这7年(即时间序列长度) 的时尚数据。此外除却收集到的时尚趋势数据,还利用instagram上帖子获 取更多用户的信息,用户信息包含三个内容分别是用户的年龄、性别和地区, 根据发帖的位置判断该服装图像的地区,总共获取了来自14个城市地区的 用户信息。将这些用户信息和趋势数据组合在一起,构成了本文发明的cpf 数据集。
[0038]
四、cpft模型输入预处理
[0039]
在本发明中对输入的时间序列数据和其他特征分别进行处理,对输入的 时间趋势数据先经过一个线性投影层,随后使用全连接的方式将数据线性映 射到指定的维度上,形成一个矢量表示,以便于后续的进行注意力的计算。 由于时间序列数据中的时间模式,数据会随着时间的推移会部分产生周期性 变化,具有自相关性或周期性,比如在时尚元素的趋势中,服装随着季节的 不断更替趋势也在变化,所以时间序列中的变化点和异常值等都十分依赖上 下文的数据点,但是transformer的自注意匹配对局部上下文不敏感的键进 行查询,这可能使模型容易出现异常,并带来底层的优化问题,所以在此处 我们使用扩展因果卷积来解决这一问题,可以使得我们对时间数据建模时保 留顺序信息,让模型对局部的上下文信息产生更高的敏感性,提高模型最终 的预测性能。
[0040]
模型输入的数据除了每个时尚元素的时间序列数据之外,还有许多其他 不会随着时间变化而产生周期性变化的静态特征数据,本发明将这些静态特 征输入,如用户的性别,年龄,地区等进行非线性处理,
[0041][0042]
对于输入的诸多静态特征,首先采用了prelu(parametric relu)激活函 数对输入进行非线性处理,在静态特征进入第一个隐藏层进行全连接处理后, 通过prelu层对其进行非线性转换,随即进入下一个隐藏层计算新的隐藏状 态,最后通过一个标准化层对结果进行标准化处理,这是为了避免在续和处 理过的时尚元素时间序列进行结合时,由于不同的方式进行权重计算,出现 权重的量纲相差很大而使得训练结果变差。
[0043]
在分别对其他输入的特征和趋势序列进行预处理后,将处理后的数据输 入到cpft模型的编码器-解码器结构当中,对其进行位置编码,充分序列获 取上下文的信息,拼接后作为输入进入编码器。
[0044]
五、时尚元素关联模型
[0045]
过往的很多工作将每个时尚元素的趋势独立进行趋势数据的收集和预 测,但事实上时尚元素并不是独立分隔的,比如如果短袖t恤的流行度趋势 上升,那么短裤的流行度趋势也在上升,毛衣的流行度趋势便会下降。所以 考虑到诸如此种不同时尚元素之间的相关特征,本文所发明的方法设计了一 种新的模型去对时尚元素之间的关联进行建模。
[0046]
本发明以每个时尚元素的时尚趋势进行计算其之间的相关性表示为他 们之间的关联,在所收集的所有时尚元素的时间趋势序列当中,随机抽取趋 势序列先经过一个线性
投影层将数据线性映射到指定的维度上,形成一个矢 量表示,再使用l1距离(如下公式)计算每两个序列之间的相似度r。
[0047]dk,p
=‖y
k-y
p
‖
[0048][0049]
其中yk,y
p
分别是任意两个时尚元素k,p的时间趋势矢量表示,d
k,p
代 表两个矢量的曼哈顿距离。
[0050]
根据我们计算所得的相似度,我们构建出一个新的损失函数:
[0051][0052]
其中是时尚元素s在cpft解码器输出的结果,是s在训练数 据中的目标序列,σ是确定正则化项权重的超参数。
[0053]
通过所提出的损失函数,我们在cpft模型输出后,通过公式计算出模型 的损失,此损失用于生成梯度以在反向传播期间训练模型。
[0054]
六、基于transformer变体的cpft模型
[0055]
cpft中encoder-decoder基本框架和attention is all you need相似, 图2显示了我们的模型的编码器解码器模型的示意图,包含了位置编码,自 注意力层,多头自注意力层和完全连接的前馈子层几个部分,但是由于 self-attention自身的二次复杂度的计算,使得预测长时间的时尚元素趋势 会变得更困难,于是我们采用了优化后的probsparse self-attention,将 自注意力机制的二次复杂度降低。
[0056]
我们的模型具体实现步骤如下:
[0057]
1.将时间序列处理方案处理的输入数据馈送到cpft编码器。
[0058]
2.从步骤1的输入数据中提取序列相对位置信息,输出位置编码。
[0059]
3.步骤2的输出被传递到优化后的多头部注意层;然后,执行相加和层 归一化操作。
[0060]
4.将步骤3的结果馈送到按位置前馈层,并且再次执行加法和层归一化 操作以计算最终输出,其被用作cpft解码器层的输入的一部分。
[0061]
5.将cpft解码器输入馈送到优化后的掩码多头注意力,并执行相加和层 归一化操作。
[0062]
6.将步骤5的输出和cpft编码器层输出用作多头注意力的输入,并执行 相加和层归一化操作。
[0063]
7.步骤6的结果被馈送到按位置前馈层,该前馈层再次执行加法和层归 一化操作以计算最终的cpft解码器层输出。
[0064]
在cpft解码器输出结果后,通过一个全连接层将来自解码器最后一层 的神经网络的注意力值扁平化,再经过我们提出的时尚元素关联模块所构建 的损失函数进行训练,最终输出预测结果。
[0065]
七、实验结果
[0066]
1、门尼粘度预测
[0067]
以门尼粘度预测作为预测的工作内容,使用本发明的模型,同样对输入 的特征分别进行静态特征和时间序列趋势进行处理,由图3可以看出,该实 例结果和真实值结果极为接近。
[0068]
2、时尚元素趋势预测
[0069]
如图4所示找出了所有的时尚元素通常被组织成具有树形结构的层次分 类法。子节点与其关联的父节点之间存在隶属关系,这将进一步影响其对应 的趋势序列。例如,如果发现属性裙子的趋势上升,则类别下服装元素也很 可能上升。通过这种模块的知识增强,其预测的结果如5图所示十分逼近真 实数据。
[0070]
以上所述为本发明最佳实施方式的举例,其中未详细述及的部分均为本 领域普通技术人员的公知常识。本发明的保护范围以权利要求的内容为准, 任何基于本发明的技术启示而进行的等效变换,也在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1