一种日志范化的数据处理系统的制作方法
1.本发明涉及数据处理领域,特别是涉及一种日志范化的数据处理系统。
背景技术:
2.目前,随着大数据的兴起,使用的软件越来越多、越来越复杂,通常软件以记录日志的方式留下操作流程,如此就产生了大量的日志,对设备的日志的范化要求越来越高,所述范化是指将日志字段提取出来,并将日志字段规则化、通用化、标准化。采用人工的方式进行查看,则需要耗费大量时间且效率极低,难以发现异常情况,对日志进行范化需要提取日志内容、修改日志内容并将日志内容以一个固定格式展现出来,因此很多服务器在加上范化功能后,会对服务器的性能造成直线下降,消耗服务器大量的资源,同时范化的规则越复杂,性能越受影响。
技术实现要素:
3.针对上述技术问题,本发明采用的技术方案为:
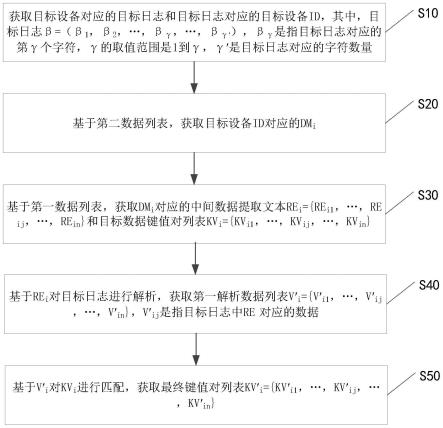
4.一种日志范化的数据处理系统,所述系统包括如下数据库、处理器和存储有计算机程序的存储器,所述数据库中存储有第一数据列表a={a1,a2,
…
,ai,
…
,am},ai=(dmi,rei,kvi),kvi={kv
i1
,
…
,kv
ij
,
…
,kv
in
},以及第二数据列表b={b1,b2,
…
,bi,
…
,bm},bi=(hi,dmi),其中,dmi是指第i个第一设备标识,rei是指dmi对应的中间数据提取文本列表,k
ij
是指dmi对应的第j个目标数据键值对,hi为dmi对应的初始设备id列表,i的取值范围是1到m,m是指第一设备标识数量,j的取值范围是1到n,n是指ai对应的目标数据键值对数量,当处理器执行一段计算机程序,执行如下步骤:
5.s1,获取目标设备对应的目标日志和目标日志对应的目标设备id,其中,目标日志β=(β1,β2,
…
,β
γ
,
…
,β
γ
′
),β
γ
是指目标日志对应的第γ个字符,γ的取值范围是1到γ,γ
′
是目标日志对应的字符数量;
6.s2,基于第二数据列表,获取目标设备id对应的dmi;
7.s3,基于第一数据列表,获取dmi对应的中间数据提取文本rei={re
i1
,
…
,re
ij
,
…
,re
in
}和目标数据键值对列表kvi={kv
i1
,
…
,kv
ij
,
…
,kv
in
};
8.s4,基于rei对目标日志进行解析,获取第一解析数据列表v
′i={v
′
i1
,
…
,v
′
ij
,
…
,v
′
in
},v
′
ij
是指目标日志中re对应的数据;
9.s5,基于v
′i对kvi进行匹配,获取最终键值对列表kv
′i={kv
′
i1
,
…
,kv
′
ij
,
…
,kv
′
in
}。
10.本发明至少具有以下有益效果:
11.基于s1-s5,通过目标日志获取目标日志中的目标设备id,在获取目标设备id时,基于第二数据列表,获取目标id对应的第一设备标识,通过第一数据列表,获取对应的中间数据提取文本和目标数据键值对列表,通过中间数据提取文本对目标日志进行解析,获取第一解析数据列表,基于目标键值对列表对第一解析数据列表进行匹配,获取最终键值对
列表,从而获取目标日志对应的键值对,使用数据库中第一数据列表和第二数据列表对目标日志进行匹配,获取目标日志中的键值对,不用采取人工方式进行识别,更加智能化、简洁化,减少了匹配时间,提高效率。
附图说明
12.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
13.图1为本发明实施例1提供的一种日志范化的数据处理系统执行程序的流程图。
14.图2为本发明实施例2提供的一种获取目标数据提取文本列表的方法的流程图。
具体实施方式
15.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
16.实施例1
17.本发明实施例1提供了一种日志范化的数据处理系统,所述系统包括如下数据库、处理器和存储有计算机程序的存储器,所述数据库中存储有第一数据列表a={a1,a2,
…
,ai,
…
,am},ai=(dmi,rei,kvi),kvi={kv
i1
,
…
,kv
ij
,
…
,kv
in
},以及第二数据列表b={b1,b2,
…
,bi,
…
,bm},bi=(hi,dmi),其中,dmi是指第i个第一设备标识,rei是指dmi对应的中间数据提取文本列表,k
ij
是指dmi对应的第j个目标数据键值对,hi为dmi对应的初始设备id列表,i的取值范围是1到m,m是指第一设备标识数量,j的取值范围是1到n,n是指ai对应的目标数据键值对数量,当处理器执行一段计算机程序,执行如下步骤,如图1所示:
18.s1,获取目标设备对应的目标日志和目标日志对应的目标设备id,其中,目标日志β=(β1,β2,
…
,β
γ
,
…
,β
γ’),β
γ
是指目标日志对应的第γ个字符,γ的取值范围是1到γ,γ
′
是目标日志对应的字符数量;
19.具体地,在s1步骤中通过如下步骤获取目标设备id:
20.s101,当h
i1
为数字时,基于h
i1
对β依次进行遍历,其中,hi=(h
i1
,h
i2
,
…
,h
iα
,
…
,h
iα
′
),h
iα
是指hi对应的第α个字符,α的取值范围是1到α
′
,α
′
是指hi对应的字符数量。
21.s102,当β
γ
为数字时,判断h
i1
是否等于β
γ
。
22.s103,当存在h
i1
=β
γ
且h
iα
=β
γ+α-1
时,将hi作为目标id。
23.s104,当h
i1
不是数字且h
iα
′
是数字时,基于h
iα
′
对β依次进行遍历。
24.s105,当β
γ
为数字时,执行s106。
25.s106,当存在h
i1
=β
γ
时,当h
iα
=β
γ-α+1
时,将hi作为目标id。
26.s107,当h
i1
不是数字且h
iα
′
不是数字时,基于h
i1
对β依次进行遍历,获取目标id。
27.基于s101-s107,判断h
i1
是否为数字,当h
i1
为数字时,使用h
i1
对目标日志进行遍历,当β
γ
为数字时,且h
i1
=β
γ
时,判断hi后α
′‑
1位字符是否和β
γ
后α
′‑
1位字符对应相等,当
对应相等时,将hi作为目标id;当hi第一个字符不是数字且hi最后一个字符为数字时,通过hi最后一个字符进行遍历,当hi最后一个字符匹配成功时,判断β
γ
前α-1是否对应相等,当对应相等时,将hi作为目标id,使用了数字先进行匹配的方法,使用数字进行匹配,排除了和目标日志中的字母进行匹配,减少了匹配时间,更加快速地获取目标id。
28.在本发明一个优选的实施例中,当h
i1
不是数字且h
iα
′
不是数字时,执行如下步骤:
29.s1071,获取固定分隔符列表c={c1,c2,
…
,cg,
…
,cz},cg是指第g个固定分隔符,g的取值范围是1到z,z是指固定分隔符的数量。
30.具体地,本领域技术人员知晓,固定分隔符可根据实际情况确定。
31.可选的,z《20;优选地,z=4。
32.进一步地,当z=4时,固定分隔符列表包括“空格”或“,”或“。”或“下斜线”。
33.s1072,将目标日志按照固定分隔符列表c进行分割,获取目标分割区域列表d={d1,d2,
…
,d
x
,
…
,dq},d
x
是指目标日志按照c进行分割后的第x个目标分割区域,x的取值范围是1到q,q是指目标分割区域的数量。
34.具体地,本领域技术人员知晓,目标日志包括固定分隔符的一种或多种,将目标日志按照固定分隔符的位置进行分割,获取目标分割区域,从而构成目标分割区域列表。
35.s1073,获取目标分割区域字符串数量列表q={q1,q2,
…
,q
x
,
…
,qq},q
x
是指d
x
对应的目标分割区域的字符串数量。
36.s1074,获取指定分割区域列表d
′
={d
′1,d
′2,
…
,d
′y,
…
,d
′
p
}和指定分割区域字符串数量列表q
′
={q
′1,q
′2,
…
,q
′y,
…
,q
′
p
},其中,q
′y≥q(hr),d
′y是指第y个指定分割区域,q
′y是指d
′y对应的字符串数量,y的取值范围是1到p,p为指定分割区域的数量。
37.具体地,将目标分割区域中字符串数量不小于hr的字符串数量的目标分割区域标记为指定分割区域,并且获取指定分割区域列表,目标分割区域中字符串数量小于hr的字符串的数量不可能为目标id,因此进行了排除之后再进行匹配,减少花费的时间,提高效率。
38.s1075,获取第二匹配次数sum2=∑
py=1
[q
′
y-q(hr)+1]。
[0039]
s1076,获取目标日志的字符数量q且获取第一匹配次数sum1=q-q(hr),其中,第一匹配次数是指基于s107进行遍历的次数。
[0040]
s1077,当sum2《sum1时,基于hr遍历d
′y,获取目标id。
[0041]
根据s1071-s1077,基于固定分隔符对目标日志进行分割,获取目标分割区域,通过判断目标分割区域的字符串的数量和hr的字符串的数量,获取指定分割区域列表,判断指定分割区域的遍历次数和直接进行遍历的次数,当使用指定分割区域的遍历次数小于直接进行遍历的次数时,在每一指定分割区域进行遍历匹配,获取目标id,从而进行遍历的次数更少,减少时间消耗。
[0042]
s2,基于第二数据列表,获取目标设备id对应的dmi。
[0043]
具体地,设备id型号对应列表中存储有设备id和dm的对应的关系,通过两者的对应关系找到目标id对应的目标dm。
[0044]
其中,在本发明一个实施例中,目标dm经过md5化加密处理,将目标设备型号及对应的厂商进行md5化生成一个固定长度的字符串,在本发明一实施例中,固定长度为128位。
[0045]
具体地,md5化是对一段信息产生信息摘要,即通过不可逆的字符串变换算法产生
唯一的md5摘要,md5摘要即一个固定长度的字符串,对一段信息产生信息摘要,以防止被篡改,同时md5摘要可能会发生碰撞,但概率很小,因此可以对设备型号及设备型号对应的厂商进行保护,同时更易于传输。
[0046]
s3,基于第一数据列表,获取dmi对应的中间数据提取文本rei={re
i1
,
…
,re
ij
,
…
,re
in
}和目标数据键值对列表kvi={kv
i1
,
…
,kv
ij
,
…
,kv
in
}。
[0047]
具体地,基于目标dm,可以获取目标设备对应的中间数据提取文本rei和目标键值对列表kvi。
[0048]
s4,基于rei对目标日志进行解析,获取第一解析数据列表v
′i={v
′
i1
,
…
,v
′
ij
,
…
,v
′
in
},v
′
ij
是指目标日志中re对应的数据。
[0049]
具体地,中间数据提取文本rei={re
i1
,
…
,re
ij
,
…
,re
in
},使用中间数据提取文本进行匹配,获取中间数据提取文本对应的解析数据。
[0050]
具体地,本领域技术人员知晓使用中间数据提取文本对目标日志进行匹配的方法,此处不再赘述。
[0051]
s5,基于v
′i对kvi进行匹配,获取最终键值对列表kv
′i={kv
′
i1
,
…
,kv
′
ij
,
…
,kv
′
in
}。
[0052]
具体地,可以理解为中间数据提取文本rei和目标键值对列表kvi中re
ij
和kv
ij
为对应关系,将第一解析数据列表中v
′
ij
进行匹配,获取最终键值对kv
′
ij
,并基于最终键值对kv
′
ij
获取最终键值对列表kv
′i。
[0053]
基于s1-s5,通过目标日志获取目标日志中的目标设备id,在获取目标设备id时,基于第二数据列表,获取目标id对应的第一设备标识,通过第一数据列表,获取对应的中间数据提取文本和目标数据键值对列表,通过中间数据提取文本对目标日志进行解析,获取第一解析数据列表,基于目标键值对列表对第一解析数据列表进行匹配,获取最终键值对列表,从而获取目标日志对应的键值对,使用数据库中第一数据列表和第二数据列表对目标日志进行匹配,获取目标日志中的键值对,不用采取人工方式进行识别,更加智能化、简洁化。
[0054]
实施例2
[0055]
在实施例1的基础上,本发明还提供一种获取目标指定文本列表的方法,如图2所示,所述方法包括如下步骤:
[0056]
s10,获取第二目标日志和第二目标日志对应的第二目标dm。
[0057]
具体地,通过s101-s107获取第二目标日志对应的第二目标id。
[0058]
进一步地,基于第二目标id,获取第二目标id对应的第二目标dm。
[0059]
s20,当dmi满足预设处理条件,执行s30,否则执行s50。
[0060]
s30,当dmi不满足预设处理条件时,否则执行s60。
[0061]
具体地,所述dmi满足预设处理条件为dmi未经过m5d化。进一步地,本领域技术人员知晓,现有技术中任何判断第一设备表示是否经过md5化的方法均属于本发明保护范围,此处不再赘述。
[0062]
s40,当存在dmi等于第二目标dm时,获取dmi对应的rei作为第二目标re列表;
[0063]
具体地,可以通过第一数据列表获取dmi对应的rei。
[0064]
s50,当任意dmi不等于第二目标dm,执行s60;
[0065]
s60,基于第一数据列表,获取中间数据提取文本列表re={re1,re2,
…
,rei,
…
,rem},rei={re
i1
,re
i2
,
…
,re
it
,
…
,re
ik
},re
it
是指第i个re列表中第t个中间数据提取文本,t的取值范围是1到k,k是指rei中指定文本的数量。
[0066]
s70,基于rei对第二目标日志进行解析,获取目标解析数据列表di={d
i1
,d
i2
,
…
,d
it
,
…
,d
ik
},d
it
是指re
it
对应的目标解析数据。
[0067]
s80,获取空集数量列表e={e1,e2,
…
,ei,
…
,em},ei是指遍历di,d
it
=null的数量。
[0068]
具体地,本领域技术人员知晓,现有技术中任何一种判断解析数据是否为空集的方法均属于本发明保护范围,此处不再赘述。
[0069]
s90,获取最小空集数量e
′
,e
′
=min(e1,e2,
…
,ei,
…
,em)。
[0070]
可以理解为,使用中间数据提取文本列表对第二目标日志进行解析,获取使用每一中间数据提取文本列表的第二解析数据列表,并根据第二解析数据列表获取第二解析数据列表中空集的数量,获取空集数量最少的第二解析数据。
[0071]
s91,获取e
′
对应的re
′
且将re
′
作为第二目标数据提取文本列表。
[0072]
具体地,e
′
《e0,e0为预设空集数量阈值,e0可根据实际需求确定。可以理解为,当最小空集数量仍然过大时,说明第二目标日志与第二目标数据提取文本列表的匹配度并不高,大部分中间数据并不能匹配成功,因此第二解析数据并不具有可信性,所以对最小空集数量设置预设空集数量阈值,保证获取的第二目标指定文本列表的可信性。
[0073]
可选的,e0《0.2*k;优选地,e0《0.1*k。
[0074]
基于s10到s90,获取第二目标日志且基于第二目标日志获取第二目标dm,当第一数据列表中dm未经过md5化时,获取中间数据提取文本列表dm进行遍历,获取第二目标指定文本列表,当没有dmi与第二目标dm相等时或者设备信息列表中dm经过md5化时,获取中间数据提取文本列表re,使用中间数据提取文本列表re对第二目标日志进行解析,获取第二解析数据和第二解析数据对应空集数量列表,将空集数量最少的中间数据提取文本列表作为第二目标数据提取文本列表,采用进行判断是否进行md5化的方式,而非现有技术中通过指令告知是否md5化的方式,更具有灵活性,减少了数据进行交互的过程,使得程序更加节约。
[0075]
基于此,本发明获取目标日志及目标日志中的目标设备id,通过判断初始设备id列表中的首个字符和末尾字符是否未数字的方法确定目标id,减少了依次进行遍历时消耗的时间,基于第一数据列表和第二数据列表,获取目标设备id对应的中间数据提取文本列表和目标数据键值对列表,从而获取最终键值对列表,实现了匹配过程,实施例2通过判断第一设备标识是否经过md5化,未经过md5化时,直接进行匹配,经过md5化时,获取中间数据提取文本列表中空集数量较少作为第二目标数据提取文本列表。从而本发明更加节约时间,提高了效率,且使得程序更加节约。
[0076]
虽然已经通过示例对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上示例仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员还应理解,可以对实施例进行多种修改而不脱离本发明的范围和精神。本发明开的范围由所附权利要求来限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1