一种基于ISSA-HKELM的短期负荷预测方法与流程
一种基于issa-hkelm的短期负荷预测方法
技术领域
1.本发明涉及一种短期负荷预测方法,尤其是涉及一种基于issa(改进麻雀搜索算法)-hkelm(优化混合核极限学习机)的短期负荷预测方法。
背景技术:
2.负荷预测是实现能源规划、经济运行和能量管理的重要基础,通常包括长期负荷预测、中期负荷预测和短期负荷预测,其中,短期负荷预测一般指的是对未来一天或者一周的负荷进行预测,短期负荷预测的特点在于会受到天气、设备状况、重大社会活动等因素的影响较大,因此准确的对短期负荷进行预测存在较大的困难。工业、民用、公用事业用电负荷特征迥异,电力负荷往往因天气的变化而具有很大的波动性和季节性,对电力负荷做出准确的预测,是电力系统制订扩容、运行、检修等计划的基础。
3.在短期电力负荷预测领域中,预测方法主要分为基于统计的传统方法和基于机器学习的方法。传统方法主要分为时间序列法、回归分析、卡尔滤波法等,这些方法多是通过对历史数据进行拟合,从而对负荷的未来趋势进行判断,方法简单,但缺点是不能反映负荷的非线性特性。机器学习方法主要包括bp神经网络、支持向量机(svm)、极限学习机(elm)等,这些方法虽然预测精度比传统方法高,但也存在过程复杂、稳定性差、参数难于调整等问题。核极限学习机(kelm)是一种基于核函数新型单隐藏层的前馈神经网络算法,在处理非线性回归方面具有良好的效果。传统的核极限学习机(kelm)大都采用单一的核函数,具有较弱的泛化能力和预测性能;麻雀搜索算法作为一种新型的群智能优化算法,具有参数设置简单、收敛速度快等优点,但麻雀搜索算法在迭代后期会出现种群多样性减小和易陷入局部极值的问题。
技术实现要素:
4.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种良好的预测精度和鲁棒性的基于issa-hkelm的短期负荷预测方法。
5.本发明的目的可以通过以下技术方案来实现:
6.根据本发明的一个方面,提供了一种基于issa-hkelm的短期负荷预测方法,该方法包括:
7.首先针对核极限学习机kelm的缺陷,结合高斯核函数和多项式核函数构造具有更强泛化能力的混合核极限学习机hkelm;
8.其次针对麻雀搜索算法易陷入局部极值的问题,引入自适应t分布策略和动态自适应权重对麻雀搜索算法进行改进;
9.再次采用改进后的麻雀搜索算法issa对混合核极限学习机hkelm的参数进行优化并建立issa-hkelm预测模型;
10.最后采用建立好的issa-hkelm模型进行短期负荷预测。
11.作为优选的技术方案,所述issa-hkelm预测模型的输入和输出变量选取如下:
12.将预测日前一天的历史负荷数据、前一天的最高温度、最低温度、平均温度、相对湿度和降雨量以及当天的最高温度、最低温度、平均温度、相对湿度和降雨量作为模型的输入量;
13.将预测日当天的负荷数据作为输出量。
14.作为优选的技术方案,所述混合核极限学习机hkelm有效解决核极限学习机泛化能力较弱的问题。
15.作为优选的技术方案,所述自适应t分布策略具体为:
16.对麻雀位置利用自适应t分布进行更新如下式所示
[0017][0018]
其中xi为第i只麻雀个体的位置;表示经过t变异后的麻雀的位置;t(k)表示参数自由度为迭代次数k的t分布。
[0019]
作为优选的技术方案,当前期迭代次数k较小时,t分布类似柯西分布变异,此时的t分布算子大概率取得较大值,位置变异采取的步长较大,使得算法拥有较好的全局搜索能力;在迭代中期,t分布由柯西分布变异向高斯分布变异转变,此时的t分布算子大概率取值相对折中,使得算法同时兼顾全局和局部搜索能力;当后期迭代次数k较大时,t分布类似高斯分布变异,此时的t分布算子大概率取得较小值,位置变异采取的步长较小。
[0020]
作为优选的技术方案,所述动态自适应权重具体为:
[0021]
将惯性权重的思想引入到麻雀中的发现者的位置更新公式中并对其进行改进,即在发现者位置更新方式中引入动态权重因子ω。
[0022]
作为优选的技术方案,所述动态权重因子ω的值与最大迭代次数k和当前迭代次数k有关,并且随着当前迭代次数k的增加而减少;在迭代初期,迭代次数较小时,ω的值则较大;在迭代后期,迭代次数变大时,ω值则较小。
[0023]
作为优选的技术方案,所述动态权重因子ω的计算公式和改进后的发现者位置更新方式如下所示:
[0024][0025][0026]
其中为上一代中第j维的全局最优解,k表示当前迭代次数;j=(1,2,
…
d);表示在第k次迭代中第i只麻雀在第j维的位置;k表示最大迭代次数;z∈(0,1]中的随机数;r2代表预警值且r2∈[0,1];st代表安全阈值且st∈[0.5,1];q代表服从正态分布的随机值;l是一个内部元素均为1的1
×
d的矩阵。
[0027]
作为优选的技术方案,所述的改进后的麻雀搜索算法issa对混合核极限学习机hkelm的参数进行优化具体过程为:
[0028]
步骤1:将配电网数据划分为训练集和测试集并进行归一化处理;
[0029]
步骤2:初始化参数,麻雀种群规模n,最大迭代次数k,安全阈值st,发现者比例pd,侦查者的比例sd,t分布变异概率p以及模型参数的优化区间;
[0030]
步骤3:计算适应度值,将模型对训练样本进行学习得到的预测值yi'和真实值yi的均方误差作为适应度值;
[0031]
步骤4:计算适应度值并排序,产生最优和最差个体,以及相对应的位置,从适应度值较优的麻雀中选择部分为发现者,剩余为跟随者;
[0032]
步骤5:根据各自的位置更新公式分别更新跟随者,警戒者和发现者的位置,计算更新后对应的适应度值并与目前的最佳适应度值进行比较,更新全局最优信息;
[0033]
步骤6:如果rand《p,对麻雀进行t分布变异操作,其中rand表示0到1之间的随机数,p取值为0.5,否则,返回步骤3;
[0034]
步骤7:计算麻雀进行t分布变异后的适应度值,如果经过t变异操作后新解的适应度值要优于全局最优值,则用变异后的新值代替以前的全局最优值,否则保留;
[0035]
步骤8:终止条件,若已达到最大迭代次数,则输出模型参数得到最佳issa-hkelm模型,否则返回步骤3。
[0036]
作为优选的技术方案,选用均方根误差、平均绝对百分比误差、平均绝对误差和拟合度作为issa-hkelm模型的评价指标。
[0037]
与现有技术相比,本发明具有以下优点:
[0038]
1)本发明通过利用issa(improved sparrow search algorithm,改进的麻雀搜索算法)的寻优能力优化hkelm的参数,通过hkelm来挖掘负荷数据内的有用信息,从而较好的拟合负荷数据,准确高效地完成超短期的电力负荷预测。
[0039]
2)本发明针对kelm模型泛化能力较弱的问题,结合高斯核函数和多项式核函数构造具有泛化能力更强的混合核极限学习机(hkelm),针对hkelm模型的预测性能由模型参数解决的问题,采用麻雀搜索算法对其参数进行优化选择,同时针对麻雀搜索算法在迭代后期会出现种群多样性减小和易陷入局部极值的问题,提出了一种基于改进麻雀搜索算法优化hkelm的短期电力负荷预测模型,增强了模型预测的稳定性,提高了预测精度。
附图说明
[0040]
图1为核极限学习机拓扑结构图;
[0041]
图2为多项式核函数曲线图;
[0042]
图3为高斯核函数曲线图;
[0043]
图4为混合核函数曲线图;
[0044]
图5为t分布、高斯分布和柯西分布函数分布图;
[0045]
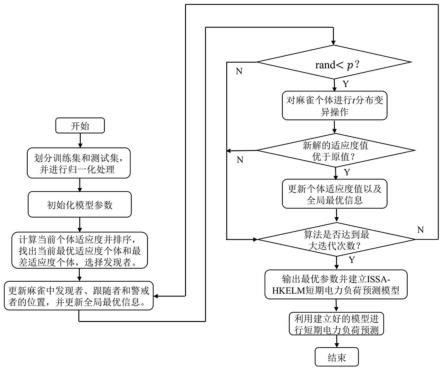
图6为issa-hkelm模型流程图;
[0046]
图7为不同模型的预测结果对比图。
具体实施方式
[0047]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
[0048]
本发明一种基于改进麻雀搜索算法优化混合核极限学习机的短期电力负荷预测
方法,首先结合高斯核函数和多项式核函数构造具有泛化能力更强的混合核极限学习机(hkelm);然后针对麻雀搜索算法易陷入局部极值的问题,引入自适应t分布策略和动态自适应权重对麻雀搜索算法进行改进;最后建立issa-hkelm模型进行短期负荷预测,并与lstm、dbn、kelm、hkelm、pso-hkelm和ssa-hkelm模型的预测结果进行对比分析,包括以下步骤:
[0049]
a、预测模型输入与输出变量的选取:
[0050]
电力负荷数据本身就具有动态特性,将历史负荷数据以天为单位,每天划分为96个时刻点(每15分钟一个点)作为负荷自身波动规律,将预测日前一天的历史负荷数据、前一天的最高温度、最低温度、平均温度、相对湿度和降雨量以及当天的最高温度、最低温度、平均温度、相对湿度和降雨量作为模型的输入量(106个输入量),将预测日当天的负荷数据作为输出量进行模型的训练和预测(96个输出量)。
[0051]
b、混合核极限学习机(hkelm)
[0052]
核极限学习机(kelm)作为一种基于核函数新型单隐藏层的前馈神经网络算法,在处理非线性回归方面具有良好的效果,该网络的输出可以表示为:
[0053]
f(x)=h(x)β=hβ
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0054]
式中,x表示输入数据,f(x)表示kelm模型的预测输出,h(x)表示隐藏层的映射函数,h表示输入样本经过核函数映射产生的矩阵,其由元素xi组成,β表示隐藏层与输出层之间的权值。kelm的核矩阵表示如下:
[0055][0056]
kelm用核矩阵ω
elm
代替了elm中hh
t
,并通过核函数将输入样本映射到高维隐层特征空间中,式中的k(xi,xj)表示核函数。常见的核函数主要分为以下四种:
[0057]
1)高斯核函数
[0058]
k(xi,xj)=exp(-||x
i-xj||2/(2σ2))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0059]
2)多项式核函数
[0060]
k(xi,xj)=(m(xi·
xj)+n)d;d=1,2,
…
,n
ꢀꢀꢀꢀꢀ
(4)
[0061]
3)线性核函数
[0062]
k(xi,xj)=xi·
xjꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0063]
4)感知器核函数
[0064]
k(xi,xj)=tanh(β(xi·
xj)+b)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0065]
由kelm拓扑结构图图1所示,x为模型的输入向量,x1,x2,
…
xn为训练集样本,为防止模型出现过拟合的现象,在核矩阵ω
elm
的主对角线上增加单位矩阵i0和惩罚系数c,然后再求β,这样使得核极限学习机拥有更好的泛化能力,输出和输出权值向量如式(7)、(8)所示。
[0066][0067]
β=(i0/c+ω
elm
)-1
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0068]
式中,t为目标输出矩阵。
[0069]
kelm的性能由核函数决定,本文结合了多项式核函数和高斯核函数作为kelm的核函数以提高模型的性能。多项式核函数是一种全局核函数,拥有较差的局部学习能力,根据多项式核函数曲线可以看出,其中测试点x=0.5,m=1,n=1,d取1、2、3和4,根据多项式函数曲线图2可以看出多项式核函数的全局特性体现在与测试点相距较远的点影响较大。
[0070]
高斯核函数是一种局部核函数,具有很好的局部学习能力,但是对超出一定范围的样本无法进行准确有效地预测,根据高斯核函数曲线图图3可以看出,其中测试点x=0.5,σ取0.1、0.2、0.3和0.4,由此可知高斯核函数的局部特性体现在与测试点相距较近的点影响较大。
[0071]
混合核函数可以同时兼顾两者的优点,因此将两种核函数进行线性组合形成混合核函数:
[0072][0073]
根据混合核函数曲线图图4可以看出,其中测试点x=0.5,λ取0.1,0.2,0.3和0.4,高斯核函数中σ取0.1,多项式核函数中m=1,n=1,d=2,混合核函数不仅对对测试点周围的样本点有影响,而且对距离测试点有一定距离的样本点也有一定影响,因此混合核函数有效结合了高斯核函数核多项式核函数的优点,弥补了单一核函数的不足。
[0074]
其中,σ、m、n和d为混合核参数,λ为多项式核函数的权系数,其中d=2。训练混合核极限学习机(hkelm)时采用改进的麻雀搜索算法对σ、m、n、λ以及惩罚系数c进行优化。
[0075]
c、改进麻雀搜索算法优化混合核极限学习机的模型(issa-hkelm)
[0076]
麻雀搜索算法(sparrow search algorithm,ssa)是于2020年由xue等人提出来的一种新型智能优化算法,该算法主要受麻雀捕食和反捕食行为的启发。麻雀集合矩阵如下:
[0077]
x=[x1,x2,
…
,xn]
t
,xi=[x
i,1
,x
i,2
,
…
,x
i,d
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0078]
式中,n表示麻雀种群的数量,i=(1,2,
…
,n),d表示变量的维度。
[0079]
麻雀的适应度矩阵表示如下:
[0080]fx
=[f(x1),f(x2),
…
,f(xn)]
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0081]
f(xi)=[f(x
i,1
),f(x
i,2
),
…
,f(x
i,d
)]
ꢀꢀꢀꢀꢀꢀꢀ
(12)
[0082]
式中,f
x
中的每个值表示个体的适应度值。麻雀种群分为发现者、跟随者和警戒者。每次迭代中选取适应度值相对较优的一部分麻雀作为发现者,一般占种群的10%~20%,主要负责带领种群向有食物的地方前进,剩下为跟随者,而警戒者则是在整个种群中随机选取10%~20%。
[0083]
发现者的位置更新方式如下:
[0084][0085]
式中,k表示当前迭代次数;j=(1,2,
…
d);表示在第k次迭代中第i只麻雀在第j维的位置;k表示最大迭代次数;z∈(0,1]中的随机数;r2代表预警值且r2∈[0,1];st代表安全阈值且st∈[0.5,1];q代表服从正态分布的随机值;l是一个内部元素均为1的1
×d的矩阵。当r2<st时,表明预警值低于安全值,麻雀种群处于较为安全的地方,附近没有天敌,发现者可以对该区域进行广泛搜索;当r2≥st时,表明预警值超过了安全值,麻雀种群周围存在危险,整个种群需要迁移到安全的地方。
[0086]
跟随者的位置更新公式如下:
[0087][0088]
式中,x
worst
表示当前全局最差的位置;x
p
表示发现者的最佳位置;a表示内部元素均为1或-1的1
×
d的矩阵;其中a
+
=a
t
(aa
t
)-1
。当i》n/2时,表明第i个跟随者的适应度较差,需要去其他区域寻找食物。
[0089]
警戒者的位置更新公式为:
[0090][0091]
式中,x
best
表示当前的全局最佳位置;β表示麻雀运动的方位,是一个服从正态分布的随机数;m∈[-1,1]中的随机值;fi表示当前麻雀个体的适应度值;fg和fw分别表示当前的全局最优和最差适应度值。为防止(f
i-fw)+ε=0使得分母为0,则将ε定为最小常数,本文设为10e-8。当fi>fg时,表明麻雀个体当前适应度值超过了目前的最优适应度值,麻雀位置处于种群的边缘地带,容易遭遇危险;当fi=fg时,表明麻雀个体当前适应度值为目前的最优适应度值,处于种群中心位置的麻雀察觉到了危险,需要转移到其他麻雀所在的位置。
[0092]
针对麻雀搜索算法的缺陷,对ssa进行改进提出了改进的麻雀搜索算法(improved sparrow search algorithm,issa):在ssa的基础上引自适应t分布策略和动态自适应权重,避免算法陷入局部极值且提高了算法的收敛速度和收敛精度。
[0093]
(1)自适应t分布策略
[0094]
t分布是学生分布的简称,其分布函数曲线形态由参数自由度的值n决定,由函数分布图图5可以看出,当自由度n越小时,t分布曲线中间表现越低平,双尾翘得越高,整体越加平滑;当自由度n=1时,t分布为柯西分布,即t(n=1)
→
c(0,1)。当自由度n越大时,t分布曲线中间表现越高耸,整体越加陡峭;当自由度n无限大时,t分布为高斯分布,即t(n=∞)
→
n(0,1)。
[0095]
对麻雀位置利用自适应t分布进行更新如下式所示:
[0096][0097]
式中,xi为第i只麻雀个体的位置;表示经过t变异后的麻雀的位置;t(k)表示参数自由度为迭代次数k的t分布。当前麻雀种群的信息在此式中得到充分应用,当前期迭代次数k较小时,t分布类似柯西分布变异,此时的t分布算子大概率取得较大值,位置变异采取的步长较大,使得算法拥有较好的全局搜索能力;在迭代中期,t分布由柯西分布变异向高斯分布变异转变,此时的t分布算子大概率取值相对折中,使得算法同时兼顾全局和局部
搜索能力;当后期迭代次数k较大时,t分布类似高斯分布变异,此时的t分布算子大概率取得较小值,位置变异采取的步长较小,使得算法拥有较好的局部搜索能力,该策略有利于提高算法的全面搜索能力。
[0098]
(2)动态自适应权重
[0099]
从发现者的位置更新公式可以看出,在算法刚开始迭代时,发现者就向全局最优解逼近,具有较小的搜索空间,容易陷入局部极值。因此本章考虑将惯性权重的思想引入到麻雀中的发现者的位置更新公式中并对其进行改进,即在发现者位置更新方式中引入动态权重因子ω。ω的值与最大迭代次数k和当前迭代次数k有关,并且随着当前迭代次数k的增加而减少。在迭代初期,迭代次数较小时,ω的值则较大,这样便能够很好地进行全局搜索;在迭代后期,迭代次数变大时,ω值则较小,此时便可以很好地进行局部搜索。
[0100]
同时将上一代的全局最优解引入到发现者的位置更新公式中,使得上一代发现者的位置和上一代全局最优解能够同时影响当前发现者的位置,由此便不会出现算法陷入局部最优的问题。权重系数ω的计算公式和改进后的发现者位置更新方式如下所示:
[0101][0102][0103]
式中,为上一代中第j维的全局最优解;rand表示0到1之间的随机数。
[0104]
如图6所示,基于改进麻雀搜索算法优化的混合核极限学习机(issa-hkelm)的预测模型是采用改进后的麻雀搜索算法(issa)对混合核极限学习机(hkelm)的惩罚系数c,混合核参数σ、m和n以及权系数λ进行寻优,从而得到最优模型,具体步骤如下:
[0105]
1)将负荷数据划分为训练集和测试集并进行归一化处理。
[0106]
2)初始化参数,麻雀种群规模n,最大迭代次数k,安全阈值st,发现者比例pd,侦查者的比例sd,t分布变异概率p以及模型参数的优化区间等。
[0107]
3)计算适应度值,将模型对训练样本进行学习得到的预测值y'i和真实值yi的均方误差(mse)作为适应度值,mse计算公式如下。
[0108][0109]
4)计算适应度值并排序,产生最优和最差个体,以及相对应的位置,从适应度值较优的麻雀中选择部分为发现者,剩余为跟随者。
[0110]
5)根据式(13)(14)(15)分别更新跟随者,警戒者和发现者的位置,计算更新后对应的适应度值并与目前的最佳适应度值进行比较,更新全局最优信息。
[0111]
6)如果rand《p,根据式(16)对麻雀进行t分布变异操作。否则,转向步骤3。
[0112]
7)计算麻雀进行t分布变异后的适应度值,如果经过t变异操作后新解的适应度值要优于全局最优值,则用变异后的新值代替以前的全局最优值,否则保留。
[0113]
8)终止条件。若已达到最大迭代次数,则输出模型参数得到最佳hkelm模型,否则返回步骤3。
[0114]
9)用建立好的混合核极限学习机模型进行短期电力负荷预测。
[0115]
选用均方根误差(rmse)、平均绝对百分比误差(mape)、平均绝对误差(mae)和拟合度(r2)作为模型的评价指标。
[0116][0117][0118][0119][0120]
本发明所构建的短期负荷预测模型的实例分析,以某地区2012年1月1日到2015年1月17日的每天96个时刻点的历史负荷作为基础,加上影响负荷的相关因素,包括最高温度、最低温度、平均温度、相对湿度和降雨量,将多维数据分为输入输出节点,进行负荷预测。将数据分为训练数据和测试数据,训练数据为2012年1月1日到2015年1月16日的数据,测试数据为最后一天的数据。七种模型的预测结果图如图7所示,预测结果评价指标值如表1所示。
[0121]
表1
[0122] lstmdbnkelmhkelmpso-hkelmssa-hkelmissa-hkelmrmse582.932126.80212.87234.69103.2078.6861.71mae487.441695.07186.69212.9082.6264.6249.82mape7.27%26.32%2.53%2.9758%1.22%0.94%0.77%r20.955020.834820.996430.996320.996490.997460.99791
[0123]
由表1的评价指标值可以看出,本实施例提出的issa-hkelm模型预测的均方根误差(rmse)、平均绝对百分比误差(mape)和平均绝对误差(mae)相比lstm模型、dbn模型、kelm模型、hkelm模型、pso-hkelm模型和ssa-hkelm模型,均在一定程度上有所减少,其中误差指标越小,表明预测效果越好;且拟合度(r2)为最高,其中拟合度越高,表明预测结果越准确。综上所述,本实施例方法可以有效去除预测的随机性,缩小了预测值的误差,大大改善了预测的准确性,进一步证明了issa-hkelm模型在短期电力负荷预测领域具有一定的优势。
[0124]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1