单目相机下基于多模态数据集成的空中手写识别方法
本发明涉及手写识别,具体为单目相机下基于多模态数据集成的空中手写识别方法。
背景技术:
1、手势空中书写(简称空中手写)指用户通过手势在虚拟的输入区内书写文本,使计算机具有能够像人一样的认字能力,是真正自然的人机交互形式。空中手写是人机智能交互的重要输入手段,提高计算机与使用者之间的沟通与交互能力,在服务机器人、机器人视觉导航、移动终端、智能家电、智能汽车等特殊领域,提供简便的操作方式。
2、现有的空中手写识别方法中,有基于数据手套、戒指、表面肌电信号、移动终端加速度传感器的方法,但是都需要穿戴设备,大大降低了用户的体验性。有基于深度相机kinect、leap、双目视觉、多传感器的方法,虽能准确地获取手的运动和形状,但这些设备价格昂贵,增加了系统实现的成本,并不实用。基于单目视觉的空中手写可以配合带有摄像头的普通移动设备,实现无障碍式的任意场景下的自由交互,是目前手势交互的主流,也是本专利使用的数据采集方式。
3、传统的空中手写孤立词识别流程包括预处理、特征提取、分类器设计三部分。三个环节环环相扣、彼此照应。预处理的目的是消除噪声和字符归一化,预处理对识别精度的影响非常大。特征提取中,希望提取尽可能多的描述字符类内差异不变性与类间差异性的特征,如链码特征、矩特征、梯度特征、局部轮廓特征、线性偏心特征,平整度,椭圆面积特征等。分类器设计时,针对不同的特征,选取合适的分类器进行分类识别,包括动态时间规整、支持向量机、隐马尔可夫模型等。传统的方法容易被人理解,也可以实现一些简单的空中手写识别,但是通用性不强,需要大量的经验和多次尝试才能选择出较好的特征,当手势字符扩展后,模型较复杂的时候,往往识别精度下降。
4、随着大数据时代的到来和深度学习技术的兴起,如今的分类器基本上被各种巧妙设计的深度神经网络所取代;而且依靠神经网络的逐层抽取特征的强大能力,可以进行特征提取;也可以采用端到端的识别系统直接进行识别,舍去了复杂的预处理和特征提取过程。卷积神经网络在处理许多分类问题时都得到了比较好的效果。如比较经典的lenet-5,是lecun等人设计的一个基于卷积神经网络的手写字符识别系统,用于识别mnist手写图像数据集,改进后达到高达99%的识别效率。后来,针对不同手写字符的特点,研究者分析cnn的特征提取性能,并对cnn进行了改进,也加入时间序列信息,得到了较好的效果,如孪生网络、rnn、cnn+lstm、rnn+lstm。因此,采用深度学习的方法进行空中手写识别成为一种必然趋势。
5、虽然cnn在现有数据集,如mnist上表现出良好的检测性能,识别率高达99%,但是在训练数据不足时,模型会出现过拟合,导致模型性能降低。空中手写现有数据集较小,而制作大规模的数据集难度较大,费时费力。项目组自制空中手写数字孤立词数据集的大小为:3人*10数字*10样本,在训练集3*10样本,验证集3*10样本,测试集24*10样本的情况下,使用lenet-5,只可以达到84%的识别率,且只能使用图像特征。在一些文献中作者提取传统轨迹特征识别,也是没有充分利用多模态数据,在小样本上,识别率低。
6、所以需要针对上述问题设计单目相机下基于多模态数据集成的空中手写识别方法。
技术实现思路
1、本发明的目的在于提供单目相机下基于多模态数据集成的空中手写识别方法,以解决上述背景技术中提出的问题。
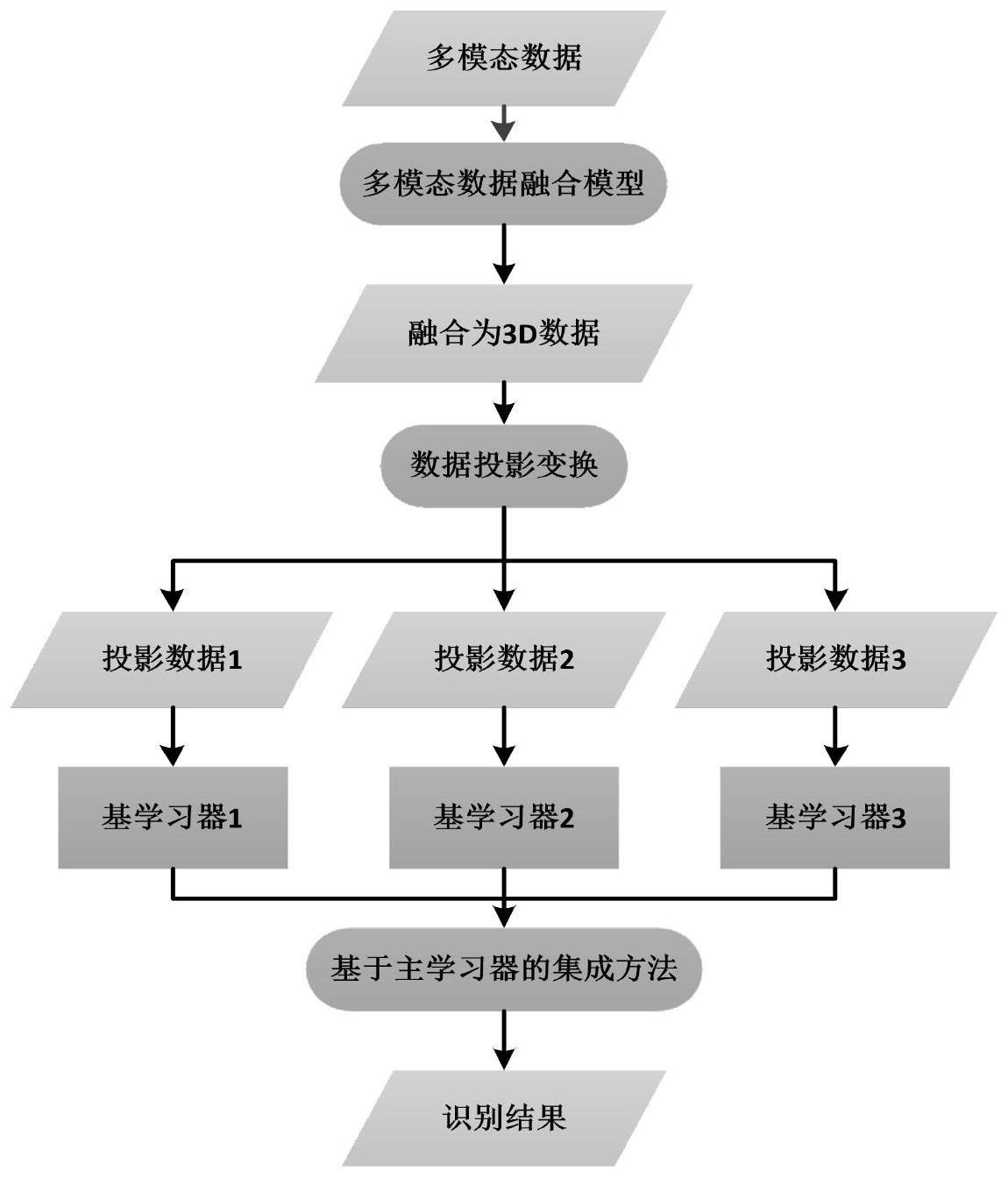
2、为实现上述目的,本发明提供如下技术方案:单目相机下基于多模态数据集成的空中手写识别方法,多模态数据包括图像数据与时序数据;多模态数据使用多模态数据融合模型进行融合,得到融合后的3d数据;对3d数据使用数据投影方法进行处理,得到3个特征投影结果,分别为投影数据1、投影数据2、投影数据3,这3个特征投影都为2d图像;对得到的3个投影特征分别进行学习,得到3个基学习器;使用基于主学习器的集成方法对3个基学习器得到的结果进行集成,获得最终的识别结果。
3、进一步的,所述单目相机下基于多模态数据集成的空中手写识别方法具体步骤为:a.多模态数据的获取;b.多模态数据融合模型;c.数据投影变换;d.学习器;e.基于主学习器的集成方法;f.识别结果。
4、进一步的,所述a.多模态数据的获取的具体步骤为:空中手写识别是基于轨迹的手势序列识别,其识别忽略了手势形状的变化信息,以手势的运动轨迹为分析数据。其数据获取的过程可以分为,首先对视频流中的手势帧进行手势预处理,包括手势分割与手势跟踪,手势跟踪可以在手势分割得到先验信息的基础上;然后根据跟踪的结果,对手势的运动轨迹进行数据提取;提取出的数据包括有手势在书写平面上的位置,这是2d的数据,还有每一帧的时间序号,这是时序特征,是1d数据。得到的图像数据与时序数据类型为获取的多模态数据。
5、进一步的,所述b.多模态数据融合模型:得到的图像数据与时序数据类型不同,为获取的多模态数据。使用多模态数据融合模型将其融合为3d数据,方法如下:原始图像数据为2d数据,原来有x,y坐标值,将其作为作为融合后3d数据的x,y坐标,将时序数据作为融合后3d数据的z坐标,这样得到了融合后的3d数据。
6、进一步的,所述c.数据投影变换:将融合后的3d数据,使用特征投影方法,分别投影到3个正交的坐标平面上,获得3个不同的数据集,其方法如下:假设融合后3d数据的3个坐标轴分别为x,y,z,对3d数据分别取在x-y平面,x-z平面,y-z平面的投影,得到的投影均为2d数据。通过将3d数据投影进行降维,得到3个相互正交的2d数据,通过这种方式进行数据变换,充分提取数据特征,来提高最终的识别效率。
7、进一步的,所述d.学习器:对得到的3个2d数据分别进行训练学习得到3个基学习器,方法如下:先将2d数据缩放到28*28尺寸,再使用相同的基学习器进行学习,采用的基学习器为8层cnn,8层网络从前往后分别为输入层28*28,16个5*5的卷积层,最大池化层,36个5*5的卷积层,最大池化层,平坦层,128个神经元的隐藏层,输出层。
8、进一步的,所述e.基于主学习器的集成方法:将得到的3个基学习器进行集成,以此获得比单一学习器显著优越的泛化性能,使用的是基于主学习器的投票方法来集成。具体方法是,因为x-y平面投影的数据为空中手写的语义内容,故将x-y平面投影的数据上学得的学习器作为主学习器,x-z平面与y-z平面投影数据上学得的学习器作为辅学习器1与辅学习器2。投票方法是,如果辅学习器1与辅学习器2的识别结果相同,则最终的识别结果为辅学习器的识别结果;如果辅学习器1与辅学习器2的识别结果不同,则最终的识别结果为主学习器的识别结果。
9、进一步的,所述f.识别结果:最终的识别结果为空中手写的语义,如数字“0-9”等。
10、与现有技术相比,本发明的有益效果是:本方法为单目相机下基于多模态数据集成的空中手写识别方法,创新性地将多模态数据进行变换,得到多个正交的同质数据集,再参与集成学习。将一维时间序列特征与二维书写轨迹图像特征融合为三维特征,然后分别对三维特征进行投影,得到3个投影平面分别作为不同的数据,学习模型识别,最后将得到的3个结果投票得到最终结果。本方法的创造性在于,通过集成学习,可以将识别率大幅度提高,实验中可以提高10%的识别效率。本方法创新性在于将时间数据与图像数据的多模态数据变换,得到多个正交的同质数据集,再参与集成学习的方法,方法简单,但是达到了较好的识别效果。本方法可以在空中手写,或者类似有时序的学习任务中应用,实用性强。
- 还没有人留言评论。精彩留言会获得点赞!