一种基于AdvGAN的对抗样本生成方法
一种基于advgan的对抗样本生成方法
技术领域
1.本发明涉及机器学习安全的技术领域,更具体地,涉及一种基于advgan的对抗样本生成方法。
背景技术:
2.深度学习作为机器学习领域的一部分,逐渐成为计算机视觉领域的研究热点。随着深度神经网络模型的不断发展,越来越多的深度学习框架和工具被开发出来。同时随着训练所需要的gpu算力等硬件的性能不断提升,训练复杂模型的成本变得越来越低,使得深度学习在各个领域都有广泛的应用。同时,由于应用的广泛,安全问题也不可忽视,常见的自动驾驶、人脸识别、物流搬运等,都是计算机视觉任务安全问题的重点关注对象。许多现在常用的神经网络结构在面对一些对抗扰动时都非常脆弱,比如googlenet、vggnet、resnet以及inception vn等。由此提出了在深度学习中的对抗攻击问题,对抗攻击的本质是通过对深度学习模型的输入样本增加微小扰动等方式,使其产生令模型辨别错误的对抗样本。但是对抗样本对人类而言是不可被观察到的,对抗样本的产生需要满足一个重要的标准,就是被干扰的样本应该在人眼中与原始样本无异,但是输入模型后会使模型输出一个非正确的结果,甚至是指定的错误结果。
3.随着2014年的一篇论文《intriguing properties of neural networks》发表,对抗攻击正式成为了深度学习安全中的一个研究领域。对于该领域的研究,集中在对现有的深度学习模型提出对抗攻击方法以证明模型所存在的安全问题,以及针对安全问题所提出的增强模型鲁棒性的对抗训练上。如何对深度学习模型进行有效的攻击,是分析深度学习模型安全性、提高模型鲁棒性的重要方法。传统的攻击方法聚焦在给原始图像添加扰动的,常用的方法包括单步计算或者迭代计算,如快速梯度符号法(fgsm)、迭代快速梯度符号法(i-fgsm),以及无穷范式约束等。通过这些方法对原始图像进行像素级别的扰动,进而生成对抗样本。传统的攻击方法有生成样本速度慢、计算量大的缺点,并且大多数是白盒攻击,生成样本的过程需要获取目标模型的结构信息、参数内容等,导致适用性比较单一。因此较新的对抗攻击的方向转向使用神经网络,尤其是使用生成对抗网络进行对抗样本的生成。但是同时也存在生成的对抗样本质量不高、添加的扰动能够人为识别、生成对抗样本成功率不高、攻击的迁移性低的问题。
4.现有技术公开了一种对抗样本生成方法、装置、设备及介质,包括:利用黑盒模型的训练数据集对多个不同初始模型进行训练,得到所述黑盒模型的多个不同替代模型;利用多个所述替代模型分别生成每个原始样本对应的对抗样本;基于每个所述原始样本对应的利用多个所述替代模型生成的多个所述对抗样本,确定所述原始样本对应的最终对抗样本。该申请利用了多个不同的替代模型,无法保证对抗样本的质量。
技术实现要素:
5.本发明为克服上述现有技术生成的对抗样本质量低的所述的缺陷,提供一种基于
advgan的对抗样本生成方法,能够生成高质量的对抗样本,降低人眼的感知程度,提高生成对抗样本的成功率。
6.为解决上述技术问题,本发明的技术方案如下:
7.本发明提供了一种基于advgan的对抗样本生成方法,包括:
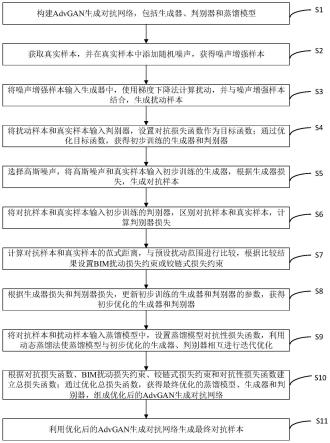
8.s1:构建advgan生成对抗网络,包括生成器、判别器和蒸馏模型;
9.s2:获取真实样本,并在真实样本中添加随机噪声,获得噪声增强样本;
10.s3:将噪声增强样本输入生成器中,使用梯度下降法计算扰动,并与噪声增强样本结合,生成扰动样本;
11.s4:将扰动样本和真实样本输入判别器,设置对抗损失函数作为目标函数;通过优化目标函数,获得初步训练的生成器和判别器;
12.s5:选择高斯噪声,将高斯噪声和真实样本输入初步训练的生成器,根据生成器损失,生成对抗样本;
13.s6:将对抗样本和真实样本输入初步训练的判别器,区别对抗样本和真实样本,计算判别器损失;
14.s7:计算对抗样本和真实样本的范式距离,与预设扰动范围进行比较,根据比较结果设置bim扰动损失约束或铰链式损失约束;
15.s8:根据生成器损失和判别器损失,更新初步训练的生成器和判别器的参数,获得初步优化的生成器和判别器;
16.s9:将对抗样本和扰动样本输入蒸馏模型中,设置蒸馏模型对抗性损失函数,利用动态蒸馏法使蒸馏模型与初步优化的生成器、判别器相互进行迭代优化;
17.s10:根据对抗损失函数、bim扰动损失约束、铰链式损失约束和对抗性损失函数建立总损失函数;通过优化总损失函数,获得最终优化的蒸馏模型、生成器和判别器,组成优化后的advgan生成对抗网络;
18.s11:利用优化后的advgan生成对抗网络生成最终对抗样本。
19.优选地,所述步骤s2的具体方法为:
20.s2.1:获取真实样本x∈x,真实样本的噪声分布为n(0,∑
*
);其中,x表示真实样本数据集,∑
*
表示噪声矩阵;
21.s2.2:对每个真实样本x选择随机噪声n∈n,添加噪声约束和离散度约束,生成噪声增强样本x
′
,获得噪声增强数据集x
′
;
22.所述噪声约束为:
[0023][0024]
所述离散度约束为:
[0025][0026]
式中,x
enc,n
(x,x
′
)表示真实样本x与噪声增强样本x
′
间的噪声约束,fw(*)表示特征提取操作,argmin表示求取||f
w+n
(x)-fw(x
′
)||2最小值时,x
′
的取值函数;||*||2表示求取l2范数操作;kl(p
x
′
(x
′
)||q
x
(x))表示真实样本x与噪声增强样本x
′
间的kl离散度,p(x
′
)表示噪声增强样本x
′
的概率密度函数,q(x)表示真实样本x的概率密度函数。
[0027]
使用kl离散度判断真实样本与噪声增强样本的数据分布差别,使噪声增强样本的
数据分布不会与原始的真实样本的数据分布相差太大,在数据特征上保持一致。
[0028]
优选地,所述步骤s3的具体方法为:
[0029]
随机选取噪声增强样本x
′
输入到生成器g中,在保持噪声增强样本数据特征的前提下,使用梯度下降法迭代计算扰动δ
adv
:
[0030][0031][0032][0033][0034]
式中,gc表示梯度符号,表示第t次迭代的预期扰动,w表示梯度参数,y表示特征标签,表示第t次迭代的梯度动量;表示第t+1次迭代的梯度动量,μ表示衰减因子,a表示符号系数,[-ε,ε]表示预设扰动范围,表示第t+1次迭代的预期扰动;表示第t+1次迭代的扰动;
[0035]
当和的差值在预设扰动范围内时,将作为扰动δ
adv
;将扰动δ
adv
与噪声增强样本x
′
结合,生成扰动样本
[0036]
优选地,所述步骤s3中,生成扰动样本后,还需对扰动样本进行筛选,具体方法为:
[0037]
计算扰动样本与真实样本x的l2范式距离:
[0038][0039]
式中,l
p
表示扰动样本与真实样本的l2范式距离;
[0040]
设定扰动阈值∈,若l
p
》|∈|,则丢弃该扰动样本。
[0041]
优选地,所述步骤s4中,对抗损失函数为:
[0042][0043]
式中,l
gan
表示对抗损失函数,f
l
(*)表示满足1-lipschitz连续的函数,即
[0044]
优选地,所述步骤s5的具体方法为:
[0045]
随机选择m个真实样本x,选定高斯噪声η,将真实样本和高斯噪声输入初步训练的生成器,初始化初步训练的生成器的参数,生成对抗样本x
adv
,并计算生成器损失:
[0046][0047]
式中,表示生成器损失,g(*)表示初步训练的生成器,d(*)表示初步训练的判别器,n
′
表示高斯噪声分布。
[0048]
优选地,所述步骤s6中,判别器损失为:
[0049][0050]
式中,表示判别器损失,g(*)表示初步训练的生成器,d(*)表示初步训练的判别器,n
′
表示高斯噪声分布。
[0051]
优选地,所述步骤s7的具体方法为:
[0052]
计算对抗样本x
adv
与真实样本x的l2范式距离:
[0053][0054]
式中,表示对抗样本与真实样本的l2范式距离;
[0055]
将与设定的扰动阈值∈进行比较,若则设置bim扰动损失约束:
[0056][0057]
式中,lb表示bim扰动损失;m表示随机选择的真实样本数量,k表示对抗样本的数量,σ表示第一超参数;
[0058]
若则设置铰链式损失约束:
[0059]
l
hinge
=e
x
max(0,||g(x)||
2-c)
[0060]
式中,l
hinge
表示铰链式损失,c表示上限值。
[0061]
优选地,所述步骤s9的具体方法为:
[0062]
s9.1:将对抗样本和扰动样本输入蒸馏模型中;
[0063]
s9.2:设置以黑盒模型为目标模型的蒸馏模型f,设定目标攻击类别t或不设定攻击类别,蒸馏模型f的对抗性损失函数为:
[0064][0065]
式中,表示蒸馏模型f的对抗性损失,lf表示第一交叉熵损失;
[0066]
s9.3:利用第i-1次迭代的蒸馏模型f
i-1
更新第i次迭代的初步训练的生成器gi和初步训练的判别器di;更新方法为:
[0067][0068]
式中,表示第i-1次迭代的蒸馏模型的对抗性损失;τ,表示第二、第三超参数;
[0069]
s9.4:利用第i次迭代的初步训练的生成器gi反馈更新第i次迭代的蒸馏模型fi;更新方法为:
[0070][0071]
式中,表示第二交叉熵损失,f(x
adv
)表示蒸馏模型对对抗样本x
adv
的输出,表示蒸馏模型对扰动样本的输出,b(x
adv
)表示对抗样本x
adv
从黑盒模型的查询结果,表示扰动样本从黑盒模型的查询结果。
[0072]
优选地,所述总损失函数为:
[0073][0074]
式中,α,β,γ表示第一、第二、第三比例系数。
[0075]
与现有技术相比,本发明技术方案的有益效果是:
[0076]
本发明首先在真实样本中添加随机噪声,获得噪声增强样本;将噪声增强样本输入生成器中,生成扰动样本;设置对抗损失函数,利用判别器区别扰动样本和真实样本,使
初步训练的生成器和判别器学习到真实样本和扰动的分布特征;之后在真实样本中添加高斯噪声,输入初步训练的生成器中,生成对抗样本;利用初步训练的判别器区别对抗样本和真实样本,根据对抗样本和真实样本差值设置bim扰动损失约束或铰链式损失约束,限制对抗样本的扰动大小,在不影响攻击效果的前提下提高对抗样本的质量,降低人类对其的感知程度,获得初步优化的生成器和判别器;最后,设置蒸馏模型与初步优化的生成器和判别器相互迭代优化,使初步优化的生成器和判别器更好的学习到对抗样本的分布特征,蒸馏模型更贴近目标黑盒模型;通过优化总损失函数,获得优化后的advgan生成对抗网络,利用其生成指定目标攻击类别或无目标攻击类别的最终对抗样本。本发明提升了对抗样本生成速度,提高了生成对抗样本的质量;降低了对抗样本的分布特征与真实样本的分布特征的差异,增加了人为识别难度同时,提高了攻击成功率。
附图说明
[0077]
图1为实施例1所述的一种基于advgan的对抗样本生成方法的流程图。
[0078]
图2为实施例2所述的advgan生成对抗网络的结构示意图。
[0079]
图3为实施例2所述的生成器g的结构示意图。
[0080]
图4为实施例2所述的判别器d的结构示意图。
具体实施方式
[0081]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0082]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
[0083]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0084]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0085]
实施例1
[0086]
本实施例提供了一种基于advgan的对抗样本生成方法,如图1所示,包括:
[0087]
s1:构建advgan生成对抗网络,包括生成器、判别器和蒸馏模型;
[0088]
s2:获取真实样本,并在真实样本中添加随机噪声,获得噪声增强样本;
[0089]
s3:将噪声增强样本输入生成器中,使用梯度下降法计算扰动,并与噪声增强样本结合,生成扰动样本;
[0090]
s4:将扰动样本和真实样本输入判别器,设置对抗损失函数作为目标函数;通过优化目标函数,获得初步训练的生成器和判别器;
[0091]
s5:选择高斯噪声,将高斯噪声和真实样本输入初步训练的生成器,根据生成器损失,生成对抗样本;
[0092]
s6:将对抗样本和真实样本输入初步训练的判别器,区别对抗样本和真实样本,计算判别器损失;
[0093]
s7:计算对抗样本和真实样本的范式距离,与预设扰动范围进行比较,根据比较结果设置bim扰动损失约束或铰链式损失约束;
[0094]
s8:根据生成器损失和判别器损失,更新初步训练的生成器和判别器的参数,获得
初步优化的生成器和判别器;
[0095]
s9:将对抗样本和扰动样本输入蒸馏模型中,设置蒸馏模型对抗性损失函数,利用动态蒸馏法使蒸馏模型与初步优化的生成器、判别器相互进行迭代优化;
[0096]
s10:根据对抗损失函数、bim扰动损失约束、铰链式损失约束和对抗性损失函数建立总损失函数;通过优化总损失函数,获得最终优化的蒸馏模型、生成器和判别器,组成优化后的advgan生成对抗网络;
[0097]
s11:利用优化后的advgan生成对抗网络生成最终对抗样本。
[0098]
在具体实施过程中,本实施例首先在真实样本中添加随机噪声,获得噪声增强样本;将噪声增强样本输入生成器中,生成扰动样本;设置对抗损失函数,利用判别器区别扰动样本和真实样本,使初步训练的生成器和判别器学习到真实样本和扰动的分布特征;之后在真实样本中添加高斯噪声,输入初步训练的生成器中,生成对抗样本;利用初步训练的判别器区别对抗样本和真实样本,根据对抗样本和真实样本差值设置bim扰动损失约束或铰链式损失约束,限制对抗样本的扰动大小,获得初步优化的生成器和判别器;最后,设置蒸馏模型与初步优化的生成器和判别器相互迭代优化,使初步优化的生成器和判别器更好的学习到对抗样本的分布特征,蒸馏模型更贴近目标黑盒模型;通过优化总损失函数,获得优化后的advgan生成对抗网络,利用其生成指定目标攻击类别或无目标攻击类别的最终对抗样本。本发明提升了对抗样本生成速度,提高了生成对抗样本的质量;降低了对抗样本的分布特征与真实样本的分布特征的差异,增加了人为识别难度同时,提高了攻击成功率。
[0099]
实施例2
[0100]
本实施例提供了一种基于advgan的对抗样本生成方法,如图2所示,包括:
[0101]
s1:构建advgan生成对抗网络,包括生成器、判别器和蒸馏模型;
[0102]
s2:获取真实样本,并在真实样本中添加随机噪声,获得噪声增强样本;具体方法为:
[0103]
s2.1:获取真实样本x∈x,真实样本的噪声分布为n(0,∑
*
);其中,x表示真实样本数据集,∑
*
表示噪声矩阵;
[0104]
s2.2:对每个真实样本x选择随机噪声n∈n,添加噪声约束和离散度约束,生成噪声增强样本x
′
,获得噪声增强数据集x
′
;
[0105]
所述噪声约束为:
[0106][0107]
所述离散度约束为:
[0108][0109]
式中,x
enc,n
(x,x
′
)表示真实样本x与噪声增强样本x
′
间的噪声约束,fw(*)表示特征提取操作,argmin表示求取||f
w+n
(x)-fw(x
′
)||2最小值时,x
′
的取值函数;||*||2表示求取l2范数操作;kl(p
x
′
(x
′
)||q
x
(x))表示真实样本x与噪声增强样本x
′
间的kl离散度,p(x
′
)表示噪声增强样本x
′
的概率密度函数,q(x)表示真实样本x的概率密度函数。
[0110]
使用kl离散度判断真实样本与噪声增强样本的数据分布差别,使噪声增强样本的数据分布不会与原始的真实样本的数据分布相差太大,在数据特征上保持一致。
[0111]
s3:将噪声增强样本输入生成器中,使用梯度下降法计算扰动,并与噪声增强样本
结合,生成扰动样本;具体方法为:
[0112]
如图3所示,为生成器g的结构示意图,生成器g包括依次连接的第一卷积层、第二卷积层、第三卷积层、第一残差块、第二残差块、第三残差块、第四残差块、第四卷积层、第五卷积层和第六卷积层,第一到第六卷积层的激活函数均为relu函数;随机选取噪声增强样本x
′
输入到生成器g中,在保持噪声增强样本数据特征的前提下,使用梯度下降法迭代计算扰动δ
adv
:
[0113][0114][0115][0116][0117]
式中,gc表示梯度符号,表示第t次迭代的预期扰动,w表示梯度参数,y表示特征标签,表示第t次迭代的梯度动量;表示第t+1次迭代的梯度动量,μ表示衰减因子,a表示符号系数,[-ε,ε]表示预设扰动范围,表示第t+1次迭代的预期扰动;表示第t+1次迭代的扰动;
[0118]
当和的差值在预设扰动范围内时,将作为扰动δ
adv
;将扰动δ
adv
与噪声增强样本x
′
结合,生成扰动样本
[0119]
生成扰动样本后,还需对扰动样本进行筛选:
[0120]
计算扰动样本与真实样本x的l2范式距离:
[0121][0122]
式中,l
p
表示扰动样本与真实样本的l2范式距离;
[0123]
设定扰动阈值∈,若l
p
》|∈|,则丢弃该扰动样本。
[0124]
s4:将扰动样本和真实样本输入判别器,设置对抗损失函数作为目标函数;通过优化目标函数,获得初步训练的生成器和判别器;所述对抗损失函数为:
[0125][0126]
式中,l
gan
表示对抗损失函数,f
l
(*)表示满足1-lipschitz连续的函数,即
[0127]
如图4所示,为判别器d的结构示意图;判别器包括依次连接的第七卷积层、第八卷积层、第九卷积层和全连接层;第七至第九卷积层的激活函数为leakyrelu函数,全连接层的激活函数为softmax函数。
[0128]
s5:选择高斯噪声,将高斯噪声和真实样本输入初步训练的生成器,根据生成器损失,生成对抗样本;具体方法为:
[0129]
随机选择m个真实样本x,选定高斯噪声η,将真实样本和高斯噪声输入初步训练的生成器,初始化初步训练的生成器的参数,生成对抗样本x
adv
,并计算生成器损失:
[0130][0131]
式中,表示生成器损失,g(*)表示初步训练的生成器,d(*)表示初步训练的判别
器,n
′
表示高斯噪声分布。
[0132]
s6:将对抗样本和真实样本输入初步训练的判别器,区别对抗样本和真实样本,计算判别器损失;所述判别器损失为:
[0133][0134]
式中,表示判别器损失,g(*)表示初步训练的生成器,d(*)表示初步训练的判别器,n
′
表示高斯噪声分布。
[0135]
s7:计算对抗样本和真实样本的范式距离,与预设扰动范围进行比较,根据比较结果设置bim扰动损失约束或铰链式损失约束;具体方法为:
[0136]
计算对抗样本x
adv
与真实样本x的l2范式距离:
[0137][0138]
式中,表示对抗样本与真实样本的l2范式距离;
[0139]
将与设定的扰动阈值∈进行比较,若则设置bim扰动损失约束:
[0140][0141]
式中,lb表示bim扰动损失;m表示随机选择的真实样本数量,k表示对抗样本的数量,σ表示第一超参数;
[0142]
若则设置铰链式损失约束:
[0143]
l
hinge
=e
x
max(0,||g(x)||
2-c)
[0144]
式中,l
hinge
表示铰链式损失,c表示上限值。
[0145]
s8:根据生成器损失和判别器损失,更新初步训练的生成器和判别器的参数,获得初步优化的生成器和判别器;
[0146]
s9:将对抗样本和扰动样本输入蒸馏模型中,设置蒸馏模型对抗性损失函数,利用动态蒸馏法使蒸馏模型与初步优化的生成器、判别器相互进行迭代优化;具体方法为:
[0147]
s9.1:将对抗样本和扰动样本输入蒸馏模型中;
[0148]
s9.2:设置以黑盒模型为目标模型的蒸馏模型f,设定目标攻击类别t或不设定攻击类别,蒸馏模型f的对抗性损失函数为:
[0149][0150]
式中,表示蒸馏模型f的对抗性损失,lf表示第一交叉熵损失;
[0151]
s9.3:利用第i-1次迭代的蒸馏模型f
i-1
更新第i次迭代的初步训练的生成器gi和初步训练的判别器di;更新方法为:
[0152][0153]
式中,表示第i-1次迭代的蒸馏模型的对抗性损失;τ,表示第二、第三超参数;
[0154]
s9.4:利用第i次迭代的初步训练的生成器gi反馈更新第i次迭代的蒸馏模型fi;更新方法为:
[0155][0156]
式中,表示第二交叉熵损失,f(x
adv
)表示蒸馏模型对对抗样本x
adv
的输出,表示蒸馏模型对扰动样本的输出,b(x
adv
)表示对抗样本x
adv
从黑盒模型的查询结果,表示扰动样本从黑盒模型的查询结果。
[0157]
s10:根据对抗损失函数、bim扰动损失约束、铰链式损失约束和对抗性损失函数建立总损失函数;通过优化总损失函数,获得最终优化的蒸馏模型、生成器和判别器,组成优化后的advgan生成对抗网络;所述总损失函数为:
[0158][0159]
式中,α,β,γ表示第一、第二、第三比例系数。
[0160]
s11:利用优化后的advgan生成对抗网络生成最终对抗样本。
[0161]
本实施例使用前馈的生成对抗网络,每经过一次训练,多次生成对抗样本;提高了生成对抗样本的速度,减少了计算时间;通过蒸馏模型反馈优化生成器,使得生成器最终学习到与真实样本相近的对抗样本的分布,通过输入真实样本直接生成扰动,使其组合成有攻击目标的对抗样本,提高了在以黑盒模型为目标的攻击中的成功率;通过设置bim扰动损失约束和铰链式损失约束来约束扰动的生成,在不影响攻击效果的前提下提高对抗样本的质量,降低人类对其的感知程度。
[0162]
实施例3
[0163]
本实施例提供一种基于advgan的对抗样本生成方法,基于构建advgan生成对抗网络,设置了两个阶段的训练过程,包括正常训练阶段和对抗训练阶段;advgan生成对抗网络包括生成器、判别器和蒸馏模型;
[0164]
正常训练阶段,训练生成器和判别器学习到真实样本的数据分布;使用公开数据集mnist作为真实样本数据集x,真实样本x∈x,真实样本的噪声分布为n(0,∑
*
),将真实样本输入特征提取器fw中提取分布特征,正常训练阶段包括以下步骤:
[0165]
1)选择真实样本数据集x中的真实样本x,从噪声分布n中选择随机噪声n,n∈n,其中∑
*
=β1f-1
(w)表示噪声矩阵;
[0166]
2)对每个真实样本x选择随机噪声n,直到整个真实样本数据集x都被注入随机造成,生成噪声增强样本x
′
;通过添加噪声约束:
[0167][0168]
式中,x
enc,n
(x,x
′
)表示真实样本x与噪声增强样本x
′
间的噪声约束,fw(*)表示特征提取操作,argmin表示求取||f
w+n
(x)-fw(x
′
)||2最小值时,x
′
的取值函数;||*||2表示求取l2范数操作;
[0169]
3)使用kl离散度判断真实样本和噪声增强样本的数据分布的差别,使噪声增强样本的数据分布与真实样本的噪声分布不能相差太大,即数据特征保持一致:
[0170][0171]
式中,l(p
x
′
(x
′
)||q
x
(x))表示真实样本x与噪声增强样本x
′
间的kl离散度,p(x
′
)表示噪声增强样本x
′
的概率密度函数,q(x)表示真实样本x的概率密度函数;
[0172]
4)初始化梯度参数w0,预期扰动随机初始化扰动δ0;
[0173]
5)从噪声增强数据集x
′
中随机选取噪声增强样本x
′
输入到生成器g中,在保持数据特征的前提下使用梯度下降法迭代,生成扰动δ
adv
:
[0174][0175][0176][0177][0178]
式中,gc表示梯度符号,表示第t次迭代的预期扰动,w表示梯度参数,y表示特征标签,表示第t次迭代的梯度动量;表示第t+1次迭代的梯度动量,μ表示衰减因子,a表示符号系数,[-ε,ε]表示预设扰动范围,表示第t+1次迭代的预期扰动;表示第t+1次迭代的扰动;
[0179]
当和的差值在预设扰动范围内时,将作为扰动δ
adv
;
[0180]
6)将扰动δ
adv
与噪声增强样本x
′
结合,生成扰动样本
[0181]
7)计算梯度惩罚项,以避免网络出现梯度爆炸现象:
[0182][0183]
8)使用正则化更新权重参数:
[0184][0185]
9)计算扰动样本与真实样本x的l2范式距离,用于断扰动是否超过范围:
[0186][0187]
式中,l
p
表示扰动样本与真实样本的l2范式距离;
[0188]
设定扰动阈值∈,若l
p
》|∈|,则丢弃该扰动样本。
[0189]
10)设置对抗损失函数:
[0190][0191]
式中,l
gan
表示对抗损失函数,f
l
(*)表示满足1-lipschitz连续的函数,即
[0192]
每轮训练完之后更新生成器g和判别器d的参数,获得学习到真实样本和扰动范围分布的初步训练的生成器和判别器,正常训练阶段结束。
[0193]
对抗训练阶段包括以下步骤:
[0194]
1)从真实样本数据集x中随机选择m个真实样本x,选择高斯噪声η∈n
′
(0,ε);
[0195]
2)使用初步训练的生成器g和判别器d作为初始化,并且初始化θg为生成器的参数,θd为鉴别器参数,初始化αg,αd为分别为生成器和鉴别器的学习率,权重参数w;
[0196]
3)将真实样本和高斯噪声输入初步训练的生成器,生成对抗样本x
adv
;
[0197]
4)将对抗样本x
adv
和真实样本输入到判别器d中,使判别器d区分对抗样本x
adv
和真实样本x的区别。计算判别器的损失
[0198][0199]
式中,表示判别器损失,g(*)表示初步训练的生成器,d(*)表示初步训练的判别器,n
′
表示高斯噪声分布。
[0200]
5)同时计算生成器的损失:
[0201][0202]
式中,表示生成器损失,g(*)表示初步训练的生成器,d(*)表示初步训练的判别器,n
′
表示高斯噪声分布。
[0203]
6)计算鉴别器和生成器的参数θd和θg,用于优化生成器和鉴别器:
[0204][0205][0206]
7)更新权重参数:
[0207]w←
w+α*adam(w,θd,θg)
[0208]
8)计算对抗样本x
adv
与真实样本x的l2范式距离:
[0209][0210]
式中,表示对抗样本与真实样本的l2范式距离。
[0211]
9)设定扰动阈值∈,若说明扰动过小,则设置bim扰动损失约束:
[0212][0213]
式中,lb表示bim扰动损失;m表示随机选择的真实样本数量,k表示对抗样本的数量,σ表示第一超参数;
[0214]
若说明扰动过大,则设置铰链式损失约束:
[0215]
l
hinge
=e
x
max(0,||g(x)||
2-c)
[0216]
式中,l
hinge
表示铰链式损失,c表示上限值。
[0217]
10)将对抗样本和扰动样本输入蒸馏模型中,蒸馏模型f的对抗性损失函数为:
[0218][0219]
式中,表示蒸馏模型f的对抗性损失,lf表示第一交叉熵损失;
[0220]
使用动态蒸馏的方法优化生成器和判别器,同时也使得蒸馏模型更加贴近目标黑盒模型,使得蒸馏模型生成的对抗样本更加贴近攻击目标类别,或针对于目标模型的黑盒无类别攻击的对抗样本,具体的:
[0221]
a)设定目标攻击类别t或不设定攻击类别;
[0222]
b)利用第i-1次迭代的蒸馏模型f
i-1
更新第i次迭代的初步训练的生成器gi和初步训练的判别器di;首先把生成器gi的初始权重设置为与前一步的g
i-1
相同,之后通过对应的
第i-1次迭代的蒸馏模型f
i-1
的参数来更新第i轮迭代的生成器和判别器,更新方法为:
[0223][0224]
式中,表示第i-1次迭代的蒸馏模型的对抗性损失;τ,表示第二、第三超参数;本实施例中,τ,分别设定为0.5;
[0225]
c)用第i次迭代的初步训练的生成器gi反馈更新第i次迭代的蒸馏模型fi;首先使用蒸馏模型f
i-1
去初始化fi,再通过给定生成器gi中生成的使用生成的对抗样本对黑盒模型的查询结果集以及对原始样本中提取的特征一同更新蒸馏模型fi,更新方法为:
[0226][0227]
式中,表示第二交叉熵损失,f(x
adv
)表示蒸馏模型对对抗样本x
adv
的输出,表示蒸馏模型对扰动样本的输出,b(x
adv
)表示对抗样本x
adv
从黑盒模型的查询结果,表示扰动样本从黑盒模型的查询结果。
[0228]
d)通过给定攻击目标的真实样本进行优化,得到一个非常靠近黑盒模型b的蒸馏模型f,生成的最终对抗样本就能够有效的攻击黑盒模型;
[0229]
11)设置总损失函数为:
[0230][0231]
式中,α,β,γ表示第一、第二、第三比例系数。α+β+γ=1,本实施例中,分别设置为0.3,0.3,0.4.
[0232]
重复上述步骤,对总损失函数进行优化,获得最终优化的蒸馏模型、生成器和判别器,组成优化后的advgan生成对抗网络。
[0233]
12)利用优化后的advgan生成对抗网络生成最终对抗样本。
[0234]
本实施例提出了一种基于advgan的对抗样本生成方法,通过蒸馏模型与生成器,判别器的相呼应优化,分两个阶段训练,更能有效的提取到图片的特征,生成目标类别的对抗样本时能够保留图片的主要特征,生成具有更高质量,更符合人类视觉的对抗样本。
[0235]
相同或相似的标号对应相同或相似的部件;
[0236]
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
[0237]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1