一种神经网络标题生成模型
1.本发明涉及自然语言处理技术领域,更具体而言,涉及一种神经网络标题生成模型。
背景技术:
2.随着深度学习技术在自然语言处理领域的快速发展,端到端神经网络标题生成也进入到了全新的发展阶段。通过一个巨大的神经网络,端到端的神经网络标题生成系统在输入文章和标题之间进行映射,无需额外的语言学知识和更多的人工标注,为一篇文档逐字生成对应的标题。
3.尽管取得了显著的成功,神经网络标题生成模型仍面临着一些问题,如丢失重要信息和生成重复或额外的单词。因此,如何帮助神网络标题生成系统规避上述问题引起了广泛关注。
技术实现要素:
4.为了解决上述技术问题,本发明提供一种神经网络标题生成模型,本发明可以在不需要任何训练数据的前提下,保证摘要的简洁性和连贯性。
5.为解决上述技术问题,本发明采用的技术方案为:
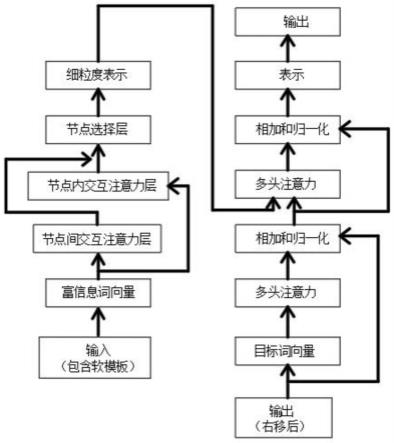
6.一种神经网络标题生成模型,包括:
7.富信息词向量层;
8.节点间交互注意力层;
9.节点内交互注意力层;
10.节点选择层;
11.解码层;
12.端到端的训练。
13.优选的,所述富信息词向量层的构建方法包括:
14.s1:选定一篇包含m个词的新闻文档x=(x1,
…
,xi,
…
,xm)、与所述文档相对应的包含n个词的标题y=(y1,
…
,yj,
…
,yn)和k个由基础神经网络标题生成模型采样生成的相应模板z=[z1,
…
,zk,
…
,zk],其中第k个模板包含个词;
[0015]
s2:将文档和每个模板组成对,将文档模板对《x,zk》视作一个节点;
[0016]
s3:采用预训练的语言模型来获得所有节点中每个词对应的词表示;
[0017]
s4:获得的富信息词向量hk,通过公式(1)计算:
[0018][0019]
其中和分别表示“[cls]”和“[sep]”。
[0020]
预训练的语言模型具备在各种自然语言处理任务上,有效生成富含语义和句法信
息的上下文相关的词表示的能力。
[0021]
优选的,所述节点间交互注意力层的构建方法包括:
[0022]
首先计算与第p个节点中的第j个词的初始表示相关的交互注意力权重通过公式(2)计算:
[0023][0024]
其中w
inter
代表权重矩阵;
[0025]
则第k个节点中的第i个词的表示聚合了来自第p个节点的信息,通过公式(3)计算:
[0026][0027]
根据上述公式,进一步构建第k节点与第p节点相关的向量表示,通过公式(4)计算:
[0028][0029]
使用不同的模板构建的不同节点包含独特的信息,不同节点之间的语义交互将帮助模型更好地捕获重要信息。完全连接的节点间交互注意层旨在实现该思想。
[0030]
优选的,所述节点选择层的构建方法包括:
[0031]
s1:计算文档-模板匹配矩阵mk,表明第k个节点中源文档和模板间的匹配度,对于mk中的每个元素使用第i个源文档词和第j个模板词的富信息词向量进行计算,通过公式(5)计算:
[0032][0033]
其中w
intra
表示权重矩阵;
[0034]
s2:获取源文档词与模板词相关的注意力分数模板词与源文档词相关的注意力分数分别通过公式(6)和(7):
[0035][0036][0037]
s3:源文章和软模板的相关向量分别通过公式(8)和公式(9)计算:
[0038][0039]
[0040]
优选的,节点选择层旨在控制第k个节点的最终细粒度节点表示gk中g
p
→k的比例,通过公式(10)计算:
[0041][0042]
其中表示元素乘法,;表示级联操作,给定节点选择注意力分数γk,第k个节点的第i个词的最终细粒度通过公式(11)计算:
[0043][0044]
根据上述公式,第k个节点通过公式(12)计算:
[0045][0046]
优选的,选择transformer解码器来逐字解码输出标题,解码输出标题中第j个词的条件概率通过公式(13)计算:
[0047][0048]
其中来自目标端表示矩阵l表示解码器层数,ffn(
·
)代表前馈神经网络;
[0049]
通过公式(14)定义:
[0050][0051]
其中ln(
·
)表示层归一化操作;
[0052]
通过公式(15)计算:
[0053][0054]
本发明与现有技术相比,具有的有益效果是:
[0055]
本发明可以在不需要任何训练数据的前提下,保证摘要的简洁性和连贯性。然而,手动创建所有模板是不现实的,因为这项工作不仅需要密集劳动,还需要大量的领域知识。在深度学习背景下,改进的基于模板的标题生成方法,将一些训练集合中特定文章的摘要作为模板为摘要提供类似的指导。这种方法虽然避免了手动创建模板的问题,但是检索特定文章的过程,需要精细的设计。检索模块用到了一个信息检索标准库apache lucene,调用这个库本身需要一定的背景知识。接着,为了根据一篇文章进行检索,还需要剔除文章中一些特定信息,如日期、导语等,以消除它们对文章匹配的影响。然后,根据已清洗过的文章,通过检索系统检索出一小部分候选文档,从训练集中查找其对应的标题作为软模板。本发明创造性地提出将基础神经网络模型所生成的采样结果当做软模板,辅助神经网络标题生成的建模。采用本文进行的改进,可以避免调用额外的信息检索库,以及人工设计数据清洗规则。
附图说明
[0056]
图1为本发明的流程图。
具体实施方式
[0057]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0058]
如图1所示,一种神经网络标题生成模型,包括:
[0059]
富信息词向量层;
[0060]
节点间交互注意力层;
[0061]
节点内交互注意力层;
[0062]
节点选择层;
[0063]
解码层;
[0064]
端到端的训练。
[0065]
富信息词向量层的构建方法包括:
[0066]
s1:选定一篇包含m个词的新闻文档x=(x1,
…
,xi,
…
,xm)、与文档相对应的包含n个词的标题y=(y1,
…
,yj,
…
,yn)和k个由基础神经网络标题生成模型采样生成的相应模板z=[z1,
…
,zk,
…
,zk],其中第k个模板包含个词;
[0067]
s2:将文档和每个模板组成对,将文档模板对《x,zk》视作一个节点;
[0068]
s3:采用预训练的语言模型来获得所有节点中每个词对应的词表示;
[0069]
s4:获得的富信息词向量hk,通过公式(1)计算:
[0070][0071]
其中和分别表示“[cls]”和“[sep]”。
[0072]
节点间交互注意力层的构建方法包括:
[0073]
首先计算与第p个节点中的第j个词的初始表示相关的交互注意力权重通过公式(2)计算:
[0074][0075]
其中w
inter
代表权重矩阵;
[0076]
则第k个节点中的第i个词的表示聚合了来自第p个节点的信息,通过公式(3)计算:
[0077][0078]
根据上述公式,进一步构建第k节点与第p节点相关的向量表示,通过公式(4)计算:
[0079][0080]
s1:计算文档-模板匹配矩阵mk,表明第k个节点中源文档和模板间的匹配度,对于
mk中的每个元素使用第i个源文档词和第j个模板词的富信息词向量进行计算,通过公式(5)计算:
[0081][0082]
其中w
intra
表示权重矩阵;
[0083]
s2:获取源文档词与模板词相关的注意力分数模板词与源文档词相关的注意力分数分别通过公式(6)和(7):
[0084][0085][0086]
s3:源文章和软模板的相关向量分别通过公式(8)和公式(9)计算:
[0087][0088][0089]
节点选择层旨在控制第k个节点的最终细粒度节点表示gk中g
p
→k的比例,通过公式(10)计算:
[0090][0091]
其中表示元素乘法,;表示级联操作,给定节点选择注意力分数γk,第k个节点的第i个词的最终细粒度通过公式(11)计算:
[0092][0093]
根据上述公式,第k个节点通过公式(12)计算:
[0094][0095]
选择transformer解码器来逐字解码输出标题,解码输出标题中第j个词的条件概率通过公式(13)计算:
[0096][0097]
其中来自目标端表示矩阵l表示解码器层数,ffn(
·
)代表前馈神经网络;
[0098]
通过公式(14)定义:
[0099]
[0100]
其中ln(
·
)表示层归一化操作;
[0101]
通过公式(15)计算:
[0102][0103]
上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1