基于GPT网络模型的短文本现代文转古文的迁移方法与流程
基于gpt网络模型的短文本现代文转古文的迁移方法
技术领域
1.本发明涉及自然语言处理技术领域,具体为基于gpt网络模型的短文本现代文转古文的迁移方法。
背景技术:
2.中华文化博大精深,能够了解并熟悉古文,可以有效的传承中华文化,提高民族的认同感,但是现有技术的古文转现代文方法大多需要专业人员利用专业的字典进行转换,工作难度大,工作效率低,普通大众在需要进行古文转现代文存在一定的难度,现有技术的转换迁移过程非常繁琐,不利于普通大众掌握,不利于公众对古文的理解和熟悉。
3.本发明基于gpt网络模型完成现代文转古文的文本风格迁移方法,充分利用gpt网络模型的简单、端到端文本生成的特点,通过有监督的现代文、古文语料对,将一段短文本现代文内容转换为短文本古文。
技术实现要素:
4.为解决上述技术问题,实现本发明技术效果,本发明提供一种基于gpt网络模型的短文本现代文转古文的迁移方法,包括有如下步骤:s1.构造古文-现代文训练数据集:将所有朝代的古文和对应现代文用tab键分开,设定古文和现代文的文本最大长度都为30,对数据进行删除过滤操作,即过滤掉古文和现代文中长度大于30的文本,合并在一个文件train.txt中,得到现代文和古文平行训练数据集;s2.建立词表:将步骤s1中得到的现代文和古文平行训练数据集中的所有字符去重后,建立词表序列,记为dict,dict的前项key为字符索引编号,dict的后项value为具体的单个字符,即dict={0:
‘
[cls]’,1:“[pad]”,2:“[sep]“,3:“国”.......},其中[cls]为文本起始符,[pad]代表当文本长度不够最大长度时,采用[pad]填充到max_len长度,[sep]为现代文到古文的分割符,max_len为步骤s1中所提及的每条文本数据最大长度;s3.数据和模型适配:设现代文和古文平行训练数据集中的某条文本样本中现代文为:“为什么会出现在这儿”,对应的古文为:“何以见于此”,则该条文本x先转化为[“[cls]”,“为”,“什”,“么”,“会”,“出”,“现”,“在”,“这”,“儿”,“[sep]”,“何”,“以”,“见”,“于”,“此”]记为列表a,文本不够最大长度60,则将列表a通过[pad]填充到该文本最大长度60,然后通过字典dict,映射成索引编号列表,进而变成张量,喂入gpt模型,将现代文和古文平行训练数据集中的所有文本执行同样的操作,得到整个训练数据集,作为模型输入;s4.构建gpt网络模型结构:其具体操作如下:模型约定文本长度为60,嵌入维度为256,针对每条文本,先经过token_embedding+postional_embedding将文本进行嵌入表示,此时文本表示矩阵形状为[60,256],将该文本嵌入输入到gpt网络模型,多头注意力机制multi_head_attention+前馈全连接神经网络feed_forward作为一个单元,重复6次,即6层相同的网络,得到整体网络模型结构;
s5.训练模型:根据步骤s4中已设定好的模型结构,加入模型优化器和损失函数进行模型训练,具体训练过程为:将步骤s1、步骤s2和步骤s3得到的模型输入,喂入步骤s4中得到的整体网络模型结构,模型最终目标即最小化损失函数,先根据网络结构进行前向传播,根据预测输出与真是输出计算损失,然后进行反向传播,通过adam优化器不断更新网络模型参数,以此往复运行,直到损失函数值降低到最小趋于稳定,将此时的参数矩阵进行保存,即可得到最优网络模型;s6.模型预测:假如用户输入的文本内容为“为什么会出现在这儿”,则将其变成序列[“[cls]”,“为”,“什”,“么”,“会”,“出”,“现”,“在”,“这”,“儿”,“[sep]”]记为list_input,其长度为len_list,然后通过
‘
[pad]’填充到最大长度60,再通过字典变成数字张量,将其作为输入,使用步骤s5中得到的最优网络模型,进入步骤s4中的网络结构,进行前向传播,得到logits值,再使用softmax计算模型输出的第len_list个位置概率最大值对应的字符,即此时模型预测下一个字为“何”,然后把“何”和输入拼接为[“[cls]”,“为”,“什”,“么”,“会”,“出”,“现”,“在”,“这”,“儿”,“[sep]”,“何”],然后再次通过
‘
[pad]’填充到最大长度max_len,再通过字典变成数字张量,将其作为输入喂入模型,此时计算模型输出的第len_list+1个位置概率最大值对应的字符。如此反复操作依次输出对应的古文,最后将所有预测的[sep]后的字符拼接在一起,作为文本风格转换的最终输出结果。
[0005]
进一步的,训练数据集中每条训练样本中的现代文最大长度不超过30字,古文最大长度不超过30字,模型最大长度为60。
[0006]
本发明的有益效果是:包括步骤有构造现代文-古文训练数据集;建立词表;数据和模型适配;构建gpt网络模型结构;训练模型;模型预测,最终输出结果;本发明使用gpt网络模型实现了现代文转古文,只需将现代文和古文通过分隔符[sep]拼接输入模型,进行模型训练即可完成,而gpt网络模型只是transoformer的解码器部分,比transformer实现更简单,相比传统的通过词典或者语法分析的文本风格迁移方法,不需要投入额外的管理成本;充分利用gpt网络模型的简单、端到端文本生成的特点,通过有监督的现代文、古文语料对,将一段短文本现代文内容转换为短文本古文。
附图说明
[0007]
图1为本发明中的gpt网络架构图。
具体实施方式
[0008]
发明基于gpt网络模型的短文本现代文转古文的迁移方法,包括有如下步骤:s1.构造古文-现代文训练数据集:将所有朝代的古文和对应现代文用tab键分开,设定古文和现代文的文本最大长度都为30,对数据进行删除过滤操作,即过滤掉古文和现代文中长度大于30的文本,合并在一个文件train.txt中,得到现代文和古文平行训练数据集;可使用基于东北大学小牛翻译团队开源的语料项目:古文-现代文平行语料(https://github.com/niutrans/classical-modern)进行现代文和古文平行训练数据集的构架;s2.建立词表:将步骤s1中得到的现代文和古文平行训练数据集中的所有字符去重后,建立词表序列,记为dict,dict的前项key为字符索引编号,dict的后项value为具体的单个字符,即dict={0:
‘
[cls]’,1:“[pad]”,2:“[sep]“,3:“国”.......},其中[cls]为文
本起始符,[pad]代表当文本长度不够最大长度时,采用[pad]填充到max_len长度,[sep]为现代文到古文的分割符,max_len为步骤s1中所提及的每条文本数据最大长度;s3.数据和模型适配:设现代文和古文平行训练数据集中的某条文本样本中现代文为:“为什么会出现在这儿”,对应的古文为:“何以见于此”,则该条文本x先转化为[“[cls]”,“为”,“什”,“么”,“会”,“出”,“现”,“在”,“这”,“儿”,“[sep]”,“何”,“以”,“见”,“于”,“此”]记为列表a,文本不够最大长度60,则将列表a通过[pad]填充到该文本最大长度60,然后通过字典dict,映射成索引编号列表,进而变成张量,喂入gpt模型,将现代文和古文平行训练数据集中的所有文本执行同样的操作,得到整个训练数据集,作为模型输入;s4.构建gpt网络模型结构:其具体操作如下:模型约定文本长度为60,嵌入维度为256,针对每条文本,先经过token_embedding+postional_embedding将文本进行嵌入表示,此时文本表示矩阵形状为[60,256],将该文本嵌入输入到gpt网络模型,多头注意力机制multi_head_attention+前馈全连接神经网络feed_forward作为一个单元,重复6次,即6层相同的网络,得到整体网络模型结构;s5.训练模型:根据步骤s4中已设定好的模型结构,加入模型优化器和损失函数进行模型训练,具体训练过程为:将步骤s1、步骤s2和步骤s3得到的模型输入,喂入步骤s4中得到的整体网络模型结构,模型最终目标即最小化损失函数,先根据网络结构进行前向传播,根据预测输出与真是输出计算损失,然后进行反向传播,通过adam优化器不断更新网络模型参数,以此往复运行,直到损失函数值降低到最小趋于稳定,将此时的参数矩阵进行保存,即可得到最优网络模型;s6.模型预测:假如用户输入的文本内容为“为什么会出现在这儿”,则将其变成序列[“[cls]”,“为”,“什”,“么”,“会”,“出”,“现”,“在”,“这”,“儿”,“[sep]”]记为list_input,其长度为len_list,然后通过
‘
[pad]’填充到最大长度60,再通过字典变成数字张量,将其作为输入,使用步骤s5中得到的最优网络模型,进入步骤s4中的网络结构,进行前向传播,得到logits值,再使用softmax计算模型输出的第len_list个位置概率最大值对应的字符,即此时模型预测下一个字为“何”,然后把“何”和输入拼接为[“[cls]”,“为”,“什”,“么”,“会”,“出”,“现”,“在”,“这”,“儿”,“[sep]”,“何”],然后再次通过
‘
[pad]’填充到最大长度max_len,再通过字典变成数字张量,将其作为输入喂入模型,此时计算模型输出的第len_list+1个位置概率最大值对应的字符。如此反复操作依次输出对应的古文,最后将所有预测的[sep]后的字符拼接在一起,作为文本风格转换的最终输出结果。
[0009]
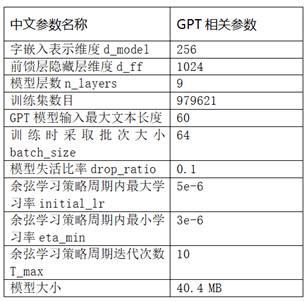
本发明中的gpt网络架构图,本发明的gpt模型的训练参数如下表。
[0010]
。
[0011]
使用本发明进行迁移后的效果如下表:。
[0012]
本发明使用gpt网络模型实现了现代文转古文,只需将现代文和古文通过分隔符[sep]拼接输入模型,进行模型训练即可完成,而gpt网络模型只是transoformer的解码器部分,比transformer实现更简单,相比传统的通过词典或者语法分析的文本风格迁移方法,不需要投入额外的管理成本。本发明训练集中每条训练样本中的现代文最大长度不超过30字,古文最大长度不超过30字,所以模型最大长度为60。相比于之前的现代文转古文方法,本发明为端到端的任务,除了准备数据,训练模型,推理模型,不需要任何复杂操作。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1