一种基于面部语义内容分解领域泛化框架的深度伪造检测算法
本发明涉及图像处理和取证,尤其涉及一种基于领域泛化的深度伪造人脸检测算法。
背景技术:
1、深度伪造视频检测已成为信息安全领域多媒体取证技术的一个亟待解决的问题。现有的深度伪造被动取证算法主要分为基于传统手工特征与基于数据驱动两类算法。其中,基于传统手工特征的算法是通过提取由篡改操作所带来的与自然图像不一致的统计特征、生物信号特征等实现的,然而这类检测算法仅在一些早期的数据集上表现出较好的检测能力,随着生成模型的不断成熟与生成算法对于明显伪影的重点消除,这类检测算法的检测能力大大减弱。相比之下,基于深度学习的数据驱动算法,通过卷积神经网络或循环神经网络自适应地提取图像和视频中存在的伪影特征,可以更有效地进行深度伪造的视频检测。具体的过程是搜集大量的深度伪造数据集,将其全部馈入到特定的神经网络(例如resnet、xception、transformer等)中,鼓励网络自适应地学习训练集的特征分布,以实现检测模型在目标数据集上的精准预测。然而,现有的基于数据驱动的检测算法所提取到图像的高维特征是高度数据集偏移的,即对训练集过拟合,造成预训练的模型在未知的数据集中检测性能差,即检测模型泛化性差。《thinking in frequency:face forgerydetection by mining frequency-aware clues》(qian y,yin g,sheng l,etal.thinking in frequency:face forgery detection by mining frequency-awareclues[c]//european conference on computer vision.springer,vol.12357,pp.86-103,2020)通过学习深度伪造图像数据与自然真实图像之间的频域特征差异,有效地提升模型在域内的检测能力,但这种方式是关注于某一数据域中真实与伪造的频域差异,一旦将所学习的模型应用于其他数据域则检测能力大幅度下降。qian y,yin g,sheng l,etal.thinking in frequency:face forgery detection by mining frequency-awareclues[c]//european conference on computer vision.springer,cham,2020:86-103.《improving the efficiency and robustness of deepfakes detection throughprecise geometric features》一文中提出现有的深度伪造视频生成过程中未对帧与帧之间的一致性做针对性处理,因此通过学习真实与伪造视频在帧与帧之间面部关键点的连续性之间的差异来实现深度伪造的检测,这类算法同样学习的是某一种数据域上的时域特征,在跨域检测中效果极差。而在现实应用中,给定一个待检测的视频,是无法获知其具体的篡改方式的,这极大地限制了基于深度学习检测算法的应用,因而如何提升检测模型的泛化能力至关重要。总的来看,现有的基于深度学习的深度伪造检测算法大都是通过设计一个基于卷积神经网络的特征提取器,提取单一源域的特定特征,所学习到的特征不可避免地会过度拟合该源域特有的痕迹,根据卷积神经网络会关注纹理丰富区域的特有属性,所关注的面部区域一般为眼睛、鼻子、嘴巴等局部语义信息,且针对不同的源域,用于判断真伪的区域是不一致的,导致在单一源域训练得到的模型在其他未知的目标域中检测性能较差。
技术实现思路
1、本发明的目的在于解决上述局限性,提供一种基于面部语义内容分解的域泛化网络框架,用于提升深度伪造检测模型的泛化性,使之能克服现有技术的以上不足。
2、实现本发明目的的技术方案如下:
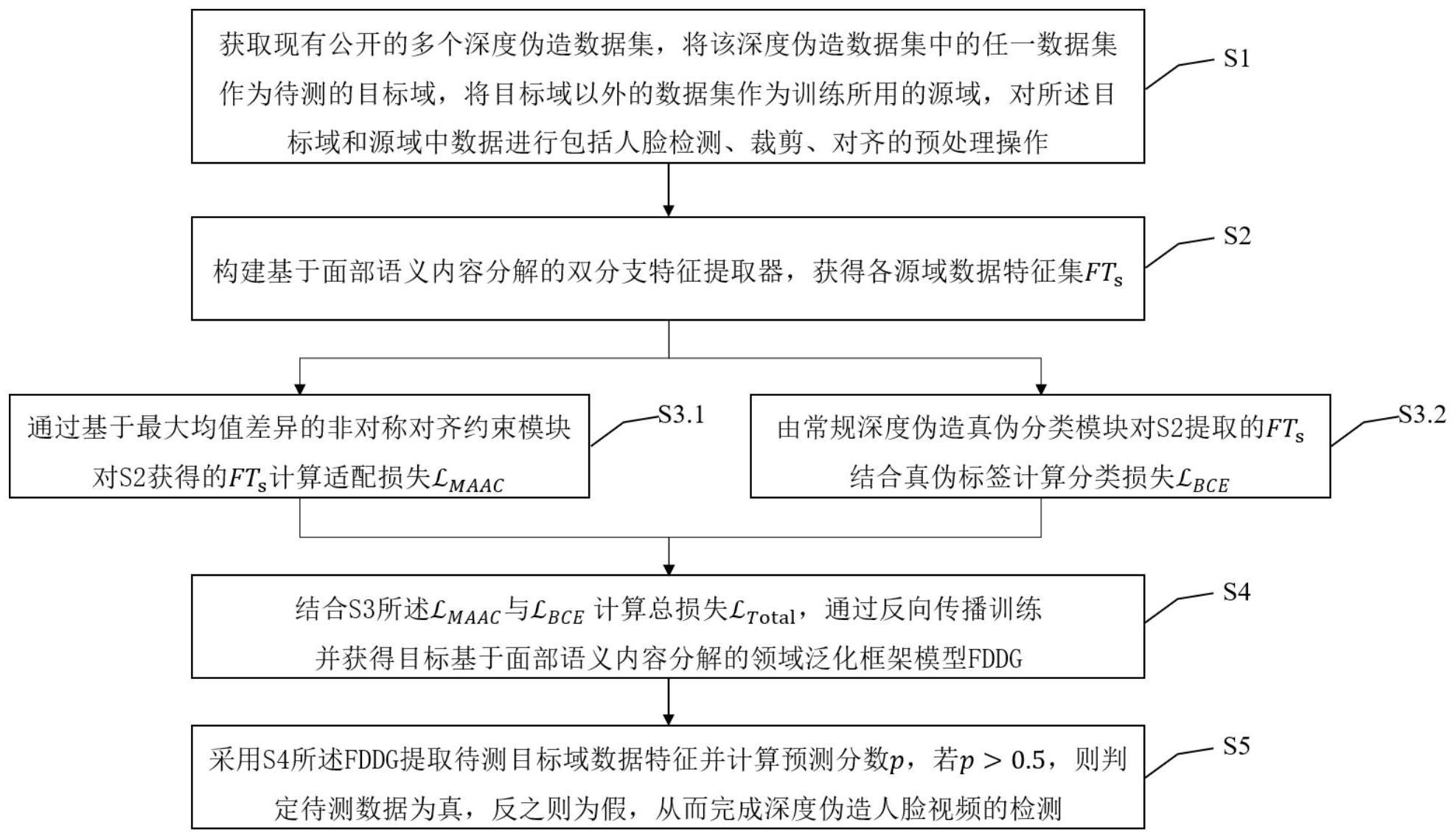
3、一种基于面部语义内容分解领域泛化框架的深度伪造检测算法,包括以下步骤:
4、步骤1:获取现有公开的多个深度伪造数据集,不同数据集是由不同的篡改方式生成的,且每个数据集中均具有视频的真伪标签与领域所属标签;将该深度伪造数据集中的任一数据集作为待测的目标域,将目标域以外的数据集作为训练所用的源域;对所述目标域和源域中数据进行包括人脸检测、裁剪、对齐的预处理操作;
5、步骤2:构建基于面部语义内容分解的双分支特征提取器fd-dbn,将步骤1预处理过的深度伪造数据集中的源域数据集馈入到fd-dbn中,其中k代表源域中数据集的个数,上标i代表源域中某一数据集的序号;具体处理方法是,一方面,采用卷积神经网络对整张人脸进行编码,提取全局特征,另一方面,通过对角线方向人脸图像块置乱模块dcsm(diagonal-directional cross-shuffling module)分解人脸图像,并采用卷积神经网络对分解后的人脸图像进行编码,提取局部特征,最后,通过基于坐标注意力机制的融合模块cafm融合上述提取的全局与局部特征,获得各源域数据特征集
6、步骤3:
7、3.1通过具有真实特征聚集约束rfc与域内-域间三元组约束ict的基于最大均值差异的非对称对齐约束模块maac(mmd-based asymmetric aligning constraint),对由步骤2提取的各源域数据特征集fts进行分布适配,计算基于最大均值差异的非对称对齐约束损失
8、其中,maac将多源域的数据分布特征考虑在内,即由不同篡改方式生成的伪造图像数据分布差异较大,因而对齐所有源域的伪造图像难度较大,相比之下,由于所有真实图像均为自然图像故而更容易对齐,因此maac通过先采用真实特征聚集约束rfc(real-feature clustering constraint)对齐多个源域的真实数据分布,再采用类内-类间三元组约束ict(intra-cross triplet constraint,ict)约束真实与伪造样本在特征空间分离的方式进行分布适配,相对应的适配损失为:
9、
10、3.2由常规深度伪造真伪分类模块将步骤2提取的各源域数据特征集fts结合真伪标签计算分类损失
11、步骤4:结合步骤3中所述与计算总损失通过反向传播训练基于面部语义内容分解的领域泛化框架模型;获得目标基于面部语义内容分解的领域泛化框架模型fddg;
12、所述网络最终的损失函数如下式所示:
13、
14、步骤5:采用步骤4训练获得的目标基于面部语义内容分解的领域泛化框架模型fddg提取待测目标域数据特征并计算预测分数p,若p>0.5,则认定待测数据为真,反之则为假,从而完成深度伪造人脸视频的检测。
15、本发明还提出了一种基于面部语义内容分解领域泛化框架的深度伪造检测系统,包括:
16、模块1:获取现有公开的多个深度伪造数据集,不同数据集是由不同的篡改方式生成的,且每个数据集中均具有视频的真伪标签与领域所属标签;将该深度伪造数据集中的任一数据集作为待测的目标域,将目标域以外的数据集作为训练所用的源域;对所述目标域和源域中数据进行包括人脸检测、裁剪、对齐的预处理操作;
17、模块2:构建基于面部语义内容分解的双分支特征提取器fd-dbn,将模块1预处理过的深度伪造数据集中的源域数据集馈入到fd-dbn中,其中k代表源域中数据集的个数,上标i代表源域中某一数据集的序号;具体处理方法是,一方面,采用卷积神经网络对整张人脸进行编码,提取全局特征,另一方面,通过对角线方向人脸图像块置乱模块dcsm分解人脸图像,并采用卷积神经网络对分解后的人脸图像进行编码,提取局部特征,最后,通过基于坐标注意力机制的融合模块cafm融合上述提取的全局与局部特征,获得各源域数据特征集
18、模块3:
19、3.1:用于通过具有真实特征聚集约束rfc与域内-域间三元组约束ict的基于最大均值差异的非对称对齐约束模块maac,对由模块2提取的各源域数据特征集fts进行分布适配,计算基于最大均值差异的非对称对齐约束损失
20、其中,maac将多源域的数据分布特征考虑在内,即由不同篡改方式生成的伪造图像数据分布差异较大,因而对齐所有源域的伪造图像难度较大,相比之下,由于所有真实图像均为自然图像故而更容易对齐,因此maac通过先采用rfc对齐多个源域的真实数据分布,再采用ict约束真实与伪造样本在特征空间分离的方式进行分布适配,相对应的适配损失为:
21、
22、3.2:用于由常规深度伪造真伪分类模块将模块2提取的各源域数据特征集fts结合真伪标签计算分类损失
23、模块4:用于结合模块3中所述与计算总损失通过反向传播训练基于面部语义内容分解的领域泛化框架模型;获得目标基于面部语义内容分解的领域泛化框架模型fddg;
24、所述网络最终的损失函数如下式所示:
25、
26、模块5:用于采用模块4训练获得的目标基于面部语义内容分解的领域泛化框架模型fddg提取待测目标域数据特征并计算预测分数p,若p>0.5,则认定待测数据为真,反之则为假,从而完成深度伪造人脸视频的检测。
27、相对于现有技术,本发明的有益效果在于:
28、(1)本发明利用基于面部语义内容分解的特征提取器,能够解决现有的卷积神经网络的检测算法会过度拟合人脸语义内容而忽视了深度伪造特有痕迹的问题,强迫特征提取器关注更细微、局部且共享的判别性特征;
29、(2)采用基于面部语义内容分解的领域泛化框架,能够同时考虑多个源域的特征分布,鼓励网络选取一个由多个源域共享的特征空间,且该特征空间能够应用到其他未知但相关的目标域数据中,解决了原有算法会学习到数据集偏移特征的缺陷;
30、(3)由于多个源域篡改类型不同,数据分布差异过大,伪造数据难以对齐,相比之下真实数据均是未经篡改的自然图像更易拟合,因而提出基于最大均值差异的非对称对齐约束,能够更好的优化网络框架,提升检测的速度与精度。
- 还没有人留言评论。精彩留言会获得点赞!