一种开放领域问答的表格检索增强方法
1.本发明属于自然语言处理和信息检索技术领域,涉及一种基于text-to-sql深度学习模型的开放域问答的表格检索增强的方法。
背景技术:
2.开放域问答相对于闭域问答,答案不局限在某一给定的阅读材料中,而是存在于一个大型的语料库中。表格作为一种存储信息的重要途径,大量存在网络服务和关系型数据库中。相对于自由文本形式,表格存储的信息量大,内容更具体,是开放域问答的重要信息来源。表格开放域问答任务将检索的对象从文本变为表格,研究从大量表格中获取用户关注的信息,在搜索引擎和人工客服中都能发挥重要作用。
3.目前,开放域问答的主流方法是两阶段框架:检索-阅读模型,它将开放域问答分为两个阶段:检索阶段的目的是从成千上万的文本中寻找和问题相关的文本段,阅读阶段将从这些相关的内容中提取回答。对于表格开放域问答来说,阅读阶段可以看作是一个闭域的表格问答。
4.在检索方面,传统的bm25方法和基于深度学习的dpr方法都是针对于自由文本,没有对表格做特别优化。有学者提出dtr,相较于dpr,使用了tapas取代bert作为编码器,针对表格结构做了编码,但检索任务与表格内容是强相关的,仅编码表格的结构导致了表格检索效果不理想。
5.闭域表格问答取得了极大的研究进展,有两种主要的方法,一种是编码表格的结构和内容,选取目标的单元格作为回答,如tapas;一种是基于语义解析,将自然语言描述的问题转换为在表格上可执行的逻辑形式,如sql,再执行该语句而得到问题相应的回答。目前,闭域的text-to-sql任务的模型,已经在wikisql等大型数据集上达到90%以上的准确率。由此可见,表格检索成为整个开放域问答准确率提升的瓶颈。
技术实现要素:
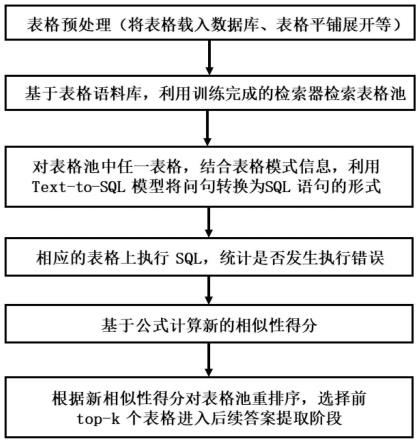
6.针对上述问题,本发明提供一种基于执行引导的面向开放领域问答的表格检索增强方法。首先使用检索器从表格语料库中初步筛选相关的表格得到表格池,然后对于表格池中各表格,使用深度学习的text-to-sql模型,结合问句和表格模式信息将问句转换为sql等的标准化的逻辑形式,接下来在表格上执行sql并判断执行结果是否发生错误,以此作为相关性依据融入新一轮相似性计算中。
7.本发明的技术方案为:
8.将开放域问答的过程分为:表格检索阶段和提取回答阶段;有如下步骤:
9.s1、表格预处理。将表格语料库利用sqlite等工具转换成为db形式,使得sql语句可以在任一表格上执行。如果表格本身就存在于关系型数据库,则跳过预处理阶段。
10.s2、实施初步检索。将表格按行平铺展开,形成文本形式的表格内容;编码该内容并加载入索引库中;利用检索器计算出问句与表格语料库中各表格原始相似度;按照原始
相似度由大到小的损失进行排序,选择前n个表格构成表格池。
11.s3、在表格上执行语句并得到新的相似性得分。对表格池中的每个表格,先将问句和表格模式信息输入text-to-sql深度学习模型,得到对应的sql语句,然后在表格上执行得到的sql语义,判断是否发生执行错误,如果没有发生执行错误,则令res
eg
=1,如果发生执行错误,则令res
eg
=0;计算新的相似性得分:
12.sim
witheg
=(1-α)
·
sim
origin
/maxsim
origin
+α
·
res
eg
13.其中sim
origin
是检索阶段的原始相似性得分,maxsim
origin
是检索阶段所有表格的最大的原始相似性得分,sim
witheg
是新的相似性得分;
14.s4、表格重排序。将表格池中的n个表格按新的相似性得分sim
witheg
从大到小重新排序,选择分数最高的top-k个表格,进入提取回答阶段;
15.s5、提取回答阶段。基于输入问句和得到的top-k个表格,利用单元格分类或生成等答案提取的深度学习模型得到答案。
16.本发明的有益效果为:在表格检索的过程中充分利用到了表格的模式信息,将执行的结果融入了检索相似性得分,有效提高了开放域问答过程中表格检索阶段的准确率。
附图说明
17.图1是开放域问答两阶段模型示意图。
18.图2是基于执行引导的表格检索增强流程图。
19.图3是基于执行引导的表格检索增强与无增强的实验结果对比。
具体实施方式
20.下面结合附图来对本发明进行详细描述。
21.本发明中,表格开放域问答的两阶段模型如图1。基于执行引导的表格检索增强流程如图2,其中,表格检索阶段可涉及到两个深度学习模型:检索器和text-to-sql模型。在实际检索前需要结合标注的表格语料库数据完成相应模型训练。
22.表格的预处理。将表格语料库利用sqlite等工具转换成为db形式,使得sql语句可以在任一表格上执行。如果表格本身就存在于关系型数据库,则跳过预处理阶段。
23.表格的平铺展开。在索引库建立之前,将语料库中的所有表格处理成连续文本的形式。将表格的标题、列名、行内容按以下形式拼接。如果没有表格标题则用空格填充。
24.表格标题|表格列名|第一行内容|第二行内容|
…
|第n行内容
25.在拼接的过程中,将分隔符加入表格转换后的拼接的文本。用“,”代表行中每个单元格的分割,用“.”代表行与行之间的分割。分隔符使得检索器能在一定程度上学习到表格的结构。
26.实施初步检索。检索器的目标是从数以万计的大型表格语料库中,根据与问题q的相关度检索出分数由大到小的n个表格t1,t2,...,tn,作为与问句相关的表格池。由于这是一个初步检索的阶段,因此n一般为一个较大的数量。考虑到后续的筛选的效率,设置n=200。
27.检索器可以采用传统的方法比如bm25,将预处理后的表格加载入elasticsearch索引库中,设置elasticsearch内置相似性算法为bm25,并设置算法参数为k=1.2,b=
0.75,指定查询返回的结果数为n,即可使用其实现表格的初步检索。bm25方法不需要进行模型训练。
28.检索器也可以使用深度学习的密集检索器dpr。dpr是一个基于bert的双编码器,两个编码器分别将问题q
nl
和表格ti编码为向量vq和向量长度和bert的编码长度一致,为d=728。经过微调后,dpr会转换问题和表格为向量形式并确保语义上相关的问题-表格对的内积相较其他不相关的更大,并能更好捕捉到语义的相似性,而bm25等传统方法对关键词更为敏感。
29.在实施的过程中,基于平铺展开的表格语料库训练一个dpr检索器,训练的过程选取了1个bm25分数最高的非gold表格作为难例,设置batch_size=32并使用了in-batch negative的训练方法。完成训练后,使用dpr的双编码器之一:表格编码器,将语料库中的所有表格做类似的处理后得到编码后的表格向量,加载入密集向量检索库fassi中。在初步检索时,使用dpr的双编码器之一:问句编码器将问句编码成向量,并在fassi库中做搜索。
30.检索器对于目标问句,返回原始相似度较高的前n的表格,以其作为表格池。
31.表格重排序。在此过程中引入了以hydranet为例的text-to-sql深度学习模型作为问句的语义解析器。在进行表格重排序之前,基于wikisql数据集训练一个hydranet模型,使用batch_size=64,learn_rate=6*10-6
,基础模型使用roberta。在表格重排序过程中,对表格池中的每个表格,先将问句和表格模式信息输入hydranet模型,解析出与问句对应的sql语句。接下来,在表格上执行该sql语句,统计执行时是否发生错误。
32.将候选表格上执行的结果按照不同类型转换为额外的参数:res
eg
,当没有发生执行错误的时候,res
eg
=1,当发生执行错误的时候,res
eg
=0。在现实情况中,往往在提问时期望结果时不为空的,因此可将结果为空视作特殊的执行错误。
33.基于以下函数计算新的相似性得分,
34.sim
witheg
=(1-α)
·
sim
origin
/maxsi
origin
+α
·
res
eg
35.其中sim
origin
是检索阶段的原始相似性得分,maxsim
origin
是检索阶段所有表格的最大的原始相似性得分,sim
witheg
是新的相似性得分;用系数α度量执行结果的重要程度,将原始检索的相关性得分与执行结果做线性求和,得到新的相似性估计分数。根据表格语料库的实际情况取不同的系数α值。在本实施过程中,取α=0.9。
36.将表格池中的n个表格按新的相似性得分sim
witheg
从大到小重新排序,选择分数最高的top-k个表格,进入提取回答阶段;
37.提取回答阶段。基于输入问句和得到的top-k个表格,利用单元格分类或生成等答案提取的深度学习模型得到答案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1