基于局部自注意力的知识增强的词义消歧方法和装置
1.本发明涉及人工智能、自然语言处理技术领域,具体涉及一种基于局部自注意力的知识增强的词义消歧方法和装置。
背景技术:
2.自动问答系统能够允许用户以自然语言文本提问的形式提出问题,对问题进行分析,依据知识库推理并为用户返回答案。自动问答系统在自助服务、智能客服、售前咨询等领域有着广泛的现实应用。对于用户输入的自然语言文本,如何快速确定自然语言文本所有单词的正确词义,将直接影响自动问答系统的性能,是自动问答系统的核心技术之一。
3.词义消歧任务是指根据歧义词所处的上下文环境,判定其正确词义。这与许多自然语言处理任务的核心目标是一致的,如前所述自动问答系统。词义消歧任务是一项极具挑战性的工作,现有方法还未能完善地解决这一问题。
4.现有的基于神经网络的词义消歧方法利用transformer和bert等语言模型来消除目标歧义词的歧义。它们将wsd(word sense disambiguation,词义消歧)视为分类任务,通常使用统一的分类器消除所有歧义词的歧义。然而,这些模型仅侧重于根据语义标注的训练数据,学习歧义词的词义与上下文的关系,而忽略了挖掘利用现有知识本体所蕴含的语义知识。针对这一问题,一些工作试图将语义知识集成到神经wsd模型中。比如,将词义注释整合到wsd中,利用记忆网络学习编码词义注释和上下文的关系;或者,将wordnet中的词义注释和上下文来构造上下文-注释对,将wsd重新定义为文本匹配任务。但是,已有工作都没有同时考虑歧义词的所有候选词义,这与人类的认知行为不一致;人类在遇到歧义词时,通常会同时考虑所有候选词义,通过比较候选词义与上下文的匹配程度,而确定歧义词的正确词义。此外,已有工作仅侧重于学习词义表示的简短定义即词义注释,而忽略了知识本体所蕴含的其它语义知识。综上所述,现有的词义消歧方法不能同时考虑所有候选词,并且未能充分利用知识本体所蕴含的语义知识,仍有巨大的改进空间。
技术实现要素:
5.针对现有词义消歧方法的不足,本发明首先通过知识增强模块增强歧义词的词义表示,然后通过基于局部自注意力的transformer模块抽取候选词义可能正确的文本跨度,最后通过预测模块判定歧义词的正确词义。
6.本发明的技术任务是按以下方式实现的,知识增强模块将歧义词的上下文与从知识本体中检索得到的候选词义的注释、例句等语义知识进行拼接,得到歧义词的上下文和候选词义增强描述的合并文本,简称为合并文本;而后,基于局部自注意力的transformer模块通过多层双向编码器、双向解码器的堆叠以实现对合并文本的编码、解码,得到合并文本各token的logits分数(token即指文本中包含的单词及标点符号等,logits分数表示当前token是候选词义所对应的增强描述的开始或结束位置的概率);最后,预测模块对合并文本各token的logits分数,进行softmax、argmax操作,得到正确词义所对应的增强描述的
文本跨度,进而判断出歧义词的正确词义。具体如下:
7.知识增强模块首先将对知识本体进行检索,得到歧义词的候选词义的注释、候选词义的例句、候选词义的上位词义注释,并进行拼接,得到候选词义的增强描述;而后,将得到的候选词义的增强描述和歧义词的上下文进行拼接,得到歧义词的上下文和候选词义增强描述的合并文本,简称为合并文本;最后,将合并文本传递给基于局部自注意力的transformer模块;
8.基于局部自注意力的transformer模块首先将合并文本转化为token向量,然后分别通过双向编码器、双向解码器对合并文本的token向量进行编码、解码操作,双向编码器利用局部自注意力机制,采取一个滑动窗口使合并文本中的各token只关注其两侧一半窗口大小的tokens,也即合并文本中各token只和两侧一半窗口大小的tokens进行交互;最后通过线性层得到合并文本各token的logits分数,并将其送入预测模块;
9.预测模块对合并文本中各token的logits分数,利用softmax、argmax进行处理,预测可能的正确词义所对应的增强描述的文本跨度;该文本跨度所对应的候选词义,即模型预测所得的歧义词的正确词义。
10.作为优选,所述知识增强模块的构建过程具体如下:将歧义词w的上下文和w候选词义的注释候选词义的例句候选词义的上位词义注释拼接起来用a表示,即a={g1,es1,hg1,g2,es2,hg2,...,gn,esn,hgn},作为基于局部自注意力的transformer模块的输入;其中w代表单词,m代表上下文的单词数量,|g|代表候选词义的注释的单词数量、|e|代表候选词义的例句的单词数量、|h|代表候选词义的上位词义注释的单词数量,上标n代表候选词义的数量,上标c、g、e、h分别表示上下文、注释、例句、上位词义注释;公式描述如下:
[0011][0012]
其中,公式(1)中的input表示歧义词的上下文和候选词义增强描述的合并文本;标签<s>、</s>包围整个输入序列;标签</d>将歧义词的上下文和外部的语义知识也即候选词义的注释、候选词义的例句、候选词义的上位词义注释分割开来;上标g1、e1、h1分别代表歧义词的第一个候选词义的注释、第一个候选词义的例句、第一个候选词义的上位词义注释,上标gn、en、hn分别代表歧义词的第n个候选词义的注释、第n个候选词义的例句、第n个候选词义的上位词义注释;下标|gn|、|en|、|hn|分别代表第n个候选词义的注释的单词数量、第n个候选词义的例句的单词数量、第n个候选词义的上位词注释的单词数量;其他符号在之前已经说明,不再累述。
[0013]
更优地,所述基于局部自注意力的transformer模块的构建过程具体如下:
[0014]
基于局部自注意力的transformer模块首先将公式(1)得到的歧义词的上下文和候选词义增强描述的合并文本转化为token向量的形式,记作t,公式描述如下:
[0015]
t={t1,t2,...t
l
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0016]
其中,t代表合并文本中的某个token的向量表示,称为token向量;下标l代表合并文本中token的数量。
[0017]
基于局部自注意力的transformer模块的双向编码器,以公式(2)得到的合并文本各token的向量表示作为输入,采用固定窗口大小w的滑动窗口,使各token只关注其每一侧二分之一w个tokens,双向编码器层第l层的输出记为即经过局部自注意力机制得到的第l层第i个token向量表示;局部自注意力机制的公式描述如下:
[0018][0019]
其中,公式(3)中的是局部query矩阵,下标代表局部注意力的关注范围;代表双向编码器层l-1层的第i个query向量,用来计算第i个token向量与局部key矩阵中的token向量的相似度;是局部key矩阵,代表双向编码器层l-1层的第i个key向量,用来计算第i个token向量与局部query矩阵中的token向量的相似度;t表示矩阵转置;是局部value矩阵,代表双向编码器层l-1层的第i个value向量,用来计算当前token向量与其他token向量最后的注意力分数;局部query矩阵、局部key矩阵、局部value矩阵都是由各token向量形成的输入矩阵与不同的可训练的参数矩阵相乘,经过线性变换得来的;dk是嵌入向量的维度;sum()为求和函数;softmax()为归一化指数函数。
[0020]
基于局部自注意力的transformer模块通过多层双向编码器、双向解码器的堆叠,最后歧义词的上下文和候选词义增强描述的合并文本的token向量表示在通过最后一层双向编码器后,得到隐藏状态的表示,公式描述如下:
[0021]
h1,h2,
…
,h
l
=transformer(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0022]
其中,h代表隐藏状态的表示;d代表隐状态的维度;所有的隐藏状态表示形成最终的矩阵h=[h1,h2,
…
,hn];transformer代表transformer模型。
[0023]
将公式(4)得到的矩阵h送入线性层处理,得到合并文本各token的logits分数,用矩阵z表示,公式描述如下:
[0024]
z=w
t
h+b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0025]
start=[z
11
…z1l
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0026]
end=[z
21
…z2l
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0027]
其中,是可训练的参数;start、end分别表示合并文本各token的logits分数,表示当前token是候选词义所对应的增强描述的开始或结束位置的概率;z
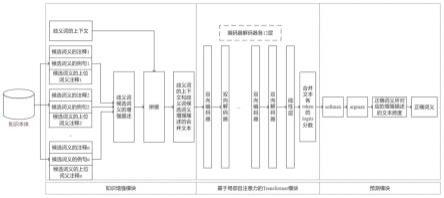
1l
代表合并文本第l个token开始位置的logits分数矩阵,z
2l
代表合并文本第l个token结束位置的logits分数矩阵。
[0028]
更优地,所述预测模块构建过程如下:
[0029]
将公式(6)、(7)得到的start、end作为预测模块的输入,预测模块通过softmax得到概率分布,然后对候选词义增强描述的文本跨度的开始和结束概率分布执行乘积操作,
生成概率对p
cor
(i,j);公式描述如下:
[0030][0031][0032]
p
cor
(i,j)=p
cor(i)×
p
cor
(j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0033]
其中,p
cor
(i)代表i是正确词义所对应的增强描述的文本跨度开始位置的概率,p
cor
(j)代表j是正确词义所对应的增强描述文本跨度结束位置的概率;exp()表示自然常数e为底的指数函数;startv代表第v个token是候选词义文本跨度开始位置的概率;endv代表第v个token是候选词义文本跨度开始位置的概率;starti代表第i个token是正确词义文本跨度开始位置的概率;endj代表第j个token是正确词义文本跨度结束位置的概率;l代表合并文本中token的数量;p
cor
(i,j)代表从i开始到j结束的文本跨度是正确词义所对应的增强描述文本跨度的概率;
[0034]
最后,预测模块通过argmax得到最后的输出;公式描述如下:
[0035]
output=argmaxp
cor
(i,j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0036]
其中,output为得分最高的文本跨度,即模型预测所得的歧义词的正确词义。
[0037]
所述词义消歧模型构建完成后,通过训练数据集进行训练与优化,具体如下:
[0038]
模型使用公开的词义消歧数据集进行训练。
[0039]
构建损失函数:由公式(6)、(7)可知,start为模型预测得到的候选词义所对应的增强描述的文本跨度开始位置的概率,end是模型预测得到的候选词义所对应的增强描述的的文本跨度结束位置的概率;然后对开始和结束位置的概率分别采用交叉熵损失函数,然后将两个损失相加,公式如下:
[0040][0041][0042][0043]
其中,starti、endj分别表示正确候选词义文本跨度开始和结束位置的概率;log代表对数损失函数;exp()表示自然常数e为底的指数函数;startv代表第v个token是候选词义文本跨度开始位置的概率,endv代表第v个token是候选词义文本跨度开始位置的概率;v=1代表第一个token;l代表合并文本中token的数量;分别表示模型预测得到的正确词义所对应的增强描述的文本跨度开始或结束位置的损失。
[0044]
优化训练模型:选择使用radam为优化函数作为本模型的优化函数,其学习率初始设置为2e-6,权重衰减设置为0.01。
[0045]
一种基于局部自注意力的知识增强的词义消歧装置,该装置包括知识增强模块构建单元、基于局部自注意力的transformer模块构建单元、预测模块构建单元、词义消歧模型训练单元,具体为:
[0046]
知识增强模块构建单元,将歧义词的上下文与从知识本体中检索得到的候选词义的注释、例句等语义知识进行拼接,得到歧义词的上下文和候选词义增强描述的合并文本,简称为合并文本;
[0047]
基于局部自注意力的transformer模块构建单元,通过多层双向编码器、双向解码器的堆叠以实现对合并文本的编码、解码,得到合并文本各token的logits分数;
[0048]
预测模块构建单元,将基于局部自注意力的transformer模块得到的合并文本各token的logits分数,通过softmax、argmax得到正确词义所对应的增强描述的文本跨度,进而判断歧义词的正确词义。
[0049]
所述词义消歧模型训练单元包括:
[0050]
损失函数构建单元,负责计算预测的歧义词的候选词义开始和结束的文本跨度与歧义词的正确候选词义开始和结束的文本跨度的误差;
[0051]
模型优化单元,负责训练并调整模型训练中的参数,减小预测误差。
[0052]
一种存储介质,其中存储有多条指令,所述指令有处理器加载,执行上述的基于局部自注意力的知识增强的词义消歧方法和装置的步骤。
[0053]
一种电子设备,所述电子设备包括:
[0054]
上述的存储介质;以及
[0055]
处理器,用于执行所述存储介质中的指令。
[0056]
本发明的基于局部自注意力的知识增强的词义消歧方法和装置具有以下优点:
[0057]
(一)本发明通过使用知识增强模块,可以整合wordnet中候选词义的注释、候选词义的例句、候选词义的上位词义注释的丰富语义信息,使得候选词义的语义描述更加丰富、准确;
[0058]
(二)本发明通过使用局部自注意力机制,将注意力限制在局部范围,允许输入更长的文本;同时能够缓解由于引入额外的信息而造成的模型的巨大计算负担,从而达到既能提升词义消歧的准确性又能控制模型的计算复杂度的目的;
[0059]
(三)本发明通过使用bart
large
作为transformer的架构,可以利用内在的隐性知识来捕捉目标歧义词的上下文及候选词义的注释、候选词义的例句、候选词义的上位词义注释中蕴含的语义信息,从而提高词义消歧的准确性;
[0060]
(四)本发明通过将wsd转化为一个文本跨度抽取问题,可以同时向模型输入歧义词的上下文和候选词义丰富的语义信息;通过模型抽取出候选词义正确的文本跨度,从而提高wsd模型的性能和泛化能力;
[0061]
(五)本发明所提出的基于局部自注意力的知识增强的词义消歧方法,能够方便地对接多种不同的知识本体,能够有效地进行扩展增强。
附图说明
[0062]
下面结合附图对本发明进一步说明。
[0063]
图1为基于局部自注意力的知识增强的词义消歧模型的框架示意图;
[0064]
图2为基于局部自注意力的知识增强的词义消歧方法的流程图;
[0065]
图3为基于局部自注意力的知识增强的词义消歧装置的结构示意图;
[0066]
图4为训练基于局部自注意力的知识增强词义消歧模型的流程图;
[0067]
图5为构建知识增强模块的流程图。
具体实施方式
[0068]
参照说明书附图和具体实施例对本发明的基于局部自注意力的知识增强的词义消歧方法和装置作以下详细地说明。
[0069]
实施例1:
[0070]
如附图1所示,本发明的主要框架结构包含知识增强模块、基于局部自注意力的transformer模块和预测模块。首先,知识增强模块将歧义词的上下文与从知识本体中检索得到的候选词义的注释、例句等语义知识进行拼接,得到歧义词的上下文和候选词义增强描述的合并文本,简称为合并文本。而后,基于局部自注意力的transformer模块通过多层双向编码器、双向解码器的堆叠以实现对合并文本的编码、解码,得到合并文本各token的logits分数;token即指文本中包含的单词及标点符号等,logits分数表示当前token是候选词义所对应的增强描述的开始或结束位置的概率。最后,预测模块对合并文本各token的logits分数,进行softmax、argmax操作,预测正确词义所对应的增强描述的文本跨度,进而判断出歧义词的正确词义。具体如下:
[0071]
(1)知识增强模块首先将对知识本体进行检索,得到歧义词的候选词义的注释、候选词义的例句、候选词义的上位词义注释,并进行拼接,得到候选词义的增强描述;而后,将得到的候选词义的增强描述和歧义词的上下文进行拼接,得到歧义词的上下文和候选词义增强描述的合并文本,简称为合并文本;最后,将合并文本传递给基于局部自注意力的transformer模块;
[0072]
(2)基于局部自注意力的transformer模块首先将合并文本转化为token向量,然后分别通过双向编码器、双向解码器对合并文本的token向量进行编码、解码操作,双向编码器利用局部自注意力机制,采取一个滑动窗口使合并文本中的各token只关注其两侧一半窗口大小的tokens,也即合并文本中各token只和两侧一半窗口大小的tokens进行交互;最后通过线性层得到合并文本各token的logits分数,并将其送入预测模块;
[0073]
(3)预测模块对合并文本中各token的logits分数,利用softmax、argmax进行处理,预测可能的正确词义所对应的增强描述的文本跨度;该文本跨度所对应的候选词义,即模型预测所得的歧义词的正确词义。
[0074]
实施例2:
[0075]
本发明的基于局部自注意力的知识增强的词义消歧方法,如附图2所示,包含构建知识增强模块、构建基于局部自注意力的transformer模块、构建预测模块和训练词义消歧模型等四个主要步骤,具体如下:
[0076]
s1:构建知识增强模块,如附图5所示,具体步骤如下:
[0077]
首先将对知识本体进行检索,得到歧义词的候选词义的注释、候选词义的例句、候选词义的上位词义注释,并进行拼接,得到候选词义的增强描述;而后,将得到的候选词义的增强描述和歧义词的上下文进行拼接,得到歧义词的上下文和候选词义增强描述的合并文本,简称为合并文本;最后,将合并文本传递给基于局部自注意力的transformer模块;
[0078]
s101根据知识本体,获取歧义词的候选词义、候选词义的注释、候选词义的例句、候选词义的上位词义注释;
railway cars coupled together and drawn by a locomotive.express trains don’t stop at princeton junction.conveyance for passengers or mail or freight.a sequentially ordered set of things or events or ideas in which each successive member is related to the preceding.a train of thought.similar things placed in order or happening one after another.《/s》
[0088]
在pytorch中,对于上面描述的代码实现如下所示:
[0089]
[0090][0091]
其中,prepare_augment_data()为定义的知识增强函数;definition,examples,hypernym_gloss分别为歧义词的上下文、候选词义的注释、候选词义的例句、候选词义的上位词注释,definitions_offsets、examples_offsets、hypernym_gloss_offset是其集合;list[str]将字符转换为列表形式;for i in range(len(definitions))遍历歧义词候选词义的注释,for i in range(len(examples))遍历歧义词候选词义的例句,for i in range(len(hypernym_gloss))遍历歧义词候选词义的上位词义注释;encode_pair()函数可得到合并文本。
[0092]
s2:构建基于局部自注意力的transformer模块
[0093]
基于局部自注意力的transformer模块首先将合并文本转化为token向量,然后分别通过双向编码器、双向解码器对合并文本的token向量进行编码、解码操作,双向编码器利用局部自注意力机制,采取一个滑动窗口使合并文本中的各token只关注其两侧一半窗口大小的tokens,也即合并文本中各token只和两侧一半窗口大小的tokens进行交互;最后通过线性层得到合并文本各token的logits分数,并将其送入预测模块;
[0094]
基于局部自注意力的transformer模块首先将s1得到的歧义词的上下文和候选词义增强描述的合并文本转化为token向量的形式,记作t,公式描述如下:
[0095]
t={t1,t2,...t
l
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0096]
其中,t代表合并文本中的某个token的向量表示,称为token向量;下标l代表合并文本中token的数量。
[0097]
举例说明:在pytorch中,对于上面描述的代码实现如下所示:
[0098][0099]
其中,autoknowledgetokenizer()为自动分词函数;autotokenizer.from_pretrained()为加载预训练函数;"《classify》","《/classify》","《g》","《/g》"为定义的特殊符号。
[0100]
s202基于局部自注意力的transformer模块的双向编码器,以s201得到的合并文本各token的向量表示作为输入,采用固定窗口大小w的滑动窗口,使各token只关注其每一侧二分之一w个tokens,双向编码器层第l层的输出记为即经过局部自注意力机制得到的第l层第i个token向量表示;局部自注意力机制的公式描述如下:
[0101][0102]
其中,公式(3)中的是局部query矩阵,下标代表局部注意力的关注范围,代表双向编码器层l-1层的第i个query向量,用来计算第i个token向量与局部key矩阵中的token向量的相似度;是局部key矩阵,代表双向编码器层l-1层的第i个key向量,用来计算第i个token向量与局部query矩阵中的token向量的相似度;t表示矩阵转置;是局部value矩阵,代表双向编码器层l-1层的第i个value向量,用来计算当前token向量与其他token向量最后的注意力分数;局部query矩阵、局部key矩阵、局部value矩阵都是由各token向量形成的输入矩阵与不同的可训练的参数矩阵相乘,经过线性变换得来的;dk是嵌入向量的维度;sum()为求和函数;softmax()为归一化指数函数。
[0103]
s203基于局部自注意力的transformer模块通过多层双向编码器、双向解码器的堆叠,最后歧义词的上下文和候选词义增强描述的合并文本的token向量表示在通过最后一层双向编码器后,得到隐藏状态的表示,公式描述如下:
[0104]
h1,h2,
…
,h
l
=transformer(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0105]
其中,h代表隐藏状态的表示;d代表隐状态的维度;所有的隐藏状态表示形成最终的矩阵h=[h1,h2,
…
,h
l
];transformer代表transformer模型。
[0106]
s204将s203的矩阵h送入线性层处理,得到合并文本各token的logits分数,用矩
阵z表示,公式描述如下:
[0107]
z=w
t
h+b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0108]
start=[z
11
…z1l
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0109]
end=[z
21
…z2l
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0110]
其中,是可训练的参数;start、end分别表示合并文本各token的logits分数,表示当前token是候选词义所对应的增强描述的开始或结束位置的概率;z
1l
代表合并文本第l个token开始位置的logits分数矩阵,z
2l
代表合并文本第l个token结束位置的logits分数矩阵。
[0111]
举例说明:在pytorch中,对于上面描述的代码实现如下所示:
[0112][0113][0114]
其中,model()为模型函数;encoder_last_hidden_state为最后一层编码器隐藏状态;logits表示当前token是候选词义所对应的增强描述的开始或结束位置的概率;split()为拆分字符串函数;squeeze()为张量降维函数;start_logits为候选词义增强描述的各token代表开始位置的logits分数,end_logits为候选词义增强描述的各token代表结束位置的logits分数。
[0115]
s3:构建预测模块
[0116]
预测模块对合并文本中各token的logits分数,利用softmax、argmax进行处理,预测可能的正确词义所对应的增强描述的文本跨度;该文本跨度所对应的候选词义,即模型预测所得的歧义词的正确词义。
[0117]
将s204得到的start、end作为预测模块的输入,预测模块通过softmax得到概率分布,然后对候选词义增强描述的文本跨度的开始和结束概率分布执行乘积操作,生成概率
对p
cor
(i,j);公式描述如下:
[0118][0119][0120]
p
cor
(i,j)=p
cor(i)×
p
cor
(j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0121]
其中,p
cor
(i)代表i是正确词义所对应的增强描述的文本跨度开始位置的概率,p
cor
(j)代表j是正确词义所对应的增强描述文本跨度结束位置的概率;exp()表示自然常数e为底的指数函数;startv代表第v个token是候选词义文本跨度开始位置的概率;endv代表第v个token是候选词义文本跨度开始位置的概率;starti代表第i个token是正确词义文本跨度开始位置的概率;endj代表第j个token是正确词义文本跨度结束位置的概率;l代表合并文本中token的数量;p
cor
(i,j)代表从i开始到j结束的文本跨度是正确词义所对应的增强描述文本跨度的概率;
[0122]
最后,预测模块通过argmax得到最后的输出;公式描述如下:
[0123]
output=argmaxp
cor
(i,j)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0124]
其中,output为得分最高的文本跨度,即模型预测所得的歧义词的正确词义。
[0125]
举例说明:在pytorch中,对于上面描述的代码实现如下所示:
[0126][0127]
其中,probabilistic_prediction()为预测函数;start_logits_lp为候选词义增强描述的文本跨度开始位置的概率;end_logits_lp为候选词义增强描述的文本跨度结束位置的概率;sense_probs为预测可能的正确候选词义的分数;label_idx为预测的正确词义所对应的增强描述的文本跨度开始和结束位置。
[0128]
以上步骤尚未进行训练时,需要进一步执行s4进行训练,以优化模型参数;当训练完毕时,由步骤s3可预测歧义词的正确词义。
[0129]
s4:训练词义消歧模型,如附图4所示。
[0130]
模型使用公开的词义消歧数据集进行训练。
[0131]
s401构建损失函数
[0132]
由步骤s204可知,start为模型预测得到的候选词义所对应的增强描述的文本跨度开始位置的概率,end是模型预测得到的候选词义所对应的增强描述的的文本跨度结束位置的概率;然后对开始和结束位置的概率分别采用交叉熵损失函数,然后将两个损失相加,公式如下:
[0133][0134][0135][0136]
其中,starti、endj分别表示正确候选词义文本跨度开始和结束位置的概率;log代表对数损失函数;exp()表示自然常数e为底的指数函数;startv代表第v个token是候选词义文本跨度开始位置的概率,endv代表第v个token是候选词义文本跨度开始位置的概率;v=1代表第一个token;l代表合并文本中token的数量;分别表示模型预测得到的正确词义所对应的增强描述的文本跨度开始或结束位置的损失。
[0137]
举例说明:在pytorch中,对于上面描述的代码实现如下所示:
[0138]
loss_fct=crossentropyloss()
[0139]
start_loss=loss_fct(start_logits,start_positions)
[0140]
end_loss=loss_fct(end_logits,end_positions)
[0141]
total_loss=(start_loss+end_loss)
[0142]
其中,crossentropyloss()为交叉熵函数;start_loss、end_loss分别为预测的候选词义增强描述的文本跨度开始和结束位置的损失;total_loss为总损失。
[0143]
s402构建优化函数
[0144]
模型经过对多种优化函数进行测试,最终选择使用radam为优化函数作为本模型的优化函数,其学习率初始设置为2e-6,权重衰减设置为0.01。
[0145]
举例说明:上面描述的优化函数及其设置在pytorch中使用代码表示为:
[0146]
optimizer=radam(optimizer_grouped_parameters,lr=0.000002)
[0147]
其中,optimizer_grouped_parameters为要更新的参数;lr为学习率。
[0148]
本发明所提出的模型在公开的词义消歧评估框架上取得了优于当前先进模型的结果,实验结果的对比具体见表1。
[0149]
表1:公开的词义消歧评估框架上的实验结果.
[0150][0151]
本发明模型和现有模型进行了比较,实验结果显示本发明方法有了很大的提升。其中,前四行是现有技术的模型的实验结果,最后一行是本发明模型的实验结果,由此可知
本发明比现有模型有了较大提升。
[0152]
实施例3:
[0153]
如附图3所示,基于实施例2的基于局部自注意力的知识增强的词义消歧装置,该装置包括知识增强模块构建单元、基于局部自注意力的transformer模块构建单元、预测模块构建单元、词义消歧模型训练单元,具体为:
[0154]
知识增强模块构建单元,将歧义词的上下文与从知识本体中检索得到的候选词义的注释、例句等语义知识进行拼接,得到歧义词的上下文和候选词义增强描述的合并文本,简称为合并文本;
[0155]
基于局部自注意力的transformer模块构建单元,通过多层双向编码器、双向解码器的堆叠以实现对合并文本的编码、解码,得到合并文本各token的logits分数;
[0156]
预测模块构建单元,将基于局部自注意力的transformer模块得到的合并文本各token的logits分数,通过softmax、argmax得到正确词义所对应的增强描述的文本跨度,进而判断歧义词的正确词义。
[0157]
词义消歧模型训练单元,用于构建模型训练过程中所需要的损失函数与优化函数,并完成模型的训练;
[0158]
进一步的,所述词义消歧模型训练单元还包括:
[0159]
损失函数构建单元,负责计算预测的歧义词的候选词义开始和结束的文本跨度与歧义词的正确候选词义开始和结束的文本跨度的误差;
[0160]
模型优化单元,负责训练并调整模型训练中的参数,减小预测误差。
[0161]
实施例4:
[0162]
基于实施例2的存储介质,其中存储有多条指令,指令有处理器加载,执行实施例2的基于局部自注意力的知识增强的词义消歧方法的步骤。
[0163]
实施例5:
[0164]
基于实施例4的电子设备,电子设备包括:实施例4的存储介质;以及
[0165]
处理器,用于执行实施例4的存储介质中的指令。
[0166]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1