基于图注意力网络的中医状态辨识方法
1.本发明属于文本分类技术领域,具体涉及一种基于图注意力网络的中医状态辨识方法。
背景技术:
2.随着现代医疗技术的发展,人们对医学的需求已经从治疗疾病转向了保持健康。中国逐渐步入世界舞台中央,中医得到了国家的关注,也开始造福世界各地的人民[1]。近年来,大数据和人工智能的快速发展,使中医管理平台和计算机辅助诊疗越来越智能化[2]。中医健康“状态辨识”理论有效促进了临床治疗,具体的是指从症状组所反应的疾病的程度、部位、性质中提炼出一组状态要素,可见状态要素归纳是中医诊断和治疗过程中尤为关键的一步。状态是对生命局部或整体功能和态势的概括,是掌握人体健康状态的核心[3]。健康状态辨识理论是基于中医诊疗逻辑,根据采集的“望闻问切”四诊信息,对人体当前阶段的症状、辨别发生病变的位置、性质、程度等状态要素进行总结的思维认识过程[4,5]。状态要素可以分为病位(如胃、脾等)和病性(如热、寒等)两种要素[6]。状态要素的本质是归纳总结人体的阴阳相争状态在特定条件下的特点,包括疾病的生理和病理特征,疾病的寒热虚实类型,环境的寒热暑湿等辨症特点[3]。传统的状态辨识方法旨在根据症状对状态要素分类。现有的状态要素归纳方法有两大类,一是基于传统机器学习方法,比如基于类属属性的多标签学习[7,8]。(multi-label learning with label-specific features,lift),多标签k最近邻(multi-label learning k nearest neighbor,ml-knn)、排序支持向量机(rank support vector machines,ranksvm)等方法。二是基于深度学习的分类方法。基于图神经网络的图表示学习可以具体化中医中症状和状态要素、证型等辩证关系,所以本发明使用图注意力网络来实现状态要素归纳的任务。
[0003]
基于状态辨识理论的状态要素归纳问题,在人工智能领域可以抽象为单标签分类和多标签分类[9]。单标签分类准确性不够高,对中医症状的特征表示不够准确。将表征参数症状作为输入特征,将状态要素作为模型的输出标签。因为每一条诊疗记录都有一个及以上的状态要素,故将本研究抽象为多标签分类问题。
[0004]
近年来,多标签文本分类的任务起源于文本分类的深度学习技术。针对状态要素预测任务,广大医生还有学者提出了诸多的图神经网络技术[10]。等人[11]提出的图注意力网络(graph attention network,gat)将注意力机制引入到基于空间域的图神经网络中[12],通过聚合邻居节点的特征训练网络,更新中心节点的特征表示,提高了模型的泛化能力。通过注意力机制,图注意力网络使得每个邻居节点学习不同的注意力权重参数,通过实现对邻居节点的有效聚合实现更高效的特征提取能力。注意力机制已经被证明在众多领域都很有效。在状态要素分类的任务中,并非所有的症状和证型都有助于分类结果,多头注意力机制使不同的症状在最终的节点表示中发挥调节作用,从而提高了分类的精度。
技术实现要素:
[0005]
本发明的目的在于提供一种基于图注意力网络的中医状态辨识方法,该方法能够获得更高的状态元素多标签分类精度。
[0006]
为实现上述目的,本发明的技术方案是:一种基于图注意力网络的中医状态辨识方法,该方法构建状态辨识图注意力网络sigat,具体的,sigat模型用表示学习表征了节点和边缘之间复杂的医学相关性。在该模型中构建了一个症状-证型图,利用图注意力网络实现了归纳状态元素;sigat分为三个模块,即:中医图构建模块、图注意力层构建模块和状态要素预测模块。
[0007]
相较于现有技术,本发明具有以下有益效果:
[0008]
本发明构建了一个中医状态辨识图注意力网络(sigat)模型,获得了更具表达中医诊疗逻辑能力的症状证型综合嵌入表示。本发明的创新点在于引入了中医症状和证型两个中医领域知识,从一个新的角度研究中医状态要素分类归纳的任务,运用图注意力网络建模了处方数据的高阶相关性。该模型的设计不但符合中医“状态辨识”理论,且在状态要素归纳性能上表现突出。在中医领域广泛采用的中医方剂大辞典数据集上的实验,验证了本发明算法的优越性,证实了中医症状和证型构图对中医状态要素多标签分类的作用。
附图说明
[0009]
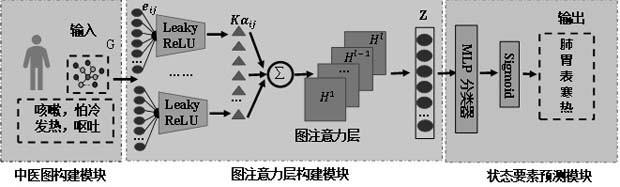
图1为本发明sigat模型结构图。
[0010]
图2为本发明基于中医健康状态辨识的症状-证型图。
具体实施方式
[0011]
下面结合附图,对本发明的技术方案进行具体说明。
[0012]
本发明一种基于图注意力网络的中医状态辨识方法,该方法构建状态辨识图注意力网络sigat,具体的,sigat模型用表示学习表征了节点和边缘之间复杂的医学相关性。在该模型中构建了一个症状-证型图,利用图注意力网络实现了归纳状态元素。
[0013]
以下为本发明具体实现过程。
[0014]
本发明提出了一种图注意力网络应用于中医健康状态辨识叫做sigat,如图1所示,sigat模型主要分为三个模块,中医图构建模块、图注意力层构建模块和状态要素预测模块。
[0015]
1、中医图构建模块
[0016]
首先我们介绍基于中医知识的图构建,假设中医处方样本总数为m,我们定义症状集v,其中症状的类别数为n,定义证型集为e,状态要素集为y,状态要素总的类别数有l个。
[0017]
对于每一条中医处方,首先将症状、证型和状态要素多热编码,将其转化为一维的向量。我们构建的图数据是一系列的相互连接的代表中医症状的节点,中医证型构造的边关系含有中医状态辨识理论知识。如图2所示,图中实线关系表示症状之间的节点连接,表示这两种症状存在于同一证型中,在图表示中为1。如果两个节点之间的关系为0,则这是两个不相关的症状节点。每个症状节点都包含独特的特征,其中表示第i个节点的特征。我们定义一个图结构g=(v,e)。
[0018]
2、注意力层构建模块
[0019]
图注意力模型的核心思想是对于图中任何一个节点特征的生成都需要关注其不同节点的贡献程度,学习该节点和其他邻居节点之间的相关性,从而分配不同的权重系数
[11]
。本节首先介绍单个图注意力层,然后堆叠多个图注意力层,进行sigat模型构建。
[0020]
1)注意力系数计算
[0021]
设图注意力层的输入是所有节点的特征h,其中n是节点(症状)的总个数,f是节点特征的原始维度。该层的目标是聚合结点的邻居信息得到新的节点特征表示,首先计算某单一节点i的注意力系数,假设它有一个邻接点j∈ni经过线性变换后分别是whi和whj,则邻接点对该节点i的注意力系数是:
[0022]eij
=a([whi||whj]),j∈niꢀꢀꢀꢀꢀꢀꢀ
(1)
[0023]
其中,w是线性映射的共享参数,它对节点的特征进行了增强,[
·
||
·
]对于节点i,j变换后的特征进行了拼接,最后a(
·
)把拼接后的高维特征映射到一个实数上,显然通过可学习的参数w和映射a(
·
),e
ij
可以表示相邻节点j对于中心节点i新特征的重要性,学习到了节点i,j之间的相关性。
[0024]
当节点i有多个邻接点时,我们将相关系数做了归一化处理,避免了注意力系数过大而导致不利于训练的问题,同时为了泛化模型的拟合能力,对线性变化后的值可以加入非线性激活函数为leakyrelu(
·
),最终得到的注意力系数计算公式为
[11]
:
[0025]
α
ij
=leakyrelu(e
ij
)
ꢀꢀꢀꢀꢀ
(2)
[0026]
然后对邻居节点特征进行加权求和,得到新的节点特征
[12]
:
[0027][0028]hi
是图注意力层输出,它对于每个顶点i融合了邻域信息的新特征,σ(
·
)是激活函数。如上所述可得单层的图注意力层特征。
[0029]
2)多头注意力机制
[0030]
使用k个独立的注意力机制,可以得到不同子空间的特征信息。在每一层图注意力层中,计算出k个独立的转换矩阵wk,根据公式(3)并行的计算多个子空间的注意力信息,然后将他们拼接起来,然后将得到的结果再次拼接
[13]
:
[0031][0032]
其中,是通过第k个转换矩阵w
(k)
计算得到的权重系数,这会导致hi有更高的维度(1,kd'),所以只可以做中间层而不可以做输出层。对于输出层,一种聚合方式是将各注意力机制h'加权平均。
[0033]
3)注意力层聚合
[0034]
以上操作得到单层症状节点及其邻近节点的注意力系数之后,模型聚合多个图注意力层,得到最后的节点表示
[14]
:
[0035][0036]
其中,l表示网络层数,显然第一层的特征h是初始症状特征v,即h
(0)
=v。图注意力层将症状邻居节点的特征聚合到中心症状节点上,利用图上证型的连接策略学习新的节点特征表达。最后,定义每条诊疗处方其症状组的特征为x,将图嵌入表示定义为:
[0037][0038]
3、状态要素预测模块
[0039]
利用图注意力机制获取症状和证型的图嵌入表示z后,在输出层设置感知机分类器的全连接层和sigmoid函数,每一个神经元对应一个标签,即:
[0040]
y=sigmoid(wz)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0041]
其中,w为可训练的模型参数,sigmoid函数将输出值转为概率,网络训练时使用的交叉熵损失函数
[15,16]
:
[0042][0043]
其中,l为网络输出层神经元个数,即数据集样本中状态要素标签的种类数,yi∈{0,1}表示标签的真实值。y'i∈[0,1]表示预测概率值。
[0044]
4、实验设置
[0045]
1)数据集
[0046]
为验证本发明方法的有效性,在真实中医方剂大辞典数据集上进行了实验。该数据集由yao[17]等人公开,其处方数据出自中医学的著作《中医方剂大辞典》。规范处理后的数据集还保留2685条处方,其中共包括症状298种、状态要素69种、证型747种,参见表1。
[0047]
表1数据集统计信息
[0048][0049]
2)实验环境
[0050]
本研究的实验基于python3.7环境,使用pytorch进行编程实现。实验设备的处理器为intel(r)core(tm)i7-10750h,显卡为nvidia 1650ti,操作系统为windows10。
[0051]
3)对比算法
[0052]
本研究使用以下几种方法来进行对比实验。
[0053]
支持向量机(support vector machines,svm):将支持向量机的核函数设为高斯核,核系数为0.3,松弛系数的惩罚项系数设为3。
[0054]
贝叶斯算法(bayesian network,nb):多元伯努利模型的朴素贝叶斯分类器将样本特征二值化(映射为布尔值)的阈值,平滑参数设置为1。
[0055]
k近邻算法(k nearest neighbors,knn):查找使用的邻居数为10,选取最近的10个点,构造的ball树和kd树的大小为3。
[0056]
随机森林算法(random forests,rf):森林里(决策)树的数目设置为10,分割内部节点所需要的最小样本数量设为2,需要在叶子结点上的最小样本数量为1。
[0057]
4)评价指标
[0058]
评价指标在本发明中,选用了多标签分类常用的7个评价指标,分别是汉明损失、覆盖误差、0/1误差、排序损失、平均精度、宏平均f1分数和微平均f1分数,将中医方剂大辞典数据集中样本总数为m,总的状态要素标签集为y,其类别总数定义为l,对于任意样本xi,y'i表示预测标签集,yi表示样本对应的真实标签集,ri(λ)表示在所有预测出来的标签中标签λ的排序位置。这些指标的定义如下所示:
[0059]
汉明损失(hamming loss,hloss)用以衡量标签被错分的次数,表示属于某个处方症状的状态要素标签没有被预测,即错分类,以及不属于该处方的状态要素标签被预测为属于该处方,即误分类。它能够表示所有标签中错误样本的比例,所以该值越小则网络的分类能力越强。δ计算实际标签和预测标签的对称差,即错分类和误分类的标签个数,计算公式如下
[18]
:
[0060][0061]
覆盖误差
[19]
(coverage error)表示状态要素标签的预测概率按照从大到小排序,所需要的覆盖真实标签的概率值平均值,maxri(λ)表示真实标签在预测标签中的排名,同样该值越小表示网络预测性能越高,计算公式如下:
[0062][0063]
0/1误差(0/1error)表示在预测样本的标签排序中,排名最高的标签不在实例的相关标签集中的次数,定义argmaxri(λ)函数表示样本xi中排位靠前的的标签,当预测标签λ不在yi中,即预测错误则δ(λ)=1;若预测正确则δ(λ)=0。0/1误差越小说明预测误差越小,性能越好,其计算公式为
[20]
:
[0064][0065]
排序损失(ranking loss,rloss)表示不相关标签的排名高于相关标签的次数,是样本不包含的标签集,yi是样本包含的标签集。对于不属于该样本的标签λb,其概率排名ri(λb)高于相关标签λa的概率ri(λa)的次数。排序损失越低说明不相关标签被预测靠前的次数更少,意味着真实相关标签预测正确性越高,计算公式如下
[21]
:
[0066][0067]
平均精度(average precision,ap)是指在预测处方的排序标签中,排在预测样本相关标签前面的也是实际相关标签yi的概率平均,对于预测标签λ',ri(λ')为预测样本的概率排名,ri(λ)为样本真实标签的排名。平均精度越大说明预测出来的标签越相关,当其值为1时达到最好性能,具体的计算公式如下
[20]
:
[0068][0069]
macro-f1考虑状态要素标签之间的差异性,首先计算所有的类别的宏平均精确度和宏平均召回率,再计算macro-f1宏平均f1分数。
[0070][0071]
micro-f1不考虑标签之间的差异,是对数据集中的每一个实例不分类,建立全局混淆矩阵,然后计算所有类别的微平均精确度和微平均召回率,从而得到micro-f1微平均f1分数:
[0072][0073]
2、实验结果和分析
[0074]
本发明分析了所提出的sigat模型的有效性,包括不同训练集比例的定量实验、与基线方法的对比试验和状态要素归纳的案例分析实验。
[0075]
首先我们将根据不同的训练数据集切分比例,来评估sigat模型的有效性。将数据集按照训练集比重分别50%,60%,70%,80%,90%进行实验,结果如表2所示,训练集80%时网络训练的汉明损失最小达到0.1060,0/1误差最小值为0.2486。训练集占70%比重时,覆盖损失最小21.9862,排序损失最小0.0858,平均精度最高达到65.92%,宏平均f1分数最高34.60%,微平均f1分数最高58.29%。
[0076]
表2 sigat模型在不同比例的训练数据集上的实验结果。
[0077][0078]
训练集80%比例时,各种对比算法的实验结果如表3所示:sigat模型在汉明损失方面性能仅高于最低的svm算法0.0075,在覆盖损失、排序损失和0/1误差方面均低于对比算法,且平均精度是最高的,65.69%高于对比算法3%-10%,宏平均f1分数30.94%高于对比算法1%-13%,微平均f1分数高于对比算法6%-10%。
[0079]
表3与基线方法的比较的实验结果
[0080]
algorithmsvmnbknnrfgathloss0.09850.10030.10260.10430.1060coverage25.031725.438039.117445.243623.3618rloss0.10180.10180.18300.21530.09330/1error0.29980.28100.29910.33700.2486
ap0.63480.63920.57350.55920.6569macro-f10.30000.21760.17120.28400.3094micro-f10.51180.46050.37610.47180.5759
[0081]
如表4所示,sigat模型正确地预测了以粗体字体显示的状态要素。案例1中,根据症状大便溏,浮肿,身重,恶寒,自汗,中医中这些症状是脾肾阳虚证的表现,归纳为气虚、脾、湿、阳虚,我们的模型预测标签是脾、寒、湿、阳虚、表,只有气虚这一要素没有被正确预测到。再如案例2中,标签中的四个状态元素都被sigat正确地预测。
[0082]
表4中医状态辨识的案例研究
[0083][0084]
参考文献:
[0085]
[1]徐佳君,罗志明,赵文,雷黄伟,周常恩,李绍滋,李灿东.基于人工智能算法的中医状态辨识规则[j].中医杂志,2020,61(03):204-208.
[0086]
[2]梁文娜,林雪娟,俞洁,闵莉,李灿东.真实世界的大数据助推中医健康管理进入人工智能时代[j].中华中医药杂志,2018,33(04):1213-1215.
[0087]
[3]陈姝婷,王洋.以状态辨识为核心的中医健康管理模式探析[j].亚太传统医药,2019,15(11):165-166.
[0088]
[4]李灿东,杨雪梅,甘慧娟,赖新梅,周常恩,陈梅妹,健康状态辨识模型算法的探讨[j].中华中医药杂志,2011,26(06):1351-1355.
[0089]
[5]wen zhao,weikai lu,zuoyong li,chang`en zhou,haoyi fan,zhaoyang yang,xuejuan lin,candong li,tcm herbal prescription recommendation model based on multi-graph convolutional network,journal of ethnopharmacology,2022,115109,issn0378-8741.
[0090]
[6]冯世纶.经方辨证依据症状反应[j].中华中医药杂志,2021,36(01):22-26.
[0091]
[7]辛基梁.基于中医状态学理论的健康状态辨识算法研究[d].福建中医药大学,2020.
[0092]
[8]辛基梁,张佳,李绍滋,李灿东.中医健康状态辨识中的多标记分类方法研究[j].中华中医药杂志,2019,34(09):3952-3955.
[0093]
[9]辛基梁,李绍滋,张佳,雷黄伟,李灿东.中医健康状态辨识方法的探索[j].中华中医药杂志,2019,34(07):3151-3153.
[0094]
[10]fan,h.,zhang,f.,wei,y.,li,z.,zou,c.,gao,y.,and dai,q,heterogeneous hypergraph variational autoencoder for link prediction,ieee transactions on pattern analysis and machine intelligence,2021.
[0095]
[11]p,cucurull g,casanova a,et al.graph attention networks[j].arxiv preprint arxiv:1710.10903,2017.
[0096]
[12]yuntao shi,kai zhou,shuqin li,meng zhou,and weichuan liu,heterogeneous graph attention network for food safety risk prediction,journal of food engineering,volume 323,2022,111005,issn 0260-8774.
[0097]
[13]潘明玥.基于图注意力网络的社交推荐系统研究[d].东北师范大学,2021.
[0098]
[14]聂听.基于图注意力网络的短文本分类研究[d].华中科技大学,2020.
[0099]
[15]fan,h.,zhang,f.,xi,l.,li,z.,liu,g.,and xu,y.,leukocytemask:an automated localization and segmentation method for leukocyte inblood smear images using deep neural networks,journal ofbiophotonics,2019,12(7),e201800488.
[0100]
[16]fan,h.,zhang,f.,wang,r.,huang,x.,li,z.:semi-supervised time series classification by temporal relation prediction,in proceedings of the ieee international conference on acoustics,speech and signal processing 2021,pp.3545
–
3549.
[0101]
[17]l.yao,y.zhang,b.wei,w.zhang,z.jin,a topic modeling approach for traditional chinese medicine prescriptions,ieee transactions on knowledge and data engineering,30(6):1007-1021,2018.
[0102]
[18]song,z.,li,y.,li,d.,li,s.:multi-label classification of legal text with fusion of label relations.pattern recognition andartificial intelligence 2022,35(2),185
–
192.
[0103]
[19]min-ling zhang,lei wu.lift:multi-label learning with label-specific features.ieee trans patternanal mach intell.2015 jan;37(1):107-20.
[0104]
[20]tsoumakas,g.,katakis,i.,&vlahavas,i.(2010).mining multi-label data.in data mining and knowledge discovery handbook(pp.667-685).springer us.。
[0105]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1