一种深度信息引导的多风格人脸素描生成方法
1.本发明涉及图像处理,具体提到了一种深度信息引导的多风格人脸素描生成方法(face2 sketch generation guided by facial depth map)的新方法,主要涉及一种利用人脸深度信息和风格特征,以构建一个与真实绘画效果更加一致的多风格人脸素描生成模型。
背景技术:
2.图像生成的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、梯度图、彩色图之间的转换等。特别地,在人脸图像生成领域,有人脸铅笔画、钢笔画的生成等应用。人脸素描生成的本质也是图像生成问题,最终目标是完成一张人脸照片到对应的素描图像的高质量转换。
3.目前比较流行的人脸图像生成算法如pix2pix、genre、cyclegan等,他们能够较好地实现人脸素描的生成,但是其生成的素描图像质量不高,在人脸局部细节的生成效果依然有很大的提升空间。比如,这些方法可能无法处理一些特殊的外观变化,如姿势、灯光、表情和皮肤颜色等。此外,这些方法只适用于单风格素描图像的生成问题,无法解决不同风格素描的生成问题。
技术实现要素:
4.本发明的目的是针对人脸素描生成质量的问题,深度信息引导的多风格人脸素描生成方法。
5.本发明解决其技术问题提供一种深度信息引导的多风格人脸素描生成方法,包括如下步骤:
6.步骤(1)构建数据集并对数据集中的图像数据进行预处理
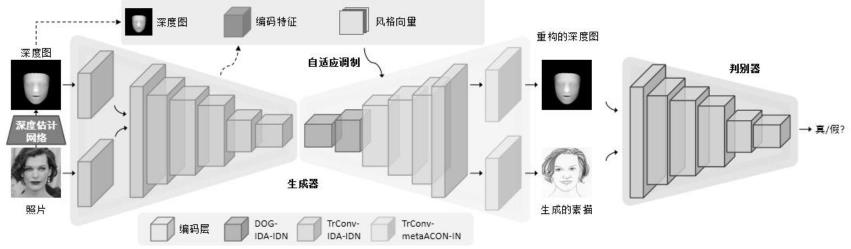
7.步骤(2)构建生成对抗网络模型并生成人脸素描
8.2-1生成器构建并生成特征向量
9.生成器g的结构遵循了经典的u-net结构,将第i个编码层的输出和对应的第i个解码层的输出连接起来,每个编码层包括卷积层、动态激活层、实例规范化层;每个解码层包括上采样卷积、动态自适应激活层、动态自适应调制层;
10.2-2通过深度和风格自适应归一化处理;
11.2-3自适应动态激活
12.2-4可变形轮廓生成
13.2-5判别器构建并输出
14.判别器内部由6个层级组成,分别由卷积层、实例规范化层、激活层,判别器的输入是一个由人脸深度图和人脸素描按通道连接后的向量,对于人脸深度图和真实的人脸素描,判别器输出为true;对于人脸深度图和生成的人脸素描,判别器输出为false;
15.步骤(3)生成对抗网络模型的训练
16.定义损失函数,训练生成对抗网络模型;
17.步骤(4)人脸素描的生成及质量评价
18.将待生成素描的人脸照片输入到训练后的生成对抗网络模型中,得到对应的人脸素描图像,并根据指标完成质量评价。
19.作为优选,所述预处理的方法为:将数据集中人脸照片、人脸素描进行人脸对齐、缩放和裁剪处理,再将数据集的人脸照片根据3ddfa方法生成对应的深度图像,最终得到一一对应的人脸照片-人脸素描-人脸深度图三元组。
20.作为优选,预处理后所述人脸照片的大小为250*250,通道数为3;人脸素描的大小为250*250通道数为1;人脸深度图的大小为250*250通道数为1。
21.作为优选,所述生成器中,其中前两层解码层,使用的是可变形卷积。
22.作为优选,所述生成器生成的特征向量包括人脸的深度信息d、人脸风格信息s和人脸外表特征a。
23.作为优选,所述深度和风格自适应归一化处理方法如下:
24.通过缩放和偏置来调制特征,使用了人脸的深度信息d、人脸风格信息s和经过编码器提取的人脸外表特征a,假设f∈rc×h×w表示当前idn模块的输入特征,其中h,w,c分别表示特征的高度、宽度和通道数,那么在c,h,w位置调制后的特征值为:
[0025][0026]
其中,f
c,h,w
和分别是idn模块输入前后的特征值,μc和σc分别为第c个通道中f
c,h,w
的平均值和标准差:
[0027][0028][0029]
其中,γ
c,h,w
(d,s,a)和β
c,h,w
(d,s,a)分别是通过浅层神经网络学习得到的缩放和偏置的参数,具体的计算过程如下:
[0030]
γ=conv(metaacon(conv(cat(d,s,a)))),
[0031]
β=conv(metaacon(conv(cat(d,s,a))))。
[0032]
作为优选,所述自适应动态激活方法如下:
[0033]
根据3d几何图形、2d外观和样式类型来决定是否绘制一个笔画得到启发,改进了现有的metaacon动态激活函数,使得参数θ根据人脸的深度信息d、人脸风格信息s和经过编码器提取的人脸外表特征a进行动态学习,原始的动态激活函数metaacon如下:
[0034]
y=(p
1-p2)
·
σ(θ(p
1-p2)x)+p2x
[0035]
其中,y代表激活后的输出,θ=σ(x),σ是一个sigmoid函数,p1和p2是可学习的参数;而自适应动态激活函数ida如下:
[0036]
θ=σ(θ(cat(d,s,a))),
[0037]
y=(p
1-p2)
·
σ(θ(p
1-p2)x)+p2x
[0038]
其中,σ代表一个浅层的神经网络。
[0039]
作为优选,所述可变形轮廓生成方法如下:
[0040]
完成的人脸素描画像与真实照片间存在几何变形,在粗尺度上进行特征对齐,在解码层的前两层使用可变形卷积代替标准的转置卷积,首先通过双线性差值将输入的特征放大两倍,然后将其输入到一个可变形卷积层,这个模块显著提高了生成轮廓的清晰度。
[0041]
作为优选,所述步骤(3)中定义的损失函数如下:
[0042][0043][0044][0045][0046][0047][0048][0049]
l
all
=l
adv
+λ1×
l
pix
+λ2×
l
geo
+λ3×
l
tex
[0050]
其中,ys表示真实的人脸素描画图像,表示模型生成的人脸素描画图像,d表示真实的人脸深度图像,表示模型重构出来的人脸深度图像,g
i,j
代表了ys在坐标(i,j)位置x方向和y方向的梯度,g
i,j
代表了在坐标(i,j)位置x方向和y方向的梯度,d(d,ys)表示输入为d和ys时判别器的输出结果,表示输入为和时判别器的输出结果;m和n代表素描的宽度和高度;
[0051]
l
adv
表示生成对抗损失函数,l
pix
表示生成的素描和真实素描之间的像素级差距,由和ys之间的l1距离得到;l
geo
表示重构的深度图和真实的深度图之间的像素级差距,由和d之间的l1距离得到;l
tex
表示纹理损失,要求生成的素描具有与真实素描相似的纹理;l
all
表示总的损失函数,它由l
adv
和l
pix
、l
geo
、l
tex
三个损失函数分别乘权重λ1、λ2、λ3求和得到。
[0052]
作为优选,所述步骤(4)中生成及质量评价方法:
[0053]
依次将数据集中的人脸照片输入到训练后的对抗生成网络模型中,得到生成的人脸素描画图像,并将生成的图像与真实的素描做fid指标的计算,完成生成素描的质量评价。
[0054]
本发明有益效果如下:
[0055]
与现有的人脸素描生成方法相比,使用本发明所述的的一种深度信息引导的多风格人脸素描生成方法,在人脸素描生成的质量上有了很大程度的提高,特别是在一些局部的笔触细节上能够生成更真实的效果,此外本方法可以生成不同风格的人脸素描。下表是本方法和图像生成领域的一些现有方法在生成人脸素描画生成结果上计算的各项指标对比情况,其中,fid、lpips指标数值越低代表生成质量越高,scoot、fsim指标数值越高代表生成质量越高。
附图说明
[0056]
图1是人脸素描生成对抗网络模型的体系结构图。
[0057]
图2是人脸素描生成器编码器层的体系结构图。
[0058]
具体实施细节
[0059]
下面结合附图对本发明做进一步说明。
[0060]
如图1、图2所示,一种深度信息引导的多风格人脸素描生成方法,具体包括如下步骤:
[0061]
步骤(1)数据预处理
[0062]
将人脸照片、人脸素描进行人脸对齐、缩放和裁剪等处理,再将数据集的人脸照片根据3ddfa方法生成对应的深度图像,最终得到一一对应的人脸照片-人脸素描-人脸深度图三元组;
[0063]
具体的,1-1选择fs2k数据集,按照官方数据集划分方法,选取1058张人脸照片和对应的素描画图像作为训练集,其余1046张的人脸图像和对应的素描画图像作为测试集。其中风格1具有357张人脸图像和对应的素描画图像作为训练集和619张人脸图像和对应的素描画图像作为测试集;风格2具有351张人脸图像和对应的素描画图像作为训练集和381张人脸图像和对应的素描画图像作为测试集;风格3具有350张人脸图像和对应的素描画图像作为训练集和46张人脸图像和对应的素描画图像作为测试集;
[0064]
1-2对数据集中的图像(包括人脸照片和素描画图像)进行预处理,先将图像进行关键点对齐,再插值缩放到250*250大小,其中人脸照片的通道数为3,素描画图像的通道数为1;
[0065]
1-3将1-2预处理后数据集中的人脸照片根据3ddfa深度生成方法,生成对应的人脸深度图像;该图像具有与人脸照片相同的大小250*250,通道数为1,图像中像素值的大小代表了该位置的深度信息。
[0066]
步骤(2)生成对抗网络模型的构建
[0067]
具体的,生成对抗网络模型包括生成器和判别器,生成器采用编码器-解码器结构,判别器为卷积神经网络;
[0068]
2-1生成器构建
[0069]
生成器g的结构遵循了经典的u-net结构。我们将第i个编码层的输出和对应的第i个解码层的输出连接起来。每个编码器层由卷积层(conv)、动态激活层(metaacon)、实例规范化层(in),即(conv-metaacon-in)组成。每个解码器层由上采样卷积(trconv/dog)、动态自适应激活层(ida)、动态自适应调制层(idn)、模块,即(trconv/dog-ida-idn)组成。其中前两层解码层,使用的是可变形卷积(dog),其余层使用的是普通卷积(trconv)。
[0070]
2-2深度和风格自适应归一化模块
[0071]
第一,为了更好地调制神经元,我们实现了一种深度和风格自适应归一化的调制模块(depth and style adaptive normalization,idn)。我们通过缩放和偏置来调制特征,与现有的spade自适应归一化调制不同的是,我们使用了人脸的深度信息d、人脸风格信息s和经过编码器提取的人脸外表特征a。假设f∈rc×h×w表示当前idn模块的输入特征,其中h,w,c分别表示特征的高度、宽度和通道数,那么在(c,h,w)位置调制后的特征值为:
[0072][0073]
其中,f
c,h,w
和分别是idn模块输入前后的特征值,μc和σc分别为第c个通道中f
c,h,w
的平均值和标准差:
[0074][0075][0076]
特别得,这里的γ
c,h,w
(d,s,a)和β
c,h,w
(d,s,a)分别是通过浅层神经网络学习得到的缩放和偏置的参数,具体的计算过程如下:
[0077]
γ=conv(metaacon(conv(cat(d,s,a)))),
[0078]
β=conv(metaacon(conv(cat(d,s,a))))
[0079]
2-3自适应动态激活模块
[0080]
我们从艺术画家根据3d几何图形、2d外观和样式类型来决定是否绘制一个笔画得到启发,改进了现有的metaacon动态激活函数,实现了一个自适应动态激活模块(informative and dynamic activation,ida)使得参数θ根据人脸的深度信息d、人脸风格信息s和经过编码器提取的人脸外表特征a进行动态学习。原始的动态激活函数metaacon如下:
[0081]
y=(p
1-p2)
·
σ(θ(p
1-p2)x)+p2x
[0082]
其中,y代表激活后的输出,θ=σ(x),σ是一个sigmoid函数,p1和p2是可学习的参数;而自适应动态激活函数ida如下:
[0083]
θ=σ(θ(cat(d,s,a))),
[0084]
y=(p
1-p2)
·
σ(θ(p
1-p2)x)+p2x
[0085]
其中,σ代表一个浅层的神经网络(conv-metaacon-conv)。
[0086]
2-4可变形轮廓生成模块
[0087]
我们观察到艺术家完成的人脸素描画像与真实照片间存在几何变形,为了模拟艺术家抽象的绘图方式,我们设计了可变形轮廓生成模块(deformable outline generation,dog),在粗尺度上进行特征对齐。我们在解码层的前两层使用可变形卷积(dcn)代替标准的转置卷积。具体地,我们首先通过双线性差值将输入的特征放大两倍,然后将其输入到一个可变形卷积层,这个模块显著提高了生成轮廓的清晰度。
[0088]
2-5判别器构建
[0089]
判别器的输入是一个由人脸深度图和人脸素描(真实素描ys/生成素描)按通道连接后的向量。判别器内部由6个层级组成,分别由卷积层(conv)、实例规范化层(in)、激活层(leakyrelu),即(conv-in-leakyrelu)组成。这里要求判别器,对于人脸深度图和真实的人脸素描,判别器输出为true;对于人脸深度图和生成的人脸素描,判别器输出为false。
[0090]
步骤(3)生成对抗网络模型的训练
[0091]
定义损失函数,训练生成对抗网络模型;
[0092]
3-1对生成对抗网络进行训练时,当损失函数达到最小时,生成对抗网络训练完成;所述损失函数如下:
[0093][0094][0095][0096][0097][0098][0099][0100]
l
all
=l
adv
+λ1×
l
pix
+λ2×
l
geo
+λ3×
l
tex
[0101]
其中,ys表示真实的人脸素描画图像,表示模型生成的人脸素描画图像,d表示真实的人脸深度图像,表示模型重构出来的人脸深度图像,g
i,j
代表了ys在坐标(i,j)位置x方向和y方向的梯度,g
i,j
代表了在坐标(i,j)位置x方向和y方向的梯度,d(d,ys)表示输入为d和ys时判别器的输出结果,表示输入为和时判别器的输出结果;m和n代表素描的宽度和高度。
[0102]
l
adv
表示生成对抗损失函数,这里使用的是cross entropy loss;l
pix
表示生成的素描和真实素描之间的像素级差距,由和ys之间的l1距离得到;l
geo
表示重构的深度图和真实的深度图之间的像素级差距,由和d之间的l1距离得到;l
tex
表示纹理损失,要求生成的素描具有与真实素描相似的纹理;l
all
表示总的损失函数,它由l
adv
和l
pix
、l
geo
、l
tex
三个损失函数分别乘权重λ1、λ2、λ3求和得到。在训练过程中,我们训练生成器g和鉴别器d,l
all
以使最小化。
[0103] fidlpipsscootfsimpix2pix18.340.3040.4930.541
pix2pixhd32.030.4680.3740.531cyclegan26.490.5050.3480.501mdal50.180.4920.3550.530sca-gan39.630.3050.6000.782fsgan34.880.4830.4050.610genre20.670.3020.4830.534ours15.060.2630.5750.551
[0104]
步骤(4)人脸素描的生成及质量评价
[0105]
将待生成素描的人脸照片输入到训练后的生成对抗网络模型中,得到对应的人脸素描图像,并根据指标完成质量评价;
[0106]
具体的,依次将测试集中的人脸照片输入到训练后的对抗生成网络中,得到生成的人脸素描画图像,并将生成的图像与真实的素描做fid、lpips、scoot、fsim等指标的计算,完成生成素描的质量评价。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1