一种基于集成学习的油井示功图自动诊断方法
1.本发明属于油井示功图故障诊断技术领域,具体涉及一种基于集成学习的油井示功图自动诊断方法。
背景技术:
2.抽油机是大多数油田的生产作业中的主要举升设备,由于其杆、管、泵在地下深处较为恶劣的环境中工作,加上生产过程中油藏环境的动态改变,导致工况复杂,使得抽油机故障频发。及时准确地判断井下工况,进而分析抽油机运转状态和产量变化原因有助于生产人员及决策者及时作出油井管理运行决策,从而在一定程度上避免油井工况进一步恶化,达到提高和优化生产效率的目的;
3.油井示功图反映的是抽油机悬点载荷随位移的变化,通过分析示功图的几何形状判断抽油机井下工况是一种常用的方法。传统示功图分析通常由人工对现场采集的示功图识别然后来判断井下的工况如何,再由现场工程师根据结果提出相应措施。随着自动化技术的不断迭代更新和油田企业对自动化、数字化的重视,基于机器学习的示功图诊断方法得到进一步发展与应用。传统方法大多针对典型功图的识别来区分常见的井下工况,然而实际生产中存在不典型的复杂示功图,这些复杂功图可能代表井下多种单一工况或复合工况,例如单一工况有泵上挂、泵下碰、油管漏失、柱塞脱出泵筒等,复合工况有油井出砂和振动、双阀漏失和供液不足等。这在复杂工况的示功图具有相似性,功图形状的细微变化代表着不同的井下工况。仅实现几种典型示功图的识别无法全面准确地构建油井示功图自动诊断模型,更不可能掌握全部实时生产工况。因此,实现精确的油井的示功图实时自动诊断是当前油井故障自动诊断的一个挑战,但从目前诊断的效果来看,故障的误报、漏报率依然较高。
技术实现要素:
4.本发明的目的是提供一种基于集成学习的油井示功图自动诊断方法,解决了目前油井故障自动诊断中故障的误报、漏报率较高的问题。
5.本发明所采用的技术方案是,
6.一种基于集成学习的油井示功图自动诊断方法,具体按照如下步骤进行:
7.步骤1:采集历史数据构建示功图数据库,对示功图数据库中的数据进行数据预处理及数据清洗;
8.步骤2:基于采油工程理论及典型示功图,对示功图进行特征提取;
9.步骤3:基于原始数据及生成数据将数据划分为训练数据集、验证数据集以及测试数据集;
10.步骤4:采用集成学习构建、结合bagging算法和决策树生成随机森林模型,进而对数据进行分类;
11.步骤5:将验证数据集输入到随机森林模型中,并利用错分率、计算效率、准确率和
召回率对示功图自动诊断结果进行评价;
12.步骤6:实时采集示功图数据,利用随机森林模型对示功图进行实时的自动诊断、判断故障原因。
13.本发明的特点还在于;
14.步骤1中,数据清洗包括重复数据处理、错误数据处理以及残缺数据处理,其中:
15.步骤1.1:对于错误数据,将数据进行一致性检测,不一致时通过数据修改使数据统一,重复检测和修改过程直到符合要求,输出数据;
16.步骤1.2:对于重复数据,采用直接去除重复数据;
17.步骤1.3:对于残缺数据,计算残缺数据x
缺
与其他数据xi的欧式距离:
18.dist=‖x
缺-xi‖2i=1,2,
…
,n
ꢀꢀꢀꢀꢀꢀ
(1);
19.对欧式距离dist进行排序,找到与残缺数据欧式距离最小的数据:
20.(x
min
,y
min
)=arg min dist
ꢀꢀꢀꢀꢀꢀ
(2);
21.其中,x
min
为欧式距离dist最小的数据特征,x
min
是对应欧式离
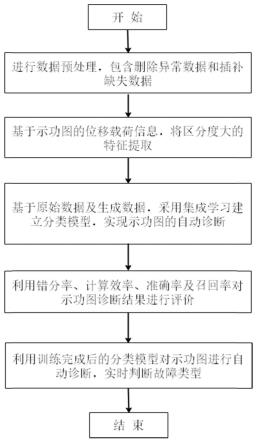
22.dist最小的数据类别标签;
23.将该数据对应的标签作为残缺标签数据的标签。
24.步骤2中,提取的特征包括:采油工程特征和示功图几何特征。
25.步骤3中,训练数据集用于帮助训练模型,即通过训练集的数据确定拟合曲线的参数;验证数据集用于做模型选择,即做模型的最终优化及确定,辅助构建模型;测试数据集用于测试已经训练好的模型的精确度。
26.步骤4中,bagging算法具体为:该算法训练多轮,每轮的训练集由从初始的训练数据中随机取出的n个训练样本组成,基于每个初始的训练数据在某轮训练集中可以出现多次或不出现,训练之后得到一个预测函数序列。
27.步骤4中,随机森林算法具体流程为:
28.从样本集中有放回随机采样选出n个样本;
29.从所有特征中随机选择k个特征,对选出的样本利用k个特征建立决策树;
30.重复上述两个步骤m次,生成m棵决策树,形成随机森林;
31.对于数据,经过每棵决策树的决策,最后投票确认新数据的分类。
32.步骤4中,随机森林模型中生成每棵决策树的规则是:
33.对于包含m个样本的原始数据集,通过自助采样得到同样包含m个样本的训练集;
34.每个样本有d个特征,那么选择一个小于d的整数,随机地从d个特征中选择k个特征,然后决策树在每个结点上进行分裂时,从k个特征中选择最优的;
35.每棵决策树都生长到最大深度,不进行剪枝;
36.其中,k值控制了随机森林的随机程度:当k=d时,随机森林中基决策树的生成过程和传统决策树相同;当k=1时,则随机选择一个属性进行划分,将k设置为d为特征数。
37.本发明的有益效果是,本发明一种基于集成学习的油井示功图自动诊断方法,通过探索性数据分析,除了示功图的基本指标外,还找到区分度较大的几个特征,上面积、下面积、最大载荷等从而使得特征对识别示功图中油井可能提示的故障更具意义;利用集成
学习将bagging和决策树结合起来形成随机森林模型,这一模型的特点在于泛化能力较强,能处理高维度的数据,偶尔丢失个别特征不会影响整体准确度,且计算速度较快,最终实现对示功图故障类型的有效诊断。本发明能够显著提高分类模型对示功图自动诊断的能力,降低错分率,提高计算效率。
附图说明
38.图1是本发明一种基于集成学习的油井示功图自动诊断方法的流程示意图;
39.图2是本发明一种基于集成学习的油井示功图自动诊断方法中随机森林模型的基本流程图。
具体实施方式
40.下面结合附图和具体实施方式对本发明一种基于集成学习的油井示功图自动诊断方法进行详细说明。
41.本发明一种基于集成学习的油井示功图自动诊断方法,首先基于采油工程理论及典型示功图的特点,对示功图进行特征提取。其次采用集成学习构建和结合bagging和决策树来生成随机森林模型从而对数据进行分类,将验证数据集输入到学习完成后的分类模型中,并利用错分率、计算效率、准确率和召回率对示功图自动诊断结果进行评价。最后实时采集示功图数据,利用学习完成的分类模型对示功图进行实时的自动诊断判断故障原因。
42.如图1所示,一种基于集成学习的油井示功图自动诊断方法,包括如下步骤:
43.步骤1、采集历史数据构建示功图数据库,对示功图数据库中的数据进行数据预处理及数据清洗。遇到残缺数据这类异常数据使用删除或插补的进行处理,处理时根据具体情况合理选择删除或者插补方法,具体方法如下:
44.步骤1.1.对于错误数据,将数据进行一致性检测,不一致时通过数据修改使数据统一,重复检测和修改过程直到符合要求,输出数据;
45.步骤1.2.对于重复数据则直接去除重复数据;
46.步骤1.3.对于残缺数据,通常采用以下过程:
47.a.计算残缺数据x
缺
与其他数据xi的欧式距离:
48.dist=‖x
缺-xi‖2i=1,2,
…
,n
ꢀꢀꢀꢀꢀꢀ
(1);
49.b.对欧式距离dist进行排序,找到与残缺数据欧式距离最小的数据:
50.(x
min
,y
min
)=argmindist
ꢀꢀꢀ
(2);
51.其中,x
min
为欧式距离dist最小的数据特征,y
min
是对应欧式距离didt最小的数据类别标签;
52.c.将该数据对应的标签作为残缺标签数据的标签。
53.步骤2、基于采油工程理论及典型示功图的特点,对示功图进行特征提取,使得特征能够更好地描述不同故障条件下的示功图特性。具体的方法如下:
54.基于不同示功图可能提示的油井故障不同等特点,提取相关特征包括:
55.采油工程特征:泵深、井当前含水率、泵充满程度、有效冲程;
56.示功图几何特征:示功图最大载荷、示功图最小载荷、示功图理论上载荷及理论下载荷、上冲程平均载荷、下冲程平均载荷、示功图上冲程曲线第一个峰值及最后一个峰值、
示功图下冲程曲线起一个峰值及最后一个峰值、示功图上冲程曲线平均斜率、示功图下冲程曲线平均斜率、上面积、下面积等。
57.步骤3、基于原始数据及生成数据将数据划分为训练数据集、验证数据集、测试数据集:
58.训练数据集:帮助训练模型,即通过训练集的数据确定拟合曲线的参数;
59.验证数据集:用来做模型选择,即做模型的最终优化及确定,辅助构建模型;
60.测试数据集:用来测试已经训练好的模型的精确度,防止噪声较大时产生的过拟合现象。
61.步骤4、采用集成学习构建和结合bagging和决策树来生成随机森林模型从而对数据进行分类。
62.bagging算法的具体流程为:让该学习算法训练多轮,每轮的训练集由从初始的训练数据中随机取出的n个训练样本组成,基于每个初始训练数据在某轮训练集中可以出现多次或根本不出现,训练之后可得到一个预测函数序列h_1,
…
h_n,最终的预测函数h对分类问题采用投票方式,对回归问题采用简单平均方法对新示例进行判别。
63.随机森林算法生成每棵树的规则是:
64.a.对于包含m个样本的原始数据集,通过自助采样得到同样包含m个样本的训练集;
65.b.每个样本有d个特征,那么选择一个小于d的整数k,随机地从d个特征中选择k个特征,然后决策树在每个结点上进行分裂时,从k个特征中选择最优的;
66.c.每棵树都生长到最大深度,不进行剪枝;
67.如图2所示,随机森林算法的基本流程是:
68.a.从样本集中有放回随机采样选出n个样本;
69.b.从所有特征中随机选择k个特征,对选出的样本利用这些特征建立决策树;
70.c.重复以上两步m次,即生成m棵决策树,形成随机森林;
71.d.对于新数据,经过每棵树决策,最后投票确认分到哪一类。
72.步骤5、将验证数据集输入到学习完成后的分类模型中,并利用错分率、计算效率、准确率和召回率对示功图自动诊断结果进行评价。
73.步骤6、实时采集示功图数据,利用学习完成的分类模型对示功图进行实时的自动诊断判断故障原因。
74.本发明一种基于集成学习的油井示功图自动诊断方法,经过集成学习后的分类模型可以用于油井示功图的自动诊断,其可以实时采集油井数据,完成可能提示的故障类型的判别,能够有效提高生产管理效率,具有一定的实用性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1