基于CNN与Transformer的低分辨率图像分类方法及系统与流程
基于cnn与transformer的低分辨率图像分类方法及系统
技术领域
1.本发明涉及计算机视觉中的图像分类领域,具体涉及一种基于cnn与transformer的低分辨率图像分类方法及系统。
背景技术:
2.图像分类的任务是学习和判断图像中是否包含某种特定的目标内容,并依据其内容信息进行分类的过程。图像分类是最基础的计算机视觉任务,其已经在人机交互、生物医学、航空航天和公安司法等领域取得了广泛应用。虽然图像分类研究取得的很大的进步,然而这些研究大部分是在高分辨率的图像中进行研究的。但在真实场景中,大部分情况下只能获得低分辨率的图像,因此,对低分辨率图像分类的研究至关重要。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种基于cnn与transformer的低分辨率图像分类方法,能有效提高对低分辨图像的分类性能。
4.为实现上述目的,本发明采用如下技术方案:
5.一种基于cnn与transformer的低分辨率图像分类方法,包括以下步骤:
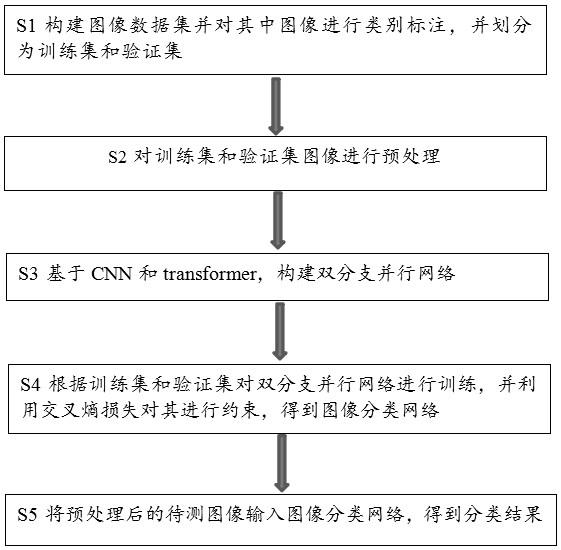
6.步骤s1:构建图像数据集并对其中图像进行类别标注,同时将图像数据集按照一定比例划分为训练集和验证集;
7.步骤s2:对训练集和验证集图像进行预处理;
8.步骤s3:基于cnn和transformer,构建双分支并行网络,通过cnn网络分支和transformer网络分支来对低分辨率图像进行特征提取,通过注意力特征融合网络将两个分支每一层的特征进行有效融合,并采用多通道注意力网络对融合后的特征进行语义信息挖掘;
9.步骤s4:根据训练集和验证集对双分支并行网络进行训练,并利用交叉熵损失对其进行约束,得到图像分类网络;
10.步骤s5:将预处理后的待测图像输入图像分类网络,得到分类结果。
11.进一步的,所述预处理包括尺寸调整和数据增强,所述尺寸调整是将输入的图像样本转化为预设大小,所述数据增强方式采用随机水平翻转、随机垂直翻转以及随机旋转。
12.进一步的,所述transformer网络分支由四个阶段组成,每个阶段由两个transformer编码器堆叠而成,transformer网络分支会输出四种不同尺寸的一维特征图。
13.进一步的,所述transformer网络分支产生的一维特征输入到转换网络中进行转换,使其与cnn网络分支产生的特征尺寸相同,转换网络中的转换公式如下:
14.xi=1
×
1conv(reshape(xi))i∈(1,2,3,4)
15.其中x为transformer网络分支四个阶段输出的一维特征,x为一维特征经过转换网络后产生的四个不同尺度的二维特征。
16.进一步的,所述cnn网络分支由5层组成,每一层均产生不同尺寸的二维特征,将第
一次层网络提取的特征输入到transformer分支中进行提取。
17.进一步的,所述注意力特征融合网络将cnn分支和transformer分支所提取的两种不同语义信息的特征进行融合,具体如下:
18.将cnn网络分支和transformer网络分支产生的特征进行相加得到一个融合特征;
19.将融合特征分两个分支进行处理,第一个分支利用全局平均池化得到融合特征的特征向量,同时利用卷积来降低维度,再利用relu激活函数进行处理,最后利用卷积来改变特征维度,得到第一个分支的注意力权重;
20.第二个分支,直接将融合特征进行卷积改变其特征尺寸,再利用relu来进行激活处理,最后利用卷积来恢复其特征尺寸,得到第二个分支的注意力权重,
21.将这两个分支的注意力权重进行相加得到一个新的注意力权重,
22.最后将新的注意力权重特征图与cnn和transformer网络产生的特征进行相乘、相加,得到最终融合的特征。
23.进一步的,所述多通道注意力网络利用多个支路,每个支路采用不同的卷积核来提取特征,之后利用通道注意力来增强特征的表示能力,公式如下:
24.x1=1
×
1conv(x)
25.x
11
=x1+x1*sigmoid(conv6(relu(conv5(maxpool(x1)))))
26.x3=3
×
3conv(x)
27.x
33
=x3+x
31
*sigmoid(conv6(relu(conv5(maxpool(x3)))))
28.x5=5
×
5conv(x)
29.x
55
=x5+x5*sigmoid(conv6(relu(conv5(maxpool(x5)))))
30.x
output
=x
11
+x
33
+x
55
31.其中,conv5为空洞卷积,用于降维,conv6为空洞卷积,用于升维,x
output
为经注意力网络输出的特征。
32.进一步的,所述交叉熵损失公式如下:
[0033][0034]
其中,qi表示软标签,b表示一个批次的样本数量,n表示类别总数也是预测向量的长度,pi表示教师网络的样本图像的预测值。
[0035]
一种基于cnn与transformer的低分辨率图像分类系统,包括处理器、存储器以及存储在所述存储器上的计算机程序,所述处理器执行所述计算机程序时,具体执行如上所述的基于cnn与transformer的低分辨率图像分类方法。
[0036]
本发明与现有技术相比具有以下有益效果:
[0037]
1、本发明通过双分支的网络架构设计,巧妙的控制了网络的深度,从而减少了图像特征信息的丢失,同时利用注意力特征融合网络,有效的将cnn和transformer的优点融合在一起,使其网络提取的特征更具有判别性,最后利用注意力网络来充分挖掘低分辨率图像中的语义信息;
[0038]
2、本发明在面对复杂背景噪声的低分辨率图像样本时也能够有效的减少噪声数据对最终分类结果的影响,具有较好的分类效果。
附图说明
[0039]
图1是本发明方法流程示意图;
[0040]
图2是本发明一实施例中模型框架图;
[0041]
图3是本发明一实施例中transformer分支结构图;
[0042]
图4是本发明一实施例中transformer编码器结构图。
具体实施方式
[0043]
下面结合附图及实施例对本发明做进一步说明。
[0044]
请参照图1,本发明提供一种基于cnn和transformer的低分辨率图像分类方法,其流程如图1所示,具体包括:
[0045]
步骤s1:构建图像数据集并对其中图像进行类别标注,同时将图像数据集按照一定比例划分为训练集和验证集;
[0046]
步骤s2:对训练集和验证集图像进行预处理;
[0047]
步骤s3:基于cnn和transformer,构建双分支并行网络,通过cnn网络分支和transformer网络分支来对低分辨率图像进行特征提取,通过注意力特征融合网络将两个分支每一层的特征进行有效融合,并采用多通道注意力网络对融合后的特征进行语义信息挖掘;
[0048]
步骤s4:根据训练集和验证集对双分支并行网络进行训练,并利用交叉熵损失对其进行约束,得到图像分类网络;
[0049]
步骤s5:将预处理后的待测图像输入图像分类网络,得到分类结果。
[0050]
在本实施例中,图像数据集分别采用了尺寸调整、数据增强两种预处理方法,尺寸调整是将输入的图像样本转化为224
×
224大小,数据增强方式采用随机水平翻转、随机垂直翻转以及随机旋转等。
[0051]
在本实施例例中,cnn分支由5层组成,每一层均产生不同尺寸的二维特征,将第一次层网络提取的特征输入到transformer分支中进行提取。而transformer由四个阶段组成,每个阶段均产生不同尺寸的一维特征。
[0052]
transformer网络分支由四个阶段组成,每个阶段由两个transformer编码器堆叠而成,transformer网络分支会输出四种不同尺寸的一维特征图。
[0053]
transformer网络分支产生的一维特征输入到转换网络中进行转换,使其与cnn网络分支产生的特征尺寸相同,转换网络中的转换公式如下:
[0054]
xi=1
×
1conv(reshape(xi))i∈(1,2,3,4)
[0055]
其中x为transformer网络分支四个阶段输出的一维特征,x为一维特征经过转换网络后产生的四个不同尺度的二维特征。
[0056]
在本实施例中,实现注意力特征融合的具体过程为:
[0057]
将cnn和transformer网络产生的特征进行相加得到一个融合特征,将该融合特征分两个分支进行处理,第一个分支利用全局平均池化得到融合特征的特征向量,同时利用卷积来降低维度,再利用relu激活函数进行处理,最后利用卷积来改变特征维度,得到第一个分支的注意力权重,
[0058]
第二个分支,直接将融合特征进行卷积改变其特征尺寸,再利用relu来进行激活
处理,最后利用卷积来恢复其特征尺寸,得到第二个分支的注意力权重,
[0059]
将这两个分支的注意力权重进行相加得到一个新的注意力权重,
[0060]
最后将新的注意力权重特征图与cnn和transformer网络产生的特征进行相乘、相加,得到最终融合的特征,
[0061]
output1=xi+yi[0062]
output2=conv2(relu(conv1(gap(output1))))
[0063]
output3=conv4(relu(conv3(output1)))
[0064]
output4=output2+output3[0065]
output=xi*sigmoid(output4)+yi*sigmoid(output4)其中,output1为初此融合的特征,output2为注意力特征融合网络中
[0066]
第一个分支产生的注意力图,output4为注意力特征融合网络低二个分支产生的注意力图,output4为总的注意力特征图,output为最终融合的特征,xi为transformer分支产生的一维特征经转换网络产生的二维特征,yi为cnn分支产生的二维特征。
[0067]
在本实施例中,利用所述多通道注意力网络来充分挖掘出低分辨率图像中的语义信息,具体为:
[0068]
多通道注意力网络利用多个支路,每个支路采用不同的卷积核来提取特征,之后利用通道注意力来增强特征的表示能力,从而通过这一系列处理来充分挖掘出低分辨率图像中的语义信息,使最终送入分类器的特征更具有判别性,公式如下:
[0069]
x1=1
×
1conv(x)
[0070]
x
11
=x1+x1*sigmoid(conv6(relu(conv5(maxpool(x1)))))
[0071]
x3=3
×
3conv(x)
[0072]
x
33
=x3+x
31
*sigmoid(conv6(relu(conv5(maxpool(x3)))))
[0073]
x5=5
×
5conv(x)
[0074]
x
55
=x5+x5*sigmoid(conv6(relu(conv5(maxpool(x5)))))
[0075]
x
output
=x
11
+x
33
+x
55
[0076]
其中,conv5为空洞卷积,用于降维。conv6为空洞卷积,用于升维。x
output
为经注意力网络输出的特征。
[0077]
本实例采用的损失为交叉熵损失函数本实例采用的损失为交叉熵损失函数来表示网络模型的输出与真实标签之间的误差,以此来提升网络模型的性能,其中,qi表示软标签,b表示一个批次的样本数量,n表示类别总数也是预测向量的长度,pi表示网络对样本图像的预测值。
[0078]
网络对样本图像各类别的预测概率值计算公式如下:
[0079][0080]
其中pi表示网络对当前样本属于类别i的概率,zi表示当前样本对应类别i的logit,n为样本类别总数。
[0081]
由标签处理成软标签公式如下:
[0082][0083]
其中n表示类别总数也是预测向量的长度。
[0084]
根据需求,重复上述步骤,直到网络模型收敛。
[0085]
用预处理后的测试集对网络模型进行图像分类。
[0086]
与上述实施例1相对应的,本实施例提出了一种基于知识蒸馏的transformer图像分类系统,该系统包括:
[0087]
训练集和测试集构建模块,用于构建训练集和测试集,并对训练集和测试集中的图像进行类别标注;对训练集合测试集中的图像进行预处理;
[0088]
模型训练模块,用于使用预处理后的训练集对多个学生网络模型同时进行训练,训练过程中利用预先训练好的教师网络模型对学生网络模型的训练进行指导,并在目标损失函数中增加相似性损失和多样性损失,输出准确率较高的学生网络模型
[0089]
模型测试模块,用于使用预处理后的测试集对输出的学生网络模型进行图像分类测试。
[0090]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1